
 精选
精选
即时解读电子表格的通用AI
人工智能已经被广泛用于从数据表中推断结果,但这通常需要针对每项任务创建一个模型。而一个通用型模型刚刚让这一过程变得简单了许多。
假设你经营着一家医院,想要预估哪些患者病情恶化的风险最高,以便医护人员能够据此对护理工作进行优先级排序。你制作了一个电子表格,每行对应一位患者,各列记录相关属性,比如年龄或血氧水平等。最后一列记录患者住院期间病情是否恶化。然后,你可以针对这些数据拟合一个数学模型,来预估新入院患者病情恶化的风险。这是表格机器学习的一个典型例子,这是一种利用数据表进行推断的技术,通常涉及为每项任务开发并训练一个定制化的模型。霍尔曼等人在《自然》杂志上发表文章称,他们开发出了一种无需专门针对特定任务进行训练就能对任何数据集执行表格机器学习的模型。
表格机器学习与统计学和数据科学有着深厚的渊源。其方法是现代人工智能(AI)系统(包括大型语言模型)的基础,其影响力怎么强调都不为过。实际上,许多线上体验都是由表格机器学习模型塑造的,这些模型可推荐产品、生成广告以及管理社交媒体内容。医疗保健和金融等关键行业也在谨慎但稳步地增加人工智能的使用。
尽管这一领域已经较为成熟,但霍尔曼及其同事所取得的进展仍可能具有革命性。作者们的成果被称为基础模型,这是一种能在多种场景下使用的通用型模型。你可能已经通过诸如ChatGPT和Stable Diffusion等人工智能工具在不知不觉中接触过基础模型了。这些模型能让一个工具具备多种功能,包括文本翻译和图像生成等。那么,用于表格机器学习的基础模型是什么样的呢?
让我们再回到医院的例子。拿着电子表格,你选择一个机器学习模型(比如神经网络),然后使用一种算法,通过调整模型的参数来优化其预测性能,用你的数据对该模型进行训练(图1a)。通常情况下,在选定一个可用模型之前,你需要训练好几个这样的模型——这是一个耗费人力的过程,需要大量时间和专业知识。当然,对于每一项独特的任务,都必须重复这一过程。
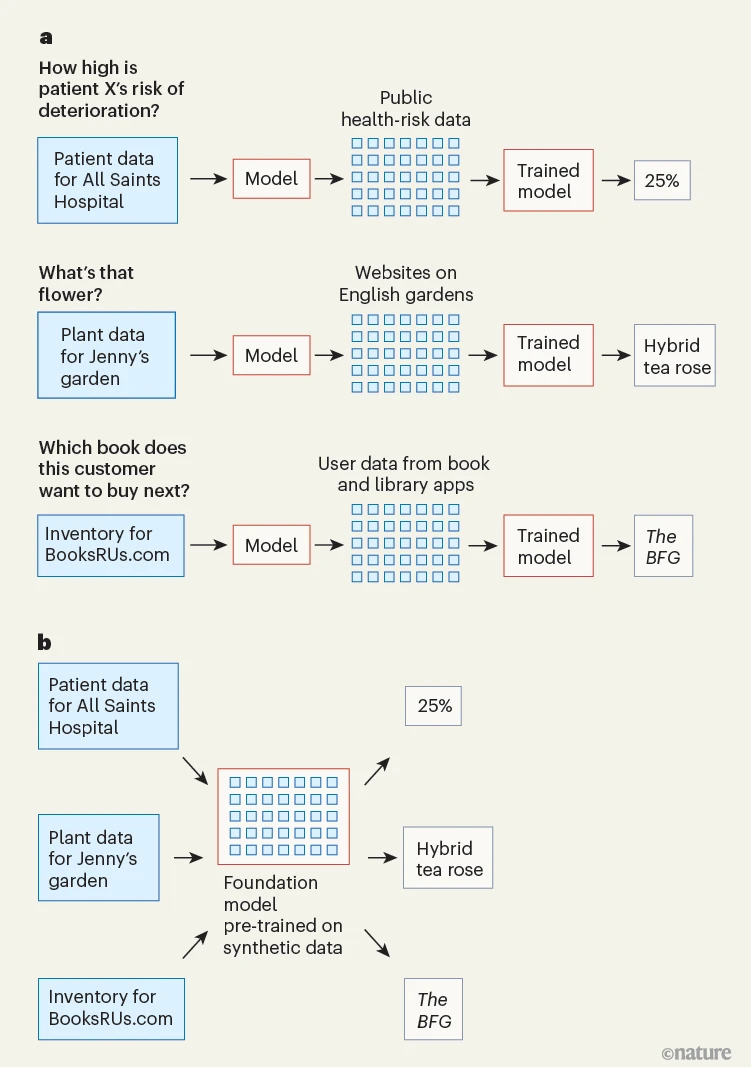
图1 | 用于表格机器学习的基础模型
a,传统机器学习模型是利用数学优化算法基于单个数据集进行训练的。每项任务以及每个数据集都需要开发并训练一个不同的模型。这种做法需要花费数年时间去学习,而且需要大量时间和计算资源。
b,相比之下,一个“基础”模型可以用于任何机器学习任务,并且是基于那些用于训练传统模型的数据类型进行预训练的。这种类型的模型只需读取一个数据集,就能立即对新的数据点做出推断。霍尔曼等人开发了一个用于表格机器学习的基础模型,在该模型中,推断是基于数据表进行的。表格机器学习可用于诸如社交媒体管理和医院决策等各种各样的任务,因此作者们所取得的进展预计将在许多领域产生深远影响。
现在,想象一下你有一个基础模型,它在读取电子表格后,就能立即预估出一个人病情恶化的风险(图1b)。然后再设想一下,这个基础模型可用于任何电子表格,适用于任何表格机器学习任务。这与自动机器学习算法类似,自动机器学习算法能使模型选择和训练的过程自动化。但是,与自动机器学习算法以及传统表格机器学习不同的是,表格基础模型完全省去了模型训练的环节。这听起来可能好得令人难以置信,但这正是霍尔曼及其同事所构建的那种基础模型。
作者们开发的基础模型名为TabPFN,而且它的效果非常显著。它可以获取用户的数据集,并立即对新的数据点(比如刚到你假设的那家医院的患者)做出推断。通过一系列实验,霍尔曼等人发现,对于多达10000行、500列的数据集,TabPFN的表现始终优于其他机器学习方法(无论是自动的还是其他的)。它在处理诸如缺失值、异常值和无信息特征等常见数据问题方面,也比其他方法更为擅长。传统机器学习模型需要几分钟甚至几小时来进行训练,而TabPFN能在几分之一秒内就针对一个新数据集生成推断结果。
霍尔曼等人必须克服几个技术障碍才能让TabPFN发挥作用,其中有一个尤其值得强调。基础模型需要在大量数据上进行“预训练”,以便它们能够识别尚未遇到的数据中的模式。然而,并没有足够的表格数据可用于有效训练一个基础模型。例如,像OpenAI的GPT - 4这样的大型语言模型是在数千亿份文档(甚至更多)上进行预训练的,使用的数据源如“网络爬虫”(见commoncrawl.org)。相比之下,表格数据集非常少:Kaggle是最大的在线机器学习平台之一,它列出了大约40万个数据集(见kaggle.com),而且并非所有这些数据集都是表格形式的。
为克服这种数据稀缺的问题,霍尔曼等人反常地选择完全忽略真实数据集。相反,他们使用1亿个模拟真实数据统计特性的随机生成数据集对TabPFN进行预训练。换句话说,TabPFN并非基于真实数据构建,而是基于其开发者对真实数据行为方式的统计假设构建的。TabPFN的性能取决于这些假设的质量。
霍尔曼及其同事的方法存在一些局限性。首先,基础模型是“黑箱”:用户无法解读模型是如何做出推断的。其次,当前版本的TabPFN可能对超过10000行、500列的数据集无效。最后,TabPFN是此类工具中的首个,因此这一策略的其他局限性以及功能还有待发现。
TabPFN可能标志着表格机器学习领域根本性变革的开端。数据科学家和开发者通常要花费数年时间学习机器学习模型开发的技巧。一个有效的基础模型可以通过减少或消除对训练独特模型的需求来改变机器学习这一领域,这可能会让从业者将精力集中在诸如数据准备、模型评估和模型部署等任务上。这听起来可能过于乐观了,但回想一下,在不到十年的时间里,大型语言模型已经引发了自然语言处理领域的重大变革。尽管表格基础模型仍处于早期阶段,但表格机器学习领域类似的变革可能已经开始了。
doi: https://doi.org/10.1038/d41586-024-03852-x
《自然》第637卷,第274页
转载本文请联系原作者获取授权,同时请注明本文来自孙学军科学网博客。
链接地址:https://wap.sciencenet.cn/blog-41174-1468561.html?mobile=1
收藏