博文
多智能体强化学习控制与决策研究综述
|
引用本文
罗彪, 胡天萌, 周育豪, 黄廷文, 阳春华, 桂卫华. 多智能体强化学习控制与决策研究综述. 自动化学报, 2025, 51(3): 510−539 doi: 10.16383/j.aas.c240392
Luo Biao, Hu Tian-Meng, Zhou Yu-Hao, Huang Ting-Wen, Yang Chun-Hua, Gui Wei-Hua. Survey on multi-agent reinforcement learning for control and decision-making. Acta Automatica Sinica, 2025, 51(3): 510−539 doi: 10.16383/j.aas.c240392
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c240392
关键词
强化学习,多智能体系统,序列决策,协同控制,博弈论
摘要
强化学习作为一类重要的人工智能方法, 广泛应用于解决复杂的控制和决策问题, 其在众多领域的应用已展示出巨大潜力. 近年来, 强化学习从单智能体决策逐渐扩展到多智能体协作与博弈, 形成多智能体强化学习这一研究热点. 多智能体系统由多个具有自主感知和决策能力的实体组成, 有望解决传统单智能体方法难以应对的大规模复杂问题. 多智能体强化学习不仅需要考虑环境的动态性, 还需要应对其他智能体策略的不确定性, 从而增加学习和决策过程的复杂度. 为此, 梳理多智能体强化学习在控制与决策领域的研究, 分析其面临的主要问题与挑战, 从控制理论与自主决策两个层次综述现有的研究成果与进展, 并对未来的研究方向进行展望. 通过分析, 期望为未来多智能体强化学习的研究提供有价值的参考和启示.
文章导读
强化学习是一类重要的控制与决策方法, 其基本思路是智能体通过与环境交互来学习如何在给定情境下做出最佳决策. 强化学习基于试错学习的概念, 智能体通过执行动作并观察结果来优化其行为, 目标是最大化长期奖励[1]. 近年来, 强化学习解决复杂决策问题的能力不断突破, 已经在机器人、自动驾驶、推荐系统[2]、博弈等领域取得显著成就. 例如, DeepMind发布的人工智能围棋程序AlphaGo[3]和AlphaGo Zero[4], 将强化学习、监督学习和蒙特卡洛树搜索结合起来, 成功学会了超越人类围棋冠军的对弈策略, 并发现了一些新的围棋策略和走法; 在机器人控制领域, 利用分层强化学习方法训练的机器狗守门员Mini Cheetah[5], 能够对快速飞行的足球进行精准拦截; 在博弈领域, DeepMind开发的DeepNash智能体[6]能够从零开始学习西洋陆军棋Stratego并成功达到人类专家水平, 这是一个行动和结果之间没有明显联系的不完全信息博弈问题; 在数学领域, DeepMind推出AlphaTensor智能体[7], 专注于寻找矩阵乘法的更高效算法, 该方法在多种不同大小的矩阵乘法任务中成功超越了现有的最佳算法.
在交通调度、自动驾驶、智能电网、工业控制等现实场景中, 常常存在多个实体同时参与决策过程, 这类由多个具有一定自主感知和决策能力的实体构成的系统称为多智能体系统. 通过独立个体之间的通信、协作或竞争, 多智能体系统能够实现远超单一个体的复杂行为, 有望解决单智能体方法难以处理的大规模复杂问题. 为此, 多智能体强化学习扩展了传统的强化学习范式, 允许多个智能体共同在环境中学习和决策, 期望通过个体局部交互涌现出复杂的全局行为或智能. 在多智能体强化学习中, 智能体根据对环境的观测采取行动, 并根据其行动的结果获得奖励或惩罚. 然而, 与单智能体强化学习不同, 多智能体系统中每个智能体的学习和决策过程不仅受到环境的影响, 还受到其他智能体行为的影响. 因此, 在多智能体环境中, 任何一个智能体的最优策略可能都依赖于其他智能体的策略. 这种相互依赖性增加了学习过程的复杂性, 因为智能体必须考虑到其他智能体的潜在行动和策略变化.
近年来, 多智能体强化学习快速发展, 相关研究可分为两条密切相关的脉络. 一部分研究从控制理论和优化方法的角度, 面向多智能体协同控制问题, 设计有效的多智能体强化学习控制算法, 在多种控制目标下实现系统稳定与性能优化; 另一部分研究从人工智能和机器学习的角度, 面向不确定环境中的序列决策问题, 研究多智能体强化学习决策方法, 在未知环境中学习高效的多智能体协调合作或对抗博弈策略. 这两类方法从不同的角度研究多智能体控制与决策问题, 有其各自的优势与特点. 本文对多智能体强化学习控制与决策领域的问题、挑战与方法进行分析与探讨, 以期为后续相关研究提供有价值的参考. 首先, 在多智能体强化学习控制方面, 从多智能体博弈和多智能体协同两个角度, 介绍强化学习算法在各类博弈与协同控制问题中的应用; 继而, 在多智能体强化学习决策方面, 从问题的视角出发, 针对性地分析多智能体强化学习所面临的难题与挑战, 系统性地综述相应解决方案和研究进展; 最后, 介绍多智能体强化学习控制与决策方法在几类现实领域的应用研究, 并对未来可能的探索方向进行总结与展望.
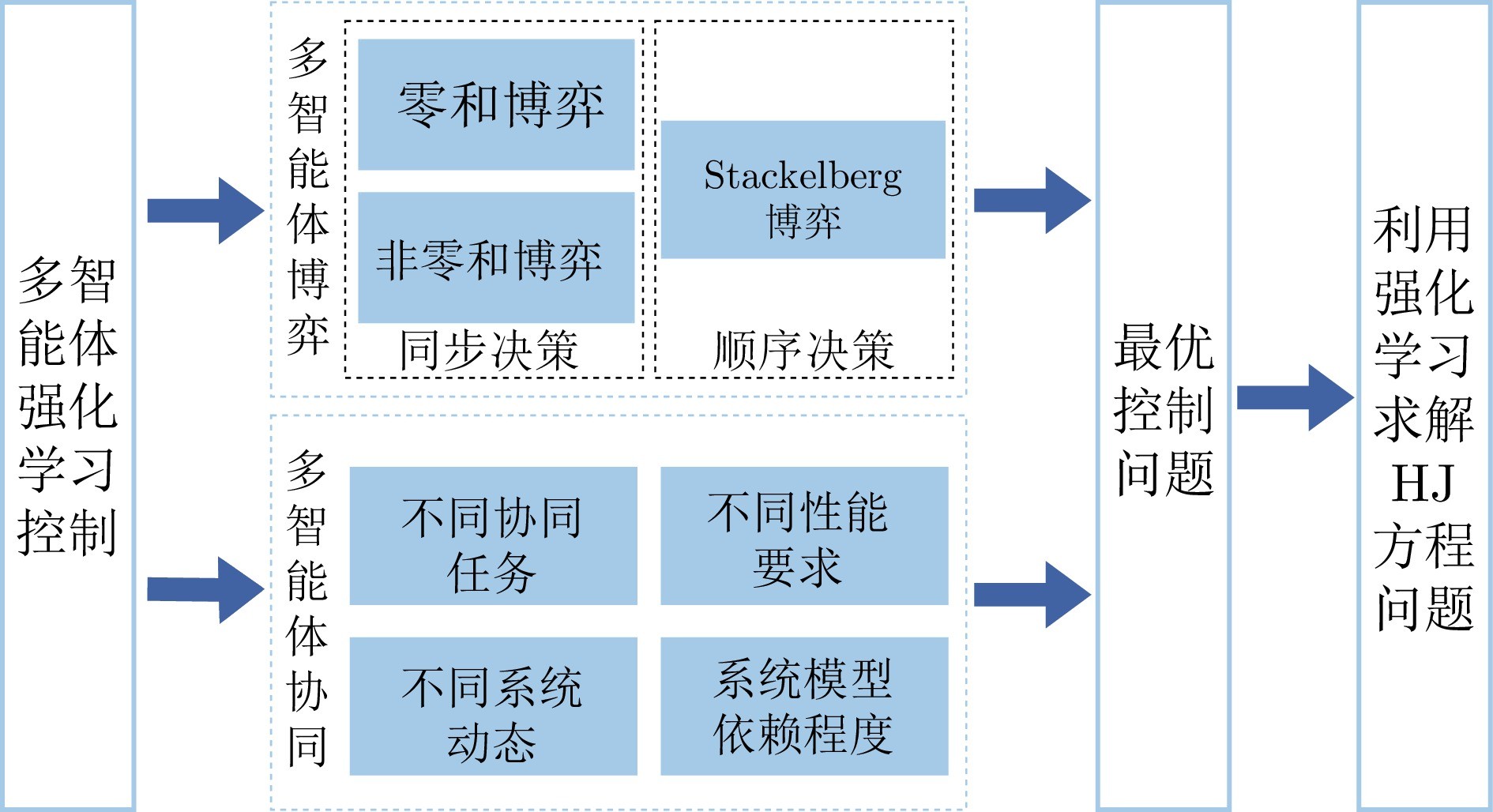
图 1 多智能体强化学习控制
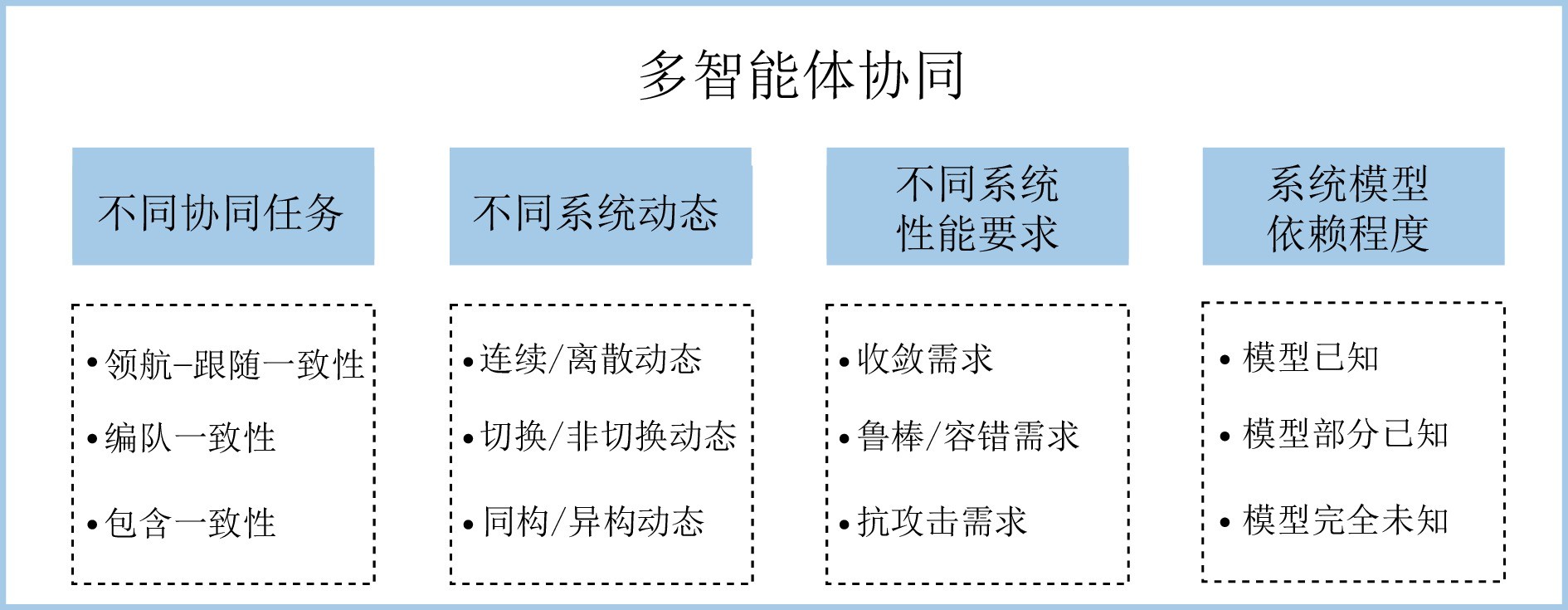
图 2 多智能体强化学习协同控制
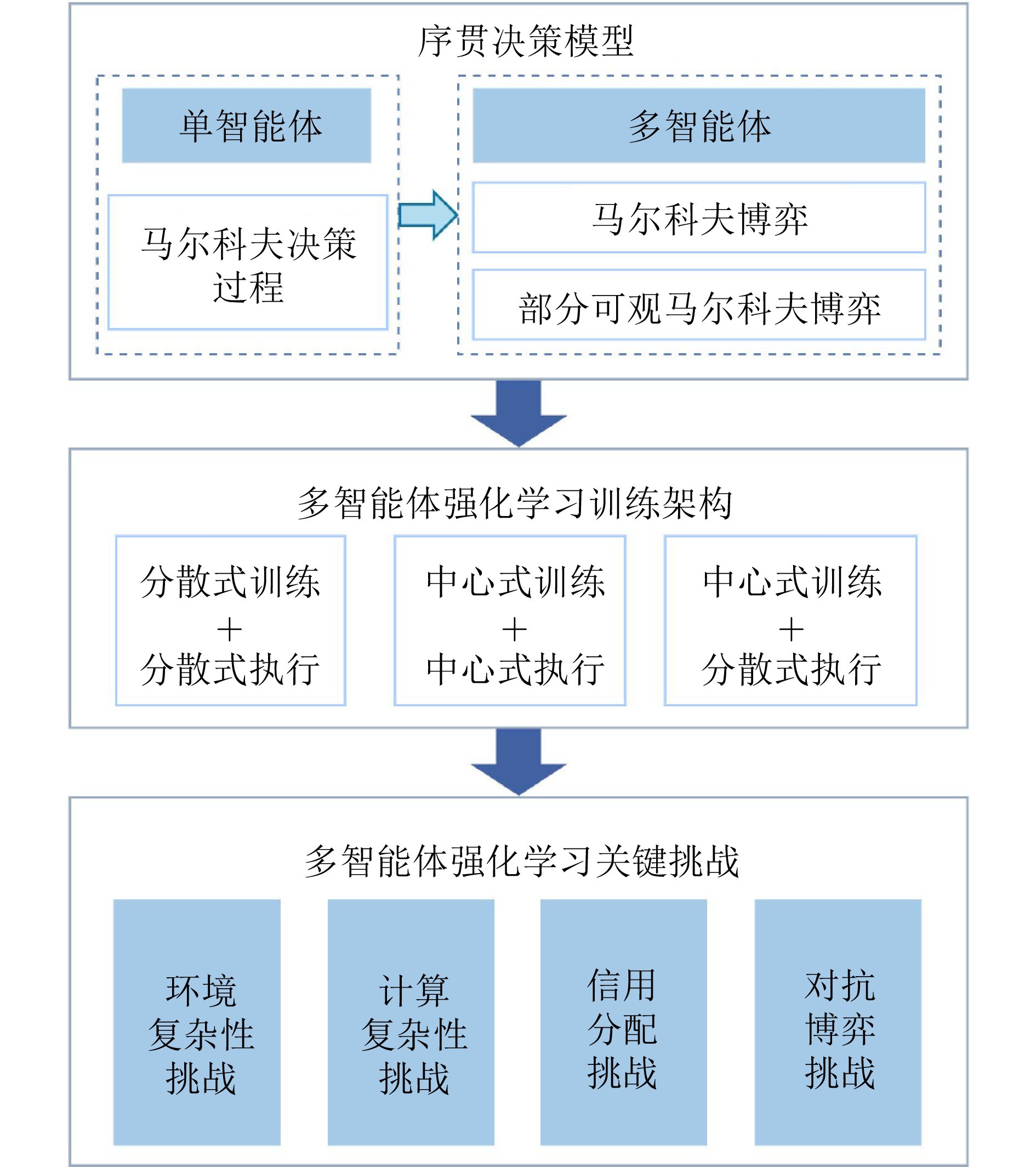
图 3 多智能体强化学习决策
本文分别从智能控制与自主决策的角度综述了多智能体强化学习的研究进展. 在多智能体强化学习控制领域, 本文首先从博弈的角度出发考虑智能体间的竞争与合作的关系, 分别介绍了零和博弈、非零和博弈与Stackelberg博弈三种主要的博弈类型, 总结了典型例子与算法; 随后从多智能体协同的角度, 总结了强化学习控制方法在不同系统动态与需求下所取得的研究成果. 在多智能体强化学习决策领域, 本文从马尔科夫决策过程和马尔科夫博弈模型出发, 分别介绍了多智能体序列决策的一般建模方法; 总结了多智能体深度强化学习的三类训练架构; 针对环境复杂性、计算复杂性、信用分配和对抗博弈四个方面, 梳理了多智能体强化学习所面临的挑战, 阐述了主流解决方案和最新研究进展. 然后, 本文选择机器人集群、智能交通、无人船舶三个重要应用场景, 分别介绍了多智能体强化学习控制与决策方法的应用研究. 最后, 结合对当前研究成果的分析与思考, 本文对多智能体强化学习的未来研究方向进行了一些展望.
1) 跨越从虚拟到现实的障碍
在多智能体强化学习的应用中, 从虚拟环境到现实世界的过渡是一个重大挑战. 出于成本、时间和安全性的考虑, 绝大多数深度强化学习研究都依赖虚拟环境提供学习所需的交互数据. 尽管多智能体强化学习方法在虚拟环境中显示出强大的潜力, 但常规虚拟环境不可能完全还原现实, 真实环境所具有的高度复杂性、动态性和不确定性很难体现在计算机仿真中, 限制了算法在现实任务中的有效性. 近年来, 一些研究借助大语言模型, 构建了包含虚拟居民和可交互社会场景的环境模拟器, 如“斯坦福小镇”[229], 以及面向机器人设计的GRUtopia[230]等. “斯坦福小镇”是一个由25个智能体和房屋、商店、公园等公共场所组成的虚拟环境, 其中的智能体能够产生自发的个体和社交行为, 并在小镇中生活和工作. 同时, 人类用户也可以通过自然语言与这些计算机智能体进行互动. 未来, 这类由大语言模型驱动的虚拟环境有望成为虚拟与现实之间的桥梁, 为多智能体强化学习研究提供更加逼近现实的训练和评估平台.
另一方面, 目前的许多研究忽略了真实环境中存在的诸多约束, 例如: 虚拟环境中可以轻易获取的环境数据在现实中很难得到、分布式设备的计算和通信资源有限、智能体之间的信息传递存在延迟和干扰等[231]. 为解决这些问题, 未来研究需要关注方法的通用性和鲁棒性, 重点考虑实际资源限制和环境复杂性, 探索轻量且高效的算法, 以适应现实世界应用的需求.
2) 高效解决多目标与多任务决策
许多现实决策问题包含相互冲突的多个目标, 策略必须在多个目标之间进行权衡, 不存在绝对的最优策略. 标准单目标方法处理多目标问题时会面临如下一些问题: 奖励函数的设计高度依赖直觉, 是一个繁琐的试错过程, 奖励函数与最终结果之间的关系通常是非线性的; 在设计决策系统时, 用户对不同目标的偏好可能是未知的; 目标偏好可能会因时间、具体场景、用户需求、安全约束等因素发生变化, 有时可能需要在不同策略之间切换. 在单智能体领域, 多目标强化学习方法已有一些研究, 如文献[232−234]等; 而多智能体和多目标强化学习这一新兴交叉领域的研究较少, 相关工作如Hu等[235]针对多智能体协同决策问题, 提出一种多目标多智能体强化学习方法. 现实世界决策中的另一项挑战是多任务问题, 智能体可能会面临相关但不完全相同的多项任务. 为单个任务分别学习专门的策略十分低效, 因为智能体不仅必须为每个任务存储不同的策略, 而且在实践中智能体可能需要自行判断任务特征. 多任务强化学习的目的是使智能体学习可以在各种相关任务中共享和使用的通用技能, 以提高策略的适用性和泛化性. 在多智能体强化学习领域, 可能面临个体和团队两个层面上的多任务问题: 在个体层面, 不同智能体可能具有不同的任务, 彼此之间需要配合或分工; 在团队层面, 智能体团队作为一个整体, 可能需要学习各类不同技能, 以解决多种团队协作任务.
总之, 多目标和多任务问题是在现实世界应用强化学习决策方法所面临的重要挑战, 而这些挑战在多智能体系统中变得更加复杂. 因此, 面向多智能体强化学习, 探索高效的多目标和多任务决策方法, 是值得进一步研究的方向.
3) 提高决策安全性和可解释性
在自动驾驶、工业自动化和医疗系统等实际场景中, 安全性至关重要. 这不仅要求智能体能够学习最优策略, 同时也必须保证在学习过程中和应用策略时的安全性, 以防止可能的风险和损失[236]. 然而, 深度强化学习方法通常以最大化奖励函数为目标, 这可能使智能体忽略现实场景中的安全约束, 阻碍了其在真实世界中的应用. 在多智能体系统中, 环境非平稳性和局部可观测问题增加了学习难度, 也加剧了安全挑战. 单个智能体要在满足自身安全约束的前提下优化奖励函数, 同时还要考虑其他智能体的行为, 以确保联合动作满足安全约束.
因此, 研究考虑约束的、安全的多智能体强化学习方法, 有助于提高多智能体强化学习在现实应用中的可行性, 是未来一个重要的研究方向.
作者简介
罗彪
中南大学自动化学院教授. 主要研究方向为智能控制, 强化学习, 深度学习和自主决策. 本文通信作者. E-mail: biao.luo@hotmail.com
胡天萌
中南大学自动化学院硕士研究生. 主要研究方向为强化学习, 多智能体强化学习和多目标决策. E-mail: tianmeng0824@163.com
周育豪
中南大学自动化学院博士研究生. 主要研究方向为多智能体系统, 强化学习控制和自适应控制. E-mail: yuhao980603@163.com
黄廷文
中南大学自动化学院教授. 主要研究方向为神经网络, 混沌动力学系统, 复杂网络和智能电网. E-mail: tingwen.huang@csu.edu.cn
阳春华
中南大学自动化学院教授. 主要研究方向为复杂工业过程建模与优化控制, 智能自动化系统与装置. E-mail: ychh@csu.edu.cn
桂卫华
中国工程院院士, 中南大学自动化学院教授. 主要研究方向为复杂工业过程建模, 优化与控制应用和故障诊断与分布式鲁棒控制. E-mail: gwh@csu.edu.cn
https://wap.sciencenet.cn/blog-3291369-1482487.html
上一篇:多智能体系统专刊序言
下一篇:异构多智能体网络拓扑可辨识性