博文
Q&A on NLP: Chapter I Natural Language and Linguistic Form
||
Guo: Professor Li, to ease into the discussion, let us begin with some foundational concepts. What exactly do we mean by natural language? What falls under the scope of the field, and where does it sit within the broader discipline of Artificial Intelligence (AI)?
Li: Natural language refers to the everyday languages we humans speak—English, Russian, Japanese, Chinese, and so on; in other words, human language writ large. It is distinct from computer languages. Because human conversation is rife with ellipsis and ambiguity, processing natural language on a computer poses formidable challenges.
Within AI, natural language is defined both as a problem domain and as the object we wish to manipulate. Natural Language Processing (NLP) is an essential branch of AI, and parsing is its core technology—the crucial gateway to Natural Language Understanding (NLU). Parsing will therefore recur throughout this book.
Computational linguistics is the interdisciplinary field at the intersection of computer science and linguistics. One might say that computational linguistics supplies the scientific foundations, whereas NLP represents the applied layer.
AI is often divided into perceptual intelligence and cognitive intelligence. The former includes image recognition and speech processing. Breakthroughs in big data and deep learning have allowed perceptual intelligence to reach—and in some cases surpass—human‑expert performance. Cognitive intelligence, whose core is natural language understanding, is widely regarded as the crown jewel of AI. Bridging the gap from perception to cognition is the greatest challenge—and opportunity—facing the field today.
The rationalist tradition formalises expert knowledge using symbolic logic to simulate human intellectual tasks. In NLP, the classical counterpart to machine‑learning models comprises linguist‑crafted grammar rules, collectively called a computational grammar. A system built atop such grammars is known as a rule‑based system. The grammar school decomposes linguistic phenomena with surgical precision, aiming at a deep structural analysis. Rule‑based parsing is transparent and interpretable—much like the diagramming exercises once taught in a language school.
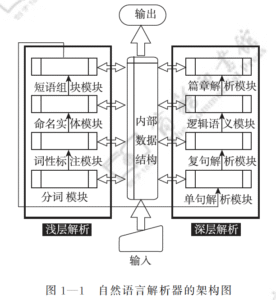
Figure 1‑1 sketches the architecture of a natural‑language parser core engine. Without dwelling on minutiae, note that every major module—from shallow parsing through deep parsing—can, in principle, be realised via interpretable symbolic logic encoded as a computational grammar. Through successive passes, the bewildering diversity of natural language is reduced first to syntactic relations and then to logical‑semantic structure. Since Chomsky’s distinction between surface structure and deep structure in late 50s, this layered view has become an orthodoxy within linguistics.
Guo: These days everyone venerates neural networks and deep learning. Does the grammar school still have room to live? Rationalism seems almost voiceless in current NLP scholarship. How should we interpret this history and the present trend?
Li: Roughly thirty years ago, the empiricist school of machine learning began its ascent, fuelled by abundant data and ever‑cheaper computation. In recent years, deep neural networks have achieved spectacular success across many AI tasks. Their triumph reflects not only algorithmic innovation but also today’s unprecedented volumes of data and compute.
By contrast, the rationalist programme of symbolic logic has waned. After a brief renaissance twenty years ago—centred on unification‑based phrase‑structure grammars (PSGs)—computational grammar gradually retreated from the mainstream. Many factors contributed; among them, Noam Chomsky’s prolonged negative impact warrants sober reflection.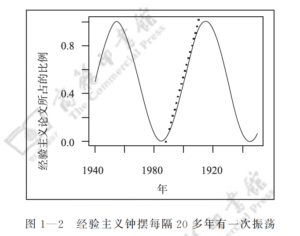
History reveals a pendulum swing between empiricism and rationalism. Kenneth Church famously illustrated the motion in his article A Pendulum Swung Too Far (Figure 1-2).
For three decades, the pendulum has tilted toward empiricism (black dots in Figure 1‑2); deep learning still commands the spotlight. Rationalism, though innovating quietly, is not yet strong enough to compete head‑to‑head. When one paradigm dominates, the other naturally fades from view.
Guo: I sense some conceptual confusion both inside and outside the field. Deep learning, originally just one empiricist technique, has become synonymous with AI and NLP for many observers. If its revolution sweeps every corner of AI, will we still see a rationalist comeback at all? As Professor Church warns, the pendulum may already have swung too far.
Li: These are two distinct philosophies with complementary strengths and weaknesses; neither can obliterate the other.
While the current empiricist monoculture has understandable causes, it is unhealthy in the long run. The two schools both compete and synergise. Veterans like Church continue to caution against over‑reliance on empiricism, and new scholars are probing deep integrations of the two methodologies to crack the hardest problems in NLU.
Make no mistake: today’s AI boom largely rests on deep‑learning breakthroughs, especially in image recognition, speech, and machine translation. Yet deep learning inherits a fundamental limitation of the statistical school—its dependence on large volumes of labelled data. In many niche domains—for instance, minority languages or e‑commerce translation—such corpora are simply unavailable. This knowledge bottleneck severely constrains empiricist approaches to cognitive NLP tasks. Without data, machine learning is a bread‑maker without flour; deep learning’s appetite as we all know is insatiable.
Guo: So deep learning is no panacea, and rationalism deserves a seat at the table. Since each paradigm has its merits and deficits, could you summarise the comparison?
Li: A concise inventory helps us borrow strengths and shore up weaknesses.
Advantages of machine learning
Requires no domain experts (but does require vast labelled data).
Excels at coarse‑grained tasks such as classification.
High recall.
Robust and fast to develop.
Advantages of the grammar school
Requires no labelled data (but does require expert rule writing).
Excels at fine‑grained tasks such as parsing and reasoning.
High precision.
Easy to localise errors; inherently interpretable.
Li: Rule‑based systems shine at granular, line‑by‑line dissection, whereas learned statistical models are naturally strong at global inference. Put bluntly, machine learning often "sees the forest but misses the trees," while computational grammars "see each tree yet risk losing the forest." Although data‑driven models boast robustness and high recall, they may hit a precision ceiling on fine‑grained tasks. Robustness is the key to surviving anomalies and edge cases. Expert‑coded grammars, by contrast, attain high precision, but boosting recall can require many rounds of iterative rule writing. Whether a rule‑based system is robust depends largely on its architectural design. Its symbolic substrate renders each inference step transparent and traceable, enabling targeted debugging—precisely the two pain‑points of machine learning, whose opaque decisions erode user trust and hamper defect localisation. Finally, a learning system scales effortlessly to vast datasets and its breakthroughs tend to ripple across an entire industry. Rule‑based quality, by contrast, hinges on the individual craftsmanship of experts—akin to Chinese cuisine, where identical ingredients may yield dishes of very different calibre depending on the chef.
Both routes confront knowledge bottlenecks. One relies on mass unskilled labour (annotators), the other on a few skilled artisans (grammar experts). For machine learning, the bottleneck is the supply of domain‑specific labelled data. The rationalist route simulates human cognition and thus avoids surface‑level mimicry of datasets, but cannot escape the low efficiency of manual coding. Annotation is tedious yet teachable to junior workers; crafting and debugging rules is a costly skill to train and hard to scale. Talent gaps exacerbate the issue—three decades of empiricist dominance have left the grammar school with a thinning pipeline.
Guo: Professor Li, a basic question: grammar rules are grounded in linguistic form. If semantics is derived from that form, then what exactly is linguistic form?
Li: This strikes at the heart of formalising natural language. All grammar rules rest on linguistic form, yet not every practitioner—even within the grammar camp—has a crisp definition at hand.
In essence, natural language as a symbolic system expresses meaning through form. Different utterances of an idea vary only in form; their underlying semantics and logic must coincide, else communication—and translation—would be impossible. The intuition is commonplace, but pinning down "form" propels us into computational linguistics.
Token & Order — The First‑Level AbstractionAt first glance a sentence is merely a string of symbols—phonemes or morphemes. True, but that answer is too coarse. Every string is segmented into units called tokens (words or morphemes). A morpheme is the smallest pairing unit of sound and meaning. Thus our first abstraction decomposes linguistic form into a sequence of tokens plus their word order. Grammar rules define patterns that match such sequences. The simplest pattern, a linear pattern, consists of token constraints plus ordering constraints.
Guo: Word order seems straightforward, but tokens and morphemes hide much complexity.
Li: Indeed. Because tokens anchor the entire enterprise, machine‑readable dictionaries become foundational resources. (Here "dictionary" means an electronic lexicon.)
If natural language were a closed set—say only ten thousand fixed sentences—formal grammar would be trivial: store them all, and each complete string would serve as an explicit pattern. But language is open, generating unbounded sentences. How can a finite rule set parse an infinite language?
The first step is tokenisation—dictionary lookup that maps character strings to lexicon words or morphemes. Unlimited sentences decompose into a finite vocabulary plus occasional out‑of‑dictionary items. Together they form a token list, the initial data structure for parsing.
We then enter classic linguistic sub‑fields. Morphology analyses the internal structure of multi‑morphemic words. Some languages exhibit rich morphology—noun declension, verb conjugation—e.g., Russian and Latin; others, such as English and Chinese, are comparatively poor. Note, however, that Chinese lacks inflection but excels at compounding. Compounds sit at the interface of morphology and syntax; many scholars treat them as part of "little syntax" rather than morphology proper.
Guo: Typologists speak of a spectrum—from isolating languages such as Classical Chinese (no morphology) to polysynthetic languages like certain Native American tongues (heavy morphology). Most languages fall between, with Modern Chinese and English leaning toward the isolating side: minimal morphology, rich syntax. Correct?
Li: Exactly. Setting aside the ratio of morphology to syntax, our first distinction is between function words/affixes versus content words. Function words (prepositions, pronouns, particles, conjunctions, original adverbs, interrogatives, interjections) and affixes (prefixes, suffixes, endings) form a small, closed set.
Content words—nouns, verbs, adjectives, etc.—form an open set forever producing neologisms; a fixed dictionary can hardly keep up.
Because function words and affixes are frequent yet limited, they can be enumerated as literals in pattern matching. Hence we have at least three grain‑sizes of linguistic form suitable for rule conditions: (i) word order; (ii) function‑word literals or affix literals; (iii) features.
Features — The Implicit FormExplicit tokens are visible in the string, but parsers also rely on implicit features—category labels. Features encode part‑of‑speech, gender, number, case, tense, etc. They enter pattern matching as hidden conditions. Summarising: automatic parsing rests on (i) order, (ii) literals, (iii) features—two explicit, one implicit. Every language weaves these three in different proportions; grammar is but their descriptive calculus.
Guo: By this metric, can we say European languages are more rigorous than Chinese?
Li: From the standpoint of explicit form, yes. European tongues vary internally—German and French more rigorous than English—but all possess ample explicit markers that curb ambiguity. Chinese offers fewer markers, increasing parsing difficulty.
Inflectional morphology supplies visible agreement cues—gender‑number‑case for nouns, tense‑aspect‑voice for verbs. Chinese lacks these. Languages with rich morphology enjoy freer word order (e.g., Russian). Esperanto’s sentence "Mi amas vin" (I love you) can permute into six orders because the object case ‑n never changes.
Chinese, conversely, evolved along the isolating path, leveraging word order and particles. Even so, morphology provides tighter agreement than particles. Hence morphology‑rich languages are structurally stringent, reducing reliance on implicit semantics.
Guo: People call Chinese a "paratactic" language—lacking hard grammar, leaning on meaning. Does that equate to your notion of implicit form?
Li: Precisely. Parataxis corresponds to semantic cohesion—especially collocational knowledge within predicate structures. For example, the predicate "eat" expects an object in the food category. Such commonsense often lives in a lexical ontology like HowNet (founded by the late Professor Dong Zhendong).
Consider how plurality is expressed. In Chinese, "brother" is a noun whose category is lexically stored. Esperanto appends ‑o for nouns and ‑j for plural: frato vs. fratoj. Chinese may add the particle 们 (‑men), but this marker is optional and forbidden after numerals: "三个兄弟" (three brothers) not "*三个兄弟们". Here plurality is implicit, inferred from the numeral phrase.
Guo: Lacking morphology indeed complicates Chinese. Some even claim Chinese has no grammar.
Li: That is hyperbole. All languages have grammar; Chinese simply relies more on implicit forms. Overt devices—morphology, particles, word order—are fewer or more flexible.
Take omission of particles as an illustration. Chinese frequently drops prepositions and conjunctions. Compare:
对于这件事, 依我的看法, 我们应该听其自然。As for this matter, in my opinion, we should let nature take its course.
这件事我的看法应该听其自然。* this matter my opinion should let nature take its course.(Unacceptable as a word‑for‑word English rendering.)
Example 2 is ubiquitous in spoken Chinese but would be ungrammatical in English. Systematic omission of function words exacerbates NLP difficulty.
Guo: What about word order? Isolation theory says morphology‑poor languages have fixed order—Chinese is labelled SVO.
Li: Alas, reality defies the stereotype. Despite lacking morphology and often omitting particles, Chinese exhibits remarkable word‑order flexibility. Consider the six theoretical permutations of S, V, and O. Esperanto, with a single object case marker ‑n, allows all six without altering semantics. Compare English (no case distinction for nouns, but marking subject pronouns from obect cases) and Chinese (no case at all):
| Order | Esperanto | English | Chinese |
| SVO | Mi manĝis fiŝon | I ate fish | 我吃了鱼 |
| SOV | Mi fiŝon manĝis | * I fish ate | 我鱼吃了 |
| VOS | Manĝis fiŝon mi | * Ate fish I | ?吃了鱼我 |
| VSO | Manĝis mi fiŝon | * Ate I fish | * 吃了我鱼 |
| OVS | Fiŝon manĝis mi | * Fish ate I | ?鱼吃了我 |
| OSV | Fiŝon mi manĝis | Fish I ate | 鱼我吃了 |
Chinese sanctions three orders outright, two marginally (marked “?”), and forbids one (“*”). English allows only two. Thus Chinese word order is about twice as free as English, even though English possesses case distinction on pronouns. Hence morphology richness does not always guarantee order freedom.
Real corpora confirm that Chinese is more permissive than many assume. Greater flexibility inflates the rule count in sequence‑pattern grammars: every additional order multiplies pattern variants. Non‑sequential constraints can be encoded inside a single rule; order itself cannot.
A classic example is the elastic placement of argument roles around "哭肿" (cry‑swollen):
张三眼睛哭肿了。眼睛张三哭肿了。哭肿张三眼睛了。张三哭肿眼睛了。哭得张三眼睛肿了。张三哭得眼睛肿了。…and so on.
Such data belie the notion of a rigid SVO Chinese. Heavy reliance on implicit form complicates automatic parsing. Were word order fixed, a few sequence patterns would suffice; flexibility forces exponential rule growth.

https://wap.sciencenet.cn/blog-362400-1486798.html
上一篇:MeanFlow: AI图像生成的降维打击
下一篇:Decoding the New EMPO Reasoning Paradigm