博文
2025.03.24-2024.03.30日周报
|
大模型"幻觉"问题和RAG大模型"幻觉"问题
“幻觉”现象是指大型语言模型在生成内容或回答问题过程中,所输出的结果存在准确性偏差,即生成的内容并非完全契合事实或逻辑,甚至可能出现与真实情况相悖的情况,也就是通常所说的“虚假生成”。
产生"幻觉"的主要原因是:
1. 训练知识存在偏差:在对大模型进行训练时,输入的知识中可能包含错误、过时的知识,甚至知识中存在偏见。这些知识被大模型学习后,就有可能在未来的输出中重现这些知识。
2. 过度泛化的推理:大型语言模型通过海量语料库进行训练,试图归纳和学习人类语言的普遍性规律与模式结构。然而,这种基于大规模语料的学习方式可能导致过度泛化现象。具体而言,模型将从一般语料中归纳出的通用模式或规律,错误地应用到特定的、具有独特特征的场景中。由于这些特定场景可能包含特殊的语义、语用规则或上下文约束,而模型未能充分识别和适应这些差异,从而导致生成的输出结果与实际需求不符,出现语义偏离或者环境不匹配问题。
3. 理解存在局限性:大模型并没有真正“理解”训练知识的深层含义,也不具备人类普遍的常识与经验,因此可能会在一些需要深入理解与复杂推理的任务中出错。
4. 缺乏特定领域的知识:通用大模型虽然掌握了大量人类通用知识且具备超强的记忆与推理能力,但可能不是某个垂直领域的专家(例如:医疗或者法律等领域)。当面临一些复杂度较高的领域性问题或私有知识相关的问题时,它就可能会编造信息并将其输出。
5. 其它情况:知识落后、输出难以解释、输出不确定等问题。
不同的"幻觉现象对应的实例举例"
实例1:历史时间的错误陈述
背景:假设某个大型语言模型的训练语料中包含了一些错误的历史知识。例如,有一部分语料错误地将“二战期间德国入侵波兰的的时间”描述为“1940年9月1日”,而实际上正确的日期是1939年9月1日。此外,这些语料中还可能夹杂着一些带有偏见的表述,比如对某些国家或民族的片面评价。
模型训练过程:在训练过程中,模型通过大量的文本数据学习语言模式和知识。由于错误的语料被模型当作“正常”知识进行了学习,它会将这些错误信息融入到自身的知识体系中。
输出"幻觉"现象:当用户询问“二战期间德国入侵波兰的具体时间”时,模型可能会回答“1940年9月1日”,这是一个明显的事实性错误。此外,如果用户询问关于二战期间某国的角色或行为,模型可能会输出带有偏见的描述,例如对某国进行不恰当的贬低或夸大,这种输出不仅不准确,还可能引发误导。
分析:这种“幻觉”现象的根源在于训练知识的偏差。模型无法区分语料中的错误信息和真实信息,因此,在生成内容时会无差别地使用所学到的知识,从而导致输出结果与事实不符或带有偏见。
实例2:医学诊断建议
背景:在生成内容时会无差别地使用所学到的知识,从而导致输出结果与事实不符或带有偏见。例如,它可能从语料中总结出“咳嗽和发热通常是感冒的症状”,这是一个普遍的规律。
模型训练过程:模型通过这些语料数据,归纳出一个通用的模式:当出现咳嗽和发热时,倾向于推荐“可能是感冒,建议多喝水、休息,必要时服用感冒药”。
输出"幻觉"现象:当用户输入一个具体的医疗问题:“我最近咳嗽、发热,而且感觉呼吸困难,还伴有胸痛”,模型可能会基于其学习到的通用模式,回答“这可能是感冒,建议多喝水、休息,必要时服用感冒药”。然而,这种回答在特定场景下是不准确的,因为咳嗽、发热、呼吸困难和胸痛也可能是肺炎或其他更严重的呼吸系统疾病的症状,需要及时就医进行专业检查。
分析:这种“幻觉”现象是由于模型的“过度泛化”导致的。它没有充分考虑特定场景下的其他关键信息(如呼吸困难和胸痛),而是简单地将通用模式应用到具体问题中,从而产生了不准确的输出。在医学领域,这种过度泛化的错误可能会导致严重的后果,因为不同的症状组合可能对应不同的疾病,需要更细致的分析和专业判断。
实例3:法律咨询中的复杂情境分析
背景:假设用户向一个大型语言模型咨询一个复杂的法律问题,涉及多个法律条款的交叉应用以及特定情境下的法律解释。例如,用户咨询:“我在公司工作期间,因为执行工作任务受伤,但公司拒绝支付工伤赔偿,我该如何维护自己的权益?”
模型输出“幻觉”现象:模型可能会给出一个非常通用的回答,例如:"你可以向劳动仲裁委员会申请仲裁,或者向法院提起诉讼。" 这个回答虽然在一定程度上是正确的,但缺乏对具体情境的深入理解。例如,模型没有考虑到以下复杂情况:
(1) 工伤认定的具体流程:用户可能需要先向当地的人力资源和社会保障部门申请工伤认定,而这个过程可能涉及复杂的证据收集和程序要求。
(2) 公司可能的抗辩理由:公司可能会以“受伤并非完全因工作原因”或“员工违反公司规定”等理由拒绝赔偿,而模型没有考虑到这些抗辩理由的应对方法。
(3) 法律条款的交叉应用:工伤赔偿可能涉及《工伤保险条例》《劳动法》《劳动合同法》等多个法律法规的交叉应用,模型没有深入分析这些法律条款之间的关系。
分析:这种“幻觉”现象是由于模型“理解存在局限性”导致的。模型虽然能够识别出“工伤赔偿”这一关键词,并给出一个通用的建议,但它并没有真正理解问题的深层含义,也没有考虑到具体情境下的复杂法律关系和可能的抗辩理由。模型缺乏人类律师所具备的法律常识、实践经验以及对复杂情境的推理能力,因此无法提供一个全面、准确且有针对性的法律建议。
实例4:介绍某企业的新产品
背景:假设某企业刚刚发布了一款全新的高科技产品,例如一款基于量子计算技术的加密设备。这款产品涉及复杂的量子计算原理、先进的加密算法以及特定的行业应用标准。这些信息是该企业的私有知识,且属于高度专业化的领域。
输出"幻觉"现象:用户向通用大模型询问:“请介绍一下某企业最新发布的量子加密设备的技术原理和应用场景。” 由于通用大模型没有接触到该企业的私有知识,也没有深入学习过量子计算技术在加密领域的具体应用,它可能会编造信息并输出类似以下内容:
(1) 技术原理:“这款量子加密设备采用了先进的量子纠缠技术,通过量子比特的叠加态实现超高速的数据加密。它能够生成几乎不可破解的密钥,确保数据传输的绝对安全。”(虽然听起来合理,但可能与实际技术细节不符)
(2) 应用场景:“该设备广泛应用于金融、军事和政府机构,能够有效防止数据泄露和网络攻击。”(可能过于笼统,缺乏具体的应用案例和技术细节)
分析:这种“幻觉”现象是由于模型“缺乏特定领域的知识”导致的。通用大模型虽然具备广泛的知识和推理能力,但在面对高度专业化的领域性问题(如量子加密技术)时,它无法提供准确的技术细节和具体的应用场景。模型可能会基于其已有的通用知识进行推测或编造,从而生成看似合理但并不准确的信息。这种现象在涉及企业私有知识或前沿技术领域时尤为常见,因为这些信息通常不在通用大模型的训练语料范围内。
RAG技术
基本思想:将传统的生成式大模型与实时信息检索技术相结合,为大模型补充来自外部的相关数据与上下文,以帮助大模型生成更丰富、更准确、更可靠的内容。这允许大模型在生成内容时可以依赖实时与个性化的数据与知识,而不只是依赖训练知识。
RAG基础概念
RAG是一种结合了检索和生成技术的自然语言处理模型。该模型由Facebook AI提出,旨在提升生成式模型在处理开放域问答、对话生成等任务中的性能。
RAG模型通过引入外部知识库,利用检索模块从大量文档中提取相关信息,并将这些信息传递给生成模块,从而生成更加准确和有用的回答或文本。
其核心思想是通过检索和生成的有机结合,弥补生成模型(如GPT-3、BERT等)在处理知识密集型任务时的不足。在传统的LLM应用中,模型仅依赖训练时学到的知识来回答问题,这导致了知识更新困难、回答可能过时或不准确等问题。而RAG系统通过在生成回答前主动检索相关信息,将实时、准确的知识作为上下文提供给模型,从而显著提升了回答的质量和可靠性。
RAG在本质上可以认为是一种借助"外挂"的提示工程,但绝不仅限于此。它并非简单地将外部知识拼接到提示词中,而是通过一系列优化手段,使大模型能够更精准地理解和高效地利用这些外部知识,从而显著提升输出答案的质量。
RAG架构
RAG模型的技术架构可以分为两个主要模块:检索模块(Retriever)和生成模块(Generator)。
具体示例如下:
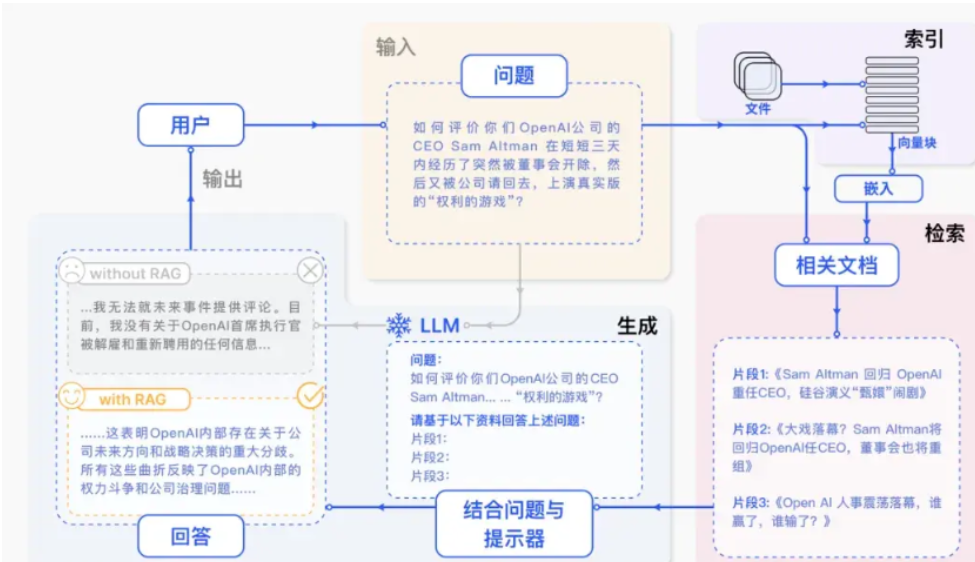
检索模块:负责从大规模的知识库或文档集合中,使用预训练的双塔模型进行高效的向量化检索,快速找到与查询最相关的若干个文档或段落。
生成模块:根据检索到的文档和输入查询生成最终的回答或文本。并使用强大的生成模型(如T5、BART等)对输入进行处理,确保生成的内容连贯、准确且信息丰富。
RAG工作流程:
1. 知识准备:
收集知识文档:从企业内部文档、公开数据集、专业数据库等来源收集相关知识文档。
预处理:对文档进行清洗、去重、分段等操作,确保数据质量。
索引化:将处理后的文档分割为适合检索的单元(如段落或句子),并建立索引以便快速查找。
2. 嵌入与索引:
使用嵌入模型:利用预训练的嵌入模型(如BERT、Sentence-BERT等)将文本转换为高维向量表示。
存储向量:将生成的向量存储在向量数据库(如FAISS、Elasticsearch、Pinecone等)中,构建高效的索引结构。
3. 查询检索:
用户查询向量化:将用户的自然语言查询通过嵌入模型转换为向量表示。
相似度计算:在向量数据库中计算查询向量与存储向量之间的相似度(通常使用余弦相似度或欧氏距离)。
检索结果排序:根据相似度得分,选择若干个最相关的文档或段落作为检索结果。
4. 提示增强:
组装提示词:将检索到的相关文档内容与原始用户查询组合成一个新的输入序列。
优化提示模板:根据任务需求设计提示模板,确保生成模块能够充分利用检索到的信息。
5. 生成回答:
输入增强提示:将增强提示模板输入生成模块(如T5、BART、GPT等)。
生成文本:生成模块根据提示模板生成最终的回答,综合考虑检索到的知识和自身的训练知识。
后处理:对生成的回答进行格式调整、语法检查等后处理,确保输出的质量和一致性。
https://wap.sciencenet.cn/blog-3623004-1479953.html
下一篇:2025.06.02-2025.06.08日周报