博文
基于深度强化学习的无人机自主感知−规划−控制策略
|
引用本文
吕茂隆, 丁晨博, 韩浩然, 段海滨. 基于深度强化学习的无人机自主感知−规划−控制策略. 自动化学报, 2025, 51(6): 1305−1319 doi: 10.16383/j.aas.c240639
Lv Mao-Long, Ding Chen-Bo, Han Hao-Ran, Duan Hai-Bin. Autonomous perception-planning-control strategy based on deep reinforcement learning for unmanned aerial vehicles. Acta Automatica Sinica, 2025, 51(6): 1305−1319 doi: 10.16383/j.aas.c240639
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c240639
关键词
无人机,深度强化学习,自主导航,复杂未知环境
摘要
近年来, 随着深度强化学习(DRL)方法快速发展, 其在无人机(UAV)自主导航上的应用也受到越来越广泛的关注. 然而, 面对复杂未知的环境, 现存的基于DRL的UAV自主导航算法常受限于对全局信息的依赖和特定训练环境的约束, 极大地限制了其在各种场景中的应用潜力. 为解决上述问题, 提出多尺度输入用于平衡感受野与状态维度, 以及截断操作来使智能体能够在扩张后的环境中运行. 此外, 构建自主感知−规划−控制架构, 赋予UAV在多样复杂环境中自主导航的能力.
文章导读
无人机(Unmanned aerial vehicle, UAV)因其在多样化应用场景中的卓越性能而日益受到青睐, 包括紧急救援[1]、地图构建[2]以及边缘智能计算[3]等. 在实际操作中, 无人机经常需要在充满障碍物的空间中穿行, 以到达一系列预定的点位. 这一需求催生对高效自主导航系统的迫切需求. 在这些系统中, 路径规划技术扮演着至关重要的角色. 为此, 研究者们已经开发了多种算法, 涵盖基于搜索的方法、基于采样的方法以及模仿自然界智慧的生物启发式算法[4]. 然而, 当置身于未知、复杂且广阔的环境时, 现有算法的局限性便显现出来. 这激发了对更智能路径规划解决方案的追求, 而深度强化学习(Deep reinforcement learning, DRL)正是在这一领域中展现出巨大潜力的关键技术[5], 并逐渐成为解决此类挑战的热点研究方向.
研究人员在探索将DRL应用于无人机导航的初期阶段, 选择在二维网格环境中对算法进行测试[6]. 在这些实验中, 无人机被抽象为质点, 仅执行一系列离散的动作. 在环境规模较小的情况下, 传统的表格型强化学习方法[7]尚能满足需求. 然而, 面对更广阔的环境, 就必须借助神经网络的强大功能来提升无人机的运行效率. 一种流行的方法是利用卷积神经网络(Convolutional neural network, CNN)来解析图像信息, 随后结合多层感知器(Multilayer perceptron, MLP)构建深度Q网络(Deep Q-network, DQN)[8], 以评估状态−动作对的价值. CNN在处理较小环境中的全局信息方面表现出色, 但在环境范围扩大时, 其处理能力仅限于局部信息, 这限制了它们在大规模环境中的应用潜力. 在无人机导航领域的研究中, 学者们已经不局限于二维环境, 而是向更为立体的三维空间拓展[9]. 在这些三维研究中, 一些工作采用体素化的环境和离散化的动作空间进行实验. 面对连续变化的真实世界, 研究者们倾向于应用简化的动力学模型来捕捉无人机运动的本质特征.
在实际的三维空间研究中, 大多数工作仅应用神经网络进行状态识别, 而决策和控制任务仍依赖于明确的程序设计. 例如, 赵栓峰等[10]使用CNN结合单目相机来完成深度估计, 而刘佳铭等[11]将其应用于目标识别. 真正将DRL应用于现实三维环境的研究相对较少. 一种普遍采取的方法是利用测距设备来感知周围环境, 并运用深度确定性策略梯度(Deep deterministic policy gradient, DDPG)[12]算法来精细调控无人机的加速度. 在此基础上, 其他学者采用双延迟DDPG (Twin delayed deep deterministic policy gradient, TD3)[13]算法, 这一算法通过引入两个网络来减少策略更新中的误差, 提高无人机导航的稳定性和可靠性. 其中, Lei等[14]采用TD3算法, 根据深度图像直接确定所需的控制指令, 并由飞行控制器执行. 此外, Xi等[15]利用分层式强化学习, 使用DQN确定航标点后, 再使用TD3完成飞行控制. 同样, Ugurlu等[16]则运用近端策略优化(Proximal policy optimization, PPO)技术, 构建了具备安全避障能力的端到端策略. 郭子恒等[17]提出一种基于DRL的无人机反应式扰动流体路径规划架构, 该架构通过在线生成对应障碍的反应系数和方向系数, 实现反应式避障. 满恂钰等[18]提出基于软演员−评论家(Soft actor-critic, SAC)强化学习算法的无人机自主导航方法, 该方法通过增强记忆机制, 整合历史记忆信息与当前观测, 有效提升无人机在未知环境下的自主导航能力. 而面对实现多无人机之间的有效通信和协调, 以完成复杂的任务, 杨永祥等[19]综述了分层强化学习(Hierarchical reinforcement learning, HRL)在无人机领域, 特别是在轨迹规划和资源分配优化问题上的应用.
当前无人机自主导航系统在复杂和未知环境中面临显著挑战, 主要问题在于对全局环境信息的过度依赖以及决策过程中的实时性不足. 大多数系统采用的图搜索或随机采样算法在缺乏全局信息时性能大幅下降, 且需要多次遍历环境信息, 这在复杂未知的环境中难以满足实时决策的需求. 此外, 尽管DRL为解决这些问题提供了新途径, 通过训练能够在局部不完全信息的基础上做出决策, 但其在可迁移性和泛化能力上仍存在局限, 智能体在面对与训练环境差异较大的场景时完成任务的能力受限. 主要因为DRL的一个关键目标是训练一个可以通过单一训练过程在不同情况下运行的路径规划器. 然而, 在有限的环境中进行训练可能会限制智能体泛化到更大、更复杂环境的能力. 当神经网络应用于比训练环境更大的环境时, 可能会导致神经网络失败, 也进一步凸显测试基于DRL的智能体的可迁移性的必要性.
针对现有问题, 本研究旨在开发一种新型的无人机自主导航算法框架, 该框架能够通过单一环境训练实现在任意环境中的应用, 从而提高无人机在多变复杂环境中的适应性和灵活性. 通过DRL技术, 本研究力图克服无人机自主导航算法对全局环境信息的依赖, 减少决策延迟, 并增强算法的泛化能力, 使其能够在与训练环境不同的实际场景中稳定运行. 这一研究目标有望推动无人机自主导航技术的发展, 为高适应性自主系统的领域带来技术进步.
本文将通过设计并改进DRL算法, 构建一个更为优化的无人机自主导航智能体, 并将这一智能体模型应用于无人机自主导航软件的设计中, 通过构建仿真环境完成软件的智能性和可迁移性的测试. 本研究主要贡献包括:
1) DRL驱动的路径规划创新, 以实现在有限感知条件下的高效路径规划. 本研究基于DRL的Double DQN (Double deep Q-network)算法, 为无人机设计精细的动作和状态空间, 实现了在单一障碍物环境中的高效自主导航训练. 引入多尺度状态输入技术, 旨在均衡状态的空间覆盖与维度, 既充分利用环境信息, 又有效规避维度爆炸的问题. 实验结果表明, 该智能体在导航任务中表现卓越, 导航成功率达到97.19%.
2)泛化能力强化的路径规划器设计, 以适应其他复杂未知障碍环境. 为解决现有算法在更广阔未知环境中性能下降的问题, 本文提出误差向量截断技术, 对智能体的状态输入进行优化, 大幅增强算法的泛化性. 实验数据显示, 引入截断技术后, 大规模环境下的导航成功率从77.20%提升至96.93%, 实现了明显的性能改善.
3)一体化无人机自主导航与运动规划软件构建, 以加速无人机的实际应用进程. 在现有路径规划器的基础上, 本文集成分段$ y $次多项式轨迹优化算法, 并结合双目视觉传感器与SE(3)飞行控制器, 开发了一个全面的无人机自主导航软件. 该软件实现自主感知、路径规划和飞行控制的无缝集成, 确保无人机在复杂未知环境中的高度自主操作. 仿真测试结果表明, 与A* 算法相比, 本系统不仅具有更强的可行性和安全性, 还实现了更低的计算成本.
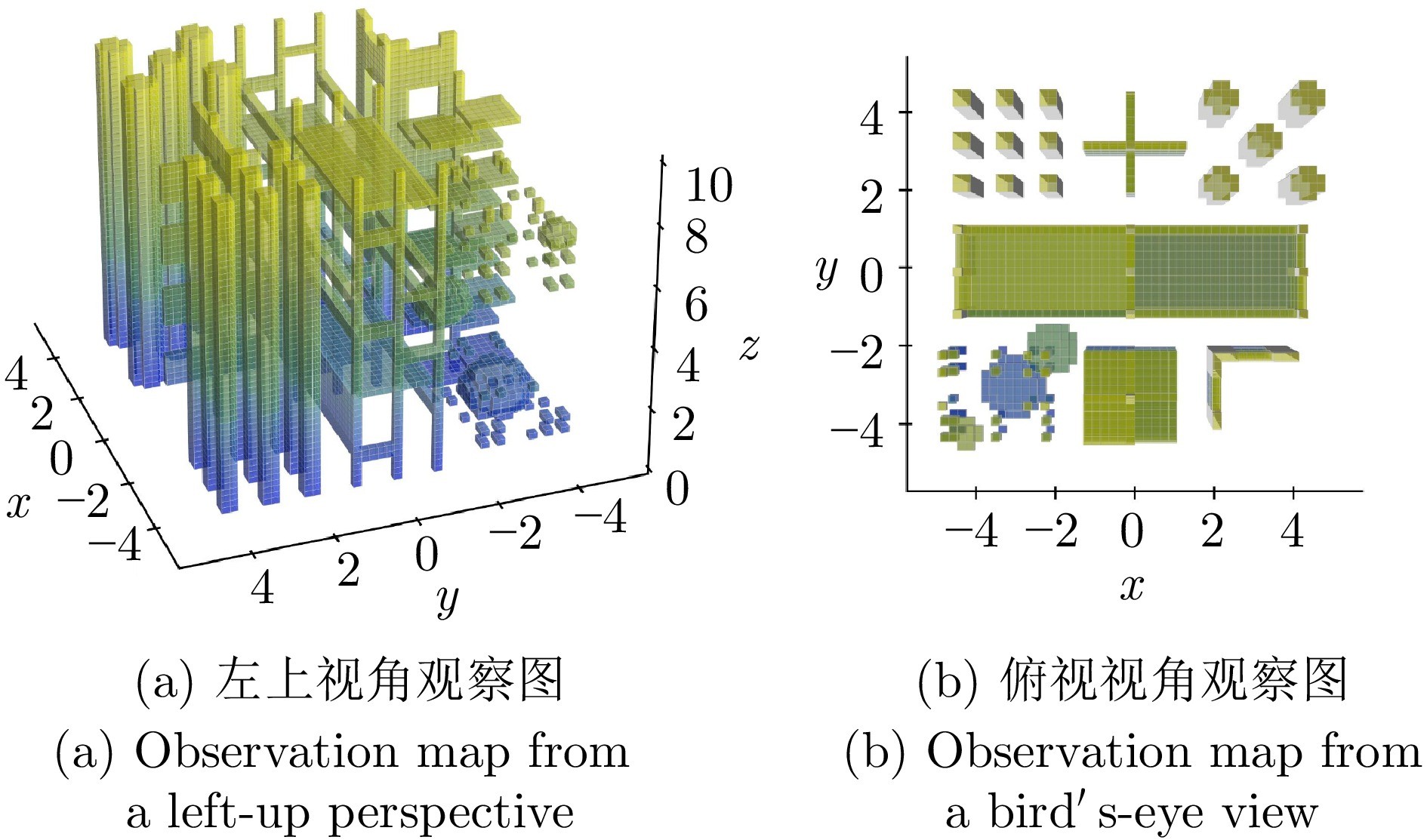
图 1 算法训练障碍物环境观察图
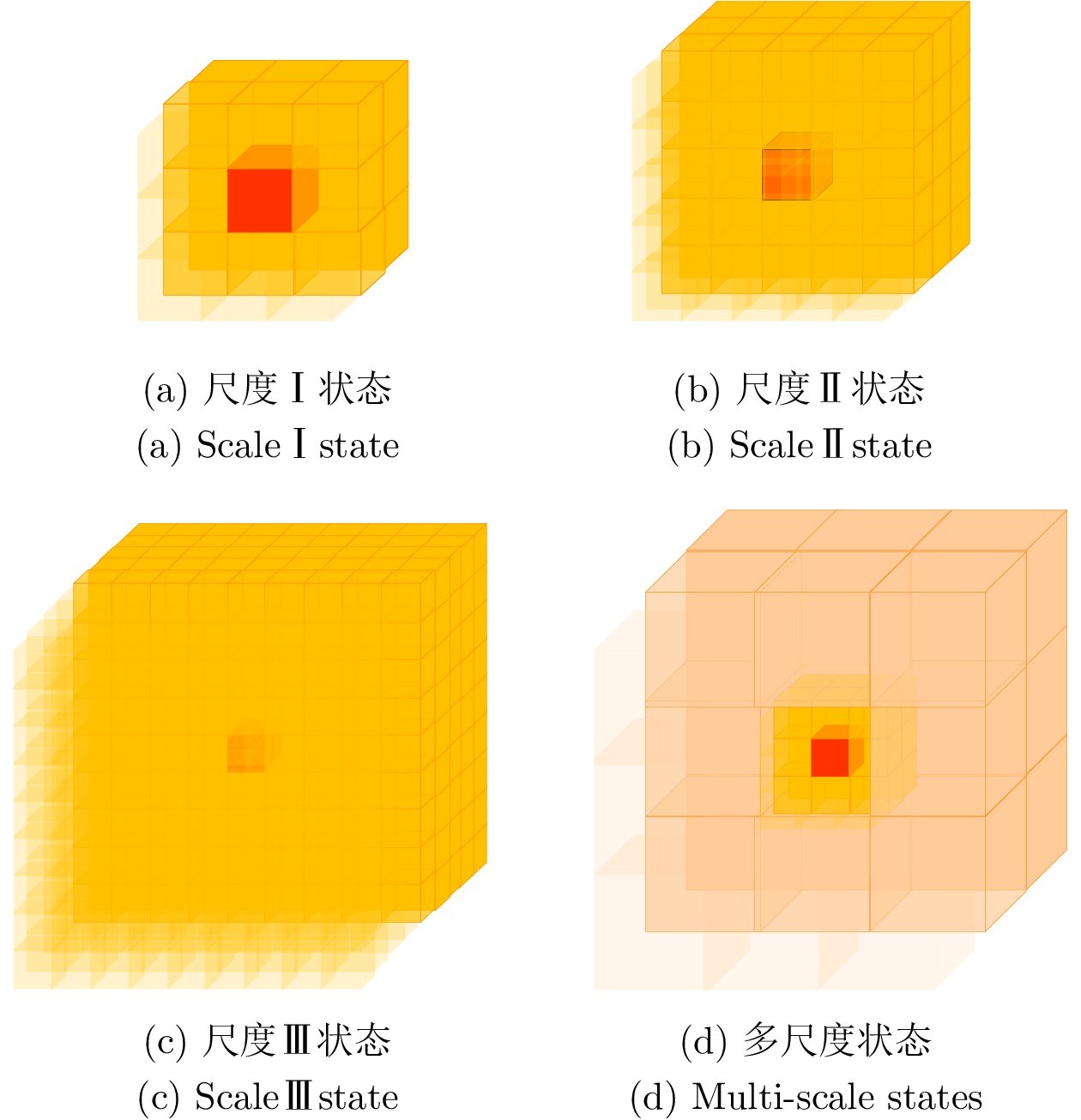
图 2 感知状态覆盖空间表示
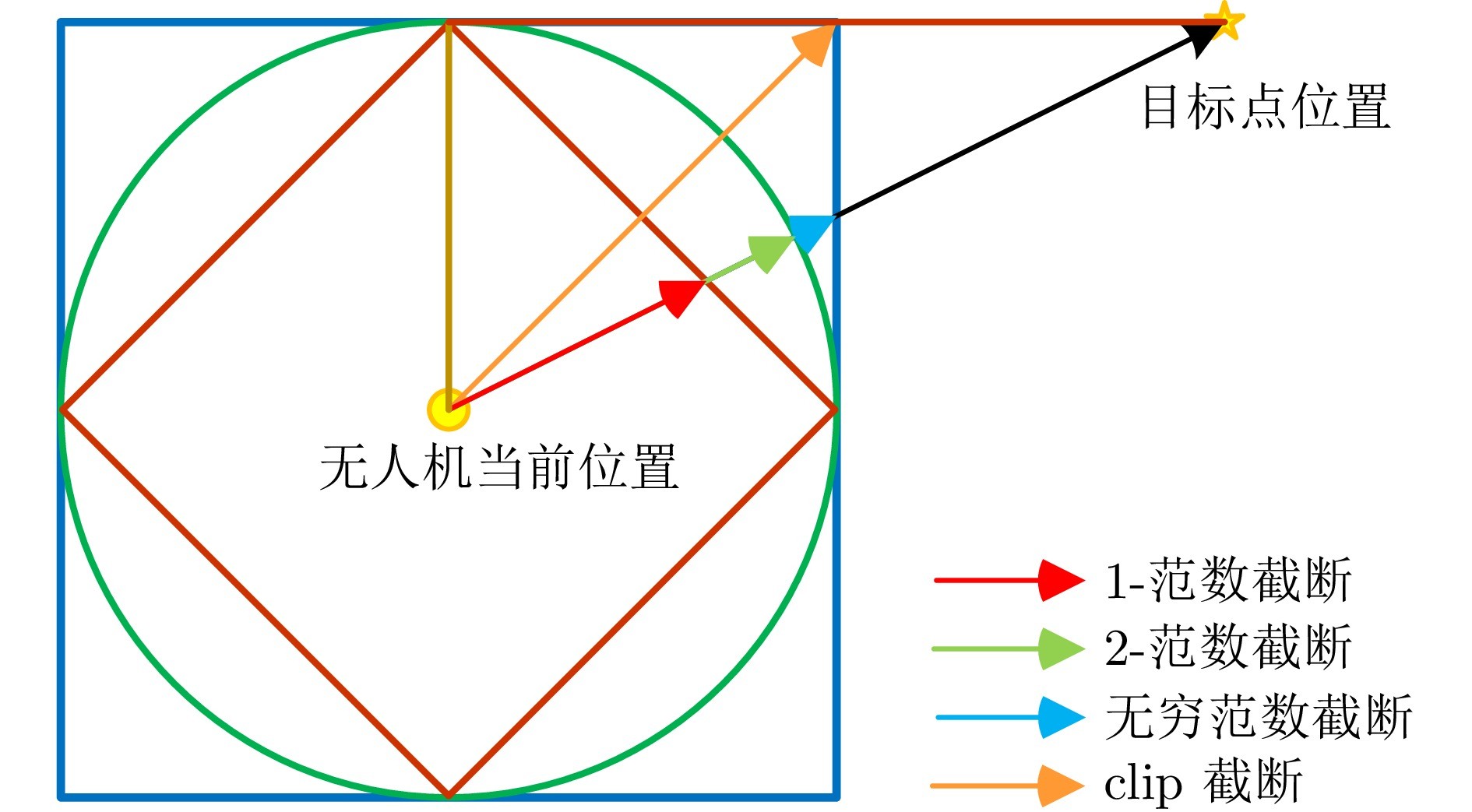
图 3 不同截断操作示意图
本文提出了一种无人机自主导航技术, 该技术核心采用了DRL驱动的路径规划器. 为进一步提升系统性能, 开发一种多尺度状态输入技术, 这一技术一定程度上平衡了状态空间的覆盖范围与维度, 显著优化了智能体的决策效率. 此外, 引入误差向量截断技术, 对无人机的误差向量进行调整, 有效拓展了DRL路径规划器在多样化实际场景中的应用范围.
本文所设计的DRL路径规划器, 能够无缝集成到一个模块化的自主导航结构中, 实现无人机在自主感知、规划和控制方面的一体化操作. 该软件已证明能在包含不同密度、尺寸、方向和高度障碍物的未知环境中成功执行导航任务. 更重要的是, 本导航技术展现出卓越的泛化能力, 能够适应比训练环境更为广阔的场景. 与传统的基于搜索的A*算法相比, 所提出的DRL路径规划算法在可行性、安全性和计算效率方面均表现出明显优势.
未来的研究应致力于提高无人机对已观测信息的利用效率、加强动力学约束在路径规划中的应用, 以及改进感知技术. 通过在障碍物信息整合、动力学约束融合, 以及体素环境的动态更新这三个关键方向上取得进展, 以提升无人机的自主导航性能, 增强其在复杂未知环境中的适应性和执行效率. 这些研究将帮助无人机更好地利用环境信息, 优化飞行路径, 并及时响应障碍物变化, 从而在无人系统的导航领域实现技术突破.
https://wap.sciencenet.cn/blog-3291369-1495020.html
上一篇:梯度引导的JPEG压缩图像超分辨率重建
下一篇:通信链路故障下高阶非匹配非线性MAS领导跟随一致性