
以往人们总是觉得,年龄越大,离疾病和死亡就越近,判断健康状况主要看身份证上的岁数,也就是实际年龄(chronological age )。但现在科学家发现,用体检报告里的常规数据,比如身高、体重、血压、血糖这些,就能算出一个更靠谱的 “生物学年龄”,这个就是表型生物钟或表型时钟。
举个例子,同样是60岁的两个人,一个经常健身、体检指标正常,另一个抽烟喝酒、多项指标超标。用表型时钟一算,可能前者的“生物学年龄”只有50岁,后者的 “生物年龄” 已经70岁了。而且大量研究证明,用表型时钟算出来的这个“生物年龄”,比单纯看实际岁数,更能准确预测一个人未来得病、甚至去世的风险。现在很多生物钟研究都在深挖细胞里的基因数据(甲基化数据),但表型时钟就像一个实用的助手,直接用医院里能测到的普通数据,快速帮我们了解身体的真实衰老程度,给健康提前拉响警报。
以前大家都觉得,用一个人活了多少年(实际年龄)就能判断他去世的风险,比如 60 岁肯定比40岁更容易生病去世。但Drs. Klemera和Doubal用身高、体重、血压、血糖这些医院常规体检数据,计算出每个人专属的“生物年龄”,并证明这个“生物年龄” 比实际年龄更能准确预测一个人什么时候会去世。打个比方,两个都是 50 岁的人,A 先生体检各项指标都正常,B 先生有高血压、高血脂。用体检数据算出 A 先生的“生物年龄”可能只有 45 岁,B 先生的“生物年龄”已经58岁了,那显然B先生未来的健康风险更高。
从这以后,科学家研究表型模型(用体检数据预测健康的方法)时,开始用数学工具来计算风险,最常用的是比例风险模型,例如:Gompertz死亡模型(是一种用于描述生物群体死亡规律的数学模型。由英国数学家Benjamin Gompertz提出。该模型认为,随着年龄增长,个体的死亡率会以指数形式上升。在一定年龄段后,每过若干年,死亡率会按一定比例增加。它常被应用于人口学、流行病学以及人寿保险等领域,帮助分析和预测群体的死亡情况,为相关决策提供依据)。这些模型就像超级计算器,把实际年龄、体检指标这些数据输进去,就能计算出死亡风险。
在Klemera和Doubal方法之前,大多数表型模型主要分为三类:1. 多元线性回归(multiple linear regression,MLR),2. 主成分分析(principal component analysis, PCA),3. Hochschild方法。MLP模型根据生物标志物与实际年龄的相关性来选择生物标志物,找出那些和实际年龄关系紧密的体检指标,比如血压、血糖等,把它们和年龄一起放进模型里计算。这种方法操作起来简单,但有较大问题是在回归边界(即最年轻和最年长的年龄)上会产生生物年龄扭曲;PCA生物钟避免了回归边界上的扭曲,但无法避免实际年龄差异带来的矛盾(paradox of age);Hochschild方法能解决实际年龄的矛盾,但实施起来很难标准化且比较复杂。Klemera和Doubal方法对上述每种方法都进行了改进,通过最小化每个生物标志物点回归线之间的距离来解决衰老的矛盾问题,相较于实际年龄,能更好地估算死亡率。
尽管人工神经网络在表观遗传时钟中得到了广泛应用,但在表型时钟中却很少被用到。一项研究使用了由21个不同结构和深度的深度神经网络(DNN)组成的集成,仅通过生理生物标志物来预测实际年龄。该模型还并联了一种基于特征重要性包装器的策略(称为排列特征重要性Permutation Feature Importance , PFI)相结合,使作者能够确定哪些变量在模型中最具影响力,该模型取得了令人印象深刻的预测性能(r = 0.91),但此实验中使用的数据集并非开源,因此,别人无法复现。
简言之,很多研究衰老的表型时钟模型都爱用线性模型,因为线性模型特别好理解。就像一本打开的书,模型里的 “系数” 就是文字,能直接告诉你每个因素(特征)对结果的影响。比如预测衰老程度时,系数大的因素,就说明它对衰老影响更大,通过这些系数,我们能一下子明白模型是怎么得出预测结果的。而人工神经网络就像一个黑盒子,输入数据进去,出来结果,但很难知道里面到底怎么运作。
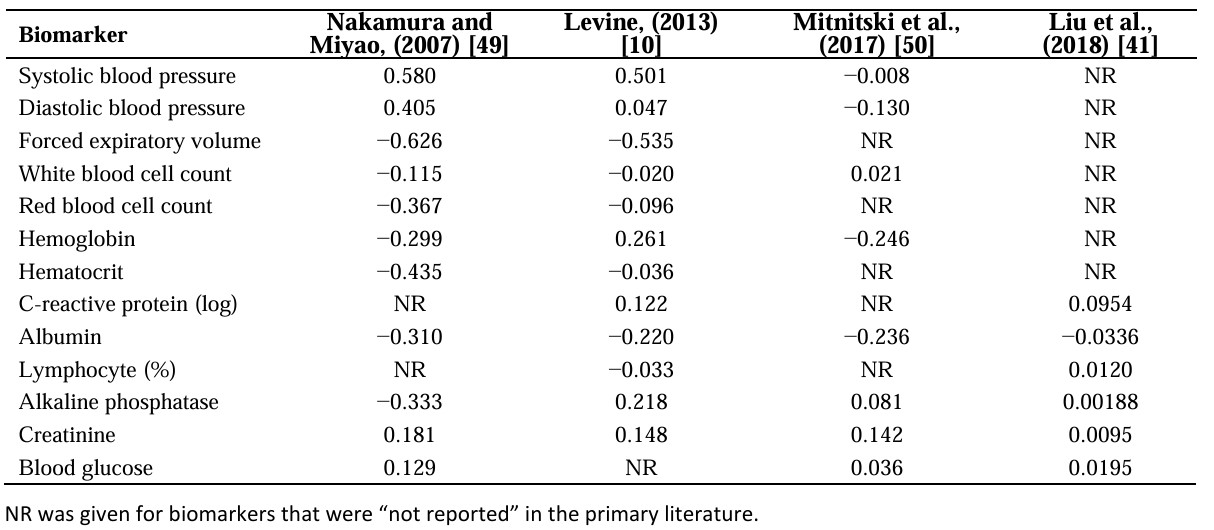
有趣的是,很多研究衰老的表型时钟模型,都发现了同样重要的血浆生物标志物,这些标志物被认为在衰老过程里起了大的作用。后来,科学家把不同表型时钟模型里的系数拿出来分析,想找出哪些血浆标志物在各研究里都被认为很重要。不过,他们也发现,同样的血浆生物标志物,在不同模型里的系数大小并不一样。这就好比同样是盐,放在不同菜谱(模型)里,用量(系数)会因为其他配料(模型里的其他特征)不同而变化。血浆生物标志物一直被认为是对衰老很有影响力。
通过观察我们身体能直接检测到的指标(比如血压、血糖这些表型数据),就能比较准确地判断我们衰老的情况,甚至预测我们的死亡风险 。虽然,很多研究都在关注甲基化数据来研究衰老,但其实通过身体能直接检测到的这些指标,也能很好地预测衰老和死亡。
表型数据有很多好处:第一,不仅能大概反映出我们身体衰老的整体情况,还能让医生了解我们身体当下具体的健康状态;第二,像血压、血脂这些表型指标的变化,和我们身体器官、细胞的功能是紧密相关的,而这些又直接影响到我们能活多久、活得好不好;第三,如果发现这些表型指标不太正常,我们可以通过调整生活习惯、改变饮食,在比较短的时间内让指标变好;第四,测血压、查血糖这些检查,价格便宜,也不需要特别复杂的技术和设备,比检测基因数据要方便得多。
所以,用表型数据构建的 “表型时钟”,比用基因数据构建的 “表观遗传时钟” 更容易在医院和日常生活中推广使用。患者也更容易理解跟踪自己表型年龄的好处,医生也能用这些数据更好地判断我们的健康状况。
临床血浆生物标志物及其各自的回归系数
转载本文请联系原作者获取授权,同时请注明本文来自阎影科学网博客。
链接地址:https://wap.sciencenet.cn/blog-3302154-1485127.html?mobile=1
收藏