博文
[资料,科普,琐记] 相关性指标 correlation, similarity,数理统计学,小样本(置信区间):要点
||
[资料,科普,琐记] 相关性指标 correlation, similarity,数理统计学,小样本(置信区间):要点
一、现有的相关性指标 similarity indices
罗列一些如下(含距离):
The Pearson Product-Moment Correlation Coefficient,
Manhattan distance, Euclidean distance, Cosine coefficient, Dice coefficient, Tanimoto coefficient, Soergel distance, 以及
mutual information, maximal information coefficient (MIC),
Spearman Rank Correlation (Spearman’s Rho), Kendall’s Tau (Kendall Rank Correlation Coefficient), Hoeffding D statistic,
Chebyshev distance, Wasserstein distance, dynamic time warping (DTW),
……
感谢您提供更多的“相关性/距离”计算方法或指标。
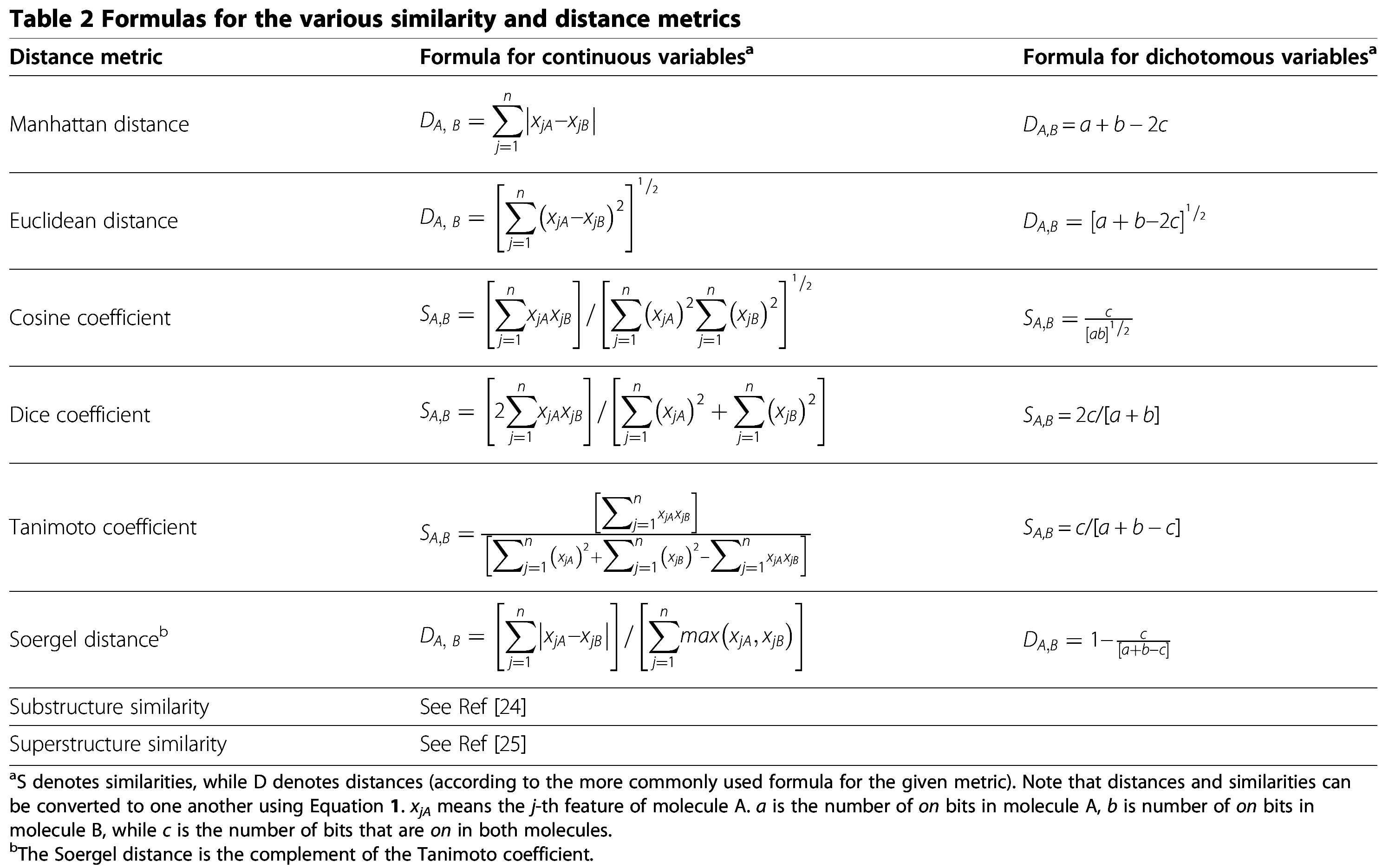
图1 常用的一些“相关性/距离”计算方法或指标
https://jcheminf.biomedcentral.com/articles/10.1186/s13321-015-0069-3/tables/2
https://jcheminf.biomedcentral.com/articles/10.1186/s13321-015-0069-3
二、我们的新“相关性指数 similarity index”
2018年7月,我们公开提出了一个新的“相关性指数 similarity index”,如下。尽管比较好用,但长相是丑了点。

图2 2018-07,我们提出的一个新的“相关性/距离”计算指标
https://ieeexplore.ieee.org/document/8630700
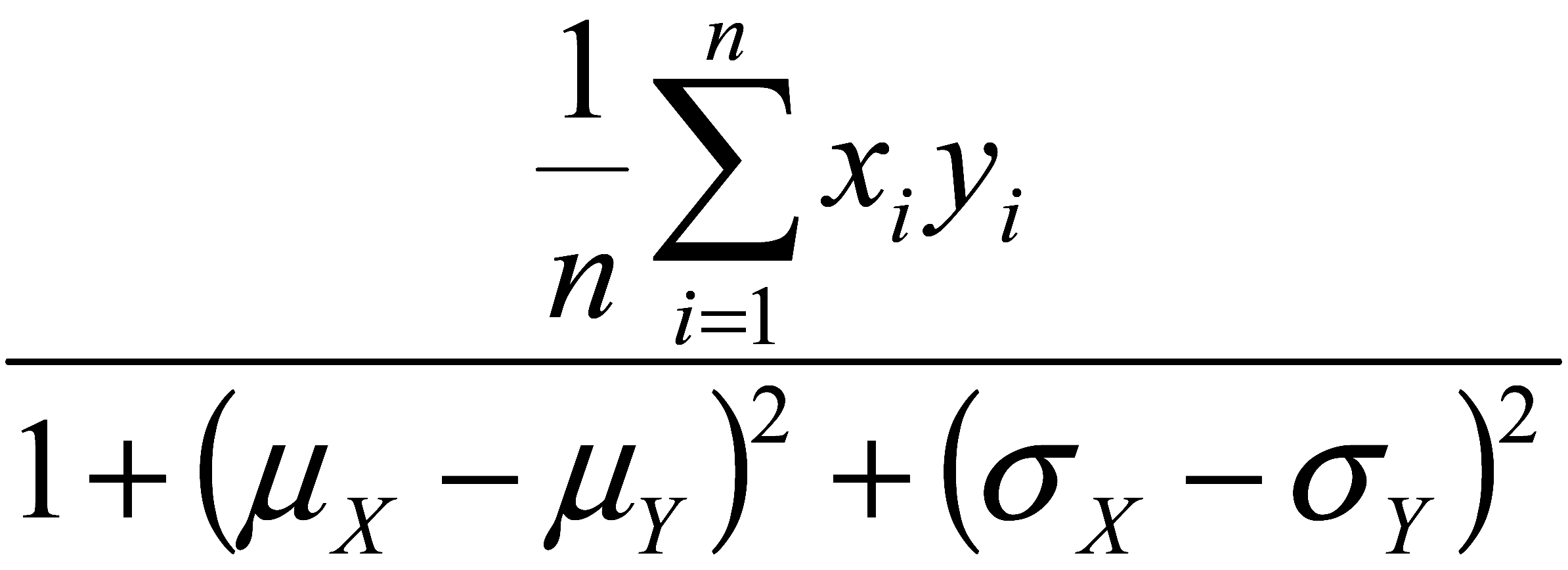
这里,分母里的“1”是为了避免“分母 denominator = 0”加入的。可以为别的“正实数”。
三、汇报:目前忙什么?
(1)近期,主要“忙于”得病。
旧病加重。多处不适。
(2)2025-08-19,早晨在学四食堂买“豆腐脑”,居然忘了付钱。经过食堂的男师傅提示,我才想起付钱:人民币 2元。
累成这个样子,实在是因为身体太不理想了。我可是真没打算白吃啊!
正是该日(2025-08-19)早晨睡醒后,终于下决心提出一个新的相关性指标。
可是,由于身体等原因,一直没能用计算机程序进行“置信区间”方面的数值实验。时间流逝得真快啊!
学到老,活到老。
病的绝望;
活出凄凉;
恸哭苍凉,
怆然涕下!
木犹如此,人何以堪!

图3 4847470943_5cbc527148_o.jpg
https://farm5.staticflickr.com/4105/4847470943_5cbc527148_o.jpg
参考资料:
[1] 武夷山,2015-01-23,“大概近似正确”的评价 ![]() 精选
精选
http://blog.sciencenet.cn/blog-1557-861961.html
第三,理论自身可能有错误。例如,科学计量学领域的作者同被引分析早在20世纪70年代已现端倪,同被引分析的一个步骤是测度相似性,人们曾用皮尔逊相关系数来测度相似性,而直到2003年,人们才指出这是错误的。
第四,算法出错。引文只是质量的替代指标,而人们经常用引文指标作为评价算法的输出变量,有时候就会得出错误的结果,比如,Bouyssou & Marchant于2011发表的文章, Waltman & van Eck于 2012年发表的文章,都指出了h指数的一些问题。
[2] 陈希孺院士,1998,《数理统计学简史》第276页。长沙:湖南教育出版社,2002
[3] Per Ahlgren, Bo Jarneving, Ronald Rousseau. Requirements for a co-citation similarity measure, with special reference to Pearson's correlation coefficient, Journal of the Association for Information Science & Technology, 2003, 54(6): 550–560, 2003.
doi: 10.1002/asi.10242
http://onlinelibrary.wiley.com/doi/10.1002/asi.10242/abstract
[4] Dávid Bajusz, Anita Rácz, Károly Héberger. Why is Tanimoto index an appropriate choice for fingerprint-based similarity calculations? [J]. Journal of Cheminformatics, 2015, 7(20): 161-169
doi: 10.1186/s13321-015-0069-3
https://jcheminf.biomedcentral.com/articles/10.1186/s13321-015-0069-3
[5] 杨正瓴,2018-06-22 00:12,慎用“机器学习中的数据预处理:缩放和中心化”
https://idea.cas.cn/zhhh/gcjskxygjs/gcjskxygjs_dzyxx/info/2018/510794.html
关于“相关性/距离”指标,与“因果性”关系的一个直观例子。该例子未经计算机程序验证,只是想通过“打比方”说明一些可能性。
问题:在《红楼梦》里,找出“贾宝玉”的亲属。
按照《红楼梦》,“甄宝玉”与“贾宝玉”长相十分接近,但并无血缘关系;贾宝玉的若干位叔伯兄弟,之间长相有些相似(个头大小也很像);贾宝玉和儿子贾桂,个头相差不少,但长相“按照比例系数缩小”后相似。
贾宝玉的“最相似”:
①按照“DTW,Dynamic Time Warping,动态时间归整”距离,大概“甄宝玉”最像;
②按照“欧几里得距离,Euclidean Distance”,大概贾宝玉的那些叔伯兄弟最像;
③按照“Pearson相关系数,Pearson product-moment correlation coefficient”,大概“贾桂”最像。
所以,“相关性”不直接等于“因果性”。“相关性”查找的结果,与采用的具体的“相关性/距离”指标有直接的联系。
因此,在机器学习、数据挖掘里,“相关性/距离”具体指标的选用,是个值得思考的问题。
2018-09-21 11:30:29

以前的《科学网》相关博文链接:
[1] 2020-06-17 13:30,敬请慎重使用和看待“数据统计与分析”的结果
https://blog.sciencenet.cn/blog-107667-1238236.html
[2] 2020-08-18 14:01,没有真正“小样本”数理统计学的世界,了无生趣
https://blog.sciencenet.cn/blog-107667-1246844.html
[3] 2018-08-18 15:06,“大数据”时期,更渴望“小样本数理统计学”
https://blog.sciencenet.cn/blog-107667-1129894.html
[4] 2024-08-26 22:18,[宇宙科学院] 牛顿论题:万有引力常数G不是常数,而是随材料、温度、压力等多种条件变化的变量。
https://blog.sciencenet.cn/blog-107667-1448299.html
[5] 2021-07-13,[困惑与求证] 线性归一化 Normalization、标准化 Standardization 是否会引起额外的误差?
https://blog.sciencenet.cn/blog-107667-1295337.html
[6] 2021-07-14 15:59,“归一化引起数据挖掘额外误差”(牛顿猜想)的一个糟糕的确定型证明尝试
https://blog.sciencenet.cn/blog-107667-1295438.html
感谢您的指教!
感谢您指正以上任何错误!
感谢您提供更多的相关资料!
https://wap.sciencenet.cn/blog-107667-1502725.html
上一篇:[讨论,科普] 什么是数学证明? (关联:演绎、归纳、完全归纳、合情推理)
下一篇:[汇报,科普] 为什么要研究新的“相关性/距离”指标(1) (关联:数据挖掘、机器学习、数理统计学)