
 精选
精选
“神奇”纠错方案被证实本质上低效
局域可纠正编码在修复错误时需要的信息很少,但它们极其之长。如今我们认识到,哪怕是最简单的版本也没法缩短了。
Ben Brubaker 著
左 芬 译
【译注:原文2024年1月9日刊载于QuantaMagazine,链接见文末。】

如果你曾经发送过文本消息,播放过CD,或者云存储过文件,你就从纠错中受益过。这一开创性想法起源于1940年代,当时研究者首次意识到可以将任何消息写成一种特定形式,使得后续的损坏能被轻易修复。
随着时间的推移,研究者们发展了多种精巧的方案来以不同的方式编码数据,并用不同的过程来修复错误。它们被称为纠错码。但在理论计算机科学家看来,最引人入胜的是所谓局域可纠正编码。这些编码同时具有两条看似近乎矛盾的性质:任何错误都只需要在少量位置阅读编码的数据来纠正,并且任何攻击者都不能通过有选择性地篡改编码来扰乱这一纠错过程。这就好像你只要翻一下书中其它几页就可以把撕去的任何一页恢复。
“这是一种神奇的现象,”剑桥大学计算机科学家Tom Gur说道,“事实上,这样一个数学对象竟然可以存在并不显然。”
但这一魔力是要付出不小的代价的。局域可纠正编码的已知实例全都极其低效——编码任何消息都会使它指数式地变长。用这种方式编码的整本书会极其笨重。
计算机科学家一直好奇是否存在更好的局域可纠正编码。他们特别聚焦于只使用三次查询来纠正任何错误的编码,寄希望于这一苛刻的约束会使得这些编码易于理解。但哪怕是这一简单情形也困惑了研究者们20多年了。
如今卡耐基梅隆大学的计算机科学家Pravesh Kothari与其研究生Peter Manohar终于证明,构建三查询局域可纠正编码无法避免指数式代价。这算是一个负面结果,但考虑到局域可纠正编码的数学已经在远离通信的领域里频繁出现这一特殊原因,任何澄清纠错极限的结果都让研究者们兴奋不已。
“这一结果很神奇,”多伦多大学计算机科学家Shubhangi Saraf说道,“这是一个巨大的突破。”
数字的强度
要理解纠错,设想你想保护的数据是一串比特,也就是0和1。这一模型中的错误可能是任何0到1或者反过来的有害翻转,不管它是源自随机扰动还是蓄意破坏。

Pravesh Kothari通过改造在逻辑表达式中识别矛盾的技术,证明了关于纠错码极限的一个新结果。
假定你想要发送一条消息给朋友,但又担心错误可能会改变其含义。一种简单的策略是,将消息中的每个0替换为000,而每个1替换为111。如果你的朋友发现消息的某一部分不是三个相同的比特出现在一行里,他们会知晓发生了一个错误。而如果错误是随机的且相对稀少,那么任何110串很可能是错自111而非000。每个三元组中一次简单的多数派投票就足以纠正大多数错误。
这一所谓重复码方案的优点在于简单,但别的方面就不值一提了。 首先,它用了三倍于任何消息的长度却只能处理相对不频繁的错误,而如果两个相邻错误出现的几率不小,我们还需要更多的冗余度。更糟糕的是,一旦错误不是随机的,比如当攻击者主动破坏编码时,它立即就失效了。在重复码里,用于纠正一个给定比特的所有信息都存储在仅仅几个其它比特里,使得它在定向攻击中很脆弱。
幸运的是,许多纠错码都可以做得更好。一个著名的例子是所谓Reed-Solomon码。它的工作方式是把消息转化为多项式——形如x2+3x+2的数学表达式,由多个项加起来,每一项带有变量(例如x)的不同幂次。使用Reed-Solomon码编码一条消息需要创建一个多项式,使得每一项对应消息中的每个字符,接着将多项式作图为曲线,并存储位于曲线上的点的坐标(选取的点数至少比字符数多一)。错误可能会把这些点中的一些拉离曲线,但如果错误不是非常多,只有一条多项式曲线可以穿过大多数点。那条曲线几乎肯定就对应于真实消息。
Reed-Solomon码超级高效——你只需存储少量额外的点来纠正错误,因此任何编码好的消息只比原始的稍微长一点。而且在给重复码带来灾难性后果的那种定向破坏下它们也没那么脆弱,因为用来纠正任何位置错误的信息都被散布到了整条编码消息了。
全局动脑,局部动手
Reed-Solomon码的强度源自互连性。但正因为这一互连性,要修复一条编码消息中的单一错误,你就必须得阅读全部内容。这在通信情况下听起来不成为一个问题:如果你发了消息,你当然想让接收者全部读完。但涉及到纠错的另一个主要应用——数据存储——它就有点烦人了。
考虑一个公司把用户的email存储在云端——也就是一个庞大的服务器阵列。你可以把email的全体视为一条长的消息。现在有一个服务器崩溃了。利用Reed-Solomon码,你得对所有编码数据进行冗长的计算才能恢复那台损失的服务器上的email。“你得检查一切,”普林斯顿大学计算机科学家Zeev Dvir说道,“那可能是数以亿计的email——需要花费大量时间。”
研究者们用“局域”这一术语来描述那些仅仅利用编码消息的片段就可以定位或纠正错误的编码。简单的重复码可以说拥有这种局域性,但这也正是让它易于破坏的原因。相反,局域可纠正编码则汇集了两个世界的优点——它既可以在少量查询下纠正任何比特上的错误,但又保留了让Reed-Solomon码如此坚韧的互连性。
“这是一个相当严格的概念,”Kothari称。

1954年,David E. Muller(左)与Irving S. Reed发明了一种编码数据的方法,使其能用非常少的信息来修复错误——付出的代价是消息会大幅延长。
局域可纠正编码最著名的例子是数学家David Muller与Irving Reed(他也参与发展了Reed-Solomon码)1954年发明的一种备受推崇的纠错码的各种变种。如同Reed-Solomon码,Reed-Muller码也使用多个项加和的多项式来编码长消息。
在Reed-Solomon码中用到的多项式只涉及一个变量,x,因此加和多个项的唯一方式是使用x的更高幂次。这会导致不断起伏的曲线,因而需要察看许多个点才能确定下来。而Reed-Muller码使用的多项式的每一项都包含多个变量的乘积。更多的变量意味着有更多的方式去组合它们,从而提供了一种方式去增加多项式项数,而无需将单个变量提升到非常高的幂次。
Reed-Muller码非常具有弹性。你可以在编码长消息时提升多项式中出现的最高幂次,增加变量的数目,或者二者同时进行。要想让Reed-Muller码局域可纠正,你只需将每个变量的最大幂次限定在一个小的常数之下,而仅仅通过增加变量数来处理更长的消息。
对于特定的三查询局域可纠正编码来说,最大幂次被设定为2。于是就涉及到的单个变量来说,编码消息的多项式会划出一条简单的抛物线。要确定这一抛物线的精确形状,你只需检查曲线上的三个点。此外,有了多个变量就有了许多这样的抛物线,它们中的任一个都可以用来纠正错误。这就是Reed-Muller如此坚韧的原因。
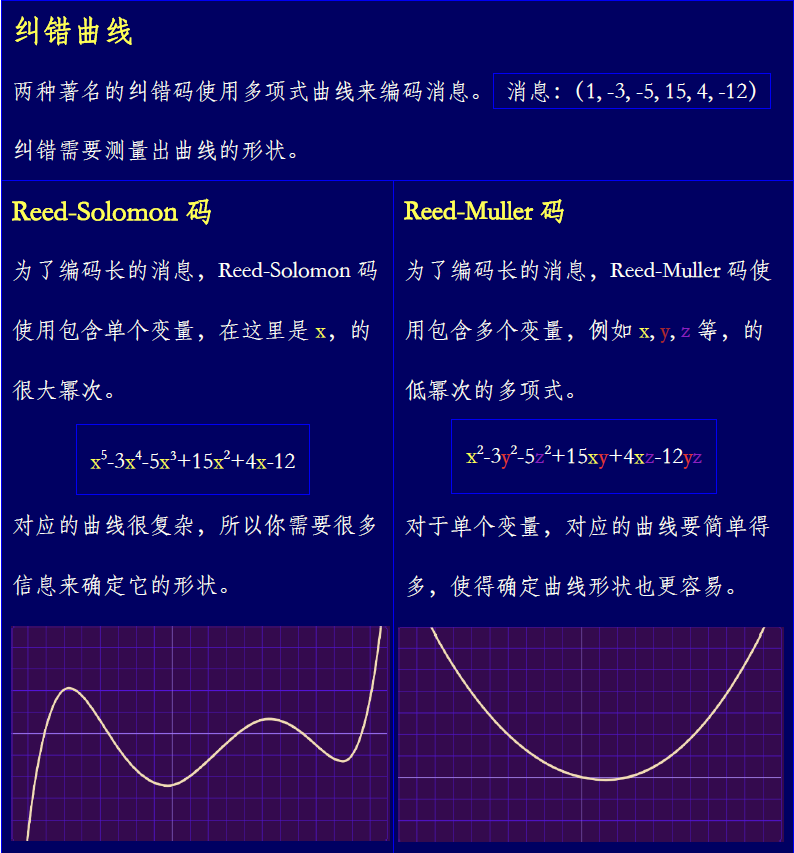
可惜的是,Reed-Muller码有一个致命的缺点:用来编码一条消息的比特数随着变量数指数式地增长。如果想得到仅用几条查询就可纠正错误的高度局域码,你需要大量变量来编码长消息,这就使得Reed-Muller码很快就变得不再实用了。
“指数这种情形是很糟糕的,”Dvir说。但它是否必然出现呢?
纠正还是译解?
随着计算机科学家在寻找更高效局域可纠正编码的过程中屡战屡败,他们开始怀疑这种码到底是不是真的存在。2003年,两个研究者证明仅使用两次查询是没法超越Reed-Muller码的。但那已经是人们能做到的极限了。
“一旦到达三,我们的知识就变得非常粗略了,”Kothari说道。
接下来的突破反而让事情更加复杂了。在发表于2008年和2009年的两篇文章中,计算机科学家Sergey Yekhanin与Klim Efremenko展示了如何构造比Reed-Muller码更高效的三查询码,但这些编码不是真正局域可纠正的。取而代之,它们拥有一种稍微不同的性质,局域可译解性。
要理解其差异,我们再来设想一个云存储提供商,他将用户数据组合成一条长的消息,并用一种纠错码来保护它。局域可纠正编码和局域可译解编码都可以只用少量查询来纠正原始消息中任何比特上的错误。
但每种纠错码都还需要不在原始消息中的额外比特——这也是为什么编码一条消息会让它变长的原因。这两种类型的编码的差异就在于它们对待这些额外比特的方式。局域可译解编码对纠正这些比特上的错误所需的查询数目不做承诺。而在局域可纠正编码中,任一个额外比特上出现的错误都能用跟纠正原始消息中任何比特上的错误完全相同的方法去纠正。
“你存储的所有东西,不管是用户的原始数据还是冗余度与校验信息——所有这些都能局域地纠正,”哈佛大学计算机科学家Madhu Sudan说道。
尽管原理上不同,局域可纠正性与局域可译解性在2008年以前看起来在实用中总是可以互换——每种已知的局域可译解编码也都是局域可纠正的。 Yekhanin与Efremenko的发现提出了这样一种可能性,这两种条件在根本上是不同的。或者,有办法改动Yekhanin与Efremenko的编码使其局域可纠正。这会再次将两种条件置于同等地位,但那也意味着研究者们在三查询局域可纠正编码的有效性方面有所误解。不论是哪种情况,常规的看法必须变革。
借助逻辑
Kothari与Manohar最终化解了这一冲突,通过改造来自计算机科学另一个不同方向——约束满足问题的研究——中的一种技术。与一群朋友协同晚餐计划就是一种约束满足问题。每个人都有接受的选项和反对的选项。你的任务是要么找到让所有人接受的方案,或者,如果不存在这种方案,就尽快弄清楚这一点。

Peter Manojar意识到他和Kothari发展起来的新技术特别适宜于研究局域可纠正编码的极限。
在这两种可能的结果间存在一种内在的不对称。一个可接受的解可能不容易找到,但一旦你找到了,很容易让其他人都信服它可行。可哪怕你知道这一问题真的“无法满足”,或许也没有一个例子来提供证明。
2021年,Kothari与Manohar,连同加州大学伯克利分校的Venkatesan Guruswami一道,在约束可满足问题的研究中取得了重大的突破,使用一种新的理论技术识别出了那些棘手的不可满足实例。他们认为这一新方法在解决其它问题上也会是一种强力工具,而Guruswami的研究生Omar Alrabiah建议他们去审视三查询局域可译解编码。
“这么说吧,当你手中拿着锤子时,看到什么都像是钉子。”Kothari称。
Yekhannin与Efremenko的惊人结果表明三查询局域可译解编码可以比Reed-Muller码更高效。但他们的编码是否是最好的了,还是三查询局域可译解编码还可以更高效?Kothari,Manohar, Guruswami与Alrabiah觉得他们的新技术或许可以证实这种编码在有效性上能达到的极限。他们的计划是构建一个逻辑表达式,让它包含给定长度下所有可能的三查询局域可译解编码的结构,然后证明它不可满足,从而说明这种编码不可能存在。
四位研究者2022年迈出了这一方向上的第一步,建立了三查询局域可译解编码的最大有效性的新极限。这一极限远远超出了研究者们用其他技术所取得的成果,但它并未排除比Yekhanin与Efremenko码更有效的所有编码。
Kothari和Manohar猜测他们可以更进一步。但进展停滞了,直到Manohar用一个快速的估算说明,这一技术可能更适用于局域可纠正编码,而非局域可译解编码。
几个月后,在多次失败的尝试让他们担心过于乐观之后,这一技术最终兑现了承诺。Kothari 与Manohar证明,正如研究者们猜测的,任何三查询局域可纠正编码都不可能显著地优于Reed-Muller码。那一指数标度行为是一种基本局限性。他们的结果也一目了然地表明,局域可纠正性与局域可译解性,尽管表面上看起来相似,但其实是根本不同的:后者明显比前者更易于实现。
Kothari和Manohar现在希望将他们的技术扩展到允许多于三次查询的编码的研究中,因为这些我们至今仍所知甚少。而纠错理论中的进展往往会在其它看似不相关的领域产生影响。特别地,局域可纠正编码在许多地方出人意料地出现,从密码学中私有数据库的搜索问题到组合学中定理的证明。现在评估Kothari与Manohar的技术会如何影响这些不同的领域还为时过早,但研究者们对此很乐观。
“这里用到了相当美妙的新想法,”Dvir说道,“我觉得它有着无限可能。”
原文链接:
https://www.quantamagazine.org/magical-error-correction-scheme-proved-inherently-inefficient-20240109/
转载本文请联系原作者获取授权,同时请注明本文来自左芬科学网博客。
链接地址:https://wap.sciencenet.cn/blog-863936-1470317.html?mobile=1
收藏