博文
机器学习预测个体治疗反应面临障碍
|
使用机器学习预测个体治疗反应面临障碍
精准医疗承诺根据个体患者情况量身定制治疗。机器学习模型被誉为加速精准医疗的工具,它通过筛选大量复杂数据来精确定位遗传、社会人口学或生物标志物,从而在正确的时间为正确的人预测正确的治疗。然而,最初对这些高级预测工具的热情现在正面临着发人深省的现实检查。在本期的第 164 页,Chekroud 等人。(1)表明,在一项临床试验中预测精神分裂症患者对抗精神病药物治疗反应的机器学习模型未能推广到新的、看不见的临床试验的数据。这些发现不仅强调了对机器学习方法制定更严格的方法标准的必要性,而且还需要重新审视精准医疗面临的实际挑战。
使用机器学习进行个体治疗预测
用于个体治疗预测的监督机器学习基于分类器的开发。为了防止过度拟合,模型验证至关重要,通常通过交叉验证或样本外验证来实现。样本外验证需要一个完全独立的数据集,并且更耗费资源,但这种方法不易受到过度拟合的影响,并且可以提供更普遍的结果。
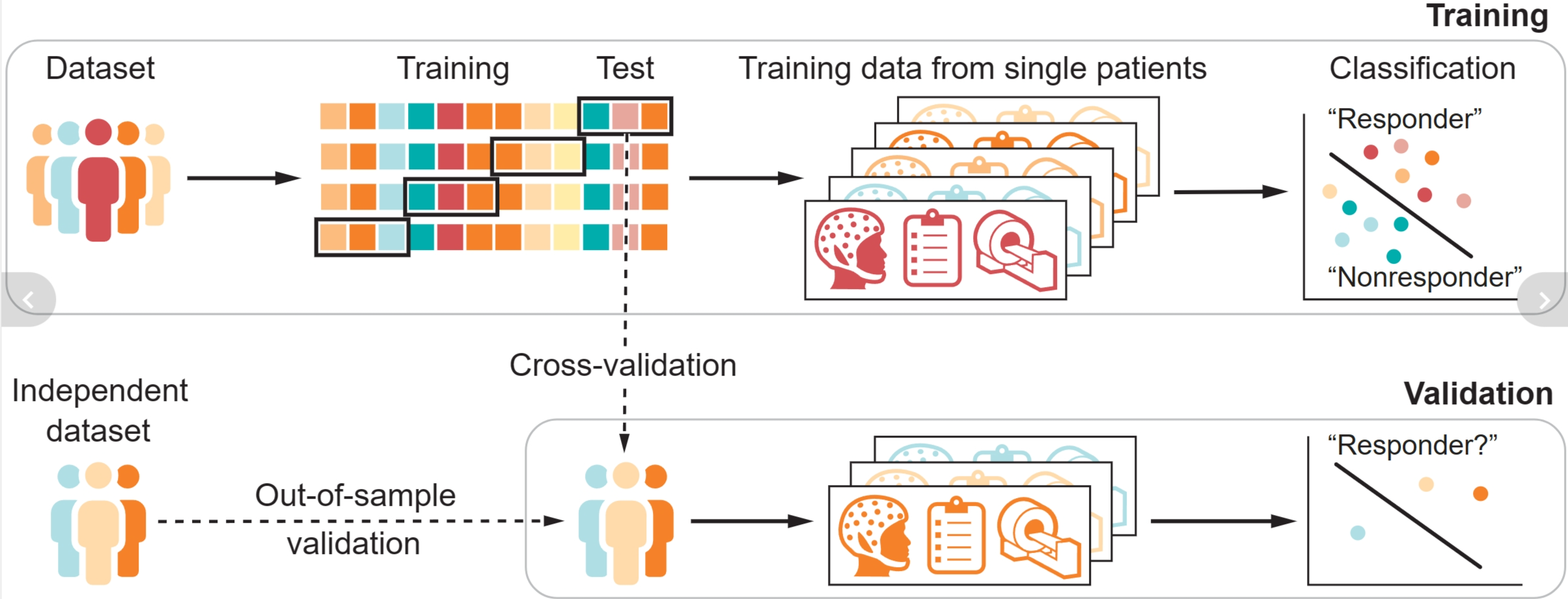
Practical challenges for precision medicine | Science
什么可以预测患者是否会从特定治疗中受益?答案可能在于他们的遗传学、生物学、社会人口学背景、社会环境、过去的经历或无数其他潜在因素。机器学习技术能够分析大型数据集,并确定最有效的特征组合,以准确预测感兴趣的变量。因此,它们为发现预测个体治疗反应的相关特征或生物标志物提供了一条有希望的途径。通常,这涉及在数据集上训练模型,该数据集的结果(例如对给定治疗的反应)是已知的。这被称为监督学习。这种方法的一个常见缺陷是过拟合。当模型相对于其训练数据过于灵活时,就会发生过拟合,这限制了其泛化性。过度拟合的一个迹象是,模型准确地预测了它所训练的数据的结果,但在新的、看不见的数据上表现不佳。为了解决过拟合问题,必须在看不见的数据上验证模型。交叉验证是用于此目的的一种广泛使用的技术。它涉及将数据重复划分为子集,在一个子集上训练模型,然后评估其对剩余“保留”数据的预测准确性(见图)。
但是,交叉验证并非万无一失。Chekroud 等人。结果显示,在使用交叉验证的特定临床试验中,经过训练以预测精神分裂症患者对抗精神病药物反应的模型未能预测其他独立临床试验中的治疗反应。交叉验证可能无意中导致对保留数据进行过度拟合的一个原因是,建模者通过迭代模型调整,最终可能会使用所有可用数据。这个问题可能比通常承认的更普遍。例如,对116项涉及各种精神病学诊断的研究的综合回顾发现了过度拟合的迹象,特别是在样本量小(<50名受试者)的研究中(2)。小样本量也会导致交叉验证结果出现较大差异,尽管这些问题在统计学和机器学习中是众所周知的,但许多研究仍然没有遵循最佳实践来改善交叉验证的结果 (3)。
确保机器学习模型的泛化性的可靠方法在于,在真正独立的、未触及的验证样本(称为样本外验证)上验证其预测准确性。通常,这种方法不用于临床研究,因为与获取更大的数据集相关的挑战以及需要严格的数据采集和使用规则。然而,Chekroud 等人的研究。越来越多的证据强调了这些更强大的验证标准的必要性,以避免机器学习模型过于乐观的结果,因为机器学习模型无法推广到更广泛的临床环境。
即使模型经过适当验证并得到大样本量的支持,预测个体患者的临床结果或治疗反应的尝试也可能不可靠。在Chekroud等人的研究中,即使汇集了来自多个临床试验的数据来训练模型,其预测仍然未能推广到新的独立试验中。造成这种情况的原因是复杂和多方面的。一个主要因素是临床人群数据的固有异质性。这个问题在精神疾病中尤为突出,精神疾病通常由一系列症状(综合征)定义。具有相同诊断标签的患者可能表现出截然不同的症状特征,需要不同的治疗。此外,不同个体的相同症状可能具有不同的生物学基础,因此需要不同的治疗策略 (4)。纯粹基于诊断标签的机器学习模型而不考虑这种类型的异质性,可能会导致在预测有效治疗策略时不准确。
应对这一挑战的一种有前途的方法是将患者分为更精确定义的类别,例如,基于潜在的症状原因。这在一定程度上可以通过使用理论驱动的计算模型来实现,这些模型旨在描述潜在的疾病机制,这种方法在计算精神病学领域越来越受欢迎。这些模型越来越多地与数据驱动的机器学习技术一起使用,形成了解决患者群体异质性问题的强大工具 (5, 6)。
另一种形式的异质性可能源于不同研究、地点或时间点的系统性差异。因此,根据特定上下文(人口、国家、环境或时间段)的数据训练的机器学习模型的预测可能依赖于与给定研究中的临床结果相关但无因果关系的特征,但在其他上下文中无法预测。解决这种异质性的一种方法是跨多个研究和研究中心汇集数据。
不可靠的预测也可能是过时的结果测量的结果。许多现有的症状评分基于问卷,这些问卷可能不再与对疾病的理解保持一致,并可能导致对治疗反应的不准确评估。例如,Chekroud 等人在临床试验中使用的阳性和阴性综合征量表 (PANSS)。正在逐渐被更现代的评估工具所取代,特别是在精神分裂症阴性症状的背景下(7)。如果问卷未能完全反映真正的疾病负担,它可能无法准确检测治疗带来的真正改善。这种差异可能导致对谁从治疗中受益或未从治疗中受益的错误分类,从而阻碍机器学习模型的准确训练。与诊断类别中的异质性类似,随着对潜在疾病机制的深入了解,结果测量将变得更加准确。
使用机器学习来预测医学中的个体治疗反应的挑战,特别是在精神病学的背景下,源于与模型验证标准、诊断异质性以及所用结果测量的相关性相关的问题的复杂相互作用。应对这些挑战对于有影响力的临床研究和实现有效的精准医疗至关重要。
https://wap.sciencenet.cn/blog-41174-1417893.html
上一篇:谷歌AI水平超过人类医生
下一篇:自动驾驶技术跨界培训蛋白质