博文
精选好文 | 大语言模型创造力的评估与理解
||

在自然语言处理领域,大语言模型(LLM)的快速发展日益受到关注。大语言模型在各种任务中都展现出了较强的创造力。然而,评估这种创造力的方法尚不完善。对大语言模型创造力的评估需考虑模型与人类的差异,要求兼顾准确性与效率,同时进行多维度衡量。来自中国科学技术大学与中国科学院计算技术研究所的研究者们搭建了一个高效评估大语言模型创造力水平的框架。本研究通过改良Torrance创造思维测验,评估了多种大语言模型在7项任务中的创造力表现,重点关注其流畅性、灵活性、原创性和精进性这四项标准。在此背景下,本研究开发了一个包含700个问题的综合测试数据集,以及一种基于大语言模型的评估方法。此外,本研究还对大语言模型面对不同提示词和角色扮演情境时的反应进行了新的分析。本研究发现,大语言模型的创造力主要在原创性方面表现不佳,而在精进性方面表现出色。同时,提示词的使用和模型角色扮演的设置能明显影响其创造力。实验结果表明,多个大语言模型之间的协作能够提升原创性。值得注意的是,本研究发现,在影响创造力的人格特质方面,人类评估与大语言模型评估结果存在共识。这些发现表明了大语言模型的设计对其创造力有重要影响,并在人工智能与人类创造力之间架起了桥梁,为理解大语言模型的创造力及其潜在应用提供了深刻见解。
图片来自Springer
全文下载:
Assessing and Understanding Creativity in Large Language Models
Yunpu Zhao, Rui Zhang, Wenyi Li & Ling Li
https://link.springer.com/article/10.1007/s11633-025-1546-4
全文导读
近年来,在人工智能领域,大语言模型发展迅猛,且日益先进。大语言模型处理各类常规自然语言处理任务(如推理和自然语言理解)的能力已显著提升。不仅如此,大语言模型在广泛的应用场景中也展现出重要价值。从将基础文本转化为引人入胜的叙事、开拓故事创作新边界,到解决复杂的算法问题,这些模型的表现看似具有可被解读为创造力的特质。大语言模型的这种创造力已在多个领域中实际体现:在科学研究中,大语言模型可以协助人们生成思路与建议;在教育领域,大语言模型可以提供个性化的学习体验;在娱乐产业,大语言模型可以参与创作音乐和艺术作品。在其诸多应用中,大语言模型似乎展现出生成原创文本的能力,协助处理涉及想象力与创造力的任务,这表明大语言模型可能确实具备创造力的某些要素。
在大语言模型所展现的广泛能力中,创造力是令其成为强大模型的关键因素。然而,在这些模型强大的能力背后,有一个值得仔细审视的重要问题:这些模型是否真的拥有真正的创造力?抑或其表面的智能仅仅只是一种假象——不过是其训练范式所生成的对人类思维的复杂模拟?这一问题触及大语言模型智能的本质,解释起来并不容易。既然大语言模型已展现出相当强的创造力,那么理解这种创造力的程度与特性便至关重要。深入洞悉大语言模型的创造力,不仅能指导人们进一步改进其性能,还能加深人们对其创造力本质的理解。这反过来又将为人们日常使用和应用这些模型提供依据,所以人们有必要开发一套有效方法,来衡量和评估其创造力。具体而言,创造性能力在以下应用场景中尤为关键:其一,大语言模型能在创造性任务上启发人类并提供新颖想法,尤其是在生成研究思路方面。不过也有观点指出,使用大语言模型也可能导致创造力的同质化。其二,利用大语言模型生成幽默,在创意和实际应用中均具有重要价值。通过模拟类人幽默,大语言模型可协助娱乐、营销和社交媒体领域的内容创作。其三,在创意写作中,大语言模型可成为强大的协作者,通过生成叙事构思、指导情节发展,甚至起草文本片段,以激发人类作家进一步完善作品。
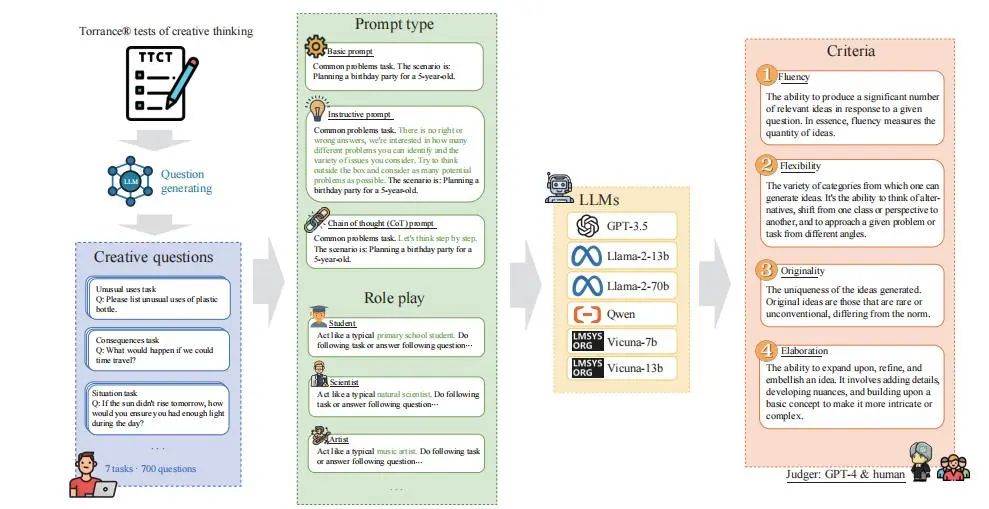
图1 创造力评估模型框架
创造力这一术语,传统上指人自然具备的创新性思考、建立非常规关联以及构想出兼具新颖性与有效性解决方案的能力。评估大语言模型的创造力面临着诸多挑战。首先,创造力本身并无明确答案可循。当人们向大语言模型提出如“真空中的光速是多少米每秒?”这类问题时,鉴于问题的客观性,其答案可以进行正式验证。然而,当人们要求模型回答如“如果动物能说话,将会产生哪些影响?”这样的问题时,情况则截然不同。因为此类问题并无标准答案,其答案具有开放性与发散性,所以很难评判其输出结果正确与否。其次,由于创造力涵盖原创性、灵活性等多个维度,因此需要设计多样化的任务和标准,才能有效衡量大语言模型在这些方面的表现。再者,大语言模型与人类存在差异,这可能导致模型生成不相关的回答或严重的逻辑问题,所以人们需要额外评估这些方面。最后,创造力评估需要在准确性与效率之间取得微妙平衡,所以传统依赖人工的评估方法实用性较低。综上所述,人们必须解决上述挑战,才能对大语言模型的创造力做出稳健可靠的评估。
本研究意识到全面评估大语言模型创造力的必要性,于是设计了一个高效框架,通过改良广受认可的心理测量学领域用于人类创造力评估的工具——Torrance创造思维测验(TTCT),来自动评估大语言模型的创造力。为增强结果的可信度并减少随机性,本研究选取了七项使用语言刺激的语言型任务。本研究利用目前最先进的大语言模型GPT-4,对每项任务的题目集进行了扩充,从而构建了测试数据集。为确保对创造力进行全面、客观的评估,并捕捉其多样化的表现形式,本研究结合了多样化的任务与评估标准。本研究设计了一套综合测试方案,纳入了衡量创造力的四项标准:流畅性、灵活性、原创性和精进性。本研究让大语言模型回答所构建数据集中的问题,从而获得大量问题-答案组。本研究采用GPT-4作为评估者来评估每个答案,因为GPT-4能够有效评估回答的开放性,并识别其存在的缺陷与错误。在恰当的提示词工程指导下,GPT-4能够高效且有效地完成对整个数据集结果的评估工作。因此,本研究的评估方法能够在效率与准确性之间实现平衡。
本研究选取了六款主流大语言模型作为测试对象,这些模型具备不同的架构和参数量级。除整体测试外,本研究还额外进行了一些探索性实验,旨在研究当输入不同类型的提示词以及设定不同角色时,大语言模型所展现的创造力水平的变化。随后,本研究为大语言模型设计了协作机制,以探究多个大语言模型协作对创造力的影响。最后,本研究还对大语言模型进行了一些与人格特质相关的心理学实验,包括情商、共情能力、大五人格量表和自我效能感。因为本研究在相关心理学研究中发现,人类的创造力与这些人格特质存在关联,因此本研究验证了大语言模型与人类在此方面的一致性。
本研究的实验与分析得出了若干结论。首先,不同模型之间的创造力表现存在显著差异,即使是参数量相同的同规模模型之间也是如此。这种差异主要存在于不同类型的模型之间,其差别主要体现在模型架构、训练过程中的参数设置、对齐策略以及训练数据集上。其次,本研究发现这些模型普遍在精进性指标上表现出色,但在展现原创性方面往往有所欠缺。再者,提供给模型的提示词类型以及具体的角色扮演要求,对其创造性输出也有重要影响。当模型接收到指导性提示词或思维链提示词时,其创造力水平会显著提升。此外,让大语言模型扮演不同角色也会带来明显差异,其中,扮演科学家角色时展现出的创造力水平最高。许多角色与默认场景相比,甚至会出现创造力下降的情况,但原创性通常有所提升。另外,多个大语言模型之间的协作能够提升创造力水平,其中原创性的提升最为明显。最后,心理量表测试的结果表明,在影响创造力的相关因素方面,如情商、共情能力、自我效能感等,大语言模型与人类之间存在一致性。

全文下载:
Assessing and Understanding Creativity in Large Language Models
Yunpu Zhao, Rui Zhang, Wenyi Li & Ling Li
https://link.springer.com/article/10.1007/s11633-025-1546-4
BibTex:
@Article {MIR-2024-08-361,
author={Yunpu Zhao, Rui Zhang, Wenyi Li, Ling Li },
journal={Machine Intelligence Research},
title={Assessing and Understanding Creativity in Large Language Models},
year={2025},
volume={22},
issue={3},
pages={417-436},
doi={10.1007/s11633-025-1546-4}}
特别感谢本文第一作者、中国科学技术大学赵耘浦博士对以上内容的审阅和修改!
纸刊免费寄送
Machine Intelligence Research
MIR为所有读者提供免费寄送纸刊服务,如您对本篇文章感兴趣,请点击下方链接填写收件地址,编辑部将尽快为您免费寄送纸版全文!
说明:如遇特殊原因无法寄达的,将推迟邮寄时间,咨询电话010-82544737
收件信息登记:
https://www.wjx.cn/vm/eIyIAAI.aspx#
∨
关于Machine Intelligence Research
Machine Intelligence Research(简称MIR,原刊名International Journal of Automation and Computing)由中国科学院自动化研究所主办,于2022年正式出版。MIR立足国内、面向全球,着眼于服务国家战略需求,刊发机器智能领域最新原创研究性论文、综述、评论等,全面报道国际机器智能领域的基础理论和前沿创新研究成果,促进国际学术交流与学科发展,服务国家人工智能科技进步。期刊入选"中国科技期刊卓越行动计划",已被ESCI、EI、Scopus、中国科技核心期刊、CSCD等20余家国际数据库收录,入选图像图形领域期刊分级目录-T2级知名期刊。2022年首个CiteScore分值在计算机科学、工程、数学三大领域的八个子方向排名均跻身Q1区,最佳排名挺进Top 4%,2023年CiteScore分值继续跻身Q1区。2024年获得首个影响因子(IF) 6.4,位列人工智能及自动化&控制系统两个领域JCR Q1区;2025年发布的最新影响因子达8.7,继续跻身JCR Q1区,最佳排名进入全球第6名;2025年一举进入中国科学院期刊分区表计算机科学二区。
▼往期目录▼
2025年第2期 | 常识知识获取、图因子分解机、横向联邦学习、分层强化学习...
2025年第1期 | 机器视觉、机器人、神经网络、反事实学习、小样本信息网络...
2024年第6期 | 图神经网络,卷积神经网络,生物识别技术...
2024年第5期 | 大语言模型,无人系统,统一分类与拒识...
2024年第3期 | 分布式深度强化学习,知识图谱,推荐系统,3D视觉,联邦学习...
2024年第2期 | 大语言模型、零信任架构、常识知识推理、肿瘤自动检测和定位...
2023年第6期 | 影像组学、机器学习、图像盲去噪、深度估计...
2023年第5期 | 生成式人工智能系统、智能网联汽车、毫秒级人脸检测器、个性化联邦学习框架... (机器智能研究MIR)
2023年第4期 | 大规模多模态预训练模型、机器翻译、联邦学习......
2023年第3期 | 人机对抗智能、边缘智能、掩码图像重建、强化学习...
2023年第2期 · 特约专题 | 大规模预训练: 数据、模型和微调
2023年第1期 | 类脑智能机器人、联邦学习、视觉-语言预训练、伪装目标检测...
▼好文推荐▼
清华大学朱军团队 | DPM-Solver++:用于扩散概率模型引导采样的快速求解器
南航张道强团队 | 综述:基于脑电信号与机器学习的注意力检测研究
哈工大江俊君团队 | SCNet:利用全1X1卷积实现轻量图像超分辨率
下载量TOP好文 | 人工智能领域高下载文章集锦(2023-2024年)
上海交大张拳石团队 | 综述: 基于博弈交互理论的神经网络可解释性研究
专题好文 | Luc Van Gool团队: 基于分层注意力的视觉Transformer
澳大利亚国立大学Nick Barnes团队 | 对息肉分割的再思考: 从分布外视角展开
前沿观点 | Segment Anything并非一直完美: SAM模型在不同真实场景中的应用调查
自动化所黄凯奇团队 | 分布式深度强化学习:综述与多玩家多智能体学习工具箱
约翰霍普金斯大学Alan Yuille团队 | 从时序和高维数据中定位肿瘤的弱标注方法
精选综述 | 零信任架构的自动化和编排: 潜在解决方案与挑战
欧洲科学院院士蒋田仔团队 | 脑成像数据的多模态融合: 方法与应用
专题好文 | 创新视听内容的联合创作: 计算机艺术面临的新挑战
哈工大江俊君团队 | DepthFormer: 利用长程关联和局部信息进行精确的单目深度估计
Luc Van Gool团队 | 通过Swin-Conv-UNet和数据合成实现实用图像盲去噪
贺威团队&王耀南院士团队 | 基于动态运动基元的机器人技能学习
乔红院士团队 | 类脑智能机器人:理论分析与系统应用 (机器智能研究MIR)
南科大于仕琪团队 | YuNet:一个速度为毫秒级的人脸检测器
上海交大严骏驰团队 | 综述: 求解布尔可满足性问题(SAT)的机器学习方法
前沿观点 | 谷歌BARD的视觉理解能力如何?对开放挑战的实证研究
港中文黄锦辉团队 | 综述: 任务型对话对话策略学习的强化学习方法
南航张道强教授团队 | 综述:用于脑影像基因组学的机器学习方法
ETHZ团队 | 一种基于深度梯度学习的高效伪装目标检测方法 (机器智能研究MIR)
▼MIR资讯▼
喜报 | MIR 首次入选中国科学院期刊分区表计算机科学类二区
致谢审稿人 | Machine Intelligence Research
专题征稿 | Special Issue on Subtle Visual Computing

https://wap.sciencenet.cn/blog-749317-1492864.html
上一篇:清华大学朱军团队 | DPM-Solver++:用于扩散概率模型引导采样的快速求解器
下一篇:精选综述 | 宾夕法尼亚州立大学等: 图反事实学习研究综述