博文
DeepSeek-R1论文《自然》
|
自然评论:《深度求索(DeepSeek)人工智能模型的核心技术》
中国公司深度求索(DeepSeek)的研究人员表示,其强大的人工智能(AI)模型R1的成功,并非依赖于使用竞争对手的输出数据进行训练。R1模型于今年1月发布时曾导致美国股市暴跌。该声明出自与R1模型同行评审版本一同发布的文件,相关研究今日(注:指论文发表当日)已发表在《自然》杂志上[1]。

R1模型旨在擅长数学、编程等“推理”类任务,且相比美国科技公司开发的工具,成本更低。作为一款“开源权重”模型,任何人都可下载使用。截至目前,它是AI社区平台Hugging Face上最受欢迎的开源权重模型,下载量已达1090万次。
这篇论文更新了今年1月发布的预印本,预印本中阐述了深度求索如何对标准大型语言模型(LLM)进行改进,以应对推理任务。论文的补充材料首次披露了R1模型的训练成本:仅相当于29.4万美元。需要说明的是,这一成本是在基础模型训练成本之外的——总部位于杭州的深度求索公司为构建R1所基于的基础大型语言模型,已投入约600万美元,但总成本仍远低于竞争对手模型(据悉耗资数千万美元)。深度求索表示,R1的训练主要使用英伟达H800芯片,而该型号芯片在2023年因美国出口管制政策,被禁止向中国出售。
严格的同行评审
R1被认为是首个经历同行评审流程的主流大型语言模型。“这是一个非常受欢迎的先例,”Hugging Face的机器学习工程师刘易斯·汤斯塔尔(Lewis Tunstall)表示,他参与了该《自然》论文的评审工作。“如果我们不建立‘公开分享大部分研发过程’的规范,就很难评估这些系统是否存在风险。”
为回应同行评审意见,深度求索团队减少了描述中的拟人化表述,并补充澄清了技术细节,包括模型的训练数据类型及其安全性。“经过严格的同行评审流程,无疑有助于验证模型的有效性和实用性,”美国俄亥俄州立大学(位于哥伦布市)的AI研究员孙欢(Huan Sun,音译)表示,“其他公司也应该这样做。”
深度求索的主要创新在于,采用一种名为“纯强化学习”的自动化试错方法来开发R1模型。该过程通过“奖励正确答案”来训练模型,而非教它遵循人类筛选的推理示例。公司表示,正是通过这种方式,模型自主习得了解决问题的类推理策略,例如无需遵循人类设定的方法,就能验证自身运算过程。为提升效率,该模型还采用“群体相对策略优化”技术,通过估算对自身的尝试进行评分,而非依赖单独的算法完成评分。
孙欢指出,R1模型在AI研究人员中“影响力颇大”。“2025年至今,几乎所有在大型语言模型中应用强化学习的研究,都或多或少受到了R1的启发。”
训练技术争议
今年1月有媒体报道称,总部位于美国加利福尼亚州旧金山、开发出ChatGPT及“o系列”推理模型的OpenAI公司研究人员认为,深度求索曾使用OpenAI模型的输出数据训练R1——这种方法理论上可在减少资源消耗的同时,快速提升模型能力。
深度求索并未在论文中公开其训练数据。但在与评审专家的沟通中,该公司研究人员表示,R1并非通过复制OpenAI模型生成的推理示例来学习。不过他们也承认,与大多数其他大型语言模型一样,R1的基础模型是基于网络数据训练的,因此必然会吸收互联网上已存在的所有AI生成内容。
孙欢认为,这种反驳“与任何学术出版物中的论证一样具有说服力”。汤斯塔尔补充道,尽管他无法100%确定R1未使用OpenAI的示例数据训练,但其他实验室的复现尝试表明,深度求索的推理模型训练方法本身已足够优秀,无需依赖上述方式。“我认为现有证据已相当明确:仅使用纯强化学习,就能让模型达到极高的性能水平。”
孙欢表示,对研究人员而言,R1的竞争力依然很强。在一项名为“ScienceAgentBench”的科学任务挑战赛(包含数据分析、数据可视化等任务)中,孙欢及其同事发现,尽管R1的准确性并非最高,但在“能力与成本平衡”方面,却是表现最佳的模型之一。
汤斯塔尔指出,目前已有其他研究人员尝试将开发R1的方法应用于现有大型语言模型,以提升其类推理能力,同时还在探索将这些方法拓展到数学、编程之外的领域。他补充道,从这个角度看,R1已然“开启了一场变革”。
梁文锋发表Nature封面论文:揭开DeepSeek-R1背后的科学原理——强化学习激励大模型推理能力
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning | Nature
让 AI 模型像人类一样进行推理是一个长期且艰巨的挑战。大语言模型(LLM)已显示出一些推理能力,但其训练过程需要大量计算资源。通过人工提示引导可改进这类模型,促使其生成中间推理步骤,从而大为强化其在复杂任务中的表现。但这种方法会导致计算成本过高,且解决复杂问题能力仍然不足。
2025 年 1 月 20 日,一家来自中国杭州的初创公司深度求索(DeepSeek)发布了一款推理模型——DeepSeek-R1,该模型推理能力强大,而对算力的需求很低,因此使用成本大幅降低,在全世界科技界迅速引发关注。
2025 年 9 月 17 日,DeepSeek 研究团队在国际顶尖学术期刊 Nature 上发表了题为:DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning 的研究论文,梁文锋为论文通讯作者,该论文还被选为本期封面论文。
该论文揭示了 DeepSeek-R1 所采用的大规模推理模型训练方法,表明了大语言模型(LLM)的推理能力可通过纯强化学习(pure reinforcement learning)来提升,从而减少增强性能所需的人类输入工作量。这种方式训练出的大模型在数学、编程竞赛和 STEM 领域研究生水平问题等任务上,比传统训练的 LLM 表现更好。此外,这种大模型所展现的新兴推理模式能够被系统地用于指导和提升小模型的推理能力。
值得一提的是,论文补充文件中首次披露了 DeepSeek-R1 的训练成本——仅仅 29.4 万美元,即使加上为打造 DeepSeek-R1 所基于的基础模型所花费的 600 万美元,总金额也远低于同类模型动辄数千万美元的花费。
大语言模型(LLM)已经在多种推理任务上展现出了令人印象深刻的能力,但它们的成功通常严重依赖大量人类标注的推理示例。这不仅成本高昂,模型的能力也受限于人类提供的范例,无法探索更优越的、非人类式的推理路径。
而 DeepSeek 的研究团队通过纯强化学习(pure reinforcement learning)方法——模型在被展示优质的问题解决案例后,会获得一个模板来产生推理过程,模型通过解决问题获得奖励,从而强化学习效果、激发出模型的推理能力,过程中无需任何人类标注的推理轨迹。
人类标注:成本与天花板并存
推理能力是人类智能的基石,使我们能够进行数学解题、逻辑推导和编程等复杂认知任务。近年来,AI 领域的研究表明,当大语言模型达到一定规模时,便会涌现出推理等高级能力。
思维链(CoT)提示是一种有效的增强方法,通过提供少量示例或简单提示(例如“让我们一步步思考”),引导模型生成中间推理步骤,从而显著提升其在复杂任务上的表现。模型也可以通过在后训练阶段学习高质量、多步推理轨迹来获得进一步增益。
但这些方法存在明显局限——依赖人类标注的推理轨迹,难以扩展且会引入认知偏差;模型被限制在模仿人类思维过程的框架内,性能天花板受限于人类提供的范例。
纯强化学习:让模型自主探索推理路径
为了应对这些问题,DeepSeek 团队旨在探索通过强化学习框架,让大语言模型以自我演进的方式发展推理能力,最小化对人类标注的依赖。
具体而言,该研究基于 DeepSeek-V3 Base 模型,采用组相对策略优化(GRPO) 作为强化学习框架。奖励信号仅基于最终预测与标准答案的正确性,对推理过程本身没有任何约束。
值得注意的是,该研究绕过了强化学习训练之前传统的监督微调(SFT)阶段。这是因为研究人员认为,人类定义的推理模式可能会限制模型探索,而受限的强化学习训练能更好地激励大模型推理能力的涌现。
通过这一过程,DeepSeek-R1-Zero 模型自然发展出了多样且复杂的推理行为。例如,该模型倾向于生成更长的响应,融入验证、反思和替代方法的探索。
模型训练中的“顿悟时刻”
在研究过程中,研究人员观察到了一个有趣的现象:DeepSeek-R1-Zero 模型在训练过程中经历了一个“顿悟时刻”。在训练过程中的某个时刻,模型在反思中突然开始频繁使用“wait”这个词。这一时刻标志着模型推理过程的显著变化——表明了模型正在发展出类似人类的反思和自我监控能力。

卓越的性能表现
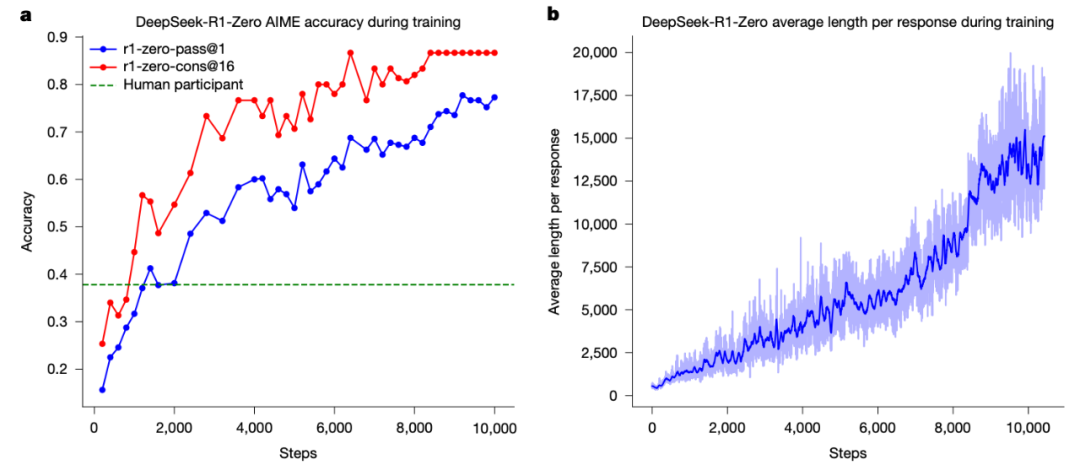
DeepSeek-R1-Zero 在美国数学邀请赛(AIME)2024 基准测试上表现出色,平均 pass@1 分数从最初的 15.6% 大幅跃升至 77.9%。通过使用自一致性解码,模型的性能可以进一步提升,达到 86.7% 的准确率,这一表现大大超过了所有人类参赛者的平均水平。
除了数学竞赛,DeepSeek-R1-Zero 在编程竞赛以及研究生水平的生物、物理和化学问题中也取得了显著表现。
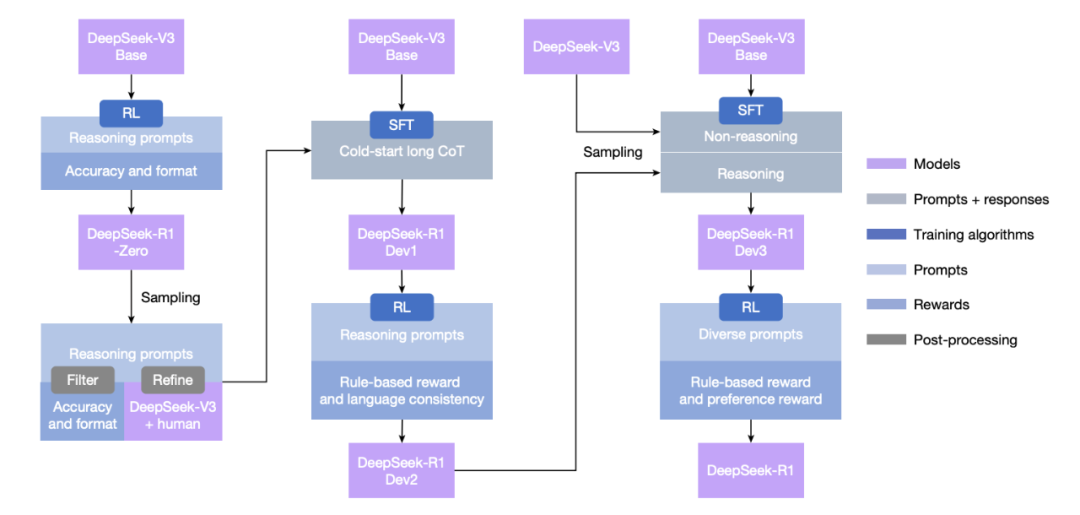
 从 Zero 到 R1:多阶段训练提升综合能力
从 Zero 到 R1:多阶段训练提升综合能力
尽管 DeepSeek-R1-Zero 展现出强大的推理能力,但也面临一些挑战,例如可读性差和语言混合问题(在同一响应中混合使用英文和中文)。
此外,DeepSeek-R1-Zero 基于规则的强化学习训练阶段专注于推理任务,而在写作和开放域问答等更广泛领域表现有限。
为了解决这些挑战,研究人员开发了 DeepSeek-R1,该模型通过多阶段学习框架训练而成,整合了拒绝采样、强化学习和监督微调。
这一训练流程使 DeepSeek-R1 能够继承 DeepSeek-R1-Zero 的推理能力,同时通过进一步的非推理数据使模型行为与人类偏好对齐。
伦理与安全考量
随着 DeepSeek-R1 推理能力的提升,研究团队也深入认识到其潜在的伦理风险。例如,DeepSeek-R1 可能受到越狱攻击,导致生成危险内容,而增强的推理能力使模型能够提供更具操作可行性和可执行性的计划。
此外,开源的模型也容易受到进一步微调,从而损害内在的安全保护措施。研究表明,DeepSeek-R1 模型的固有安全水平与其他最先进模型相比处于中等水平(与 GPT-4o 相当),当与风险控制系统结合时,模型的安全水平可提升至卓越标准。
未来展望与挑战
DeepSeek-R1 在推理基准测试中取得了前沿成果,但仍面临一些能力限制:
1、结构化输出和工具使用:目前的结构化输出能力不及现有模型,且无法使用搜索引擎和计算器等工具来改进输出性能;
2、标记效率:虽然能够根据问题复杂度动态分配计算资源,但在响应简单问题时仍存在“过度思考”现象;
3、语言混合:当前主要针对中文和英文优化,处理其他语言查询时可能出现语言混合问题;
4、提示工程:对提示词敏感,少样本提示会持续降低其性能;
5、软件工程任务:由于评估时间长,大规模强化学习尚未广泛应用于软件工程任务。
纯强化学习方法本身也存在固有挑战,特别是奖励黑客问题——模型可能会找到捷径来“黑客”奖励模型,而不是真正提高解决问题的能力。
结语
DeepSeek-R1 系列模型的研究表明,预训练检查点本身就具有解决复杂推理任务的巨大潜力。解锁这种潜力的关键不在于大规模人类标注,而在于提供困难的推理问题、可靠的验证器以及足够的强化学习计算资源。
高级推理行为,例如自我验证和反思,似乎在强化学习过程中有机地涌现出来。这一研究为未来开发更自主、自适应的大语言模型铺平了道路,有望在多种需要复杂推理的领域实现突破。
随着 DeepSeek-R1 等纯强化学习方法的发展,未来有望解决任何可以被验证器有效评估的任务,无论这些任务对人类来说多么复杂,配备这种先进强化学习技术的机器有望通过这些领域超越人类能
https://wap.sciencenet.cn/blog-41174-1502507.html
上一篇:纳米气泡热酸稳定性研究
下一篇:固态储氢实现电动化