
AI生成内容正在污染预印本:审核人员如何反击
预印本服务器上,疑似由论文工厂产出或借助人工智能工具生成的投稿数量正不断攀升。
AI content is tainting preprints: how moderators are fighting back

像PsyArXiv这样的预印本服务器,正忙于处理由人工智能系统撰写的可疑内容。图片来源:《自然》
这篇预印本的标题——《自我实验报告:生成式人工智能界面在梦境状态中的出现》——引起了心理学家奥利维亚·柯特利的怀疑。
当她点开查看时,疑虑更深了。这篇2024年7月发布在PsyArXiv(一个心理学领域非同行评审研究的发布平台)上的手稿仅几页长,且只列出了一位作者,还未标注所属机构。比利时鲁汶天主教大学的柯特利表示,文中描述的人工智能实验“实在太离谱了”。
于是,她将这篇预印本及其他类似的稿件标记给了PsyArXiv的管理人员,这些稿件随后被移除。PsyArXiv科学顾问委员会主席、爱尔兰梅努斯大学的心理学家德莫特·利诺特称,这篇关于梦境状态的手稿在研究方法中使用了人工智能,却未明确说明人工智能的使用方式,也未说明是否在作品的其他部分使用了人工智能,这违反了该平台的使用条款。
在回应《自然》的询问时,所列作者刘佳正(音译)的邮箱回复称,人工智能在这篇预印本的生成过程中仅起到了有限作用。
PsyArXiv只是众多面临可疑投稿困扰的预印本服务器——以及期刊——之一。有些论文带有论文工厂的痕迹,这些机构会按需生成科学论文;另一些则有由人工智能系统撰写的证据,比如虚假参考文献,这可能是人工智能“幻觉”的表现。
这类内容给预印本服务机构带来了难题。许多机构都是非营利组织,致力于让科学家更便捷地发表成果,而筛查低质量内容既耗费资源,又会拖慢投稿处理进度。这种筛查还会引发关于哪些手稿应被允许发布的争议,且大量可疑内容的涌入本身也存在风险。
“如何在保证质量的同时,保持相对宽松的审核方式,避免整个系统陷入瘫痪?”美国心理科学改进协会执行委员会派驻PsyArXiv科学顾问委员会的联络人凯蒂·科克问道,“没人希望看到这样一个世界:读者得自己去判断某篇文章是否属于正当学术成果。”
人工智能生成内容激增
《自然》联系的几家预印本服务机构表示,在其收到的投稿中,看似由大型语言模型(如驱动OpenAI的ChatGPT的模型)生成的比例相对较小。例如,预印本服务器arXiv的运营方估计,约2%的投稿因出自人工智能、论文工厂或两者共同作用而被拒。
位于纽约的openRxiv负责运营生命科学预印本服务器bioRxiv和生物医学服务器medRxiv,其负责人理查德·塞弗表示,这两个平台每天会拒收超过10篇看似模式化、可能由人工智能生成的手稿。这两个平台每月收到约7000份投稿。
但有人表示,情况似乎正变得更糟。arXiv的审核人员注意到,2022年底ChatGPT推出后不久,人工智能撰写的内容就有所增加,而“在过去三个月左右,我们才真正意识到这成了一场危机”,arXiv的科学总监、宾夕法尼亚州立大学的天体物理学家斯泰因·西古德松说。
2024年7月25日,位于华盛顿特区的非营利组织开放科学中心(PsyArXiv的托管方)发布声明称,“注意到明显增多的投稿似乎是由人工智能工具生成或在其大量辅助下完成的”。利诺特证实,PsyArXiv上的这类投稿“略有增加”,平台正采取措施减少此类内容。
柯特利标记的那篇关于梦境状态的手稿,凸显了预印本审核工作的挑战:该预印本被移除后不久,一篇标题和摘要几乎完全相同的预印本又出现在该平台上。与作者相关联的邮箱回复称,“人工智能的作用仅限于数学推导、符号计算、整合和应用现有数学工具、公式验证”等八项任务。发件人自称是“一位来自中国的独立研究者”,没有高等教育学位,“唯一的工具是一部二手智能手机”。这第二篇预印本也已被下架。
聊天机器人助手
上周发表在《自然·人类行为》上的一项研究1估计,2024年9月,在ChatGPT推出近两年后,大型语言模型生成的内容占arXiv上计算机科学摘要内容的22%,占bioRxiv上生物学摘要文本的约10%(见“聊天机器人的崛起”)。相比之下,一项针对2024年期刊发表的生物医学摘要的分析2发现,14%的摘要包含大型语言模型生成的文本。
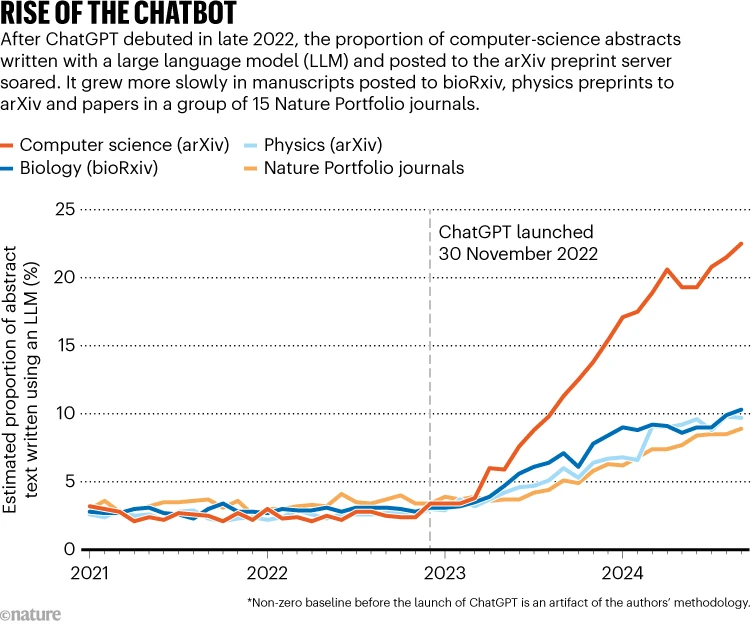
该研究中提到的一些人工智能生成文本,可能出自那些原本难以用英文撰写手稿的科学家之手,加州斯坦福大学的计算机科学家、《自然·人类行为》那篇论文的合著者邹自强(音译)说。
塞弗表示,这些合理用途使得“划清界限”颇具挑战,他还称这些数字并不令人意外,预印本平台必须向作者明确,他们要对自己发布的内容负责。
arXiv计算机科学部门主席、机器学习领域先驱托马斯·迪特里希说,许多向arXiv提交计算机科学预印本的研究者并非以英语为母语,他们很可能会借助大型语言模型来改进写作。他认为22%这一数字“非常合理,但这并不意味着存在欺诈行为”。
加强防控
华盛顿大学研究科学学的沙汉·阿里·梅蒙表示,在信息高速传播的时代,有问题的预印本可能会被迅速分享。“这为虚假信息、炒作打开了大门……此外,(预印本)还会被谷歌搜索收录,”梅蒙补充道,“所以人们在谷歌上搜索信息时,可能会把这些预印本当作信息来源。”
一些预印本服务器,如PsyArXiv,会下架被标记为可疑内容的手稿。另一些则会将内容标记为“已撤回”,除非法律要求,否则不会移除。它们会使用各种自动化工具和人工审核员来识别可疑内容。例如,据拥有Research Square并出版《自然》的施普林格·自然集团介绍,预印本服务器Research Square使用一种名为Geppetto的工具来检测人工智能生成文本的痕迹。
但问题论文的增多意味着,许多服务器正努力加强防控。
例如,arXiv的运营方希望收紧综述类论文(综合特定主题文献的论文)的发布标准,因为西古德松称收到了大量他所谓的“超低质量综述”,“很明显是在线生成或在其辅助下完成的,目的是给作者的发表履历添砖加瓦”。开放科学中心表示,正考虑一系列措施,包括“在投稿流程中增加新步骤,以阻止低质量内容”。
一直依赖人工审核员的openRxiv团队,如今正着手开发自动化工具,以识别人工智能生成内容的特征。但塞弗表示,这样的努力就像“一场军备竞赛”。“我们非常担心,在不久的将来,会出现无法区分完全人造内容和真实内容的情况。这是我们所有人都将面临的挑战。”
转载本文请联系原作者获取授权,同时请注明本文来自孙学军科学网博客。
链接地址:https://wap.sciencenet.cn/blog-41174-1497456.html?mobile=1
收藏