
AI可精准预测20年后人会得哪些病
一款名为“德尔菲-2M”(Delphi-2M)的改良型大型语言模型,通过分析个人的医疗记录和生活方式,能评估出1000多种疾病的患病风险。
Learning the natural history of human disease with generative transformers | Nature
一款基于英国40万人数据训练的人工智能系统,可估算一个人在20年内患上癌症及其他多种疾病的可能性。图片来源:Brooks Kraft/Corbis/Getty
近日,一款新型人工智能工具可预测一个人患上1000多种疾病的风险,部分预测甚至能提前数十年做出[1]。
这款名为“德尔菲-2M”的模型,利用健康记录和生活方式因素,能提前20年估算一个人患上癌症、皮肤病、免疫性疾病等疾病的可能性。尽管该模型仅基于英国的一个数据集训练,但这种“多疾病建模”能力未来或许能帮助临床医生识别高风险人群,从而尽早采取预防措施。相关研究已于今日发表在《自然》(Nature)杂志上。
“该工具能一次性对多种疾病进行建模,这种能力非常惊人,”德国慕尼黑大学(Ludwig Maximilian University of Munich)计算机科学家斯特凡·福伊尔里格尔(Stefan Feuerriegel)表示,他本人也开发过用于医疗领域的人工智能模型。“它能生成一个人未来完整的健康轨迹,”他补充道。
健康“预言家”
研究人员此前已开发出基于人工智能的工具,可预测人患上某些疾病的风险,包括部分癌症和心血管疾病。但该研究的合著者、德国海德堡癌症研究中心(German Cancer Research Center)数据科学家莫里茨·格尔斯通(Moritz Gerstung)指出,这些工具大多只能估算单一疾病的风险。“医护人员若想得到全面的健康评估,可能需要运行数十个这类工具,”他说。
为解决这一问题,格尔斯通及其团队对一种名为“生成式预训练Transformer”(GPT)的大型语言模型(LLM)进行了改良——GPT正是ChatGPT等人工智能聊天机器人的核心技术基础。这类模型在接收问题后,会根据其训练过的海量数据,输出统计学上概率合理的结果。
研究团队设计的这款改良型大型语言模型,可根据一个人的既往病史,预测其患上1258种疾病的可能性。该模型还纳入了个人的年龄、性别、体重指数(BMI),以及与健康相关的习惯(如吸烟、饮酒)等信息。研究人员利用英国生物样本库(UK Biobank,一项长期生物医学监测研究)中40万名参与者的数据,对“德尔菲-2M”进行了训练。
对于大多数疾病,“德尔菲-2M”的预测准确性达到或超过了现有“单一疾病风险评估模型”的水平。同时,其表现也优于一种“基于生物标志物(人体内特定分子或化合物的水平)预测多种疾病风险”的机器学习算法。“它的表现好得出乎意料,”格尔斯通说。
对于有明确进展规律的疾病(如部分类型的癌症),“德尔菲-2M”的预测效果最佳。根据医疗记录中包含的信息,该模型可计算出一个人在未来20年内患上每种疾病的概率。
疾病“预警系统”
格尔斯通及其团队还利用丹麦国家患者登记处(Danish National Patient Registry)的健康数据对“德尔菲-2M”进行了测试——该数据库是一个已追踪近半个世纪住院记录的全国性数据库,包含190万人的信息。研究人员发现,该模型对登记处人群的预测准确性,仅略低于对英国生物样本库参与者的预测。格尔斯通表示,这表明即便将该模型应用于“非训练所用的国家医疗系统数据集”,它仍能做出一定程度上可靠的预测。
美国得克萨斯大学休斯顿健康科学中心(University of Texas Health Science Center at Houston)的生物信息学研究员 Zhi Degui(音译:支德贵)长期致力于人工智能模型开发,他认为“德尔菲-2M”为“快速发展的多疾病同时建模领域”做出了“颇具吸引力”的贡献,但该模型仍存在局限性。例如,英国生物样本库的数据仅记录了参与者“首次患病”的情况,而支德贵指出,一个人“患病的次数”对于“个人健康轨迹建模”而言“至关重要”。
目前,格尔斯通及其团队正计划利用多个国家的数据集评估“德尔菲-2M”的准确性,以扩大其适用范围。“思考如何整合这些信息、开发出更精准的算法,将是未来的关键方向,”他说。
利用生成式Transformer模型研究人类疾病的自然史
医疗健康领域的决策需基于对患者过往及当前健康状态的理解,以预测并最终改变其未来健康走向[1,2,3]。人工智能(AI)方法有望通过从大规模健康记录数据集中学习疾病进展模式,为这一任务提供助力[4,5]。然而,其潜力尚未得到大规模的充分验证。本研究对GPT[6](生成式预训练Transformer)架构进行改良,以模拟人类疾病的进展过程及疾病间的相互竞争关系。我们基于英国生物样本库(UK Biobank)40万名参与者的数据,对该模型(命名为Delphi-2M)进行训练,并利用丹麦190万人的外部数据(未调整模型参数)对其进行验证。结果显示,Delphi-2M可根据个体既往疾病史,预测1000多种疾病的发生率,准确性与现有单一疾病预测模型相当。此外,Delphi-2M的生成式特性使其能够生成模拟的未来健康轨迹,为未来20年潜在疾病负担提供有效估算,同时也可用于训练未接触过真实数据的AI模型。可解释AI方法[7]为解读Delphi-2M的预测结果提供了思路:既揭示了疾病章节内部及跨章节的共病集群,以及这些集群对未来健康的时间依赖性影响,也指出了模型从训练数据中学习到的偏差。综上,基于Transformer的模型似乎非常适用于健康相关的预测性和生成性任务,可应用于人群规模的数据集,并能揭示疾病事件间的时间依赖关系,这有望加深对个体化健康风险的理解,为精准医疗方案提供参考。
Learning the natural history of human disease with generative transformers | Nature
人类疾病随年龄的进展具有以下特征:健康期、急性疾病发作期,以及慢性衰弱期,且常表现为共病集群。共病模式对个体的影响存在差异,并与生活方式、遗传特征及社会经济地位相关[1,2,3]。理解个体的共病风险对于定制医疗决策、推动生活方式改变或指导个体参与筛查项目(如癌症筛查[8,9])至关重要。关键在于,健康状况不能仅通过单一疾病诊断来理解,而需结合个体的共病情况及其随时间的演变过程。目前,针对特定疾病(从心血管疾病到癌症)的预测算法种类繁多[10,11,12],但能预测人类全谱系疾病的算法却寥寥无几——根据《国际疾病分类第十版》(ICD-10)编码系统,仅顶层分类就包含1000多种疾病诊断。
对于人口老龄化及人群潜在疾病谱发生变化的群体而言,学习并预测疾病进展模式同样重要。例如,有预测显示,到2050年,全球癌症确诊病例数将增加77%[13];在英国,到2040年,患有抑郁症、哮喘、糖尿病、心血管疾病、癌症或痴呆等重大疾病的劳动年龄人口,将从300万增至370万[14]。因此,对预期疾病负担进行建模对于医疗健康和经济规划至关重要;此外,持续追踪疾病发生情况及其在人群中的未来流行趋势,有助于构建更具知情决策能力的医疗系统。
人工智能领域的最新进展或许能解决共病建模中一些难以克服的方法学局限[15]。除疾病诊断数量庞大这一问题外,这些局限还包括:模拟既往事件间的时间依赖关系、整合潜在的多样化预后相关数据,以及预测结果的统计校准。大型语言模型(LLM)[16,17,18,19]是人工智能的一个分支领域,支撑了ChatGPT[20,21]等聊天机器人的开发,其核心是将语言建模为词片段(即“令牌”,token)序列。新文本通过逐令牌生成,生成过程基于所有前文内容;经过充分训练后,令牌间的统计依赖关系足以生成符合语境甚至具备对话性的文本,且往往难以与人类撰写的文本区分。
大型语言模型与疾病进展建模存在相似性——二者均需识别既往事件,并利用事件间的相互依赖关系预测未来疾病序列。这种相似性近期催生出一系列新型AI模型。例如,基于BERT的模型[22,23,24,25]已被开发用于特定预测任务;通过电子健康记录训练的Transformer模型,可用于预测胰腺癌[26]、自伤行为[25]、中风[24]等疾病诊断,以及自尊水平[27]等非临床指标。然而,尽管已有一些有前景的概念验证[4,28,29],全面性、生成性共病建模的潜力尚未得到充分评估。
本研究证实,与大型语言模型类似的注意力机制Transformer模型,可进一步拓展用于学习终身健康轨迹,并能基于既往健康诊断、生活方式因素及其他有效数据,同时精准预测1000多种疾病的未来发生率。我们开发的拓展模型(命名为Delphi-2M)基于人群规模研究队列“英国生物样本库”的数据进行训练,并在丹麦人群登记数据库中完成验证。该模型的“词汇表”包含ICD-10顶层诊断编码,以及性别、体重、吸烟状态、饮酒状态和死亡信息。Delphi-2M可提供个体水平的多疾病发病预测,并能在个体生命周期的任意节点模拟未来健康轨迹。此外,Delphi的内部模型有助于揭示既往数据如何影响后续疾病的发生率。我们还评估了不同人群亚组间模型的偏差与公平性,并探讨了Delphi作为医疗健康建模框架的潜力。
用于健康记录的Transformer模型
个体的健康轨迹可通过一系列诊断来表示,这些诊断基于首次确诊年龄记录的ICD-10顶层编码及死亡信息。此外,我们以平均每5年1个的频率随机添加“无事件”填充令牌,以消除无其他输入的长时间间隔(这类间隔在年轻人群中尤为常见,且期间基线疾病风险可能发生显著变化)(扩展数据图1)。这些数据共包含1258种不同状态——对应大型语言模型术语中的“令牌”。其他输入信息包括性别、体重指数(BMI)、吸烟和饮酒状态指标,这些信息仅作为输入,不被模型预测(图1a)。
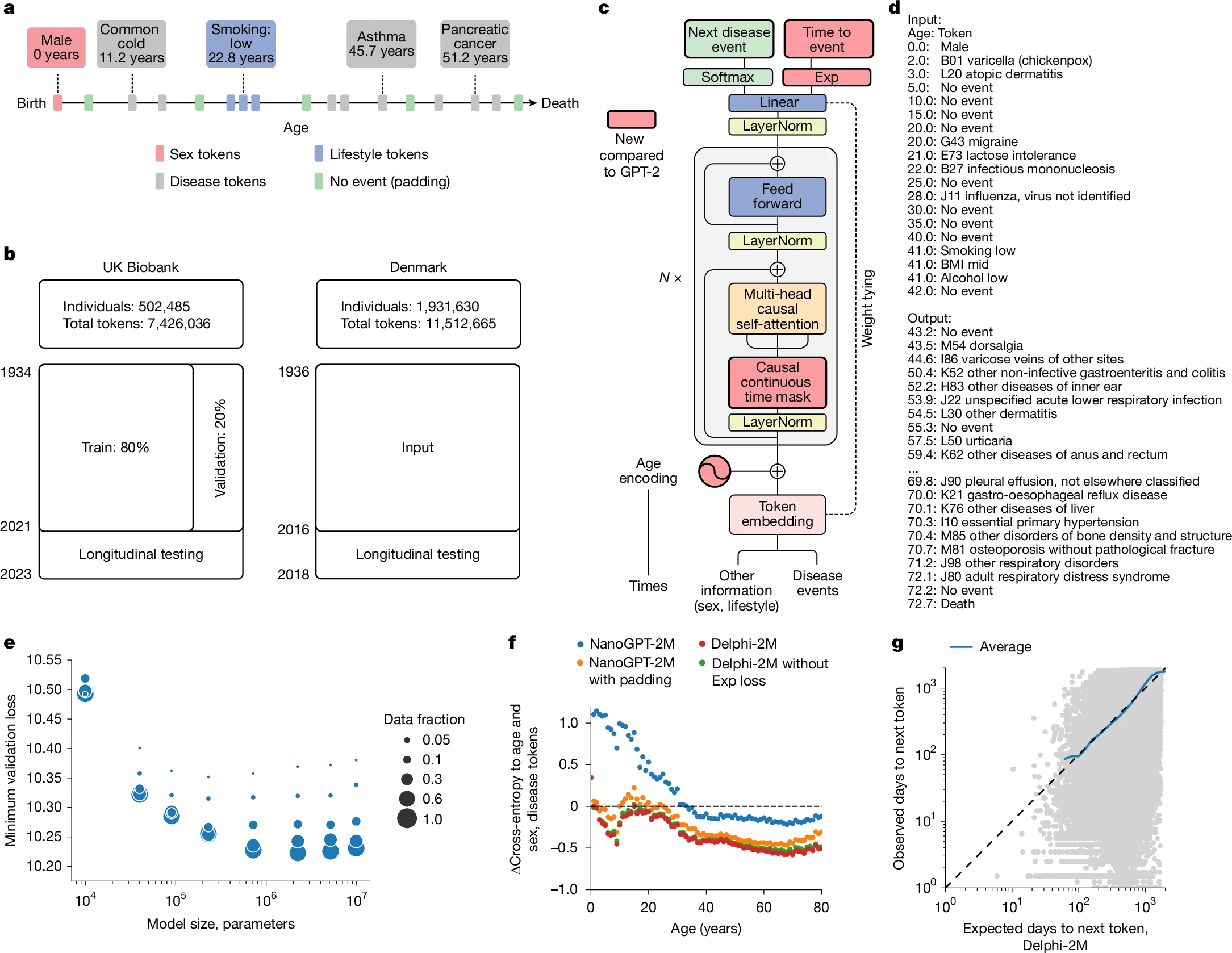
图1:Delphi(改良型GPT架构)对健康轨迹的建模
a. 基于ICD-10诊断、生活方式及健康填充令牌的健康轨迹示意图,每种信息均记录具体年龄。
b. 训练、验证及测试数据来源:左侧为英国生物样本库,右侧为丹麦疾病登记数据库。
c. Delphi模型架构。红色部分表示与基础GPT-2模型相比的修改内容。“N×”表示将Transformer模块按顺序应用N次。
d. 模型输入(提示词)与输出(样本)示例,包含(年龄:令牌)对。
e. Delphi的缩放定律:显示不同训练数据量下,最优验证损失随模型参数变化的函数关系。
f. 消融实验结果:以基于年龄和性别的基线为参照,通过交叉熵差异(纵轴)衡量不同年龄(横轴)的模型表现。
g. 事件发生时间预测的准确性:灰色圆点代表每次下一个令牌预测中,事件发生的实际时间(纵轴)与预期时间(横轴)。蓝色线代表横轴连续区间的平均值。
转载本文请联系原作者获取授权,同时请注明本文来自孙学军科学网博客。
链接地址:https://wap.sciencenet.cn/blog-41174-1502470.html?mobile=1
收藏