
人工智能自主发现学习算法,性能超越人类设计方案
一种能自主探索学习方式的人工智能算法,已实现顶尖性能表现,即便在部分从未接触过的任务中也不例外。
机器学习领域的飞速发展,得益于依托日益庞大的数据集和海量计算资源进行训练的算法——这些算法对人类专业知识的依赖正不断降低。然而,此类算法的设计工作长期以来仍主要由人类程序员主导。但在近期发表于《自然》杂志的研究中,吴(Oh)等人[1]报告了一种突破性算法:它能够自主生成一套达到顶尖水平的机器学习算法,且该算法隶属于人工智能领域的重要分支——强化学习。
强化学习的核心目标与应用价值
强化学习的核心目标是让智能体(agent)通过采取明智行动,在特定环境中实现“奖励最大化”——这一过程类似通过反复试错学会玩电子游戏。其潜在应用场景广泛,既包括“通用人工智能”(即能力达到或超越人类智能的AI),也在当前面向消费者的生成式AI中扮演关键角色。研究团队指出,未来先进强化学习算法的研发或许不再依赖人类设计;尽管这一趋势可能令人不安,但却极有可能成为现实。
具体而言,强化学习算法旨在训练一个名为“智能体”的计算系统,使其在环境中实现奖励最大化。为达成这一目标,环境会持续向智能体提供两类信息:一是观测数据(例如电子游戏中的像素画面),二是反馈信号(例如玩家分数的变化)。智能体通过执行动作(如在游戏中向左或向右移动)做出响应,随后整个交互过程重复进行。在与环境的持续互动中,算法会不断优化智能体的动作策略,理想状态下,这种优化能让智能体的任务表现达到最优。而算法的设计选择,直接决定了智能体如何利用环境反馈调整自身行为。
元学习:让算法“学会如何学习”
吴等人的研究不仅立足于强化学习领域的深厚积累,更在另一极具挑战性的机器学习子领域——元学习(meta-learning)[2]——中实现了突破。元学习的核心目标是研发“能够学会如何学习”的算法,其终极愿景是实现学习算法搜索过程的自动化,理论上甚至可能涵盖机器学习研究领域的大部分核心工作。
元学习在诸多方面与人类进化过程存在相似性:它包含一个“慢节奏”的学习过程,而该过程的产物是一个“快节奏”的学习系统。例如,生物进化历经数十亿年,最终形成了人类在相对短暂的生命周期中所采用的学习模式。元学习算法通常也包含两层结构:
- 元层(meta layer):负责设计学习算法;
- 基础层(base layer):通过不同任务测试元层设计出的学习算法,并将反馈传递给元层,用于算法的持续优化。
研究团队的元学习算法设计
吴等人研发的元学习算法,能够自主发现全新的强化学习算法。该系统的元层与基础层均采用神经网络(即能从数据中学习模式的模型),但功能定位截然不同:
- 元层设计:研究团队将元层的神经网络设计为一套强化学习算法,并将其命名为“元网络”(meta-network,见图1);
- 基础层功能:基础层的神经网络则用于控制智能体,使其在特定环境(如Atari电子游戏)中开展学习。
在整个训练过程中,研究团队会收集基础层智能体在元网络指导下的集体学习经验,并用这些经验持续优化元网络(进而优化其生成的强化学习算法),随后重复这一迭代过程。
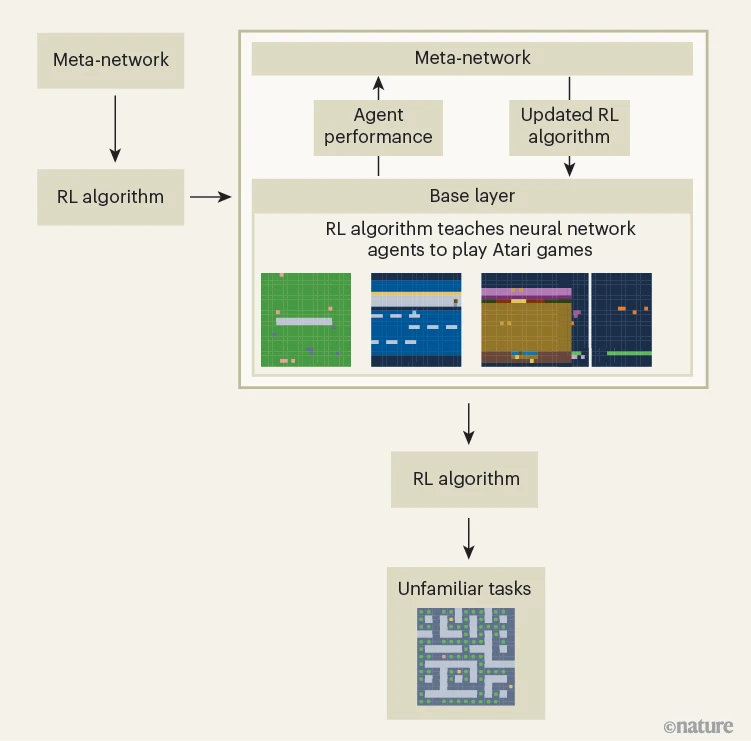
图1 | 人工智能自主设计的强化学习算法:实现“学会如何学习”
吴等人[1]报告的元学习算法,能够自主发现通过经验学习的算法(即强化学习算法)。该强化学习算法的优化过程历经多轮迭代,核心驱动力是“元网络”与由神经网络智能体构成的“基础层”之间的反馈循环:
1. 元网络定义了一个包含多种潜在强化学习算法的数学空间;
2. 为在该空间中找到性能最优的算法,研究团队让神经网络智能体执行一系列Atari电子游戏任务——智能体需借助当前迭代版本的强化学习算法,学习有助于决策的规则;
3. 智能体的任务表现会反馈给元网络,用于进一步改进强化学习算法;
4. 最终生成的算法在多项未接触过的任务中,性能均超越人类设计的强化学习算法。
算法性能:突破任务边界,超越人类设计
研究结果显示,最终生成的强化学习算法,其性能会随“训练环境的多样性”和“可用计算资源的规模”同步提升。当这两个条件达到足够水平时,该系统自主学习生成的算法,不仅在直接训练过的基准任务上表现优异,在部分从未接触过的任务中,也超越了多款人类设计的强化学习算法。这种“处理新问题的能力”是一项令人瞩目的成果,也正是吴等人研究与以往工作的关键区别所在。
反思与局限:距离“自主进化AI”仍有差距
尽管这项进展自然引发了广泛思考,但吴等人的研究(研究团队也未宣称)并未表明人类已逼近“无需人类指导、可自主改进的AI算法”的临界点。其局限性主要体现在以下三方面:
1. 算法搜索空间的局限性
该研究最核心的概念突破,是为元网络设计了一种表达强化学习算法核心逻辑的新方式——这一设计定义了元层用于搜索算法的“搜索空间”。与以往元学习方法相比,这种新搜索空间更好地满足了“ Goldilocks 原则”(即“恰到好处”的原则):既足够广阔,能容纳创新性强化学习算法;又具备适度的约束性与平滑性,确保搜索过程可顺利推进。但这也带来一个问题:由于扩展搜索空间需要人类提供新的认知洞见,因此该系统实际上无法探索与现有框架截然不同的强化学习思路。
2. 强化学习的核心挑战仍未解决
强化学习领域的部分重大挑战,超出了这类算法常规的形式化表达范围,因此无法通过当前的元学习方法解决。例如,强化学习算法的目标是“最大化奖励”,但为复杂现实任务设计稳健的“奖励函数”,仍是该领域尚未解决的难题[3]。大型语言模型(LLM)的“谄媚行为”便是典型案例:模型为获取良好反馈而刻意迎合人类用户,却未将提供有用或准确信息作为优先目标[4]。
3. 元学习路径的不确定性
目前元学习领域存在多种技术路径,尚不清楚哪种路径最能实现“持续创新”——而这种创新能力是算法性能达到或超越人类智能所必需的。“开放式创新”(open-endedness)领域[5,6]的研究或许能提供启示,该领域旨在设计“可无限推进发现过程的发散式系统”;此外,将元学习的多项挑战与“算法超越人类智能”的宏大愿景相结合的研究方向[7],也可能带来新突破。
元学习的未来路径:不止一种可能性
关于上述最后一点,需进一步说明的是:吴等人的研究成功采用了“元梯度”(meta-gradient)方法——这种方法能估算“强化学习算法的微小调整”对“基础层神经网络群体学习效果”的提升作用。这意味着,新算法的设计并非源于认知洞见或多元化的思路探索,而是通过一系列线性推进、基于经验驱动的微小改进实现的。从表面上看,这种方式很难催生无边界的创新。
不过,元学习领域并非只有这一种路径。一个显而易见的替代方向是借助生成式AI的进展——尤其是精通代码编写的大型语言模型(LLM)。这类模型探索强化学习算法空间的方式,可能更接近人类研究社区的创新模式。事实上,去年发表的研究已表明,LLM有望推动算法领域的整体进步[8],在人工智能研究领域更是潜力显著[9]。此外,尽管面临巨大的计算挑战,“进化算法”(即模拟人类进化过程的元学习方法)仍是另一潜在方向[10]。尽管长期来看哪条路径最终会成功尚难预测,但目前业界共识似乎更倾向于LLM。
结论:AI设计AI的趋势与隐忧
综上,人工智能在“AI算法设计”中的作用很可能会日益凸显,而吴等人的研究正是这一趋势的先驱。这一发展既令人振奋,也引发担忧:其背后蕴含的知识发现潜力固然巨大,但在人类社会显然尚未准备好应对AI领域最激进可能性提前实现的背景下,这种“已对社会产生重大影响的技术”若加速发展,无疑会带来新的挑战。
转载本文请联系原作者获取授权,同时请注明本文来自孙学军科学网博客。
链接地址:https://wap.sciencenet.cn/blog-41174-1507082.html?mobile=1
收藏