
AI 到底会消耗多少能量?好的、坏的和未知的
研究人员希望公司对人工智能的电力需求更加透明。

弗吉尼亚州卡尔佩珀县弥漫着干草和粪便的气味,在这里,每三个人就对应着一头牛。“我们有大型农场,其中大多数仍为家庭所有,还有大片森林。” 全县5.5万居民之一的莎拉·帕尔米利(Sarah Parmelee)说道。她补充道:“这里是非常迷人的美国小镇。” 但这个田园般的理想之地正处于21世纪的变革之中。在过去几年里,该县已批准建设七个大型数据中心项目,这些项目将助力科技公司实现其关于生成式人工智能(AI)的宏大计划。在这些巨大的建筑里,一排排计算机服务器将帮助训练诸如ChatGPT等聊天机器人背后的人工智能模型,并对来自世界各地可能多达数十亿的每日查询给出答案。 在弗吉尼亚州,这些建设将产生深远影响。每个数据中心设施的耗电量可能与数万户家庭的用电量相当,这有可能推高居民的用电成本,并使该地区的电力基础设施超出负荷。帕尔米利和社区里的其他人对数据中心的用电需求心存警惕,尤其是因为弗吉尼亚州早已被誉为世界数据中心之都。2024年12月发布的一份由该州委托进行的评估报告指出,尽管数据中心带来了经济效益,但其发展可能会在十年内使弗吉尼亚州的电力需求翻倍。 帕尔米利为总部位于弗吉尼亚州沃伦顿的非营利组织皮埃蒙特环境委员会工作,她正在绘制该州数据中心的增长情况图。她问道:“电力从哪里来呢?他们都说,‘我们会从邻近地区购买电力’。但那个地区也正计划从你这里购买电力。” 在全球许多地方,数据中心正以创纪录的速度涌现,类似的人工智能与能源之间的冲突也在酝酿之中。大型科技公司在生成式人工智能上投入巨大,与那些从数据中提取模式但不生成新文本和图像的旧人工智能模型相比,生成式人工智能运行所需的能源要多得多。这促使各公司总共花费数千亿美元建设新的数据中心和服务器,以扩大其运算能力。 从全球视角来看,人工智能对未来电力需求的实际影响预计相对较小。但数据中心集中成群分布,这对当地可能产生深远影响。与其他能源密集型设施,如钢铁厂和煤矿相比,数据中心在空间上更为集中。公司倾向于将数据中心建筑建得彼此靠近,以便它们能够共享电网和冷却系统,并在彼此之间以及与用户之间高效传输信息。尤其是弗吉尼亚州,通过提供税收优惠吸引了数据中心公司,导致了数据中心更加密集地聚集。 帕尔米利说:“如果你有了一个数据中心,很可能会有更多。” 弗吉尼亚州已经有340个这样的设施,帕尔米利绘制出了该州159个拟建的数据中心或现有数据中心的扩建计划。根据加利福尼亚州帕洛阿尔托的一家研究机构——电力研究协会(EPRI)的一份报告,在弗吉尼亚州,数据中心的用电量占该州总用电量的四分之一以上。在爱尔兰,数据中心的用电量占该国总用电量的20%以上,而且其中大多数位于都柏林边缘。在美国,至少有5个州的数据中心设施用电量超过了该州总用电量的10%。 更麻烦的是,公司对于其人工智能系统的电力需求缺乏透明度。独立研究员乔纳森·库米(Jonathan Koomey)研究计算领域的能源使用已有30多年,他在加利福尼亚州伯林盖姆经营着一家分析公司。他说:“真正的问题是,我们在运作时几乎没有关于实际情况的详细数据和了解。” 阿姆斯特丹自由大学的研究员、荷兰公司Digiconomist(该公司致力于研究数字趋势带来的意外后果)的创始人亚历克斯·德弗里斯(Alex de Vries)说:“我觉得每个研究这个话题的人都快疯了,因为我们得不到所需的资料。我们只是尽最大努力,尝试各种方法来得出一些数据。” 计算人工智能的能源需求 由于缺乏公司提供的详细数据,研究人员通过两种方式探究人工智能的能源需求。2023年,德弗里斯采用了一种基于供应链(或基于市场)的方法。他研究了在生成式人工智能市场占据主导地位的英伟达(NVIDIA)服务器之一的耗电量,并推算出其一年所需的能源。然后,他将这个数字乘以对正在发货的此类服务器总数的估计,或者乘以特定任务可能所需的服务器数量估计值。 德弗里斯用这种方法估算了如果谷歌搜索使用生成式人工智能所需的能源。两家能源分析公司曾估计,在每次谷歌搜索中实施类似ChatGPT的人工智能将需要40万至50万台英伟达A100服务器,根据这些服务器的电力需求,每年的耗电量将达到23至29太瓦时(TWh)。然后,德弗里斯估计谷歌每天处理的搜索量高达90亿次(这是来自不同分析师的大致数字),据此计算出通过人工智能服务器的每次请求需要7至9瓦时(Wh)的能源。根据谷歌在2009年的一篇博客文章中公布的数据(见go.nature.com/3d8sd4t),这是一次普通搜索能耗的23至30倍。当被要求对德弗里斯的估算发表评论时,谷歌没有回应。 德弗里斯说,这种能源计算感觉像是 “抓救命稻草”,因为他不得不依赖那些他无法验证的第三方估算数据。而且他得出的数据很快就过时了。现在,人工智能集成到谷歌搜索中所需的服务器数量可能会减少,因为如今的人工智能模型能够以较低的计算成本达到2023年模型的准确率,正如美国能源分析公司SemiAnalysis(德弗里斯曾参考该公司的估算数据)在给《自然》杂志的一封电子邮件中所写的那样。 即便如此,该公司表示,评估生成式人工智能能源消耗的最佳方法仍然是监测服务器的发货量及其电力需求,这大体上也是许多分析师所采用的方法。然而,分析师很难单独计算出生成式人工智能的能耗,因为数据中心通常也会执行非人工智能任务。 自下而上的估算 研究人工智能能源需求的另一种方法是 “自下而上” 的方式:研究人员测量特定数据中心中一个与人工智能相关请求的能源需求。然而,独立研究人员只能使用预计与专有模型类似的开源人工智能模型来进行测量。 这些测试背后的理念是,用户提交一个提示,比如生成图像的请求或基于文本的聊天请求,然后一个名为CodeCarbon的Python软件包允许用户的计算机访问在数据中心中执行该模型的芯片的技术规格。人工智能研究员萨沙·卢乔尼(Sasha Luccioni)参与了CodeCarbon的开发工作,她在总部位于纽约市的Hugging Face公司工作,该公司运营着一个人工智能模型和数据集的开源平台。卢乔尼说:“在运行结束时,它会估计出你所使用的硬件消耗了多少能源。” 卢乔尼等人发现,不同的任务所需的能源量各不相同。根据他们的最新研究结果,平均而言,根据文本提示生成一张图像大约消耗0.5瓦时的能源,而生成文本的能耗略低一些。作为对比,一部现代智能手机充满电可能需要22瓦时的能源。但也存在很大差异:更大的模型需要更多能源(见 “人工智能使用多少能源?”)。德弗里斯说,这些数字比他论文中的数字要低,这可能是因为卢乔尼等人使用的模型至少比ChatGPT背后的模型小一个数量级,而且人工智能的效率也在不断提高。
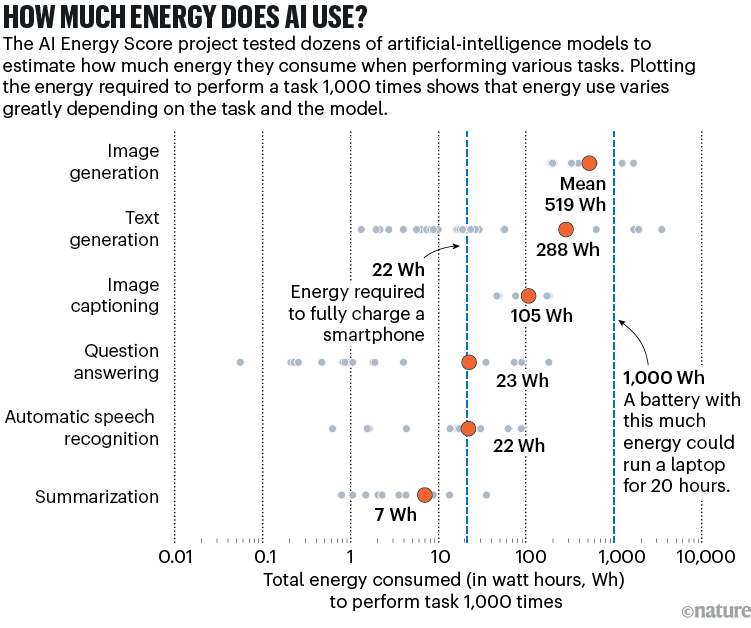
数据来源:HuggingFace人工智能能源评分排行榜
宾夕法尼亚州匹兹堡市卡内基梅隆大学的计算机科学家艾玛·斯特鲁贝尔(Emma Strubell)是卢乔尼的合作者,她表示,这些数字是下限。否则,“公司就会站出来纠正我们了,” 她说,“但他们并没有这么做。”
此外,公司通常会隐瞒软件估算数据中心冷却能耗所需的信息。维护CodeCarbon软件的法国数据科学家贝努瓦·库尔蒂(Benoît Courty)说,CodeCarbon软件也无法获取某些类型芯片的能耗数据,这其中包括谷歌的专有张量处理单元(TPU)芯片。
卢乔尼还研究了训练生成式人工智能模型需要消耗多少能源,训练模型即模型从大量数据中提取统计模式的过程。但是,正如德弗里斯在估算谷歌相关数据时所假设的那样,如果模型每天要接收数十亿次查询,那么用于回答这些查询的能源(可达太瓦时的电量)将在人工智能的年度能源需求中占据主导地位。训练像GPT-3(首个版本ChatGPT背后的模型)那么大规模的模型,所需能源大约为1吉瓦时。
上个月,卢乔尼和其他研究人员发起了 “人工智能能源评分项目”,这是一项公开计划,旨在比较不同任务下人工智能模型的能源效率,并为每个模型给出星级评定。卢乔尼说,专有封闭模型的开发者也能够上传测试结果,不过到目前为止只有美国软件公司Salesforce参与了该项目。
斯特鲁贝尔说,公司对于其最新行业模型的能源需求越来越守口如瓶。随着竞争日益激烈,“公司对外分享的信息越来越少了”,她说。但是像谷歌和微软这样的公司已经报告称,他们的碳排放量在增加,他们将其归因于为支持人工智能而进行的数据中心建设。(当《自然》杂志询问谷歌、微软和亚马逊等公司对于缺乏透明度的批评时,这些公司并未回应,而是强调他们正在与地方当局合作,以确保新的数据中心不会影响当地的公用事业供应。)
现在一些政府要求公司提高透明度。2023年,欧盟通过了一项《能源效率指令》,要求额定功率至少为500千瓦的数据中心运营商每年报告其能源消耗情况。
全球预测
分析师们表示,基于供应链估算方法,数据中心目前的用电量在全球电力需求中仅占一小部分。国际能源署(IEA)估计,2022年此类设施的用电量为240至340太瓦时,占全球电力需求的1%至1.3%(如果包括加密货币挖矿和数据传输基础设施,这一比例将提高到2%)。
人工智能的蓬勃发展将使这一比例有所上升,但国际能源署的报告指出,由于许多行业的电气化、电动汽车的普及以及对空调需求的增加,预计到2050年全球电力消耗将增长80%以上,数据中心 “在整体电力需求增长中所占的份额相对较小”(见 “全球电力增长”)。
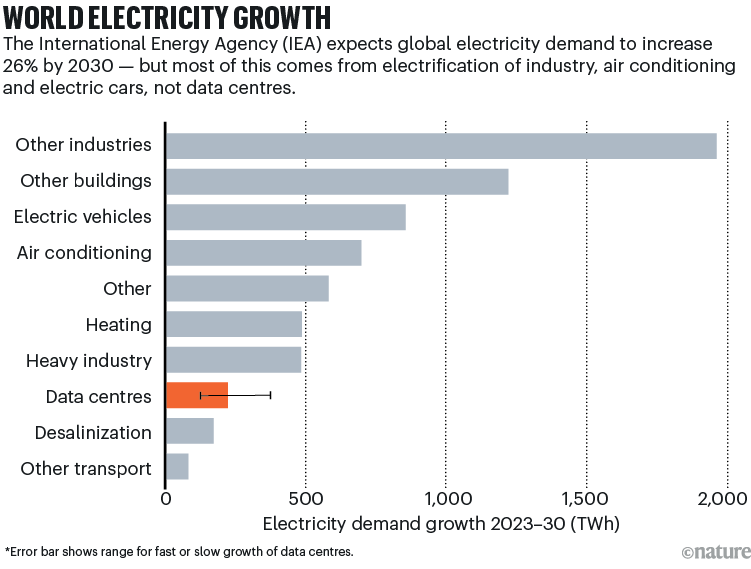
数据来源:参考文献4
库米(Koomey)警告称,即便对人工智能当前的能源需求进行了估算,要预测其未来的发展趋势依然困难重重。他说:“没有人能确切知道,哪怕是再过几年,人工智能数据中心或者传统数据中心的用电量会是多少。”
他指出,主要问题在于对于未来所需的服务器和数据中心的数量存在分歧,而且在这个领域,公用事业公司和科技公司出于经济利益考虑,有夸大相关数字的动机。他补充道,他们的许多预测都基于 “简单化的假设”。“他们只是将最近的趋势推断到未来10年或15年。”
去年年底,库米共同撰写了一份由美国能源部资助的报告。该报告估计,目前美国数据中心的用电量为176太瓦时,占美国总用电量的4.4%,到2028年,这一用电量可能会翻倍或增至三倍,占比达到7%至12%。
与此同时,SemiAnalysis公司在2024年3月的一份报告中(见go.nature.com/439becc)提出,数据中心的用电量会更高:到2028年,数据中心的用电量将占美国总用电量的15%;到2030年,将占全球发电量的4.5%(大约是国际能源署(IEA)数据的两倍;见“数据中心对全球的影响较小”)。国际能源署正准备在下个月更新其数据。但无论其预测结果如何,很明显,人工智能对能源的影响在地方和区域层面将最为显著。
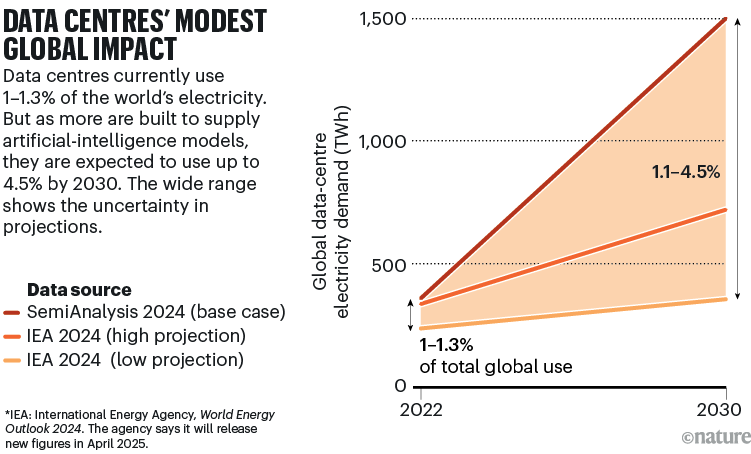
数据来源:参考文献4,SemiAnalysis公司
弗吉尼亚州面临的压力
正当世界各地的研究人员努力评估人工智能对能源的影响时,弗吉尼亚州的居民同样也缺乏有关该地区数据中心用电量的信息。帕尔米利(Parmelee)通过梳理新闻报道、行业出版物、纳税申报单以及众包的线索,追踪到了一些数据中心的电力需求情况。但她说,获取这些信息一直都很困难。
位于里士满的弗吉尼亚州联合立法审计审查委员会(JLARC)是一个负责监督该州项目和机构的政府机构。该委员会的首席立法政策分析师马克·格里宾(Mark Gribbin)表示,当地的电力公司确实知道建设数据中心的公司声称它们将需要多少电力。他是那份发现数据中心将在十年内使弗吉尼亚州的电力需求翻倍的报告(见 “数据中心对当地的影响更大”)的共同作者。但公司一般不会公布单个数据中心的具体用电数据。
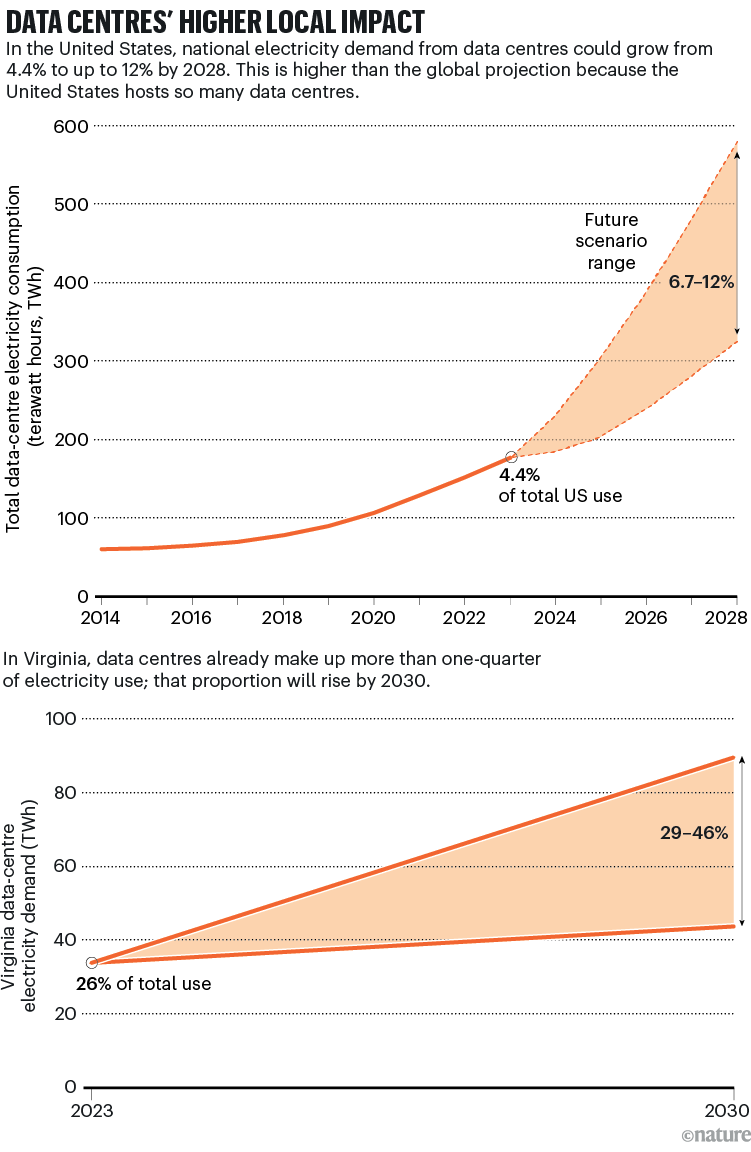
数据来源:参考文献5(上图);参考文献2(下图)
上个月,弗吉尼亚州的立法者通过了一项数据中心透明度法案,在《自然》杂志付印时,该法案正等待该州州长签署。该法案并未要求公司披露其电力需求,而是要求提供有关用水和土地使用等方面的环境影响报告。
与此同时,弗吉尼亚州的电力基础设施已经显现出压力。位于华盛顿特区以西的威廉王子县,一些已获批的数据中心面临着长达三年的延期,原因是电力公司无法在承诺的时间内为它们供电。
弗吉尼亚州联合立法审计审查委员会(JLARC)的报告称,对于该州的电力公司而言,要为预计的数据中心用电需求建设足够的基础设施 “非常困难”。太阳能设施的新增速度需要达到2024年的两倍,而风力发电量则必须超过所有 “目前已确定用于未来开发” 的海上风电场的发电能力。
在某些情况下,建设数据中心的公司正试图自行获取电力供应。例如,去年,微软达成了一项协议,重启宾夕法尼亚州三里岛核电站的一个核反应堆,以为其人工智能业务供电。尽管其中一些项目使用了低碳或可再生能源,但一些电力公司和立法者仍在推动建设更多的化石燃料发电厂,比如燃烧天然气的发电厂,而这将增加碳排放。
人工智能的需求会下降吗?
建设数据中心的热潮基于这样一种假设,即越来越多的人希望更频繁地使用人工智能。但国际能源署(IEA)的分析师在去年的一篇评论文章中写道(见go.nature.com/4hu2hos):“人工智能使用的增长速度和方式在根本上仍然不确定。” 人们对人工智能表现不稳定感到担忧,并且存在一些针对人工智能模型侵权的诉讼;未来生成式人工智能需要多少计算能力也尚不清楚。
今年早些时候发布的中国模型 “智谱清言-R1”(DeepSeek-R1)似乎能够以较低的成本与美国的模型相抗衡(尽管这一说法受到了质疑)。这使得一些研究人员认为,工程师现在可以在不一定要扩大模型规模的情况下创建更好的模型,这可能会降低数据中心的计算需求。
相反,如果生成式人工智能的效率大幅提高,人们很可能会更多地使用它,这一现象被称为 “杰文斯悖论”,以19世纪英国经济学家威廉·斯坦利·杰文斯(William Stanley Jevons)命名。他观察到,煤炭动力技术效率的提高加速了其普及,从而抵消了任何能源节约。
十年后,生成式人工智能的使用有可能按照计划增长,卡尔佩珀县目前所有拟建的数据中心都将满负荷运行。但也有可能生成式人工智能会变成一种相对小众的技术,一些数据中心会因为缺乏需求而关闭。
库米(Koomey)说:“如果你在做出看似笃定的预测,而实际上却存在巨大的不确定性,那么肯定会有人因此受损。”
Nature 639, 22-24 (2025)
转载本文请联系原作者获取授权,同时请注明本文来自孙学军科学网博客。
链接地址:https://wap.sciencenet.cn/blog-41174-1476247.html?mobile=1
收藏