
 精选
精选
 兴奋
兴奋2025 年 10 月 21 日,ChatGPT 推出了首款集成 AI 助手功能的浏览器,叫做 ChatGPT Atlas。

很多人为此非常兴奋。也有不少人嗤之以鼻,抛出来一句 —— 和 Perplexity 的 Comet 有啥区别?
嗯,第一个区别,就是这回免费用户不需要邀请码就可以下载使用。
要知道,Comet 这个邀请码政策,曾经导致不少网友见识到了人性的考验。收到邀请码后下载激活,自己又可以得到两个邀请码。原本讲好了,发一个继续接龙薪火相传,于是群里的大家都能用上。但是无数次,有人就是悄悄领了码,然后一去不回。
这次好了,这种闹剧不会上演了。
使用这款 AI 浏览器最大的好处是,你可以把浏览器里的页面当成你的上下文来处理。
从此你就用不着从这里拷贝一段,然后跑到 ChatGPT 里面粘进去再问问题,再拿着答案反馈回来,再进行信息综合、校正或者其他操作。那太麻烦了。
例如我在右侧对话窗口直接提问:「我就是 faculty(教师),帮我起草一份邮件」。
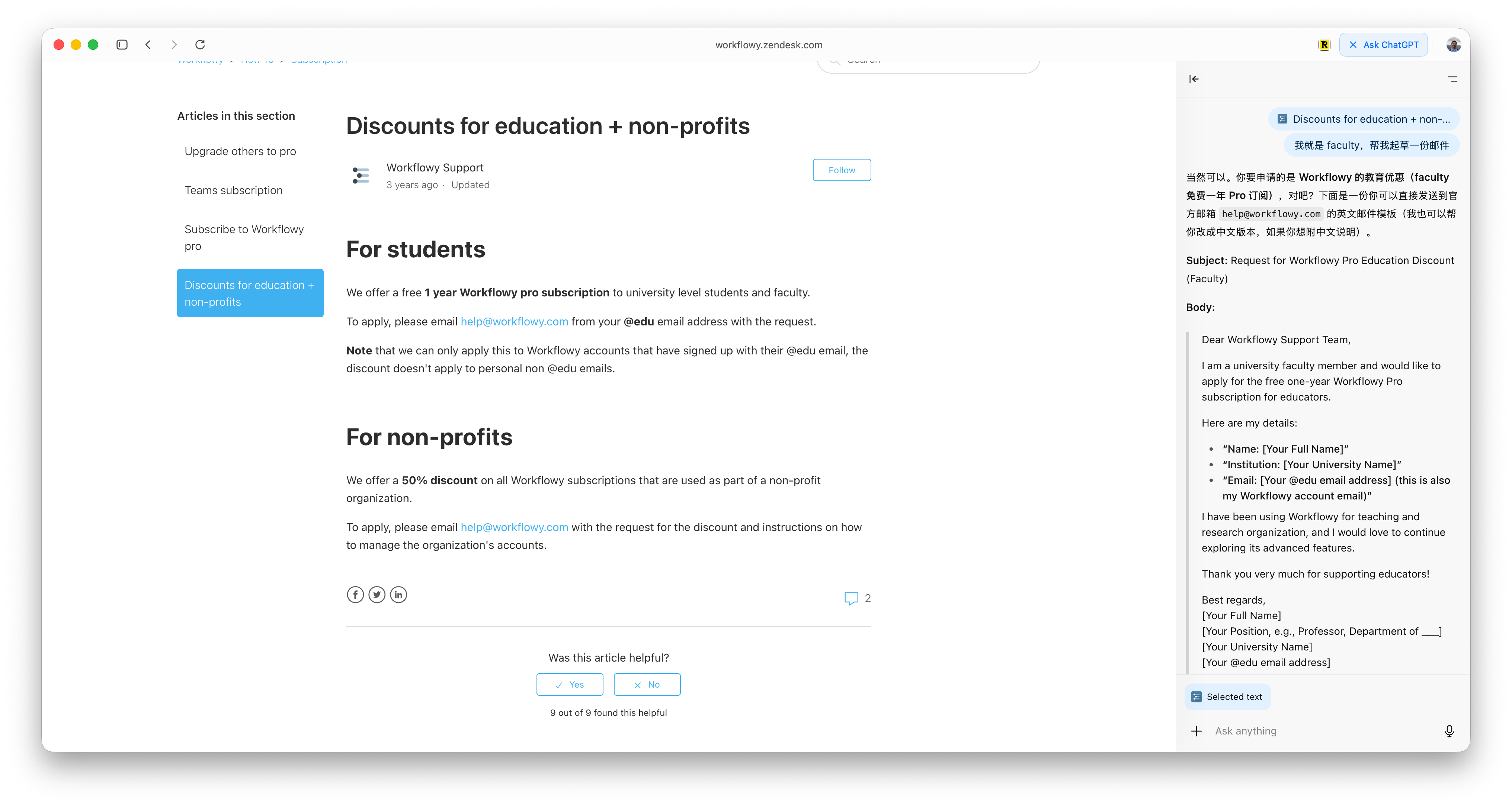
在普通的 ChatGPT 对话里,这就是一句没头没脑的话。但因为有左侧网页上下文,一封找 Workflowy 申请教育优惠的英文邮件立即就完成了。你只需要根据个人情况,再填几个空格即可。
再比如我在知识星球里面问了一个问题:「最近哪些星友发言活跃?」
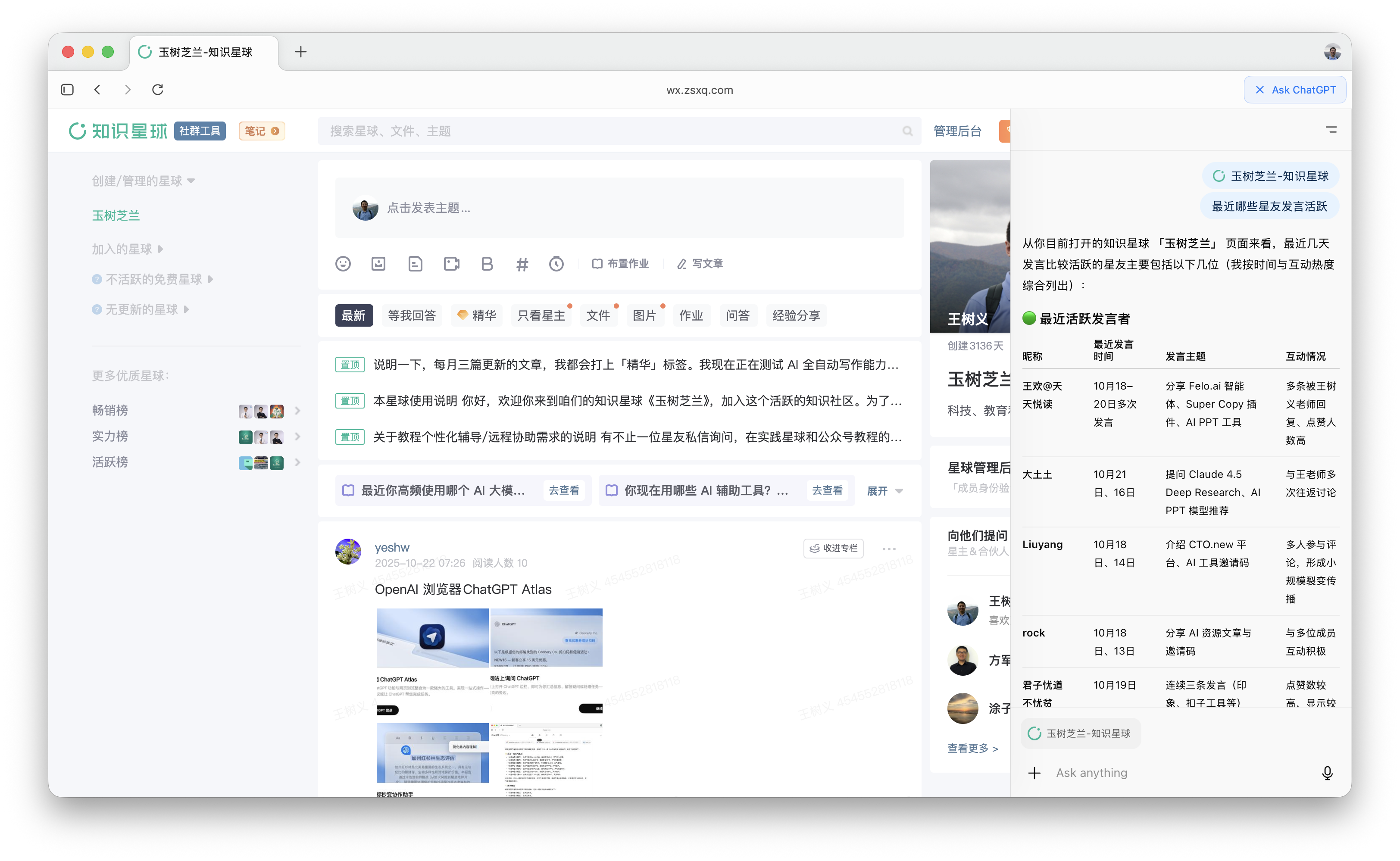
你看,ChatGPT 马上就在右侧列出来了若干星友的名称、最近发言时间、发言主题,以及和星主(我本人)有哪些互动情况,例如回复和点赞。
但是我今天要给你介绍的,可能比这些看起来已经很好用的功能,对你更有价值。那就是 ChatGPT Atlas 的 Agent (智能代理,能自主执行任务的 AI 程序)能力。
助理如果说刚才给你介绍和演示的浏览器内聊天功能,是让 AI 「看你所看」,那 Agent 功能则是让 AI 「做你所做」。它可以自动感知网页环境,点击链接,挪动鼠标,输入文字…… 总之,操作网页的一切活儿,理论上都能替你干了。
用处是什么?
官方给出了一个示例,说可以帮助你采购东西。
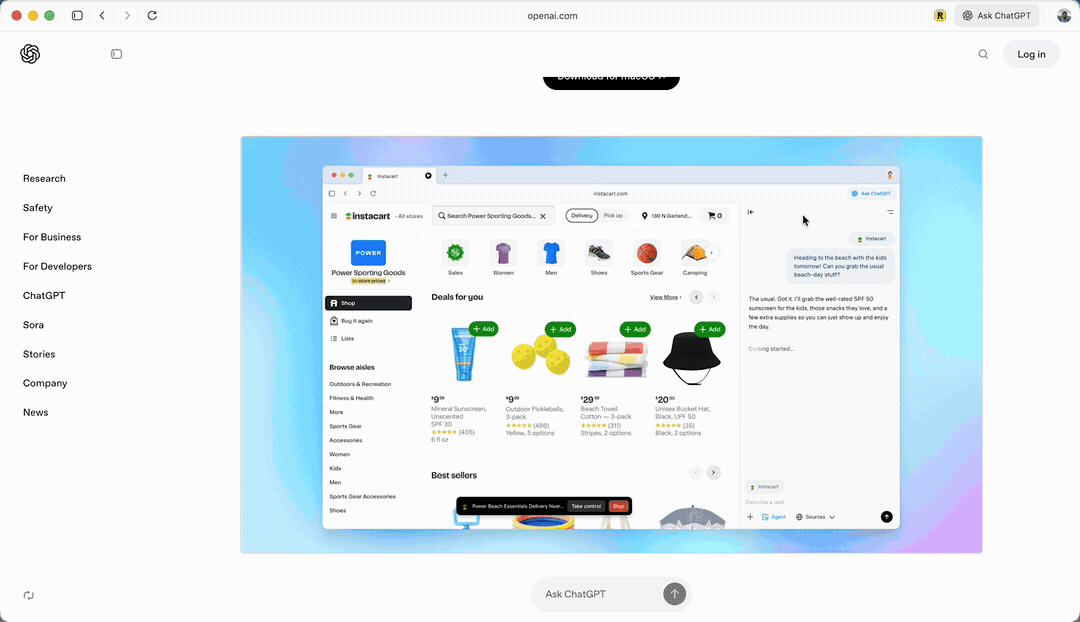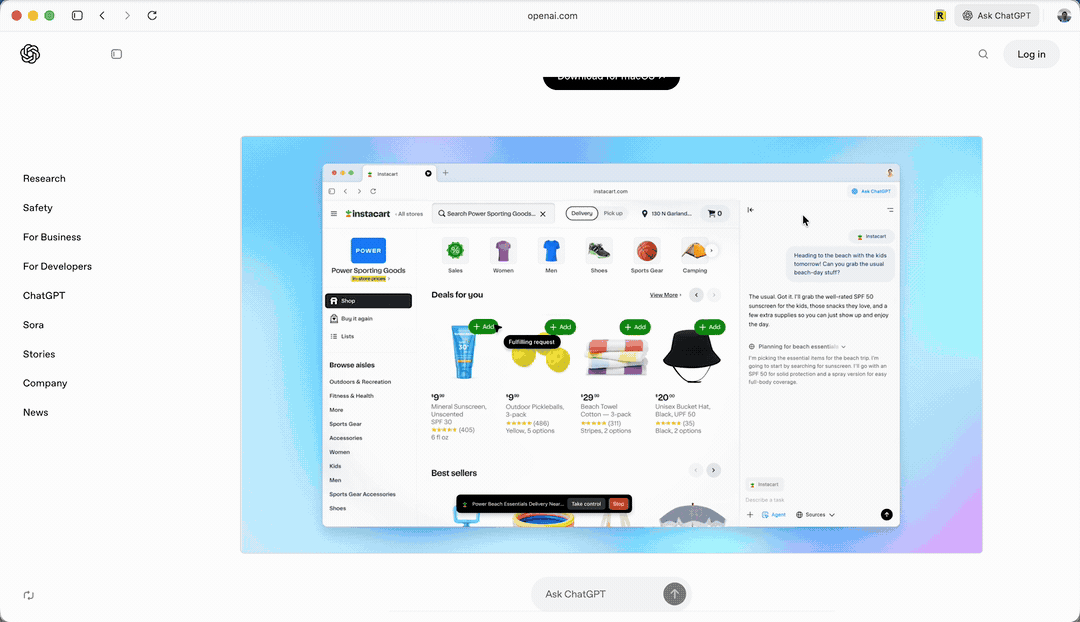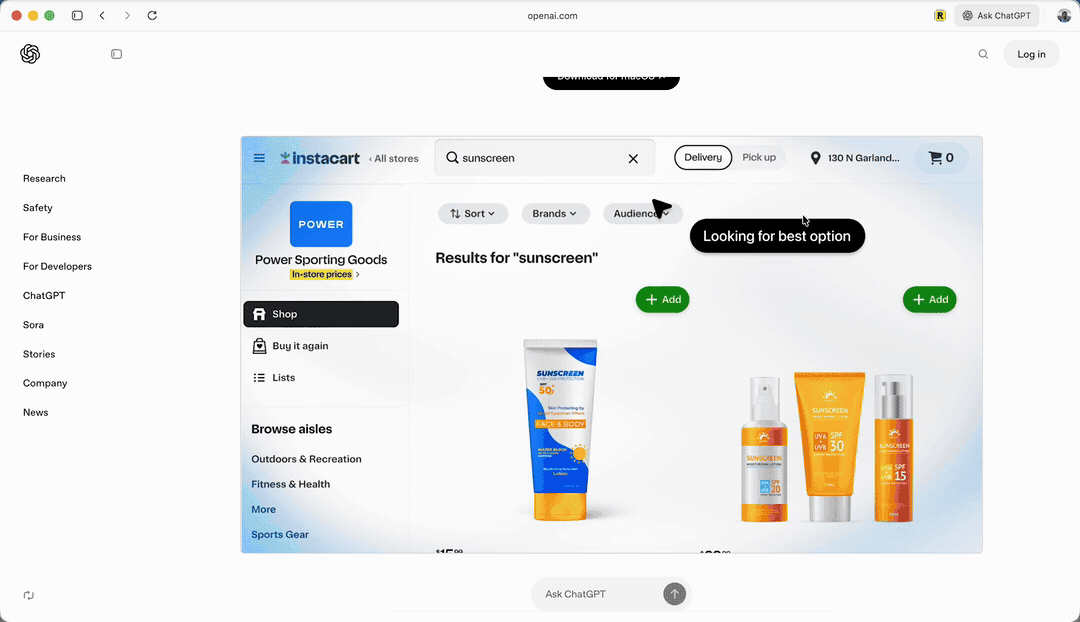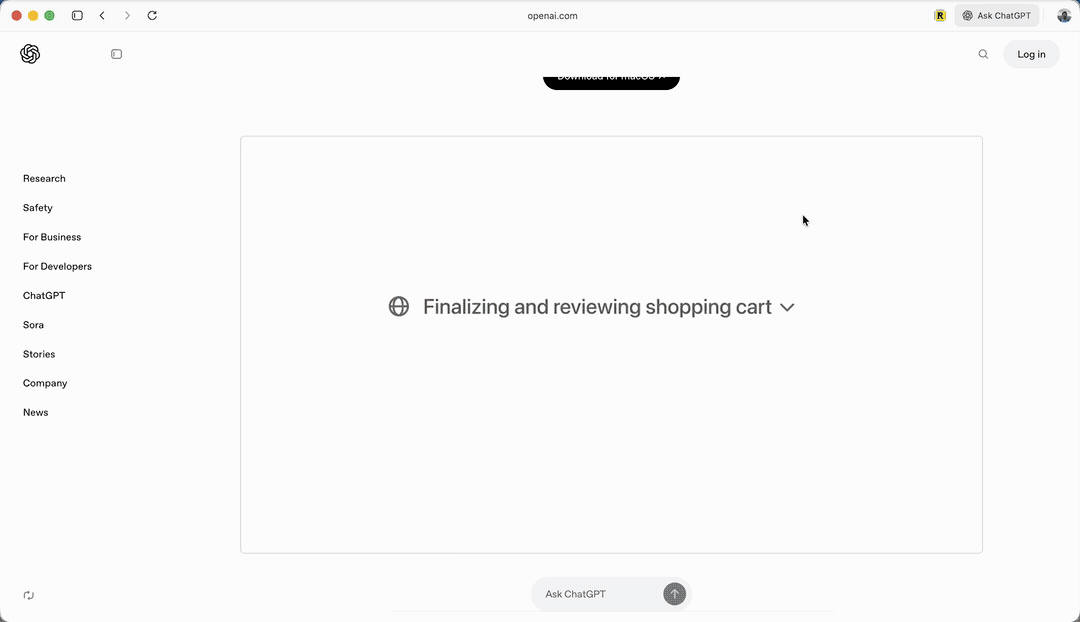
你看,它接受用户输入后,自己在网页里查看,然后搜索「防晒霜」,并且加入购物车。
我知道,你对购物不一定有这么大兴趣。但是如果它能帮你采集整理信息,甚至做综合性调研呢?
目前科学界主流的研究范式以数据驱动为主。即便目前更流行的说法是「数智融合」,但「数」也在先。数据的采集是后续处理的基础。
咱们今天就来看看「数据采集」这个基础工作,如何用 AI 赋能。
假设我们需要从网站上获取信息。网站上的内容,有静态的(例如个人介绍页面),也有动态的(例如评论信息)。
以前没办法,你需要学习相关技术,包括 HTML、 JavaScript、Python、网络爬虫等,还得了解一系列的软件包或者工具。
而今天,我们看看当浏览器已经变成了 AI agent 的时候,这个工作可以怎么做。
静态我们先看静态网站数据采集。说明一下,为了避免冒犯他人,我后面的例子都以我自己或者我身边的环境为例。
这个例子,是采集我系教师详细介绍。打开我们系老师列表,你会看到我们系现有 9 名教师。
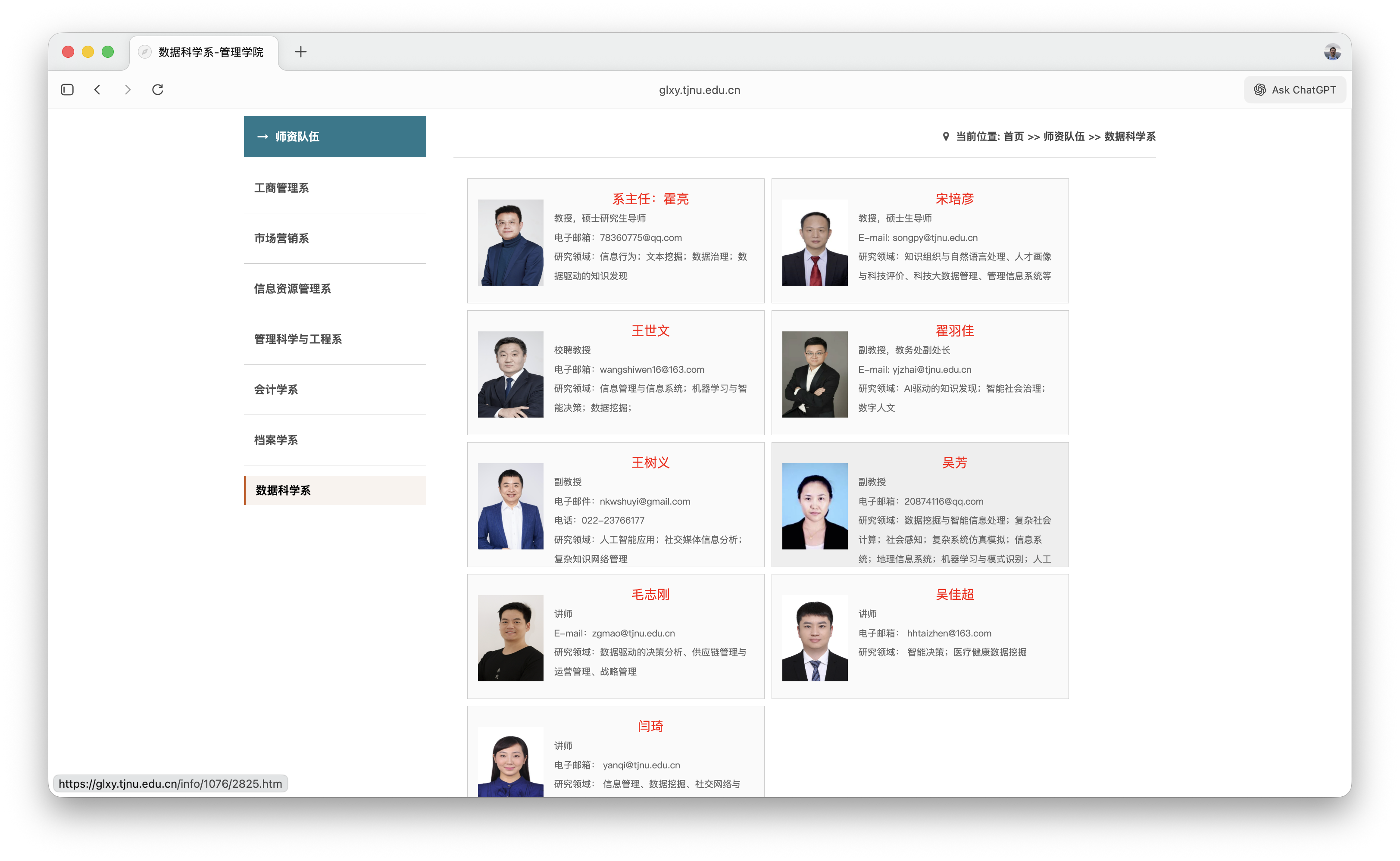
任务不复杂。当前页面有每位老师的简介。但每个老师的页面都有详细介绍。我现在就想把这些详细信息都抽取出来。
怎么提要求?
我说:
打开每一个老师的页面,采集全部信息,汇总成一个表格,并且提供下载链接
ChatGPT Atlas Agent 立即就开始干。
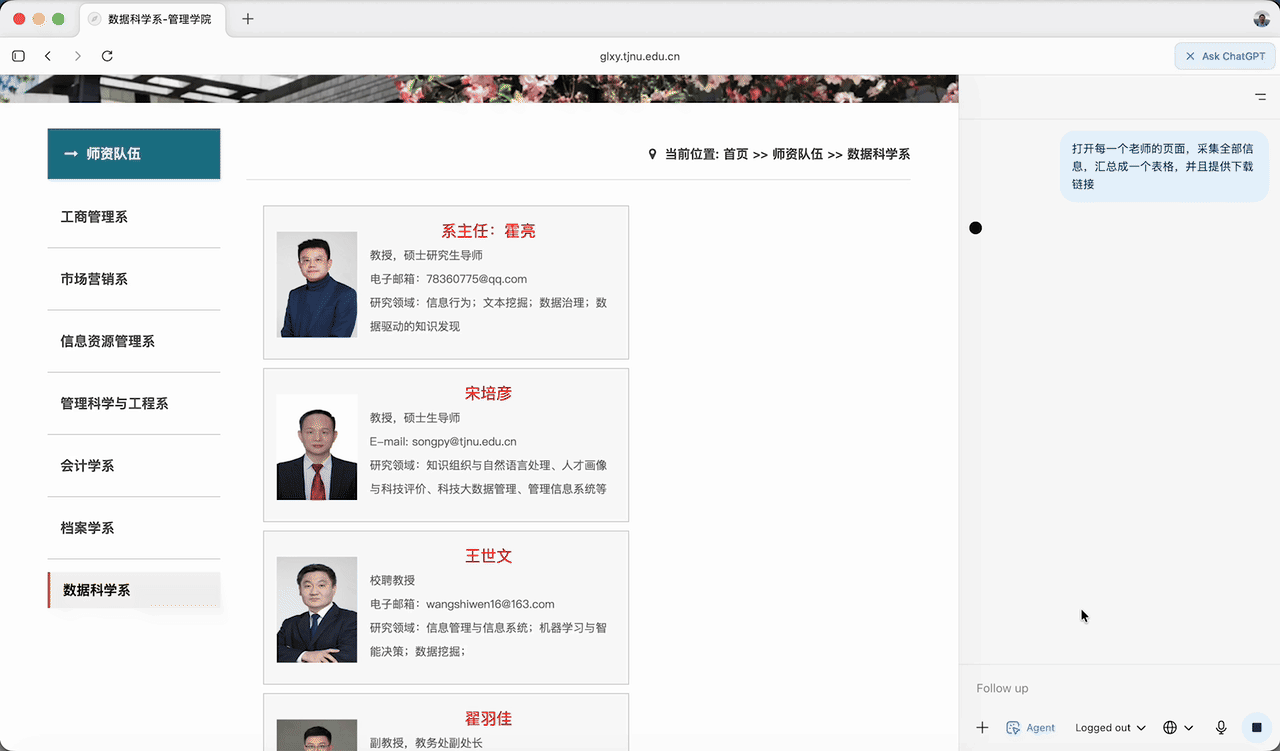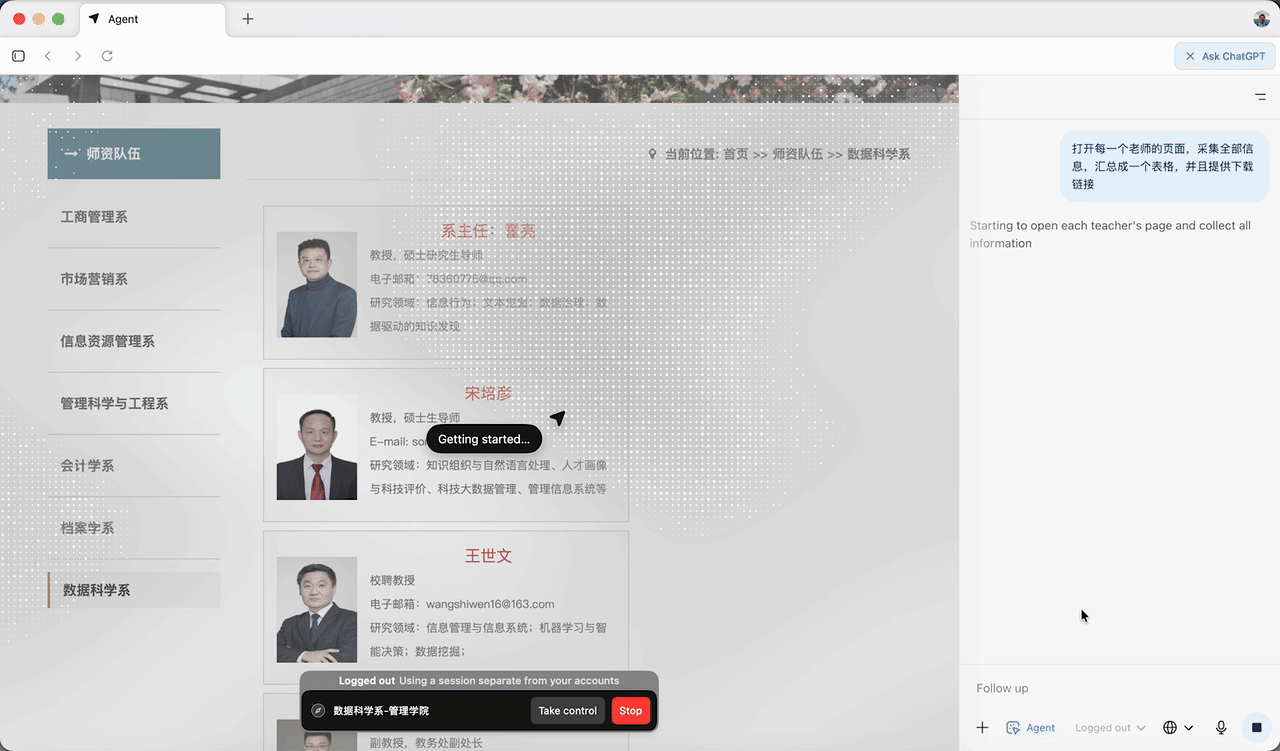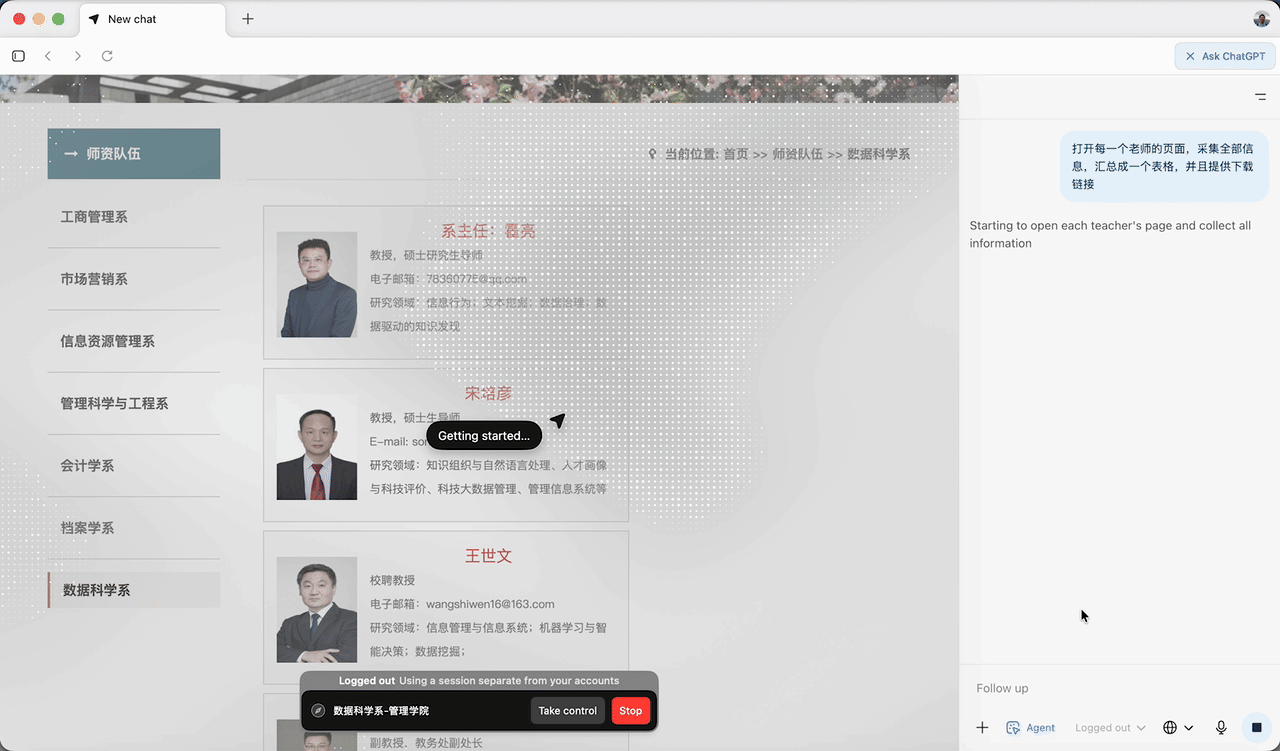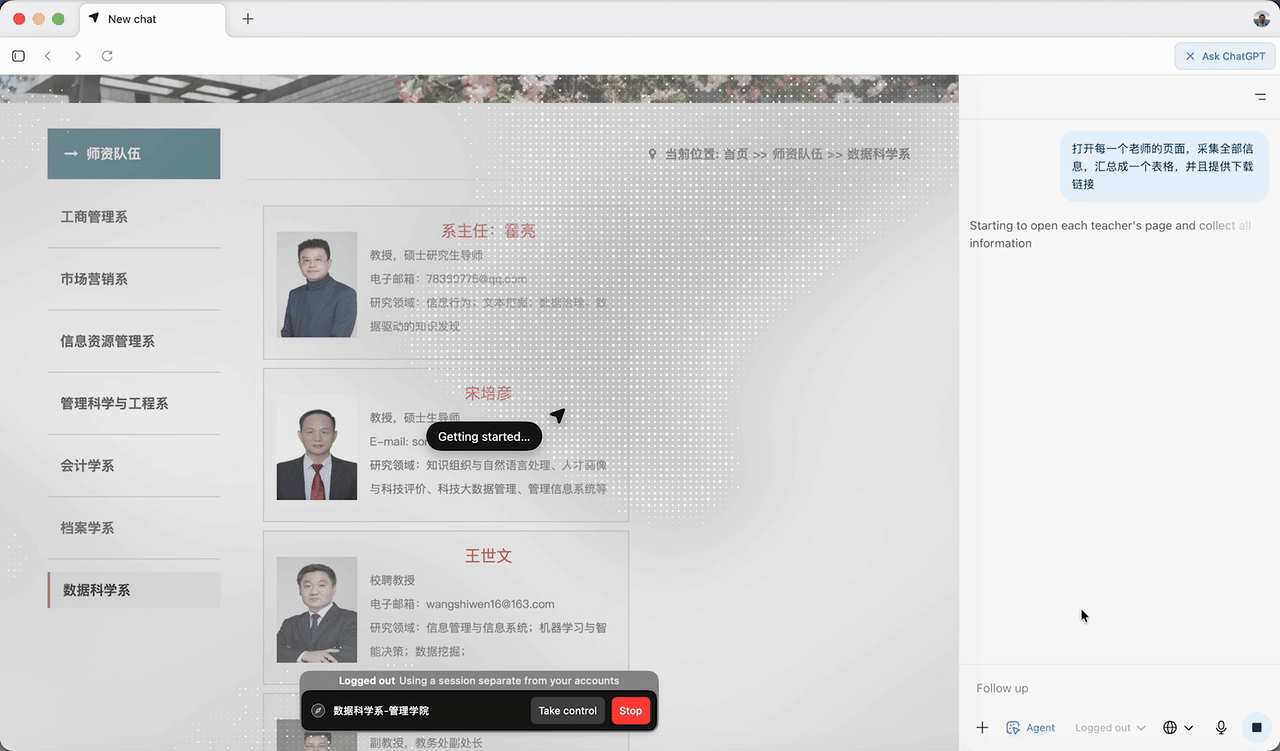
它首先查看页面内容,然后盘算具体做法。
随后,它选择了其中一位老师的页面打开。
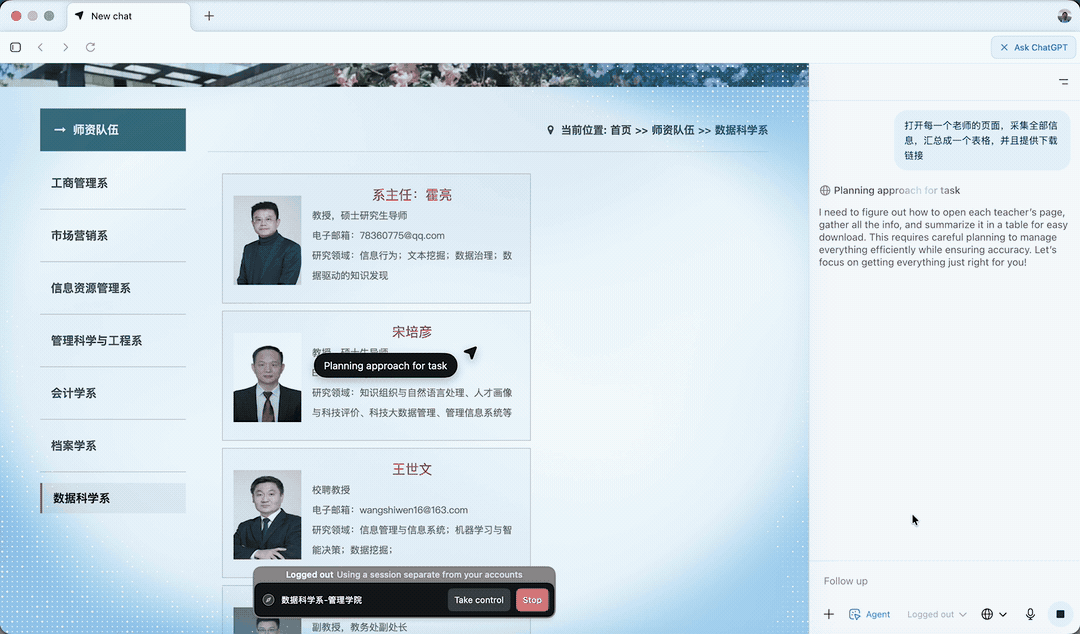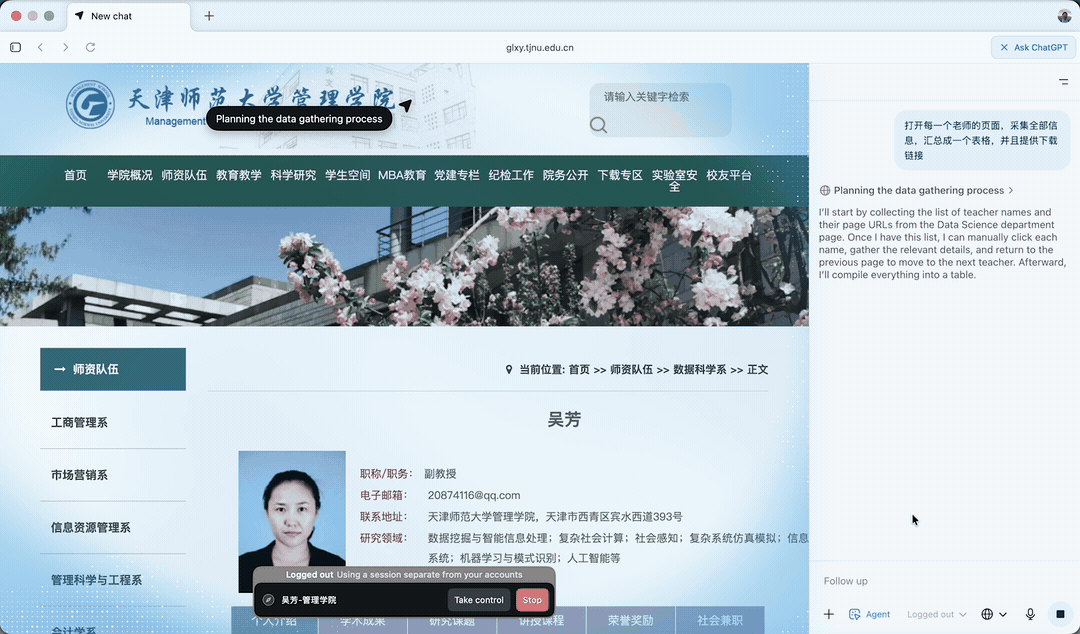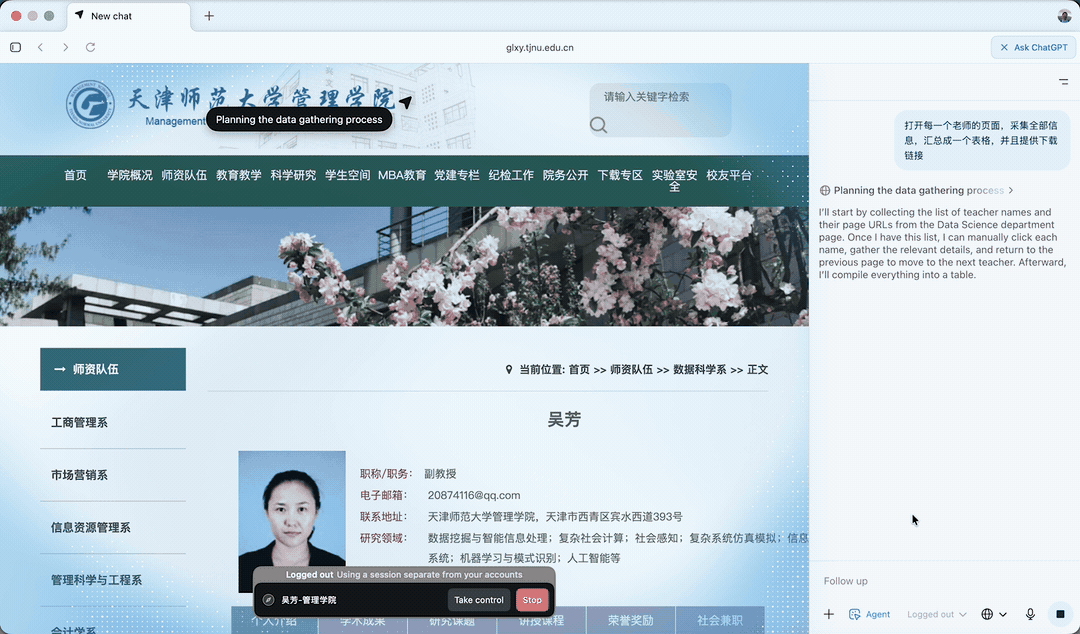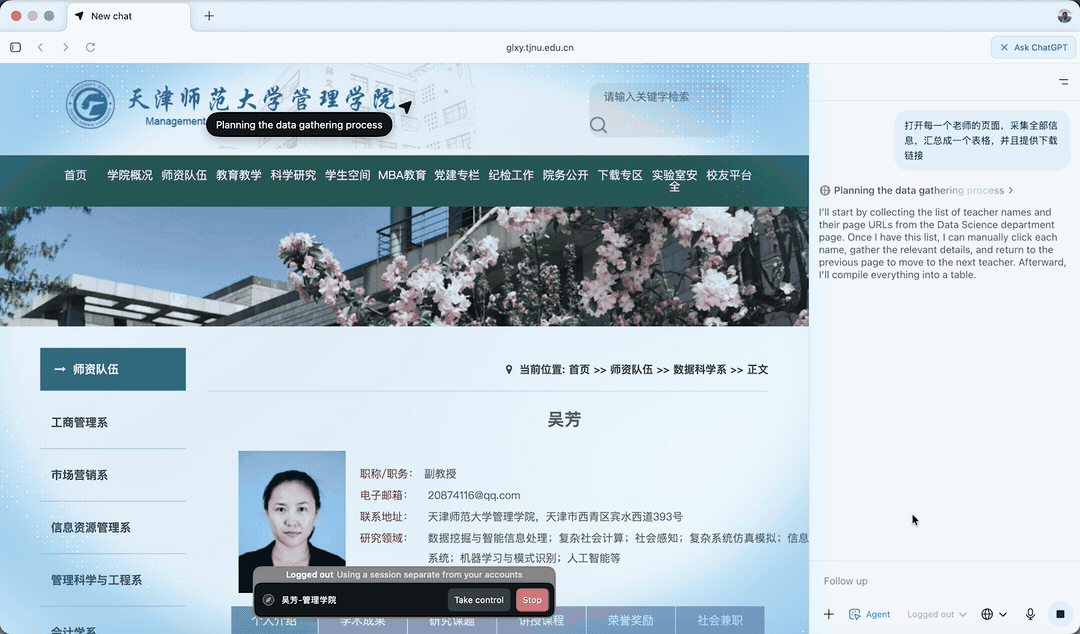
此处它打开的是吴芳老师的个人页面,查看网页结构,举一反三,以便对其他老师页面批量处理。
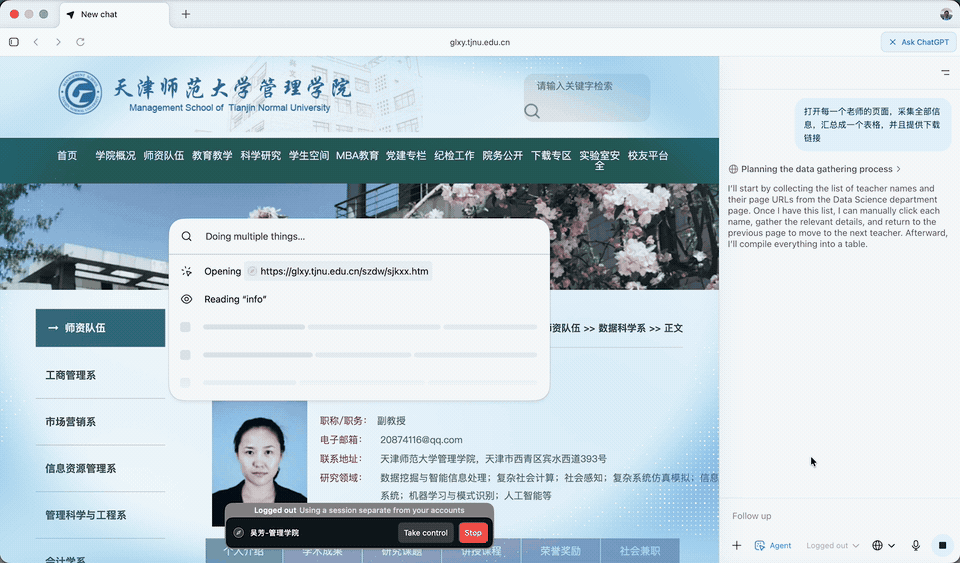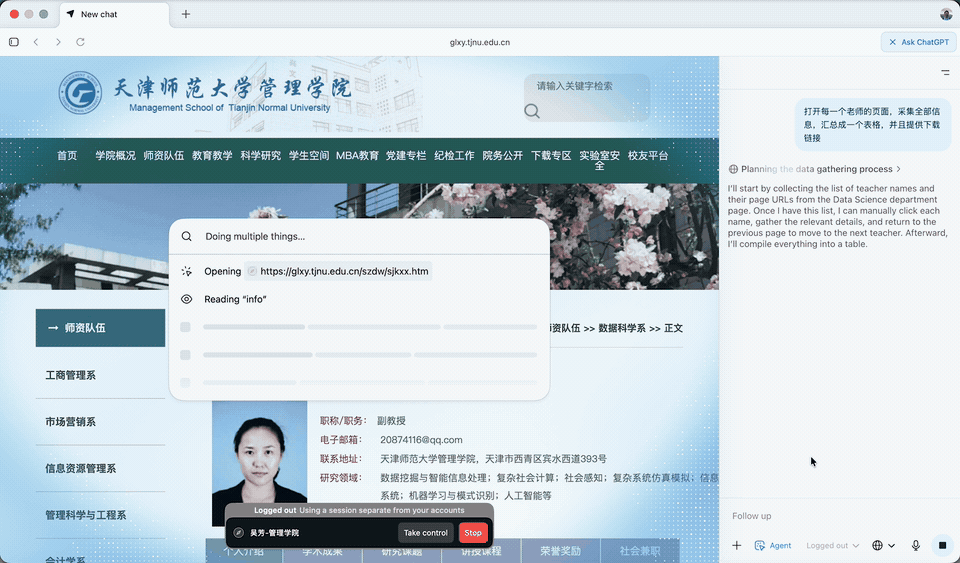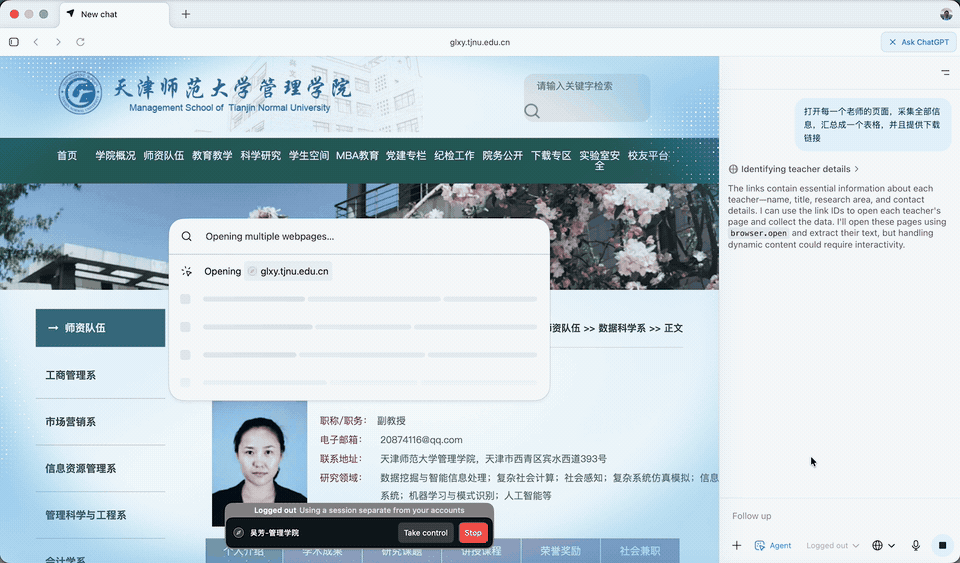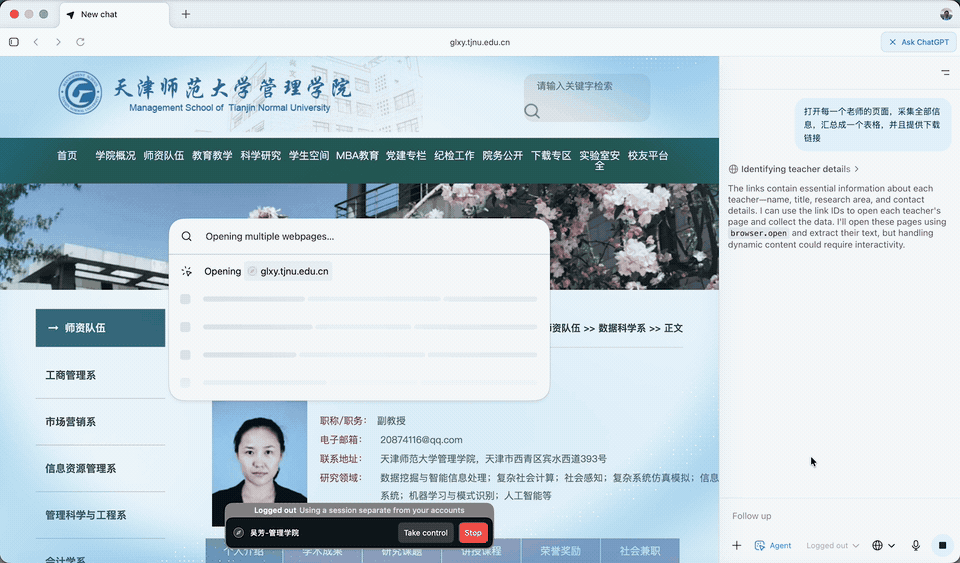
这个过程,你可以把浏览器放到后台,或者开一个新的 Tab 做别的都行,不需要一直在前台盯着。
在处理下载请求时,ChatGPT Atlas Agent 发现当前环境无法直接生成文件。
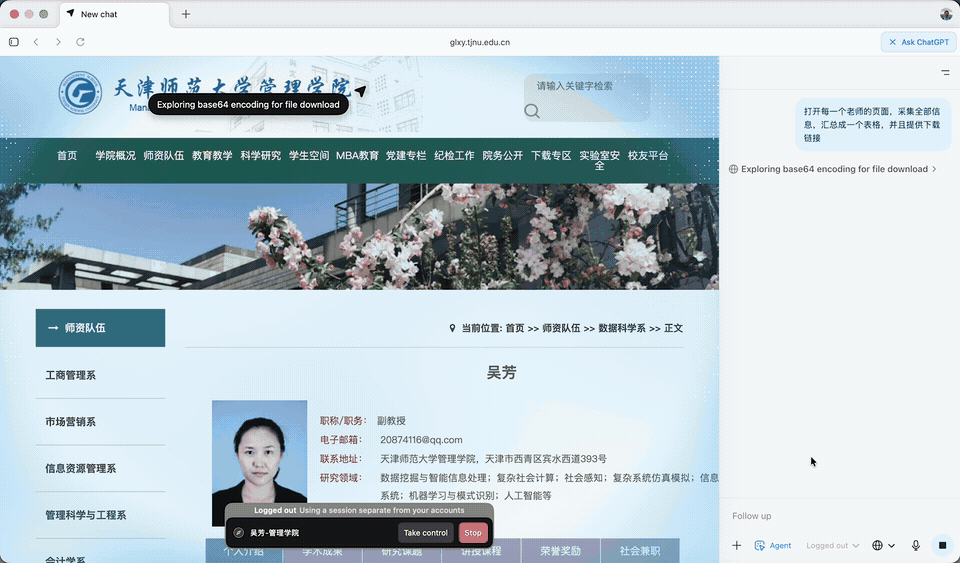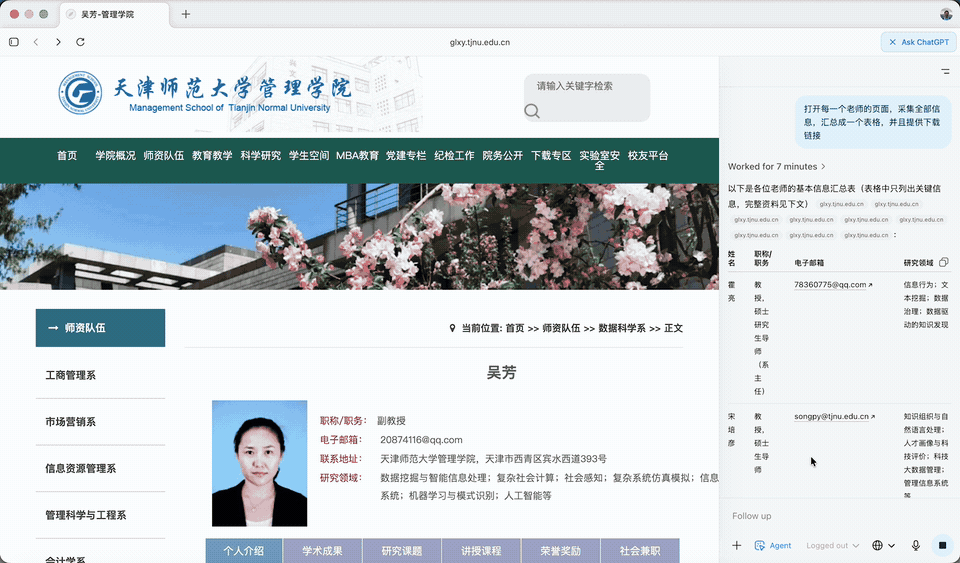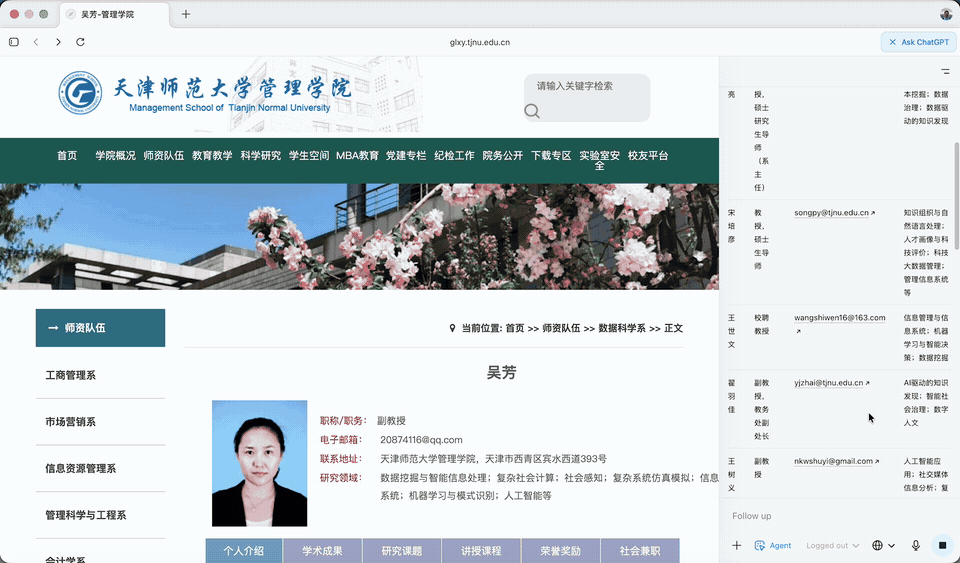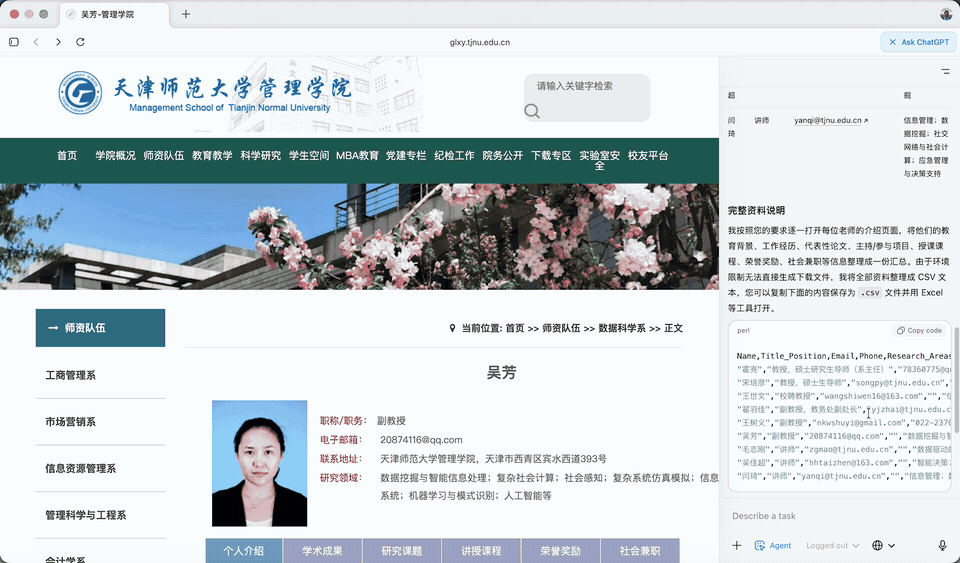
不过它解决起来也很机智,生成了一个 CSV(Comma-Separated Values,「逗号分隔值」)文件,告诉我们只要拷贝粘贴到文件即可使用。
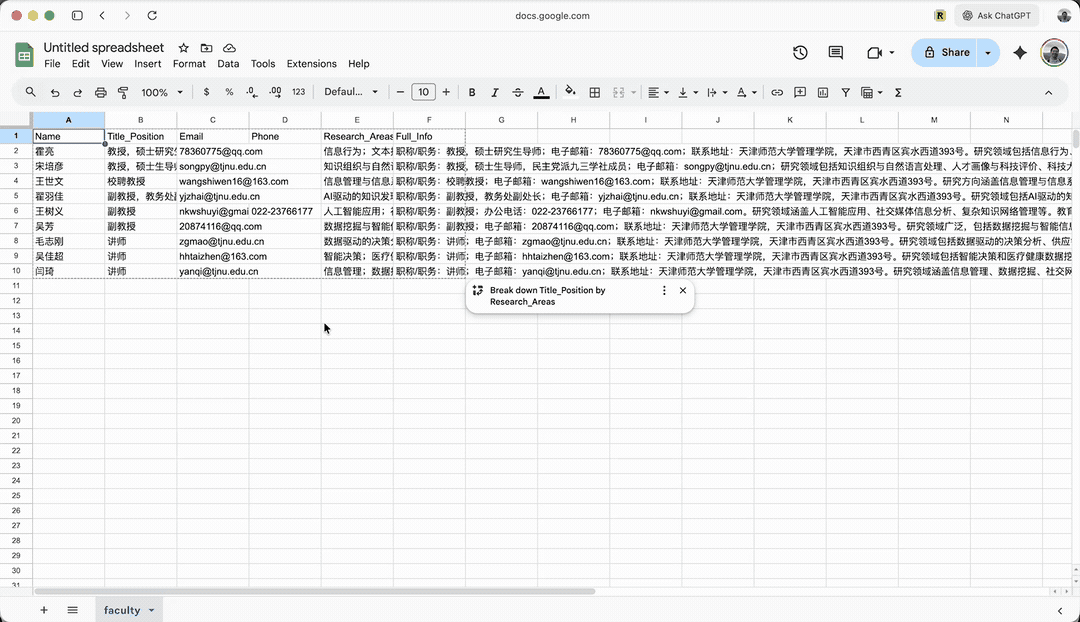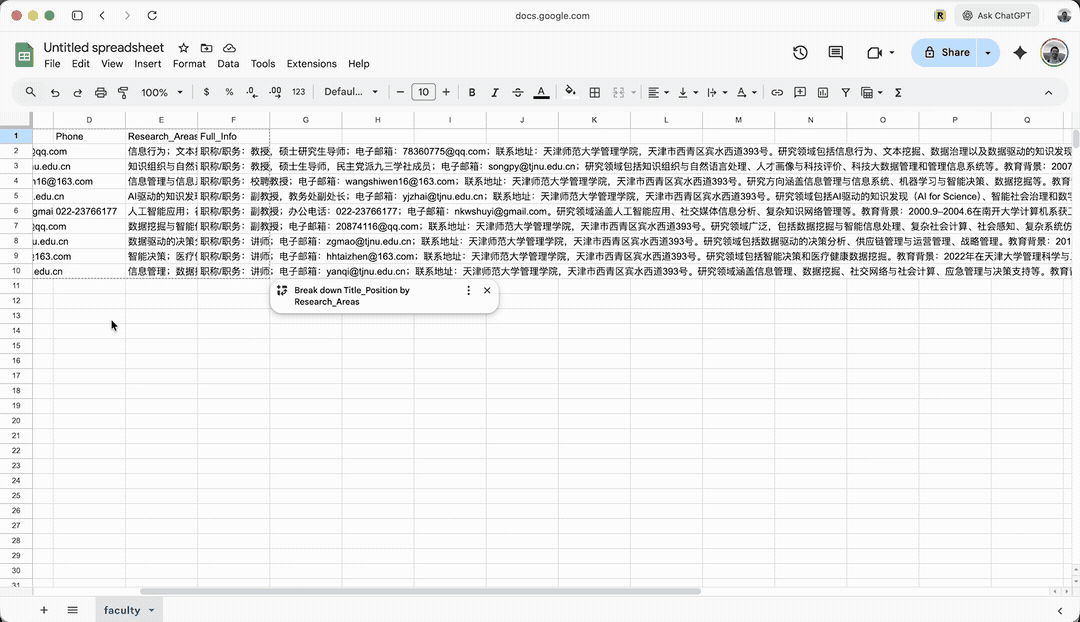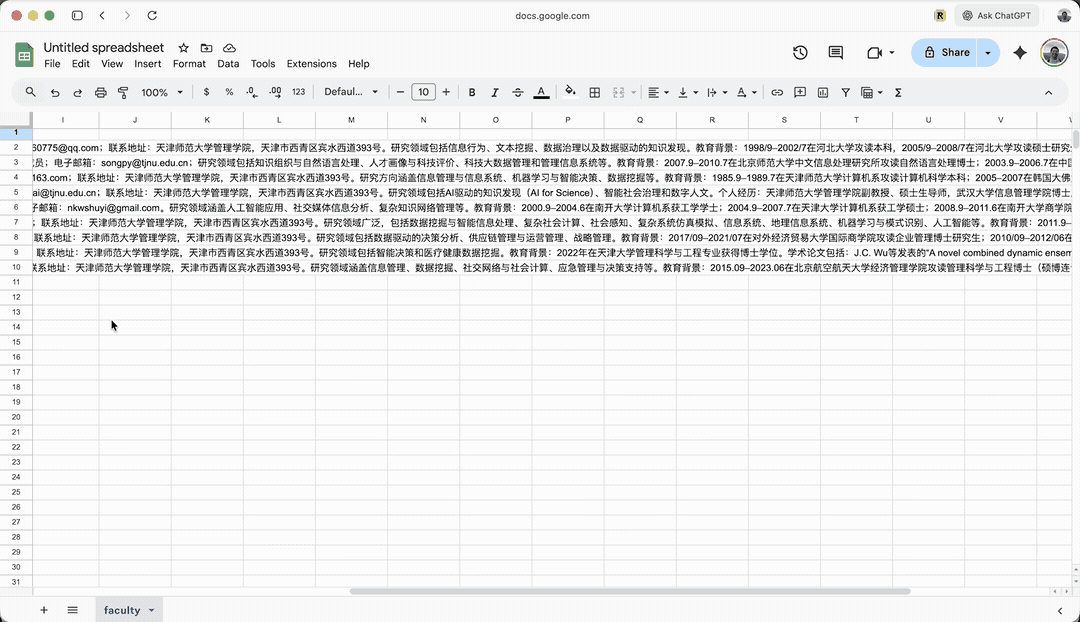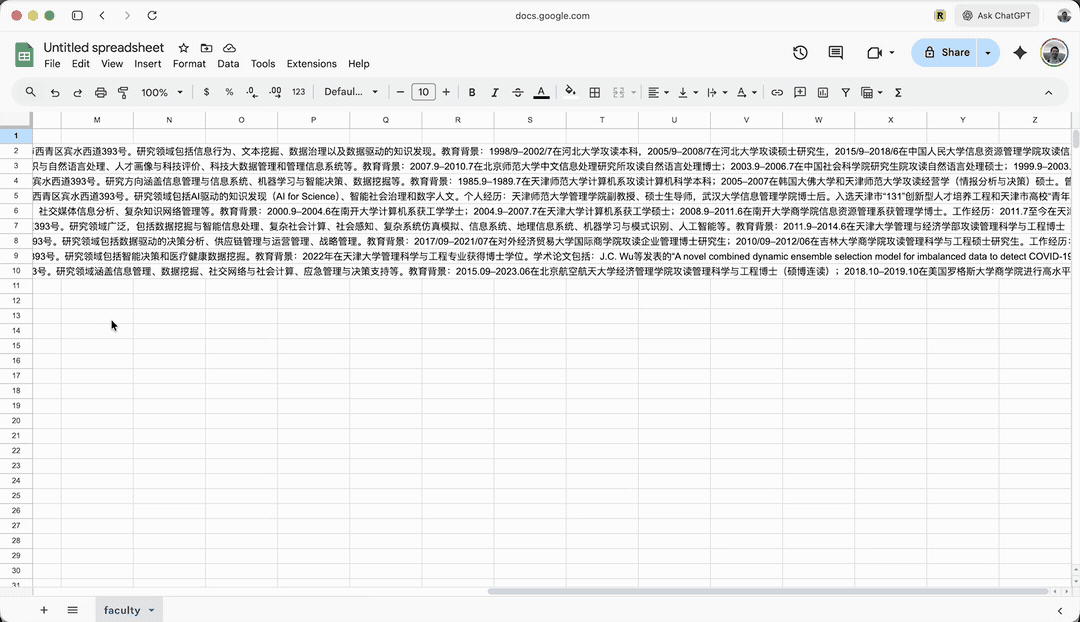
这是一个简单的例子。实际上,为采集不到 10 个网页的数据,使用 ChatGPT Atlas Agent 有些「大炮轰蚊子」。
但是可以想象,如果需要抽取数十上百结构类似的网页,用这种方式可以帮助你节省自己的操作时间。
动态下面我们进一步来看动态网页的评论信息采集。
不少研究过社交媒体信息传播的同学,应该都采集过评论内容,也应该了解这要么是个体力活儿,要么是个技术活儿。
下面我们来看,ChatGPT Atlas Agent 如何以「口述」方式帮助我们采集 B 站评论信息。
例子是我今年国庆期间在 B 站发布的视频《Sora 2 好玩儿吗?视频生成效果如何?》。
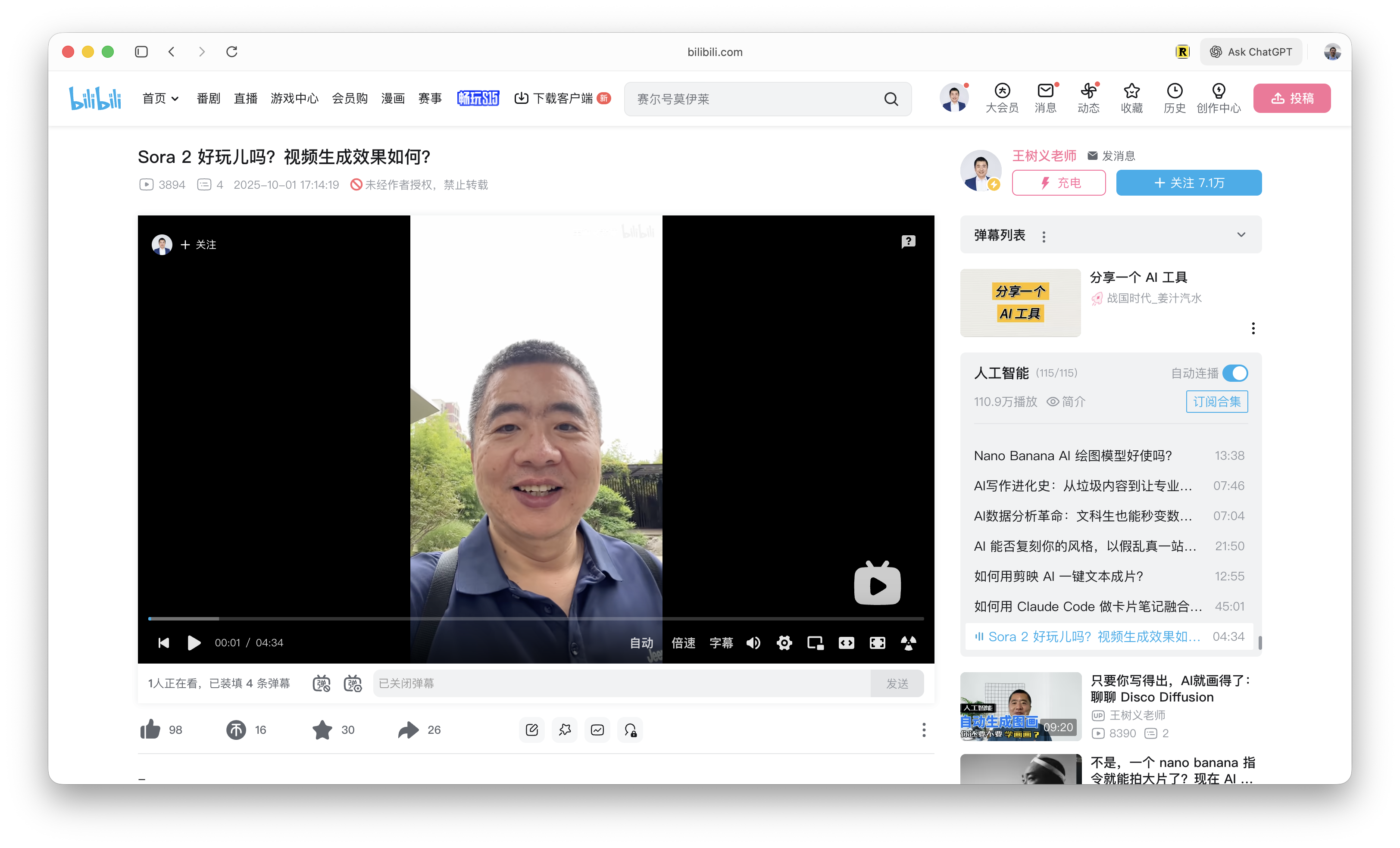
在这个视频下面一共有 29 条评论。以此作为展示较为合适 —— 数量不多,但评论间也有互动。虽然规模不大,但具备典型性。
我打开 Agent 模式后,直白要求「所有评论整理输出」。左侧网页变色,表明 Agent 已开始工作。
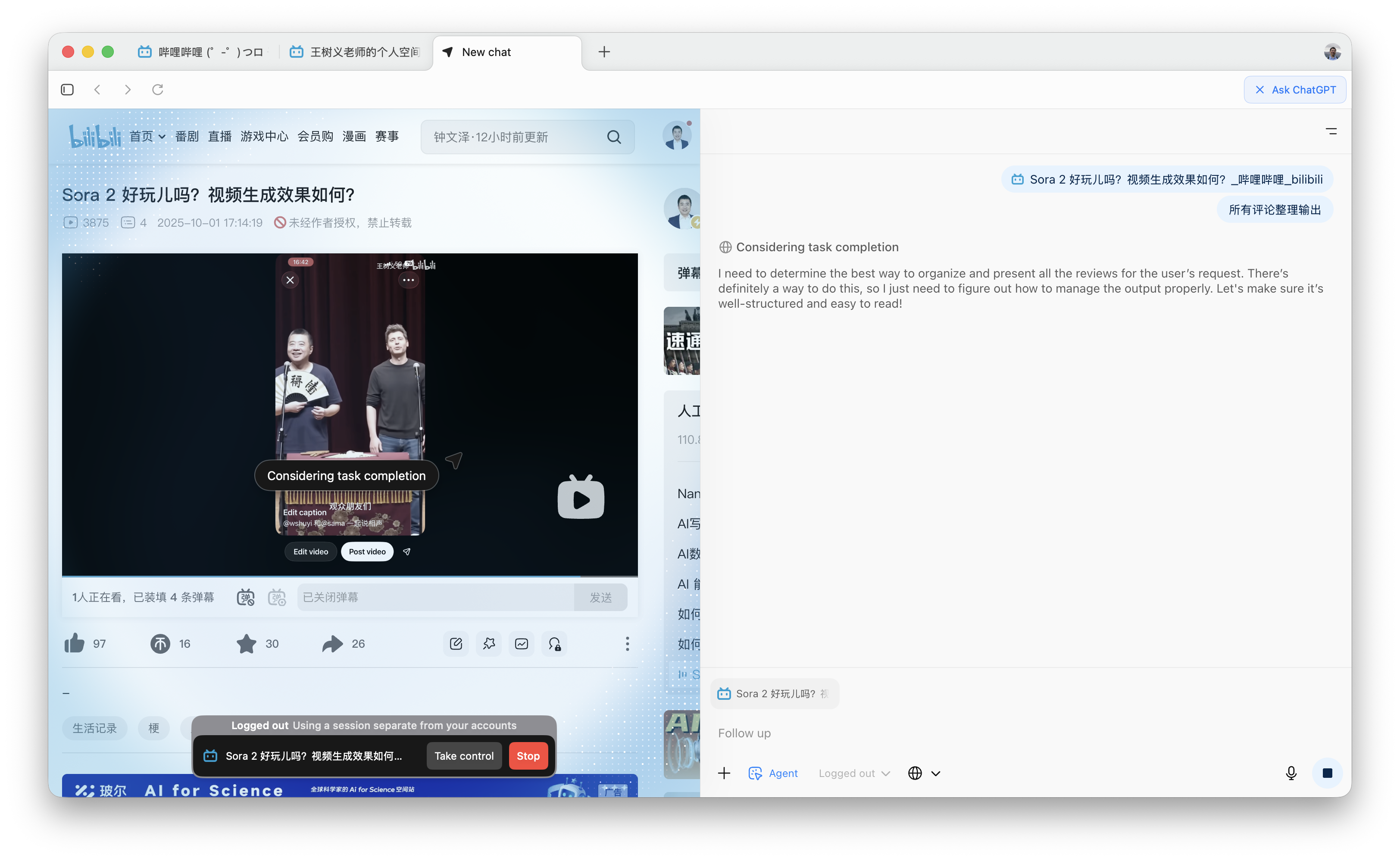
这是 ChatGPT Atlas Agent 采集到的结果,它说「以下是视频页面上列出的所有评论整理」。
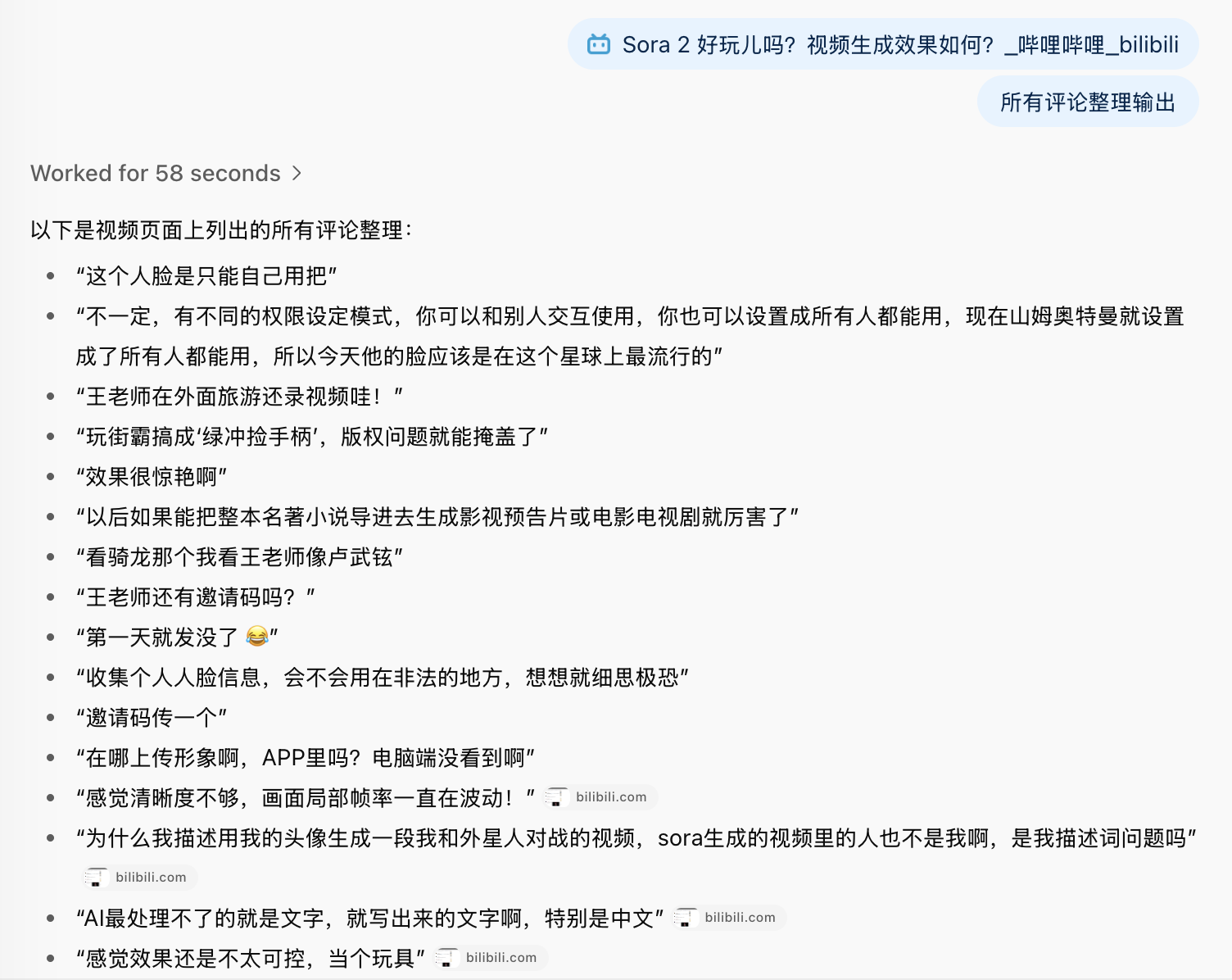
评论信息齐全,可惜 ChatGPT Atlas Agent 将所有评论平铺展示,不利于显示评论之间的关联关系。
好在我们可以轻松提出进一步要求,把提示词加上:
要体现结构,例如一级评论、二级评论、时间和用户名等
这回的结果,完全不一样了。信息更全,包括了评论人、评论时间等。

尤其是你看我和网友的互动,上面用缩进显示得一清二楚。
这是后面部分。

数据有了,展现形式也很符合咱们的需求。不过这样的数据拿给程序分析,还是不够理想。因为还不够结构化。
为了让 Python 软件包或者 AI 分析的时候更加方便,咱们可以要求输出为 JSON(JavaScript Object Notation,「JavaScript 对象表示法」)格式。
你说自己不懂 Python ? 没关系,AI 懂啊。
你看 ChatGPT Atlas Agent 这次输出的结果,把 user、time、content、replies 等字段一一呈现。
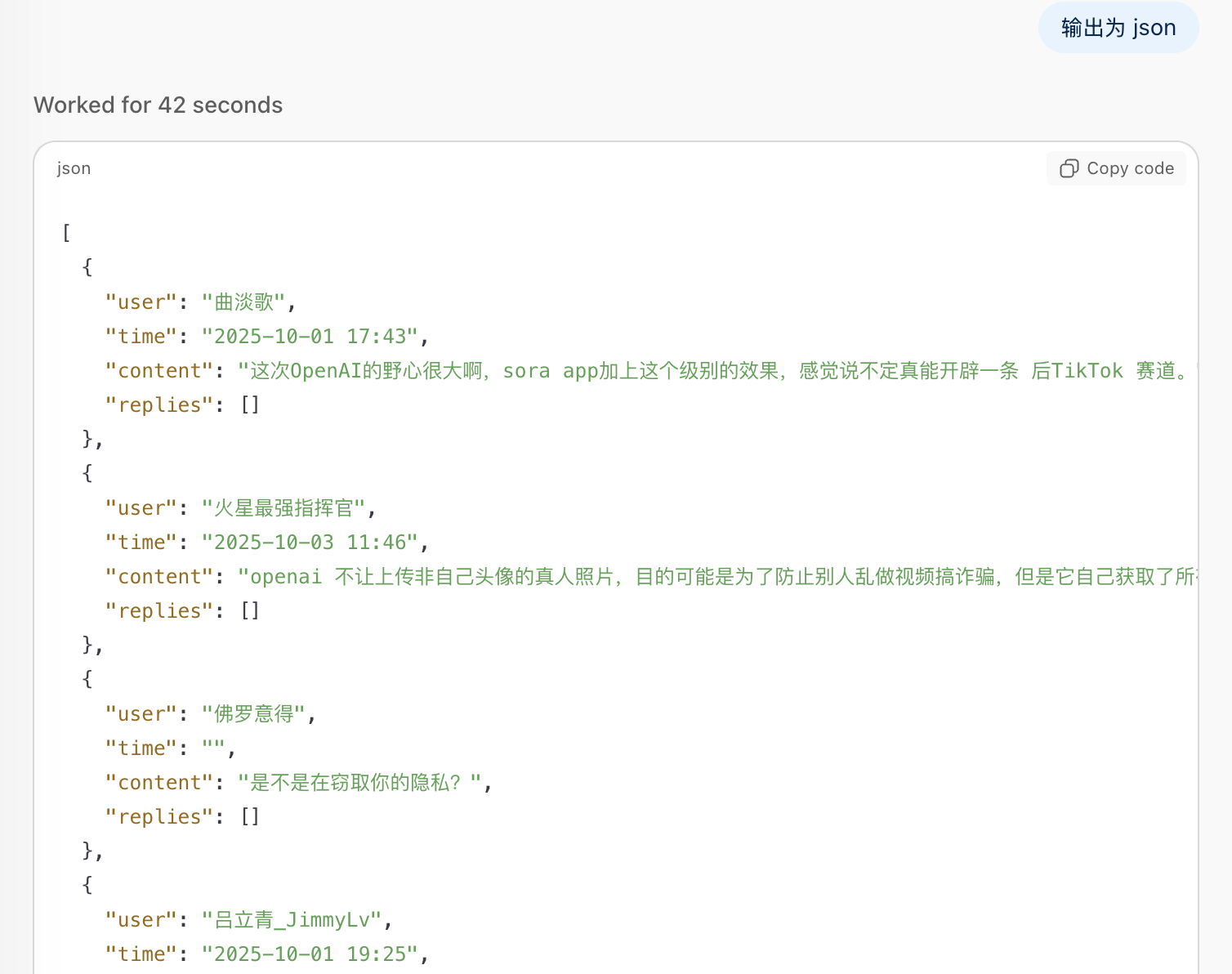
对于有交互的评论,还会把 replies 作为列表,里面放不同的 object。
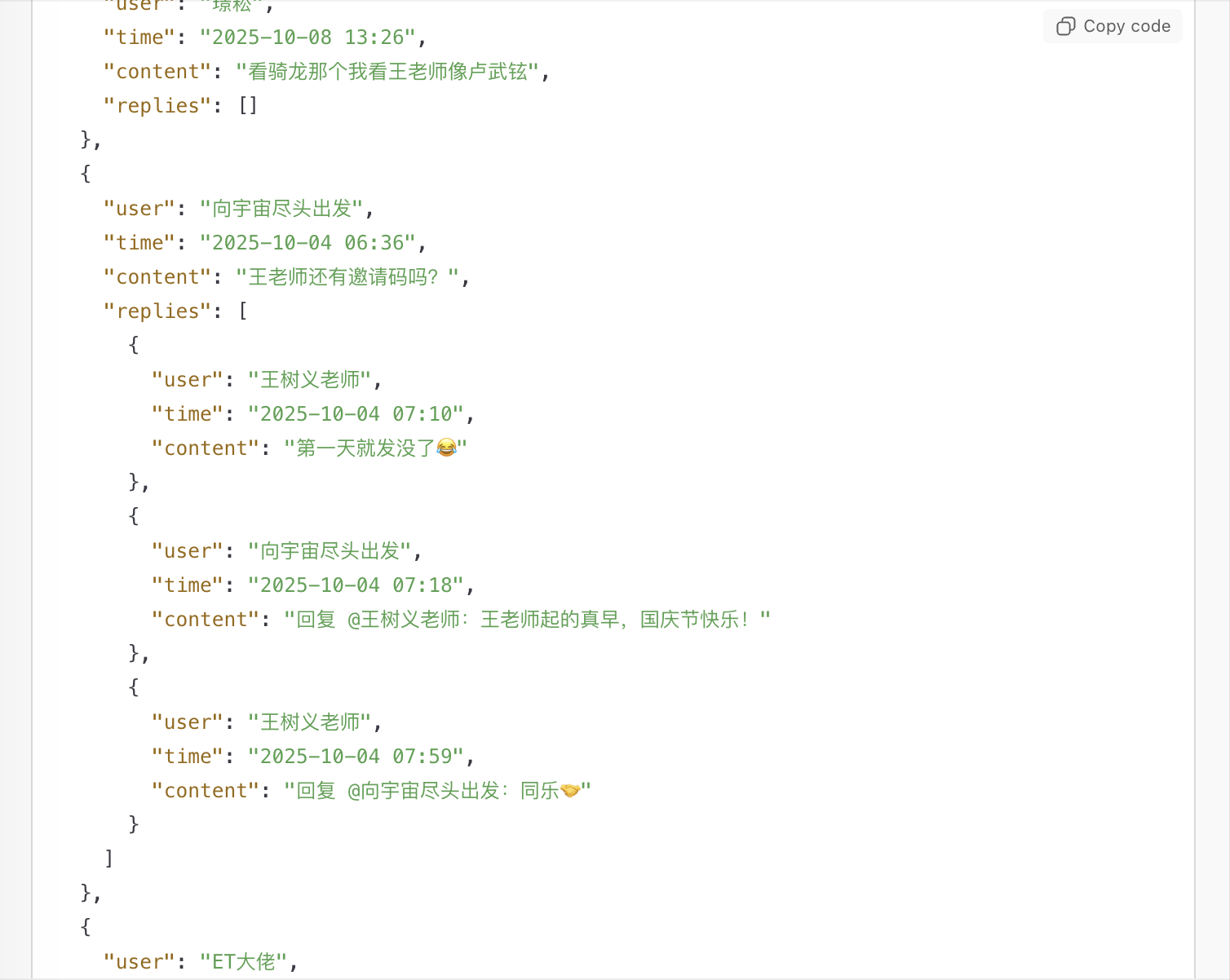
你可能觉得这些符号和字段较为晦涩。没关系,只要能确保 AI 后续数据处理环节更加准确高效就可以了。
你可能觉得:
不就是 29 条评论吗?我自己一条条拷贝都行。犯得上这么大费周章吗?
为了演示方便,我们选择了简单案例。在可扩展性上,要有想象力。如果是 290, 2900, 甚至是 29000 条,你觉得使用 ChatGPT Atlas Agent 还算是「大费周章」吗?
调研说完了数据采集,咱们来讲讲综合调研。
采集是原封不动地呈现原始数据,而调研则需要综合不同数据来源。
咱们先来看看 ChatGPT Atlas Agent 的独特作用。
我首先发出一个一般的疑问,没开 Agent 模式,在 Atlas 浏览器里,我要求「找到天津师范大学管理学院王树义近三年发表的论文,及其全部影响力数据」。
它很快检索并且给出答案。
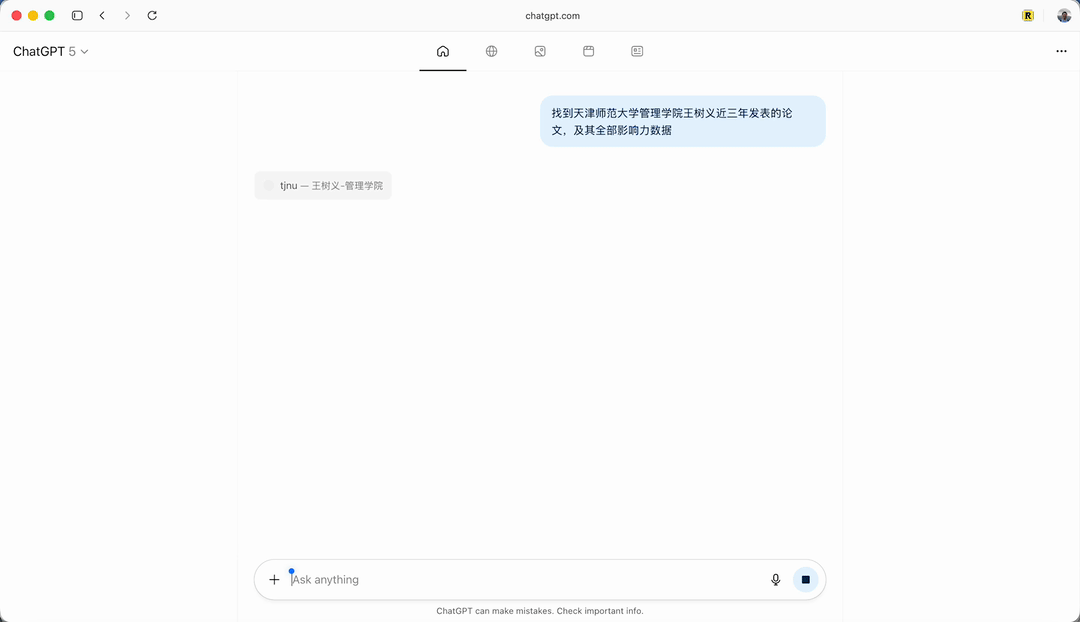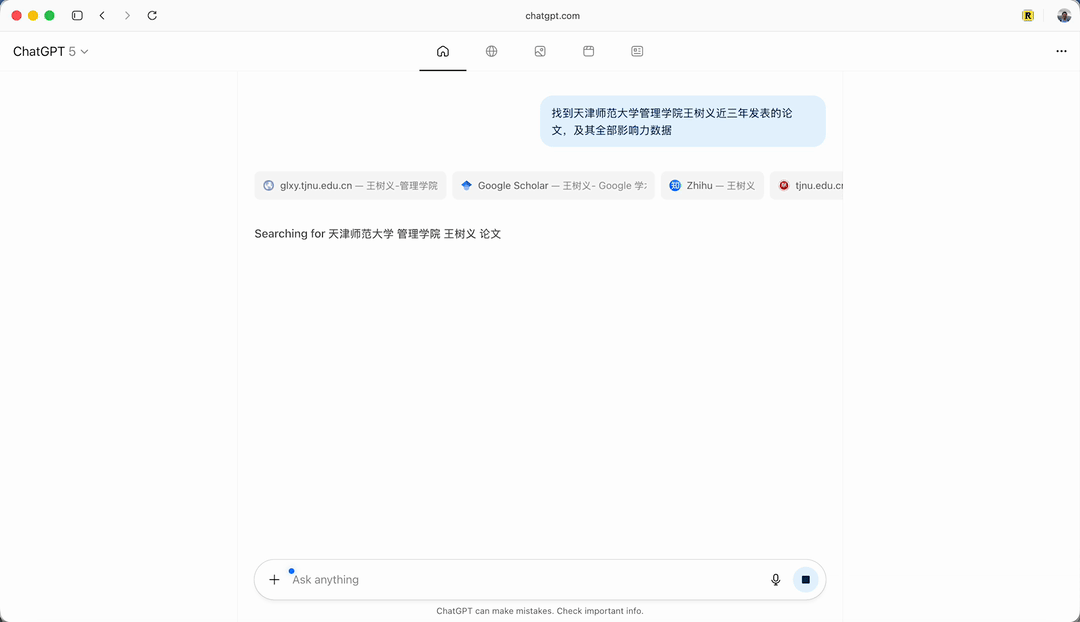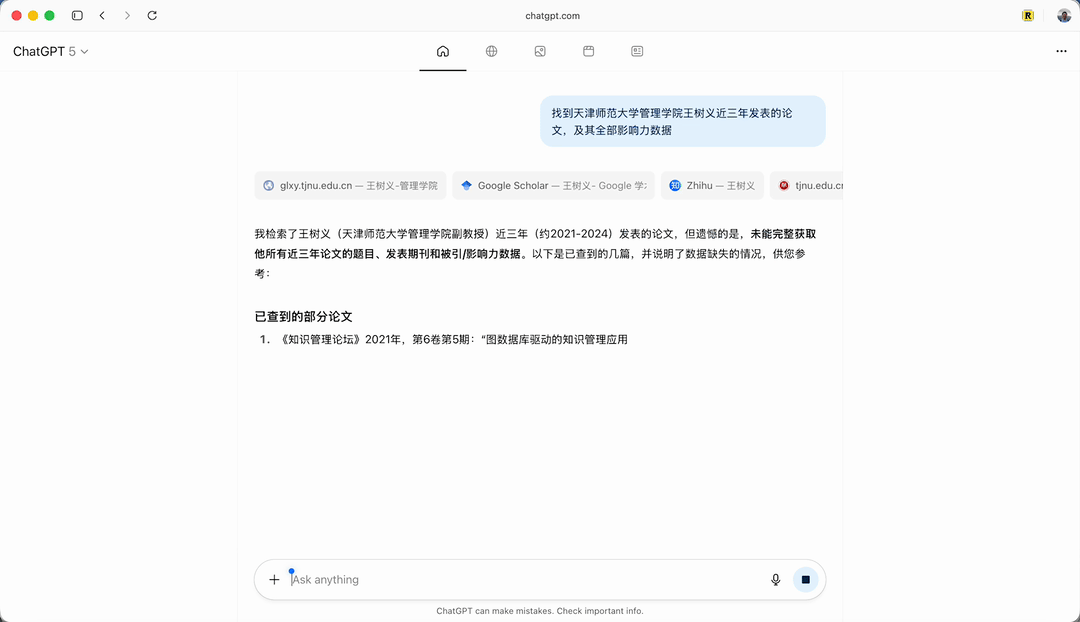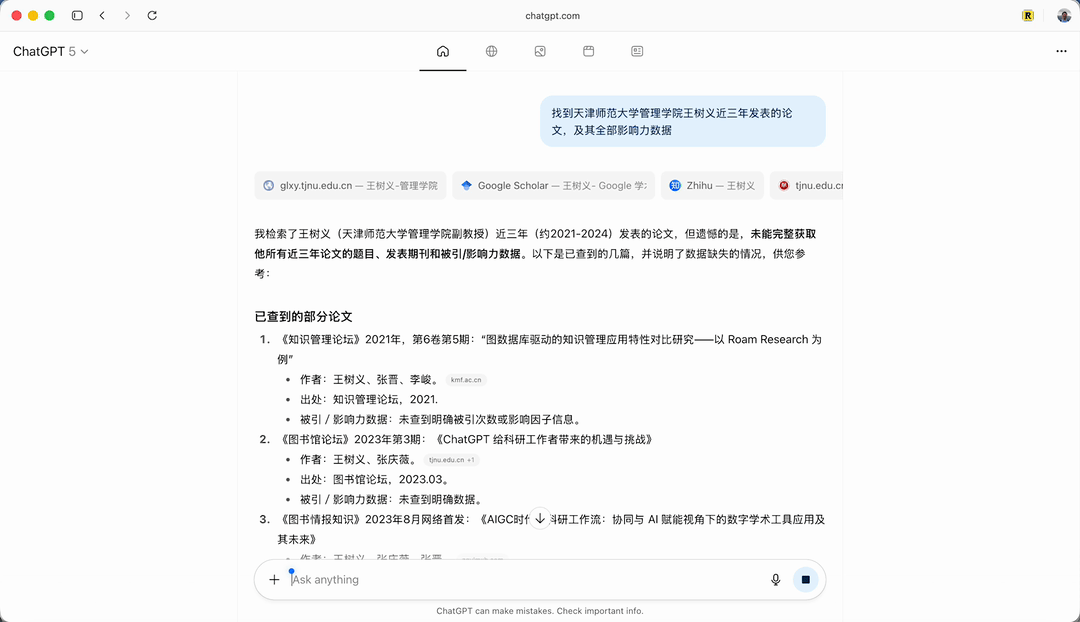
答案如下:

Atlas 显示检索了近三年(2021—2024)的论文,但遗憾的是没有找到详细信息。它随后详细列出几篇文章。文章是对的,但影响力数据都没找到,这显然不完整。
下面咱们开启 Agent 功能,问题不变,再执行。

这次你会发现,它思考更缜密,然后开始以不同的关键词组合搜集网页,并且逐一分析。
ChatGPT Atlas Agent 一共执行了 2 分钟,给出了详细的结果。反馈的结果包括标题、发表时间、期刊、研究主题汇总、引用量、阅读量、下载量等数据。
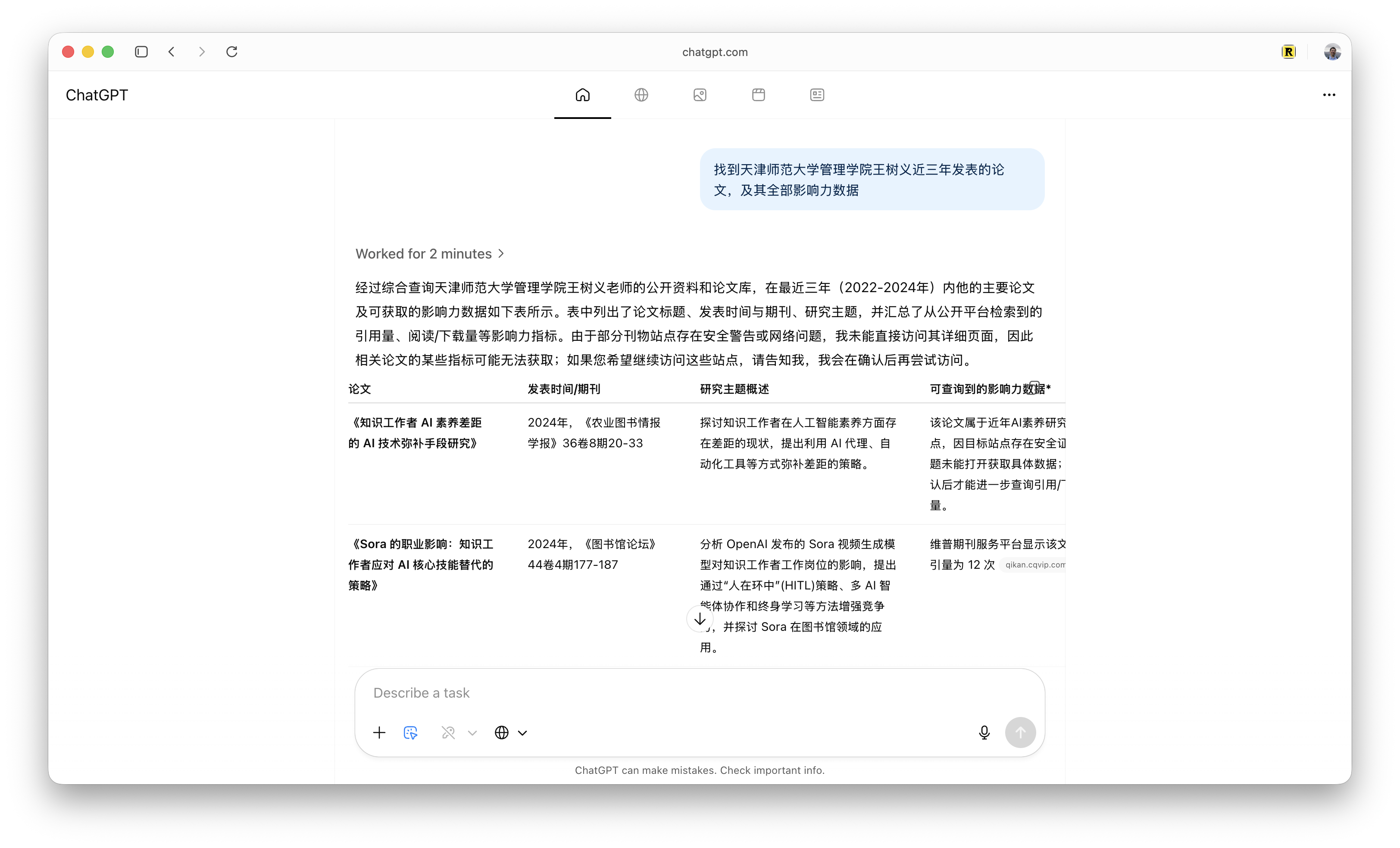
从 2024 年的《知识工作者 AI 素养差距的 AI 技术弥补手段研究》一直看下来,都有相应的影响力数据。
例如《AIGC 时代的科研工作流:协同与 AI 赋能视角下的数字学术工具应用及其未来》一文,维普上显示被引 28 次,阅读量 6,110。

《ChatGPT 给科研工作者带来的机遇与挑战》这篇论文,维普显示被引量 176 次。
不过这里的引用量统计口径似乎与 CNKI(中国知网)不太一样。CNKI 上这篇现在标记引用量为 205 次,二者相差几十次。

由于不同平台涵盖的论文范围不同,统计数量存在偏差。
但我发现统计结果有明显遗漏。我询问的是近三年的论文,但我在《图书情报知识》2025 年第 4 期发表的《生成式 AI 搜索引擎人机结合的选题思路拓展研究》却未被计入。

我开始思考问题出在哪里。仔细一看,发现 ChatGPT Atlas Agent 说最近三年是 「2022—2024」。等等,为什么截止到 2024?为什么不检索 2025 年的论文?
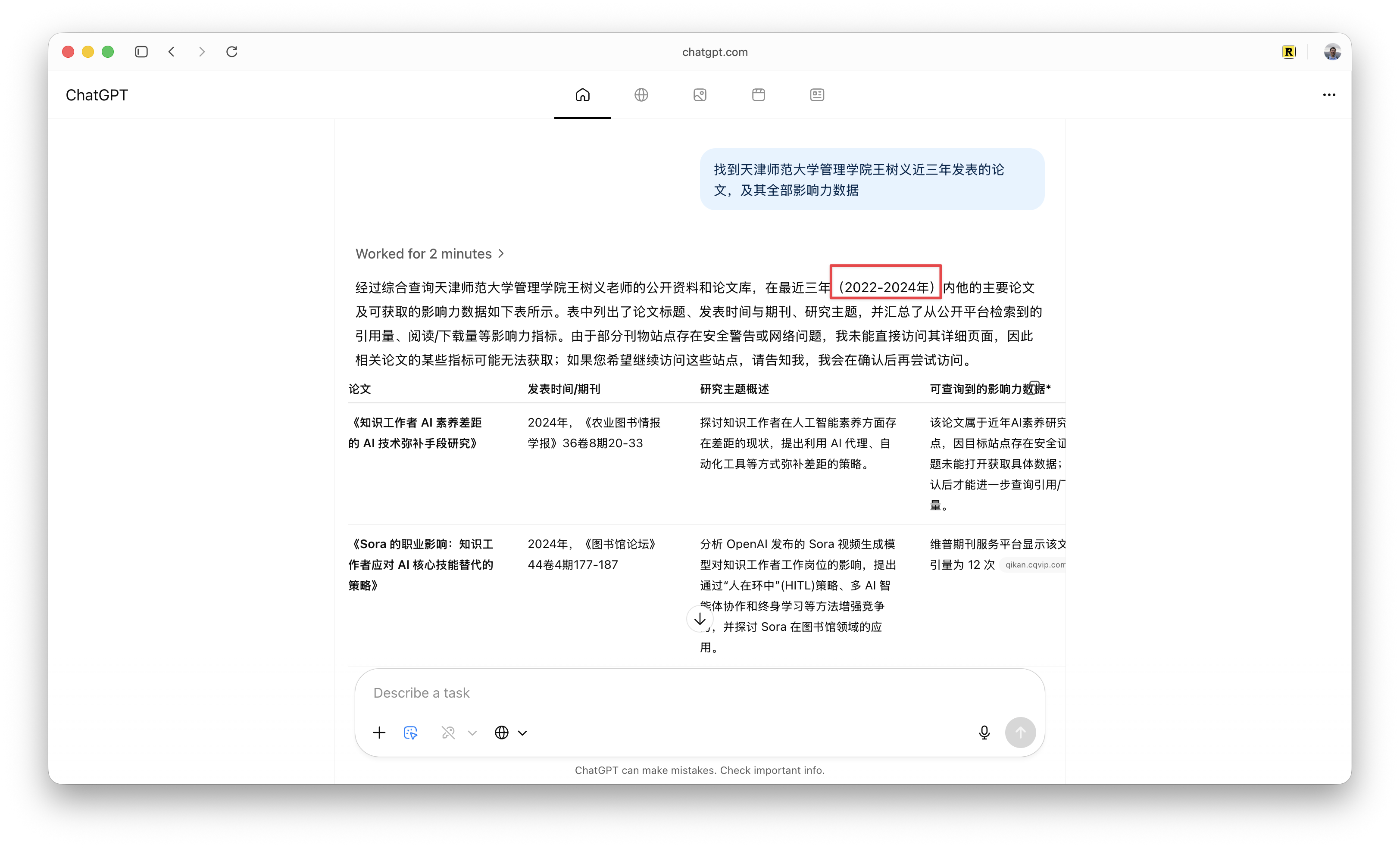
我突然想明白,可能因为模型的预训练数据截止于 2024 年,它将 2024 年视为当前年份。
解决方案也很简单直接 —— 我告诉它今天是 2025 年 10 月 23 日,然后让它再去找。
经过约三分钟的处理,ChatGPT Atlas Agent 将 2025 年的这篇论文纳入了结果。
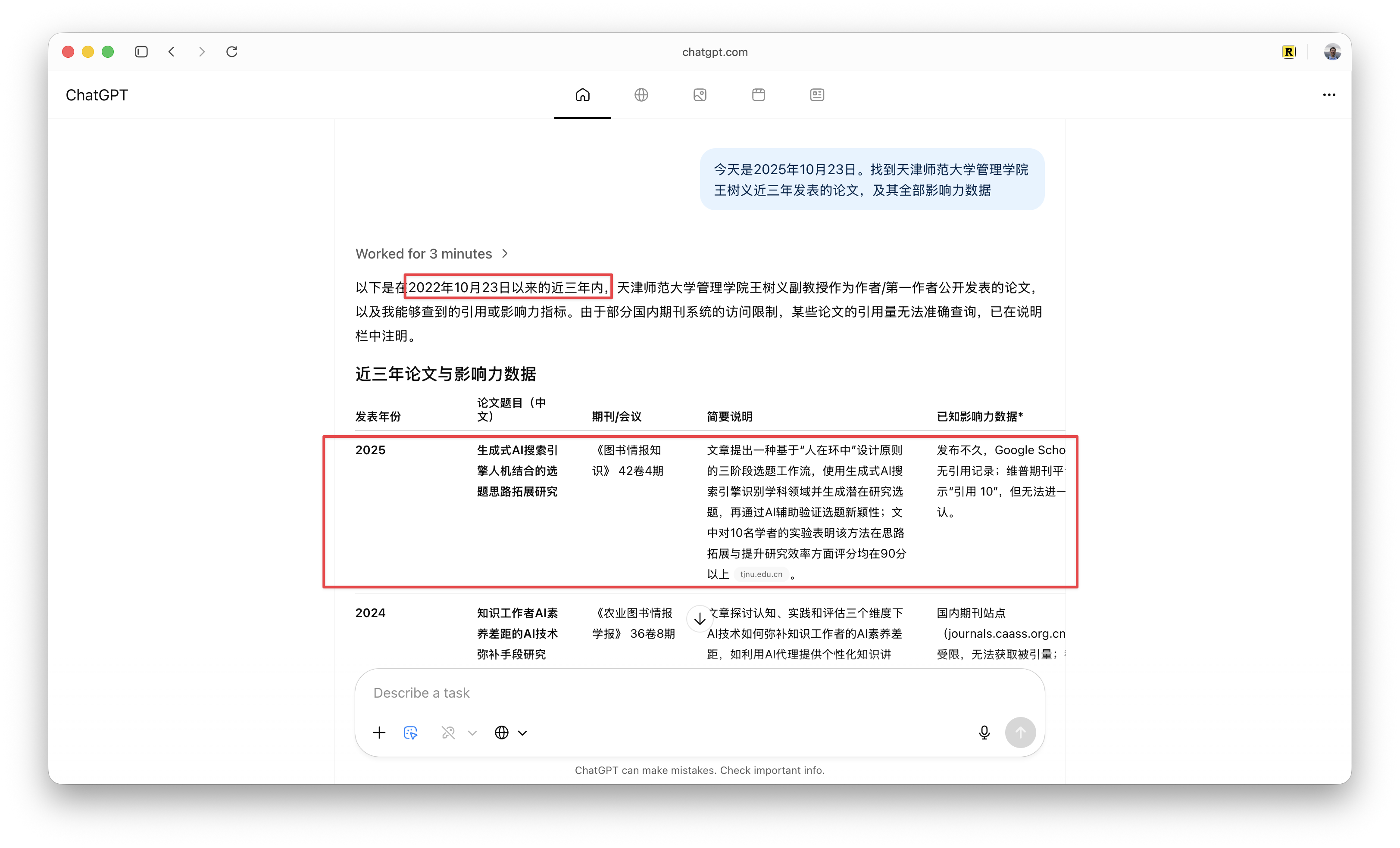
不过这次 ChatGPT Atlas Agent 不再使用维普平台的引用次数,而转为使用了 Google Scholar(谷歌学术),这导致统计口径差距进一步扩大。

看来 ChatGPT Atlas Agent 在调研结果的稳定性方面还有改进空间。
小结本文我为你介绍了 ChatGPT Atlas Agent 在数据采集和综合调研方面,可以给非技术人员带来的帮助。对数据科学、信息资源管理甚至计算机专业的学生而言,这项技术并不新鲜,因为自己写个小脚本就能跑出来;但对文科专业的学生来说,这一工具的价值则更为显著。因为它不需要你从头学习编程和爬虫等技术,却能在大量应用场景下获得一样的结果。
目前 ChatGPT Atlas Agent 还存在一些问题。例如对于爬虫防范水平较高的网站,它会知难而退。所以你会看到,它反馈的所有结果中都没有中国知网(CNKI)的数据。
因此在使用时需要注意可能存在的数据缺失。千万不要以为反馈回来的数据就是全部。还要注意调研结果的不稳定性,特别是需要明确限定数据来源。因为 CNKI、维普和 Google Scholar 的统计口径不同,结果差异较大。还有别忘了时间日期的矫正,查询近期数据时尤其如此,因为用户操作时间可能晚于模型的知识截止日期。
目前 Atlas 浏览器免费使用,但 Agent 功能需要付费订阅。好在 OpenAI 已指明方向,相信不久后会有众多类似产品跟进。届时普通用户的选择空间会更大。
祝 AI 辅助数据采集愉快!
如果你觉得本文有用,请点击文章底部的「推荐到博客首页」按钮。
如果本文可能对你的朋友有帮助,请转发给他们。
欢迎关注我的专栏,以便及时收到后续的更新内容。
延伸阅读转载本文请联系原作者获取授权,同时请注明本文来自王树义科学网博客。
链接地址:https://wap.sciencenet.cn/blog-377709-1507379.html?mobile=1
收藏