
 精选
精选
感受技术进步的同时,你也应该防范它带来的风险。

今天咱们来聊聊最近一个很火的 AI 绘图功能 —— 它在社区里的昵称是 Nano Banana,估计你今早已经被它刷屏了。我们来看看它到底好不好使。
这个名字听着有点奇怪,因为它并非一个正式的产品名。它最初是大家在模型竞技场里发现的一个代号,指向的是 Google Gemini 模型中一项原生的图像生成新功能。这项功能并非一个独立的模型,而是深度集成在大语言模型(Gemini 2.5 Flash)之中,让 Gemini 具备了直接绘图的能力。

前些日子,这个功能先在一些 AI 模型竞技场上进行了灰度测试。用户无法主动选择它,但在模型匿名对战时,它会冷不丁地冒出来。大家很快就发现,这个模型的图片生成效果和能力比同场竞技的其他模型要强得多,因此都盼着它早日正式上线。因为当时的代号是 Nano Banana,这个名字就流传开来,成了大家对这项新功能的昵称。
当它真正上线后,名称改为了 Gemini 2.5 Flash Image. 社区非常兴奋,社交媒体上立刻涌现了大量的测试结果。下面就带你看看我自己的测试体验。
从《阿甘正传》说起要测试,我们得先选个有意思的题目。我上中学时特别爱看《阿甘正传》这部电影,它在豆瓣上的评分至今高达 9.5 分,可以说是影史经典。

电影里有个片段,不知道你还有没有印象 —— 阿甘在白宫见到了肯尼迪总统。我们都知道,肯尼迪总统在 1963 年就遇刺身亡了,而这部电影是 1994 年上映的,显然不可能让总统本人来参演。那这个镜头是怎么实现的呢?

影片里的这个片段看起来非常自然。我当时觉得无比神奇,后来还特意让 GPT-5 Thinking 模型帮我查找资料,了解背后的制作过程。

以今天的技术,让一位逝去的演员在电影里 “复活” 已经不是难事,但在当时,这背后涉及的技术相当复杂。团队需要让演员在蓝幕前表演,然后通过数字技术处理成老胶片的效果。为了让肯尼迪 “开口说话”,制作团队需要将配音演员的嘴唇和下颌区域进行数字替换,再结合抠像、变形、转描、颗粒与色彩匹配等一系列繁琐操作。可以想象,在那个年代制作这么一个几秒钟的镜头,成本有多高,过程有多麻烦。
AI 图像合成的进化其实到了 2024 年,我们已经可以轻松地把自己的形象放到任何场景中了。之前我也给你演示过,比如站在埃菲尔铁塔前。

或者和一条龙合影。

当时要做这样的图片,流程已经比原来大大简化,你不需要折腾像 ComfyUI 那样复杂的工作流。我的做法是,提供几十张个人高清照片,放进一个特定图片应用里进行微调(fine-tuning),训练出一个关于我的人物模型。之后,这个模型就可以生成我出现在不同场景的图片了。但这个过程依然有些麻烦,而且你的数字形象被锁定在了那个特定平台上,无法轻易迁移。
现在有了 Gemini 的这项新功能,你就可以尝试单样例生成 —— 也就是只给它一张照片,就能实现想要的人物和场景合成。我们来看个具体的例子。
实战测试:三张图搞定「跨时空合影」这次测试,我准备了三张图片:
人物一:一张我自己的照片,前两天在第五届开智大会的讨论环节上拍的,笑得比较灿烂,我挺喜欢。
人物二:一张奥黛丽·赫本的经典照片,我想和一位历史名人同框出镜。
背景图:一张我在国家自然博物馆拍的非洲草原场景,里面有鸵鸟、狒狒,非常有动感和紧张感。



我的目标是:把我和赫本并肩放在这个非洲草原的场景前。我们使用的工具是官方的 Google AI Studio。
打开之后,你会在显要位置看到「What's new」里介绍了这项 Gemini 的原生图像生成功能。
它默认的示例提示词是生成一个香蕉,这大概也是对 Nano Banana 这个代号的致敬吧。我们不用它的示例,直接把刚才那三张图片上传,然后给出提示词:
图一中的人物与图二中的人物,并肩站在图三的场景之前握手,女士举起手机自拍。
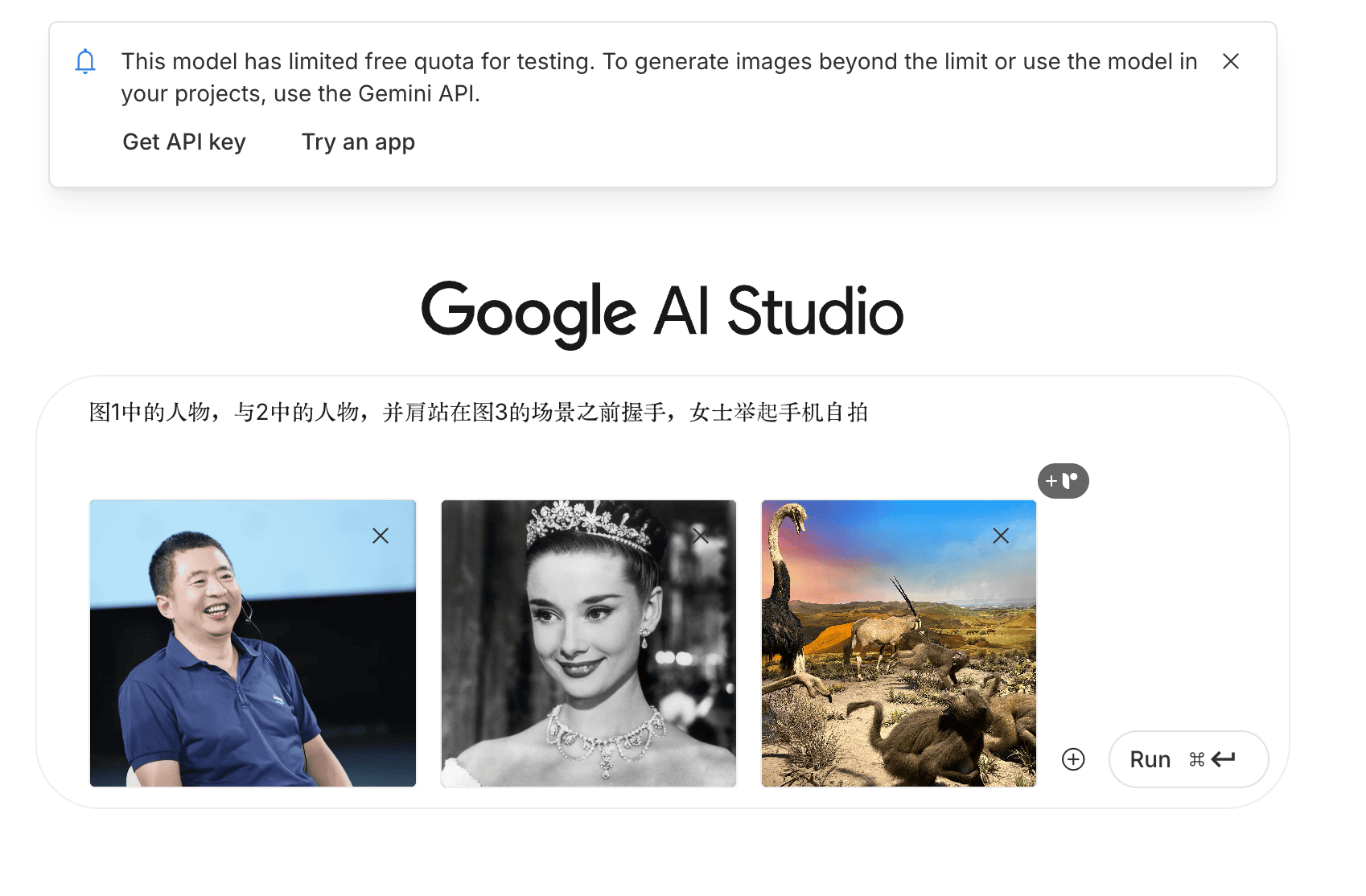 要求很明确,我们来实际运行一下。点击运行后,它会先分析这三张图,然后开始生成。我估算了一下,整个过程耗时和 GPT-4o 的图像生成差不多。
要求很明确,我们来实际运行一下。点击运行后,它会先分析这三张图,然后开始生成。我估算了一下,整个过程耗时和 GPT-4o 的图像生成差不多。
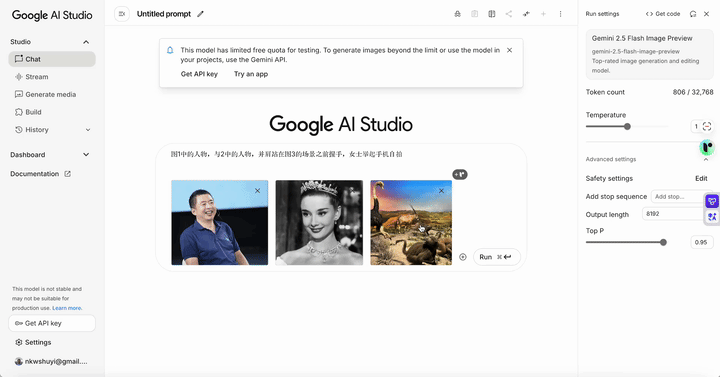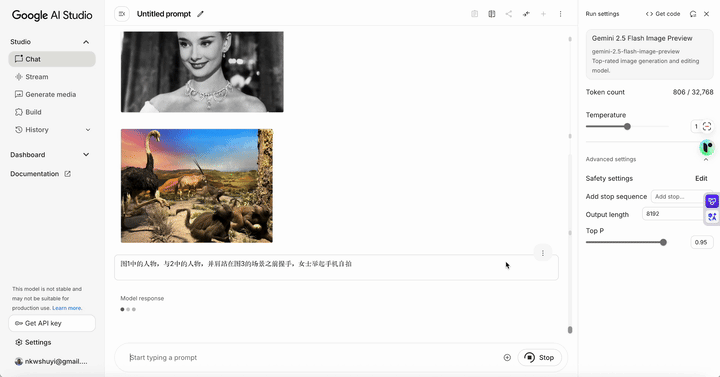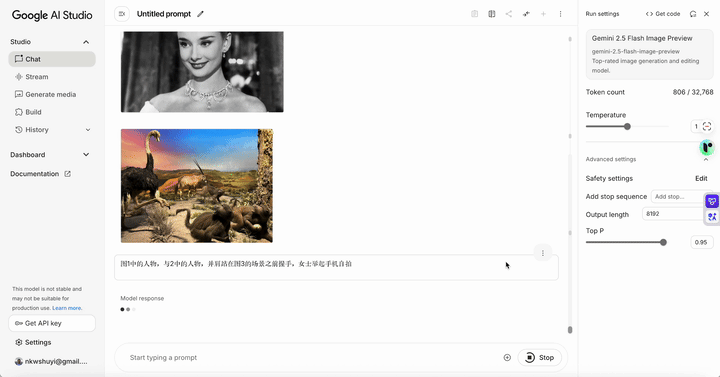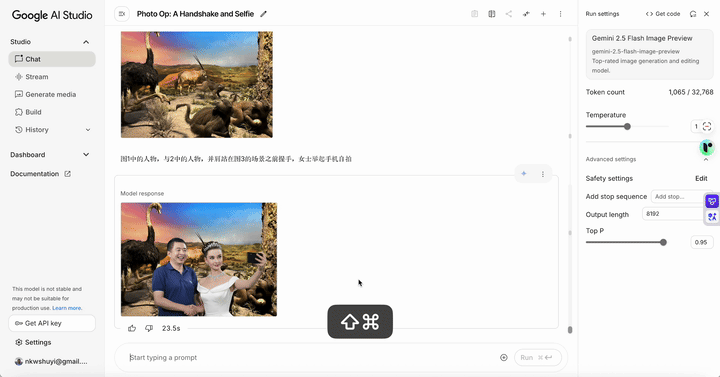
耐心等待片刻,结果就出来了。结果相当惊艳!虽然系统还在进行一些局部细节的优化,但主体画面已经生成。
放大看看。
我和赫本站在非洲草原背景前,由她举着手机自拍。你会发现,我们俩的视线都非常自然地盯着手机的镜头 —— 这个细节把握得非常好。既然是自拍,眼睛当然要看镜头。整个人物和背后的场景融为一体,毫无违和感。
看到这个结果,我真的觉得太棒了。仅仅用了三张照片,所有我们想要的效果都实现了,人物的一致性也保持得非常好。技术的进步,让曾经无比复杂的图像合成变得如此简单。以后我上课如果需要什么特定的合成场景图片,用这个工具一下子就能搞定。
另一妙用:批量生成文章配图看完了强大的照片合成功能,我们再来看看它的其他玩法。一个在我日常工作中非常重要的用途,就是用它来绘制卡通风格的图像,作为文章的题图或插图。
这次,我给它的指令是:
把用户的输入认真理解后绘制出来。其中如果提到 AI 的意象,用机器人来指代。在与内容不冲突的情况下,画风尽量要清爽明快、积极正面,建议使用 Q 版动画形式,16:9 尺寸。

随后,我把我最近在知识星球上写的一篇长文《氛围编程实战:Python 实现视频转 GIF 动图智能自适应优化》全文贴了进去,一直到最后的延伸阅读链接。

通常情况下,用 GPT-4o 的图像功能处理这类需求,它只会生成一张图。但 Nano Banana 的反应让我大吃一惊 —— 它直接给我列出了一个包含十张图的清单,说这些都是它认为可以为文章增色的插图创意,包括:封面图、痛点展示、传统工具的瓶颈、氛围编程的起始、AI 协作解决问题、结果展示、重器轻用的理念、享受技术红利、总结分享。看得我都有些应接不暇。

紧接着,它就开始一张一张地生成这些图片。这个过程我就不完整展示了,你会发现它画图的速度比刚才合成照片时要快得多。它就像一个任劳任怨的插画师,一篇文章喂进去,十张配图自动给你画出来,真正做到了 “量大管够”。
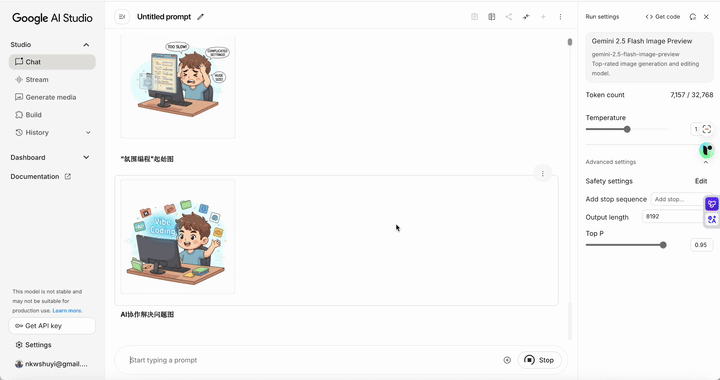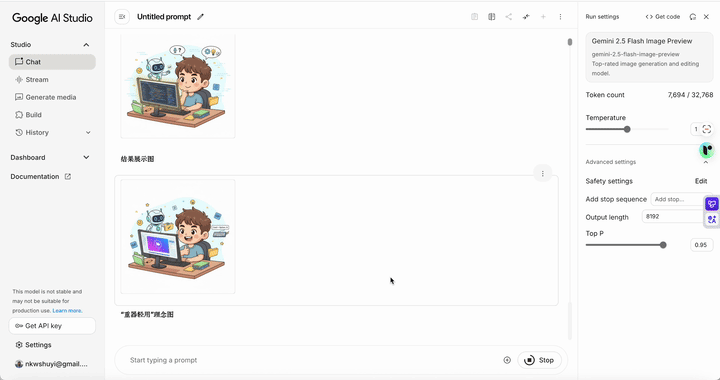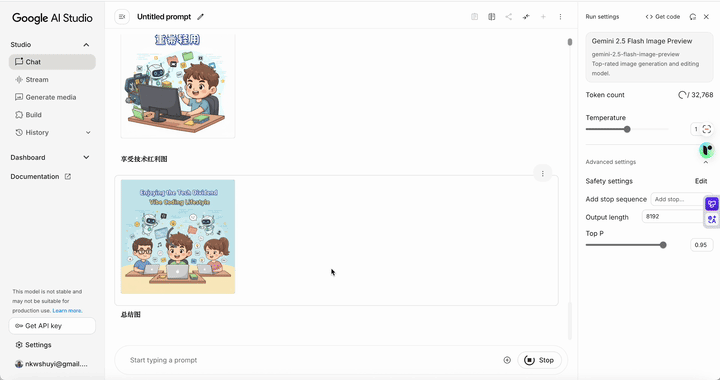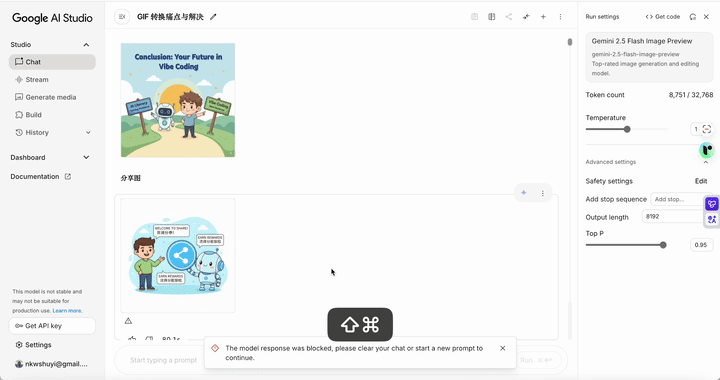
我们来看看成品。虽然图片中的中文文字显示还有问题(这也是目前许多海外模型的老毛病),但无论是画风、场景构图,还是它所展现的细节,我觉得都相当不错。

比如,这张图表达了参数太多导致调整缓慢的痛点。

这张图展示了我们用氛围编程进行协作并快速得到结果。

还有一张图形象地画出了如何将不同的 Web coding 工具结合起来实现 “重器轻用”。

总的来说,在这个用途上,Nano Banana 中文处理能力是短板。但别着急,我们都知道国产大模型在中文方面已经做得非常出色。这些技术一旦融合,我们未来用上既有强大绘图能力,又能深刻理解和表达中文的 AI 工具,是指日可待的。目前,一个简单的临时方案是在提示词里加个补丁,要求图片里如果出现文字,一律用英文展示。
 小结
小结经过一番测试,我觉得 Nano Banana (Gemini 2.5 Flash Image)的绘图功能非常好用。它基本上把我之前使用的多种绘图工具的功能整合到了一起,无论是修改图片、合成照片,还是直接从文本生成图像,都极其方便。
特别是它支持三张图同时输入进行合成处理的能力,非常强悍。人物特征的一致性保持得很好,还能根据你的要求自动调整视线角度和表情,实在太棒了。如果你从事创意相关工作,这些功能想必会对你大有裨益。
但与此同时,我也想再次强调技术进步带来的风险。
只要别人拿到你的一张照片,理论上就可以让你和任何人在任何地点「做任何事」。这项技术给我们敲响了警钟。你看,就连赫本那张几十年前的黑白老照片,都能被还原成一个现实场景中的彩色人物,肤色和质感都高度逼真。
所以,到了今天,与其反复强调 “注重隐私保护、不要轻易发布照片”,意义恐怕已经不大了。因为在数字时代,你很难做到一张照片都不出现在公共视野中。
相比之下,更重要的事情是提升我们自己的 AI 素养。遇到事情,不要慌张。电信诈骗和敲诈勒索,利用的都是人们在信息不对称下的恐惧和脆弱。如果你因为一张合成照片就乱了阵脚,那会非常被动。因此,我们必须主动去了解,现在的 AI 技术已经发展到了什么阶段。只有具备了这种认知,我们才能做到不信谣、不传谣,不被别有用心的人利用技术带到沟里去。
赶紧试试 Gemini 里这项被昵称为 Nano Banana 的新功能吧,也欢迎你把自己的创意成果分享到留言区,咱们一起交流。
祝 AI 绘图愉快!
如果你觉得本文有用,请点击文章底部的「推荐到博客首页」按钮。
如果本文可能对你的朋友有帮助,请转发给他们。
欢迎关注我的专栏,以便及时收到后续的更新内容。
延伸阅读- 看着星友 3 分钟抢光 AI 调研工具内测名额,我突然明白了什么叫生产力革命
- Midjourney 能识图了,这是个好事儿吗?
- 人工智能绘图应用 DALLE 2 开始公开测试了
- AI 真要成精了?ChatGPT 上手体验
- AI 应用蓬勃爆发,你的「护城河」足够宽吗?
转载本文请联系原作者获取授权,同时请注明本文来自王树义科学网博客。
链接地址:https://wap.sciencenet.cn/blog-377709-1499308.html?mobile=1
收藏