
 精选
精选
人工智能通过染色质数据来揭示基因相互作用
一种基于DNA紧密包装区域以及可被调控因子接触区域相关数据进行训练的人工智能模型,能够预测基因表达情况以及调控关键基因的转录因子之间的相互作用。
对于多细胞生物体内的细胞而言,要想发挥不同的作用,每个细胞就必须表达一组不同的蛋白质,使其能够执行自身功能、维持其基因调控状态并对刺激做出反应。尽管每个细胞都拥有相同的基因组,但控制基因表达的表观遗传修饰取决于细胞所处的环境,例如发育阶段、疾病状态或组织环境等。染色质(DNA的包装形式)的可及性受到表观遗传调控,它决定了基因组中的哪些调控区域能够被转录因子(开启或关闭基因或者调节其表达水平的蛋白质)所接触。付等人在《自然》杂志上发表文章称,他们开发了一种机器学习模型,该模型基于来自200多种成人和胎儿细胞类型的染色质可及性数据进行训练,旨在了解不同的染色质可及性“景观”是如何产生不同转录状态的。随后,研究人员应用这一模型对这些状态以及驱动表达的调控序列和转录因子之间的相互作用进行预测。
现有的从基因组序列预测细胞表观遗传或转录状态的模型,通常针对每种不同的细胞环境分别进行微调。这样就能基于相同的基础基因组序列实现细胞状态特异性。然而,这种方法可能导致模型朝着该细胞环境的平均表观遗传或转录状态进行调整,为了实现准确的环境特异性,就需要对越来越窄的细胞状态进行微调。此外,为每种细胞环境生成单独的模型会降低模型通过同时对比多种环境来学习的能力。
基础模型是一种机器学习模型,它基于大规模、通用数据集进行训练,以获取与模型所学领域相关的基础知识。然后,这些知识可以被迁移,用于优化各种应用中的性能。过去几年开发的许多基础模型都基于多样的基因表达谱进行训练,以便能够在无需单独模型的情况下,做出与基因功能和细胞状态相关的、具有环境特异性的预测。然而,它们“词汇表”中的“单词”是整个基因,而非单个核苷酸的序列。因此,利用染色质可及性数据对这类模型进行微调的尝试,依赖于将给定基因组区域的染色质可及性水平分配给指定基因。这就妨碍了对调控蛋白结合以影响基因表达的序列进行细致分析。
与这种方法不同,付等人开发了一种直接基于来自不同细胞类型的染色质可及性数据进行训练的模型(图1)。通过这种方式,一个统一的模型就能够学习到调控基因表达的表观遗传景观的关键特征。作者将这一工具称为通用表达转换器(GET),它能够从染色质可及性数据中推断基因表达模式,即便对于那些未包含在训练数据中的未知细胞类型也可以做到,这意味着通过观察不同环境下的染色质可及性状态,能够学习到一种通用的“语法”。
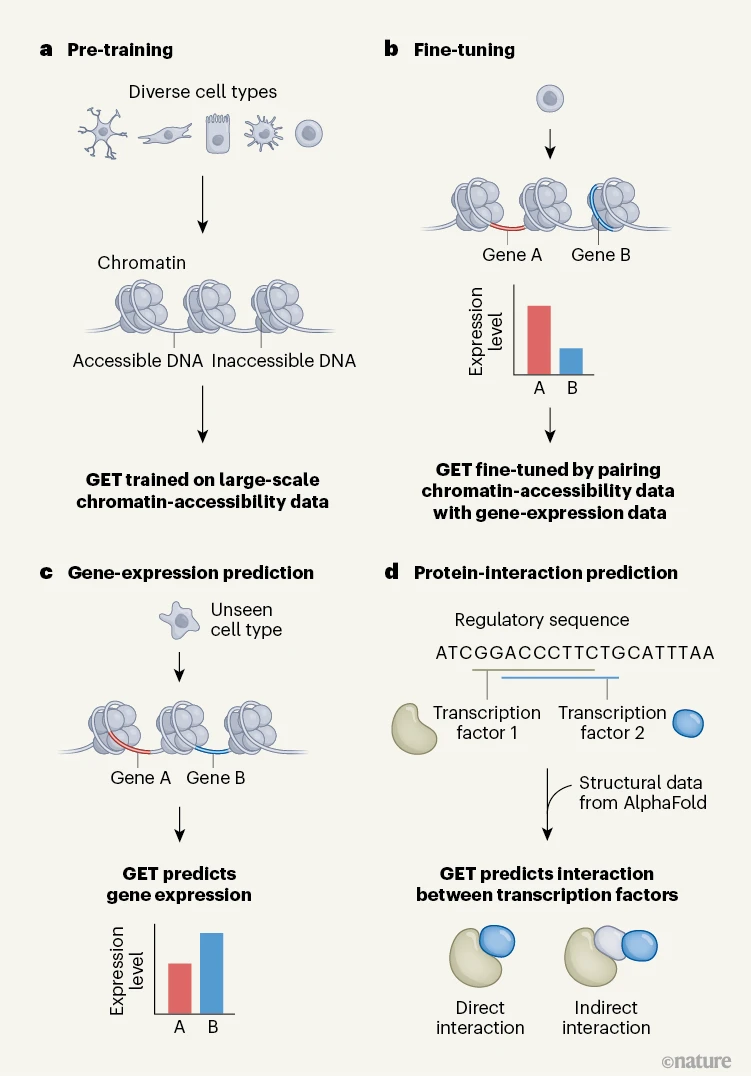
图1 | 一种用于预测基因表达和转录因子相互作用的机器学习模型
a,染色质(DNA的包装形式)对转录机制的可及性会影响细胞内基因表达的水平。付等人基于来自数百种细胞类型的染色质可及性数据对一个名为GET的模型进行了预训练。随后作者将GET用于一系列下游应用。
b,例如,通过利用配对数据对GET进行训练,使其针对从染色质可及性来预测基因表达这一任务进行微调。
c,之后作者利用经过微调的模型从染色质可及性来预测未知细胞类型中的基因表达。
d,他们还利用GET来预测基因组中供转录因子结合的调控序列,并且结合从人工智能工具“阿尔法折叠”(AlphaFold)获得的蛋白质结构信息,预测两个转录因子是直接相互作用还是间接相互作用。
尽管许多基因的表达可以从基因组中附近调控区域的可及性来推断,但有些基因的表达并不能通过其局部可及性来预测;例如,尽管它们处于稳定开放的染色质区域,但其表达仍可能会发生变化。发育过程中的关键调控因子如果表达异常,可能会产生严重后果,它们可能需要通过染色质重塑来进行严格调控。相比之下,维持完全分化细胞功能的基因可能位于开放区域,这样转录就可以根据细胞波动的需求进行调整,而且调整速度比染色质重塑所需时间更快。
一个基因既会受到其局部调控区域(可能直接影响其表达)的影响,也会受到远距离区域(可通过调控其某个调控因子间接影响它)的影响。全基因组染色质可及性图谱包含了目标基因局部区域以及整体调控状态两方面的信息。因此,GET能够从整体状态中学习推断出上游调控因子的表达水平,进而解释处于稳定开放染色质区域的下游基因的表达情况。
作者利用GET来预测驱动基因表达的调控序列(或元件)。为此,他们利用来自一种名为K562的人类细胞系的单细胞染色质可及性及转录测量数据对GET进行训练。作者将GET的预测结果与通过实验测量的、随机插入K562细胞基因组中的基因组序列的调控活性进行了对比。GET成功地学习到了整个基因组中各元件的调控活性,并且其表现优于基于K562基因组数据训练的其他替代模型。
随后,作者应用GET来确定调控红细胞前体细胞(成红细胞)中影响胎儿血红蛋白水平的四个基因表达的调控元件。胎儿血红蛋白是镰状细胞贫血的一个治疗靶点,基因疗法一直聚焦于提高其水平以缓解该疾病。与实验数据对比时,GET在检测有影响力的调控元件方面优于之前的模型,而且在预测远离目标基因的调控元件时,它比其他替代方法更精确——尽管精确度确实会随着距离增加而降低。
最后,付等人应用GET对转录因子之间的相互作用进行分类整理。他们将这一分类整理的结果与利用蛋白质结构预测模型“阿尔法折叠”(AlphaFold)进行的结构分析相结合,以检验所预测的相互作用是否可能涉及蛋白质之间的直接结合。
作者通过实验证实了蛋白质 - 蛋白质相互作用,证明了转录因子TFAP2A和ZFX之间存在直接相互作用,正如他们的方法所预测的那样。这种相互作用在某些情况下可能起着至关重要的作用,例如在颅骨和面部发育过程中——已知这两种蛋白质都参与调控这一过程。作者还通过实验证实了转录因子PAX5与一组“核受体”转录因子之间所预测的相互作用。研究人员认为,PAX5中常见的一种突变可能会增强这种相互作用,而该突变与B细胞急性淋巴细胞白血病的风险升高有关。这一发现凸显出GET可用于识别与疾病相关的相互作用,若经实验验证,这些相互作用可能会指向潜在的治疗靶点。
GET揭示驱动表达的调控元件以及预测转录因子之间此前未被观察到的相互作用的能力,强调了全基因组染色质可及性图谱包含了足够的信息,能够基于目标基因周围调控区域以及其上游调控因子周围调控区域的可及性状态,准确预测转录情况。未来的工作可以整合有关细胞调控其他层面的信息,以进一步深入了解染色质可及性与三维染色质构象、蛋白质翻译以及翻译后修饰之间的关系。此外,将GET扩展到能在核苷酸水平分辨率上运行,或许能使其从已知细胞类型进行外推,预测基因变异的影响,即便在没有染色质可及性图谱的情况下也能做到。这对于研究临床上难以取样的与疾病相关的细胞类型(如心脏细胞或脑细胞)来说将尤为有价值。
转载本文请联系原作者获取授权,同时请注明本文来自孙学军科学网博客。
链接地址:https://wap.sciencenet.cn/blog-41174-1468491.html?mobile=1
收藏