
面向文本引导增强型Transformer融合的多模态情感分析
廖翔宇,柯显信,刘清华,李国良
(上海大学 机电工程与自动化学院,上海200444)
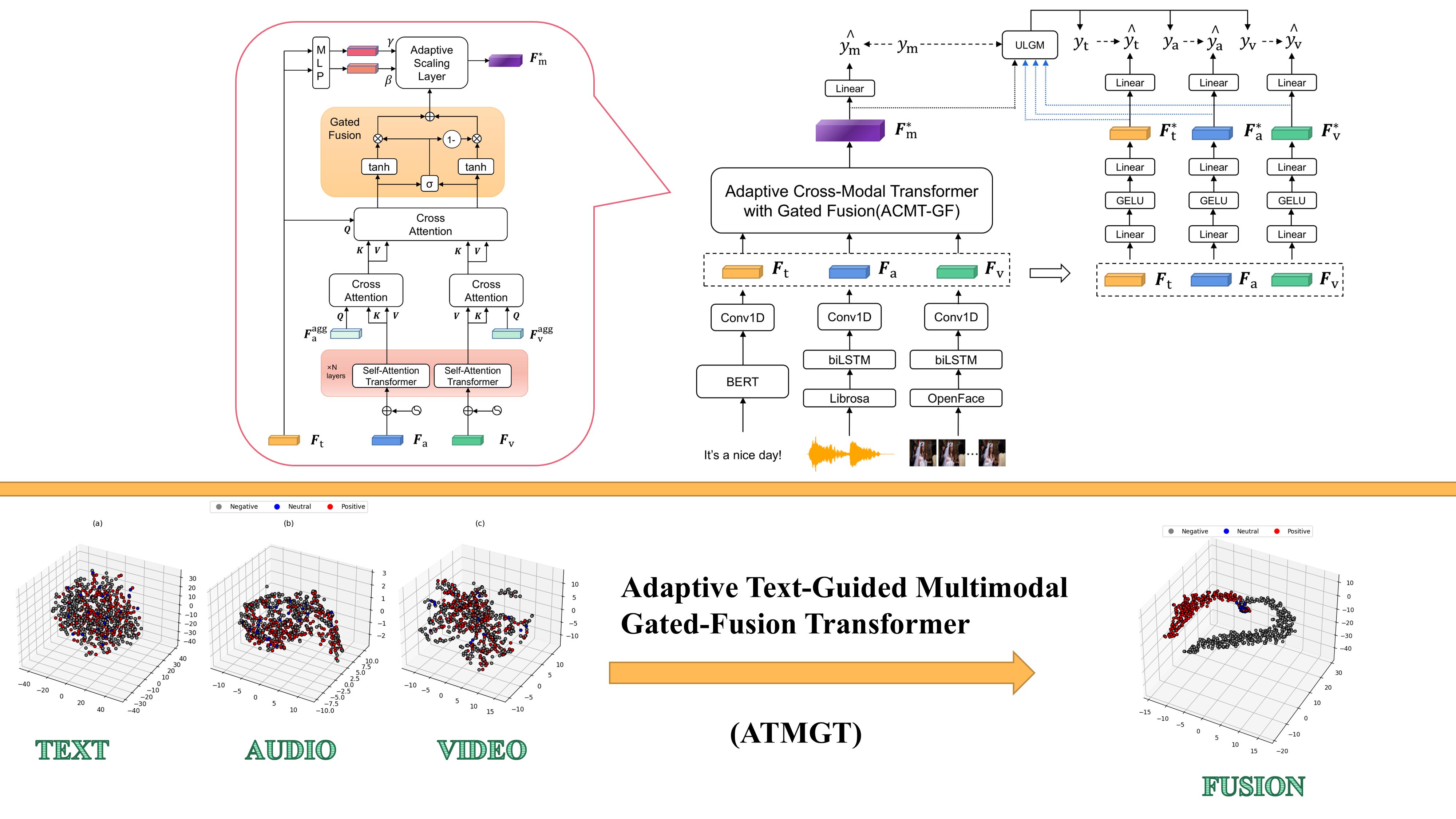
摘要:多模态情感分析通过融合文本、视频和音频数据,有助于更准确地推断情绪状态,但多模态数据的异质性也带来了挑战。为了解决上述问题,本文提出了一种新颖的模型,即自适应文本引导的多模态门控融合Transformer(ATMGT)。该模型利用基于Transformer的自注意力和交叉注意力机制,实现文本、音频和视觉模态之间的深度交互与融合。随后,采用门控融合机制有效整合音频与视觉特征,缓解信息冗余问题。此外,模型将文本视为局部特征,引导对由音视频数据形成的全局特征进行缩放,从而突出情感关键区域。提出的自监督标签生成模块进一步地增强了特定模态的学习能力,并提升了情感分类的鲁棒性。实验结果表明:所提出模型在CMU-MOSI、CMU-MOSEI和CH-SIMS等多个数据集上,在多个评价指标下均取得了优异性能,优于现有主流方法。最后,通过消融实验验证了各核心模块对整体性能的贡献。
关键词:情感分析,多模态融合,Transformer,注意力机制,自监督学习
扫二维码浏览全文

Cite this article
Liao, X., Ke, X., Liu, Q. et al. Text-Guided Enhanced Transformer Fusion for Multimodal Sentiment Analysis. J. Shanghai Jiaotong Univ. (Sci.) (2025). https://doi.org/10.1007/s12204-025-2848-y
转载本文请联系原作者获取授权,同时请注明本文来自黄龙旺科学网博客。
链接地址:https://wap.sciencenet.cn/blog-45888-1506193.html?mobile=1
收藏