
缘起我有段时间没用 Perplexity 了。你知道,我从 2023 年就推荐过 这个工具,还在另一篇关于 文献综述 AI 应用对比 的文章里详细介绍过它的学术搜索能力。那时候,它曾经是我最喜欢的搜索工具。

回想起来,当时的 ChatGPT 还存在一些明显问题,比如无法联网获取实时信息。而 Perplexity 可以联网查询真实资料,这点极其重要。尽管它可能不如 ChatGPT 那样想象力丰富、灵动,但在汇总专业资料、提供真实数据支撑方面,它确实更胜一筹。
那时候我特别推崇它的学术搜索功能。在对话框中选择「academic」选项后,你可以询问最近关于某个研究主题的文献,它会给出包含多篇相关论文的结果,这些文献大多来源于 NIH、Semantic Scholar、arXiv 等专业学术网站。更重要的是,当你问「想学习某个主题应该如何入门」时,它不会直接推荐课程,而是先询问你在相关领域的基础水平,提供初级、中级、高级选项。这种个性化的学习路径推荐,对初学者来说非常有用。
2025 年初,当众多 AI 应用都纷纷推出 Deep Research 功能时,作为 AI 搜索领域的佼佼者,Perplexity 自然不甘示弱。它迅速推出了自己的 深度研究解决方案,试图在这个新兴市场中分一杯羹。毕竟,相比于 OpenAI Pro 每月 200 美元的高昂订阅费,Perplexity 仅需 20 美元的价格优势实在太具吸引力了。

然而,理想很丰满,现实却很骨感。当我怀着满满期待开始测试这个新功能时,问题开始暴露出来。虽然 Perplexity Deep Research 在查找相关资料方面表现不错,能够从多个来源收集信息,但在将这些资料整合编织成最终报告时,却产生了令人担忧的大量幻觉内容。

注意上图中标红的地方,千万别信,没有的事儿。
最让人困扰的是,这些幻觉并非完全由 Perplexity 胡编乱造,而是在检索到真实信息的基础上「添油加醋」。比如,它会在准确的学术背景介绍中突然插入一些莫须有的数据,或者凭空创造出一些从未存在过的研究成果。这种「半真半假」的表达方式,让用户很难在第一时间识别出问题所在。
但是最近,Perplexity 似乎突然又活跃了起来。特别是昨晚,它突然放出大量的免费年度 Pro 订阅,不少好友连夜发消息告诉我。

也有星友在知识星球里面第一时间把消息告诉了大家。

这一宿下来,不少星友都已经领到了优惠。

但是今早,这个优惠码就已经失效了。

好在我之前已经通过 Lenny's Newsletter 优惠购买了一整年的 Perplexity Pro,但是一直扔在一边。但是因为这次的优惠活动,突然提醒我看了一眼 Perplexity 近期的变化。于是我立即注意到了 Perplexity Labs 这个东西。
定义我让 ChatGPT o3 查询了一下 Perplexity 究竟是啥,它是这样告诉我的:
Perplexity Labs 是 Perplexity AI 在 2025 年推出的一个革命性功能,专门面向 Pro 付费用户开放。如果说传统的搜索引擎是帮你找答案,那么 Perplexity Labs 就像是给你配了一个能干的项目助手,它不仅能回答问题,更能帮你把想法变成实实在在的可交付成果。
想象一下,你只需要用自然语言描述一个需求,比如「根据我上传的销售数据,生成一份包含盈利分析图表的财务报告」,Labs 就会像一个多面手团队一样,自动完成从数据清洗、代码编写、图表制作到报告生成的整个流程。整个过程通常需要 10 分钟以上,但最终你能拿到的不是简单的文字回答,而是可以下载的 Excel 表格、PNG 图片、Markdown 报告,甚至是可以在浏览器中直接运行的交互式小应用。
这种能力的核心在于 Labs 集成了深度网络浏览、代码执行、CSV 处理、图表生成和静态资源托管等多项技术。当你上传一个数据文件或提供一个网址时,Labs 会在安全的沙箱环境中自动编写并运行 Python、R 或 JavaScript 代码,对数据进行处理和可视化。你不需要有任何编程基础,也不需要在本地安装任何开发环境。
于是我明白了过来:这是个 Perplexity 提供的 AI Agent 功能,与 Manus、Flowith 和 Genspark 类似。
这些工具的共同特点是什么?它们都具备了自主性。能够理解目标、制定计划、选择工具、执行任务,并交付最终成果。
但是我现在是不怎么相信广告的,Perplexity Labs 究竟效果如何?还是得咱们亲自动手试试看才行。
实战这是我原本打算输入的原始问题:
调查大语言模型研究中「反向学习」的应用
不过我觉得这个问题过于粗放。于是我细化了这个提示词,使用了下面这种非常完整的要求方式。
请撰写一份关于大语言模型研究中 "反向学习"(Reverse Learning/Unlearning) 应用的技术调研报告,要求如下:
【概念澄清】首先明确界定在 LLM 语境下 "反向学习" 的确切含义,区分于机器学习其他领域的相关概念(如对抗学习、遗忘学习等)。避免概念混淆。
【技术脉络】梳理反向学习在 LLM 发展中的演进路线:
【案例深度分析】选择 3-5 个代表性研究工作进行剖析:
【实践视角】从工程应用角度评估:
【前沿展望】基于当前研究趋势,分析:
【呈现要求】
目标读者:具有 ML 基础知识,希望深入了解 LLM 前沿技术的研究者或工程师
篇幅:2000-2500 字
成功标准:读完后能够理解反向学习的核心价值,并能判断在自己的项目中是否适用
你觉得细化得如何?是不是更加有的放矢呢?
当然了,作为一个懒人,我是不会自己手动去细化的。我利用的,是能够改进提示词的提示词 —— 听起来是不是像套娃?哈哈。
详细要求有了,下面咱们把它交给 Perplexity Labs 开始工作。

这里注意选择 Labs 模式,就是那三个按钮当中的第三个,前两个分别是普通搜索和 Deep Research。
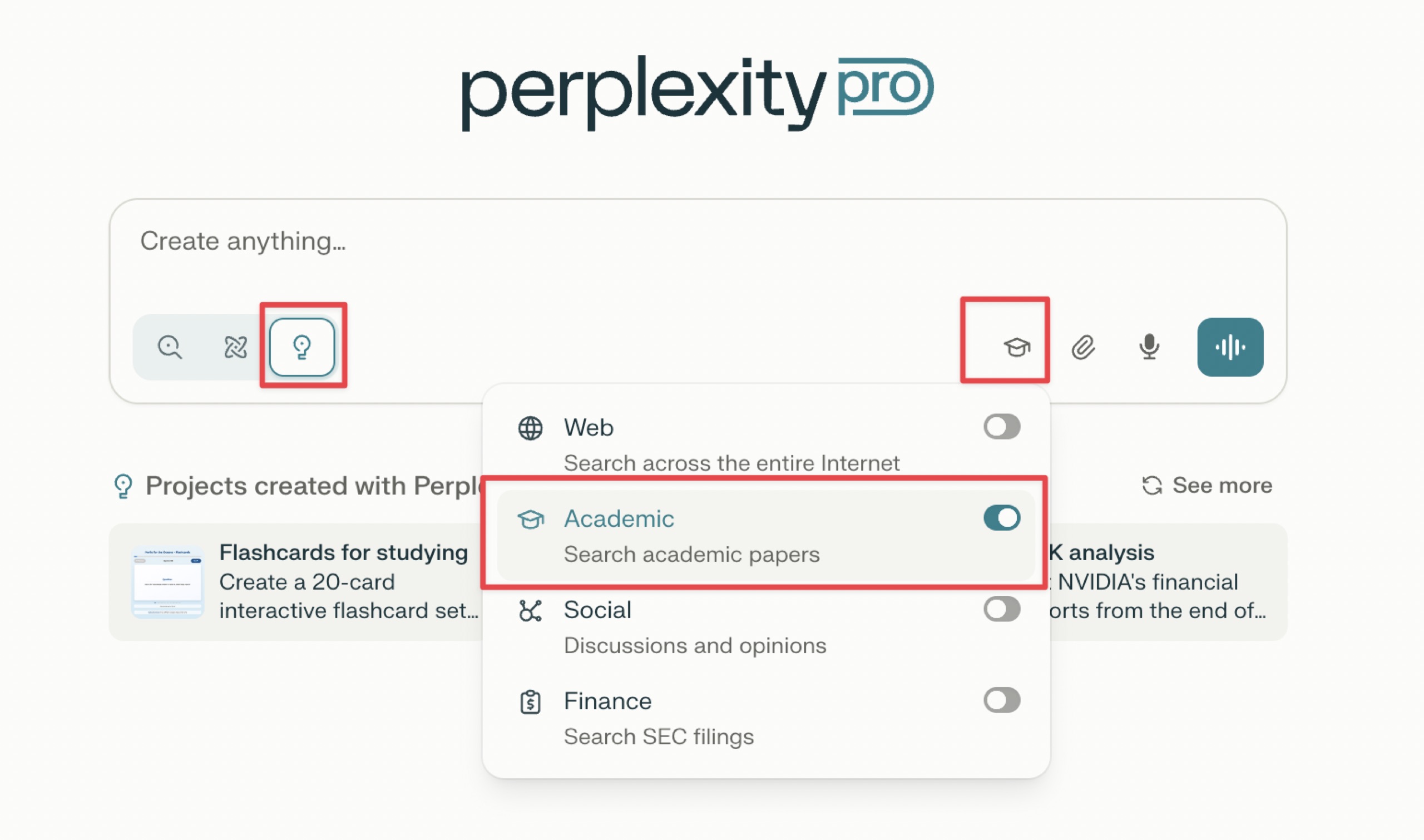
另外注意在搜索来源上选择 Academic,而不是普通的 Web 模式。
Perplexity 首先进行了内容非常丰富的调查,找寻了许多的来源文献。
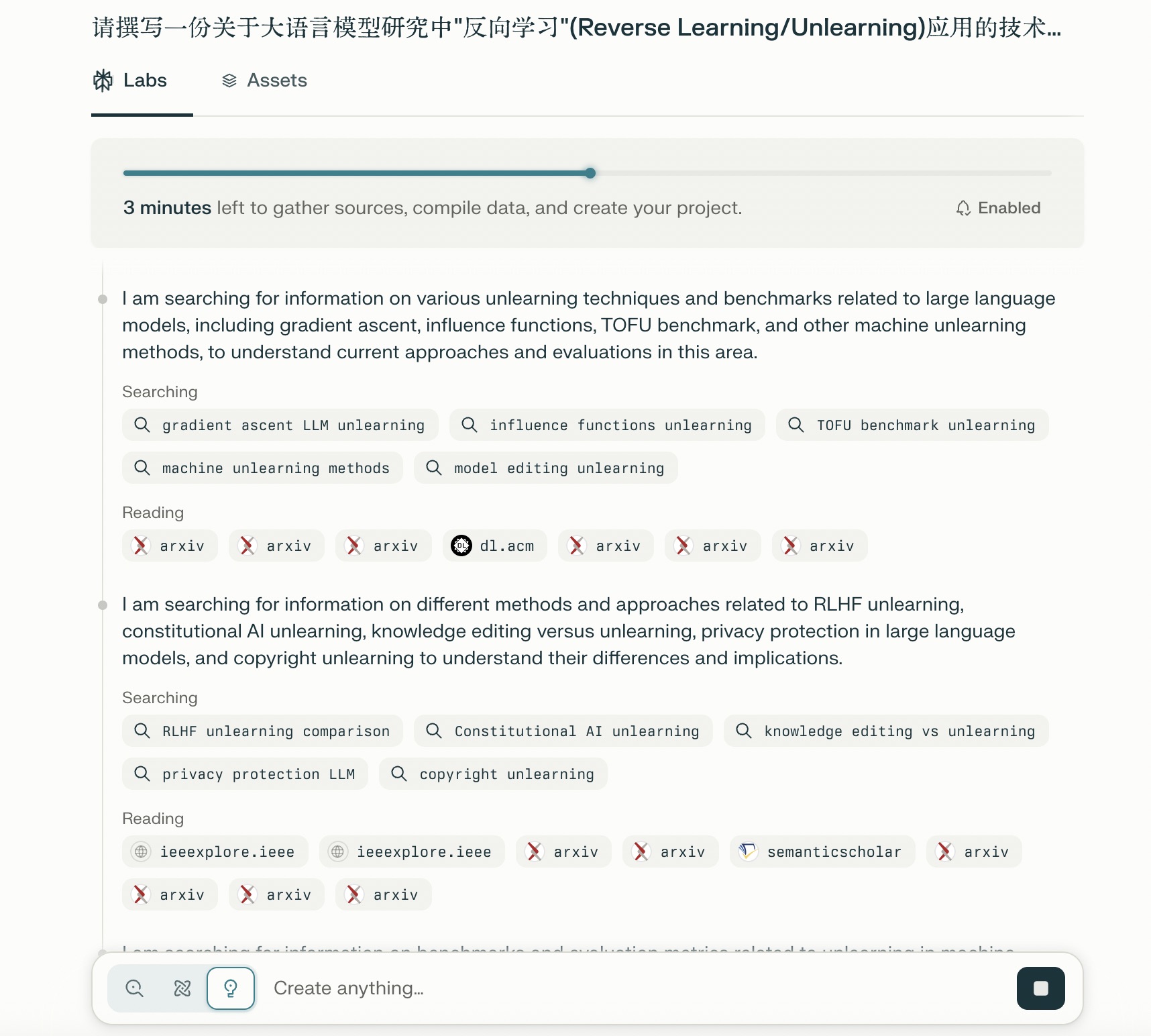
看到这里文献主要来自于 arXiv、ACM、IEEE 和 Semantic Scholar 这些学术来源,我就放心多了。
你要是以为这是另外的一个 deep research,那就错了,因为在 perplexity Labs 中,它是要编写程序的。对于数据它要进行综合,通过编写程序来汇总,甚至编程进行图片的输出等等。
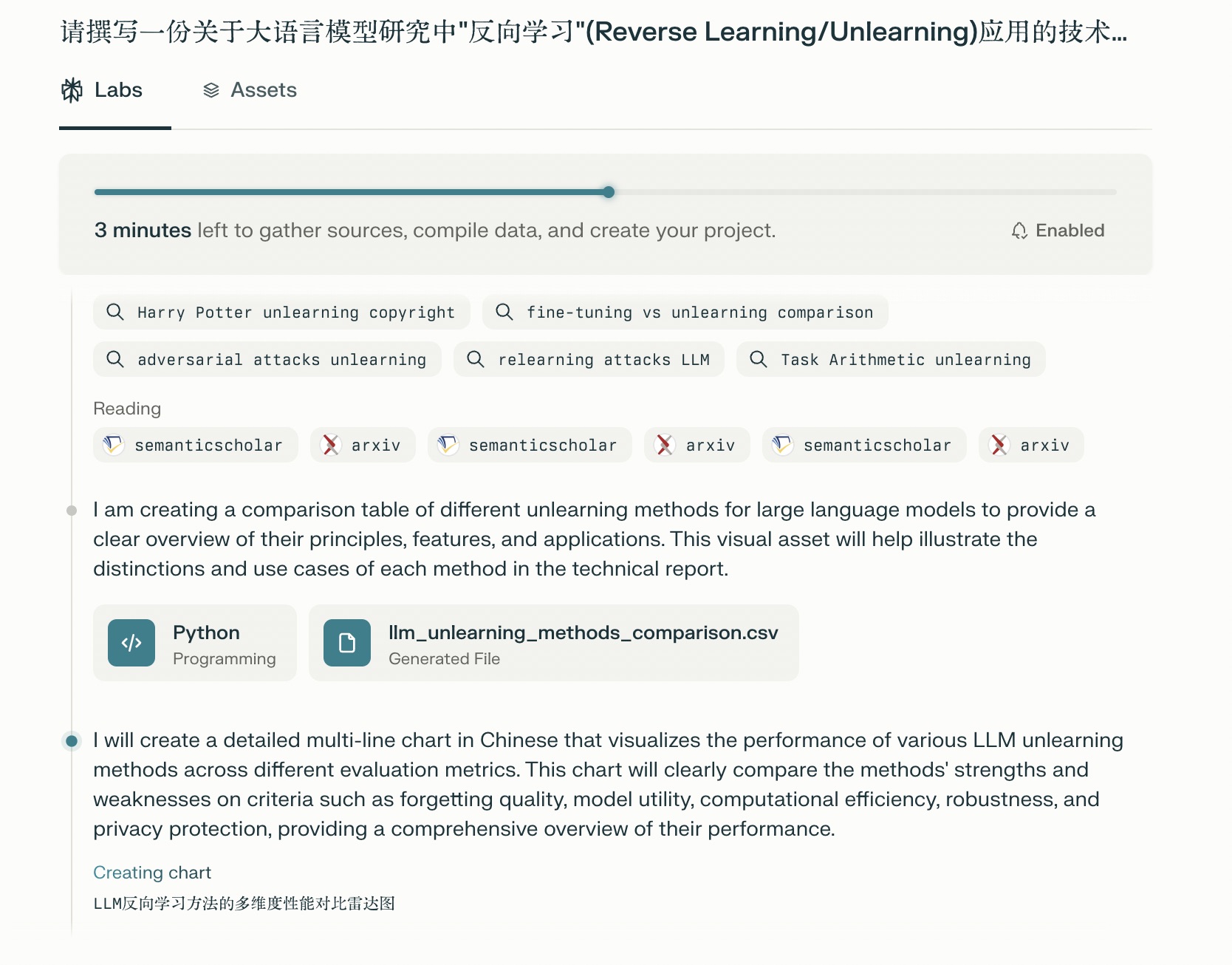
这里通过数据的搜集和整理,Perplexity 已经产生了若干个 csv,并且在生成图片,到这里基本上意味着快要大功告成了。
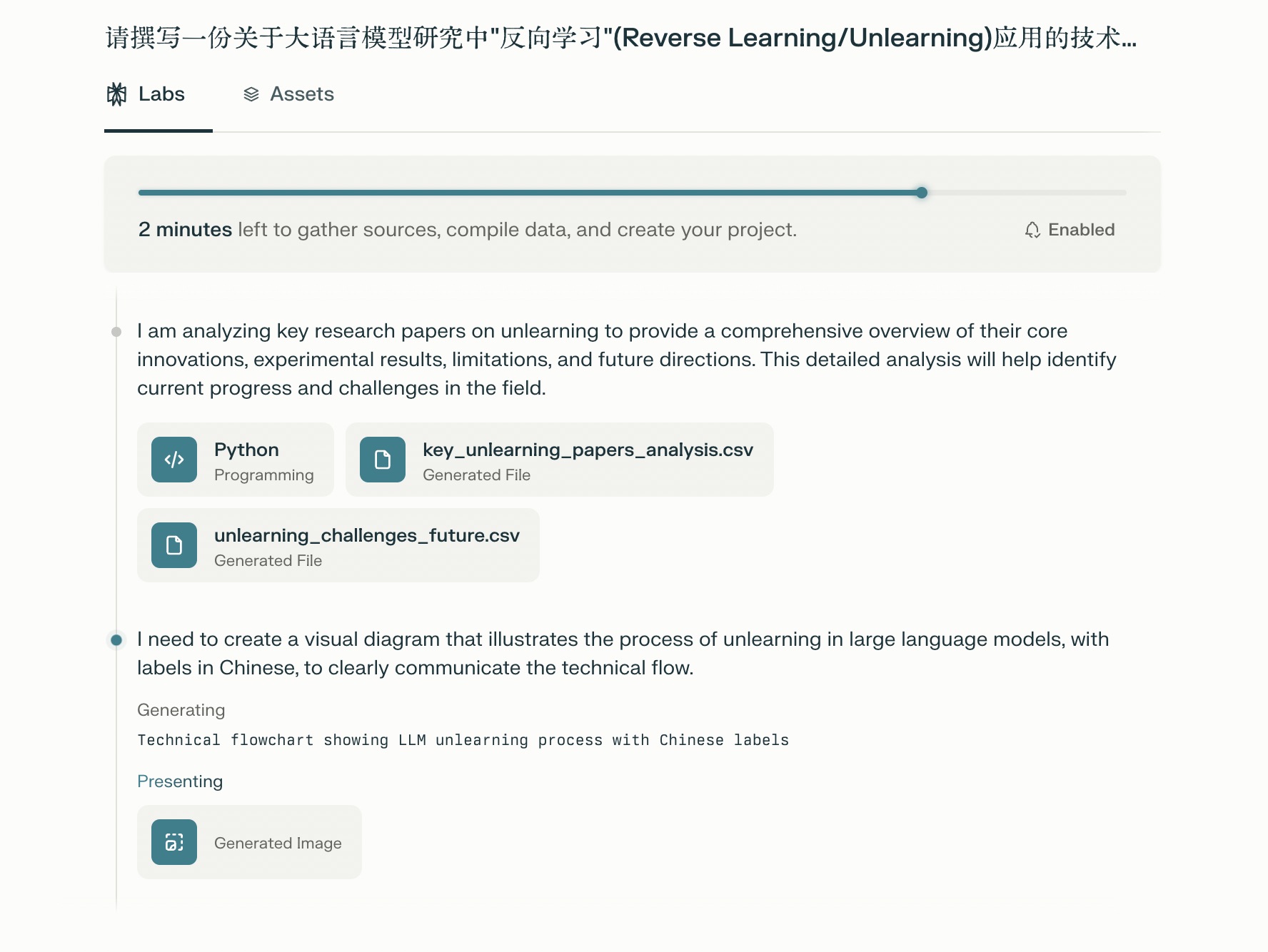
结果,不出意外的出意外了。这里提示的是 sorry, something went wrong,然后让你 try again,我看到之后非常的难过 —— 好几分钟就这样白白耽误了?
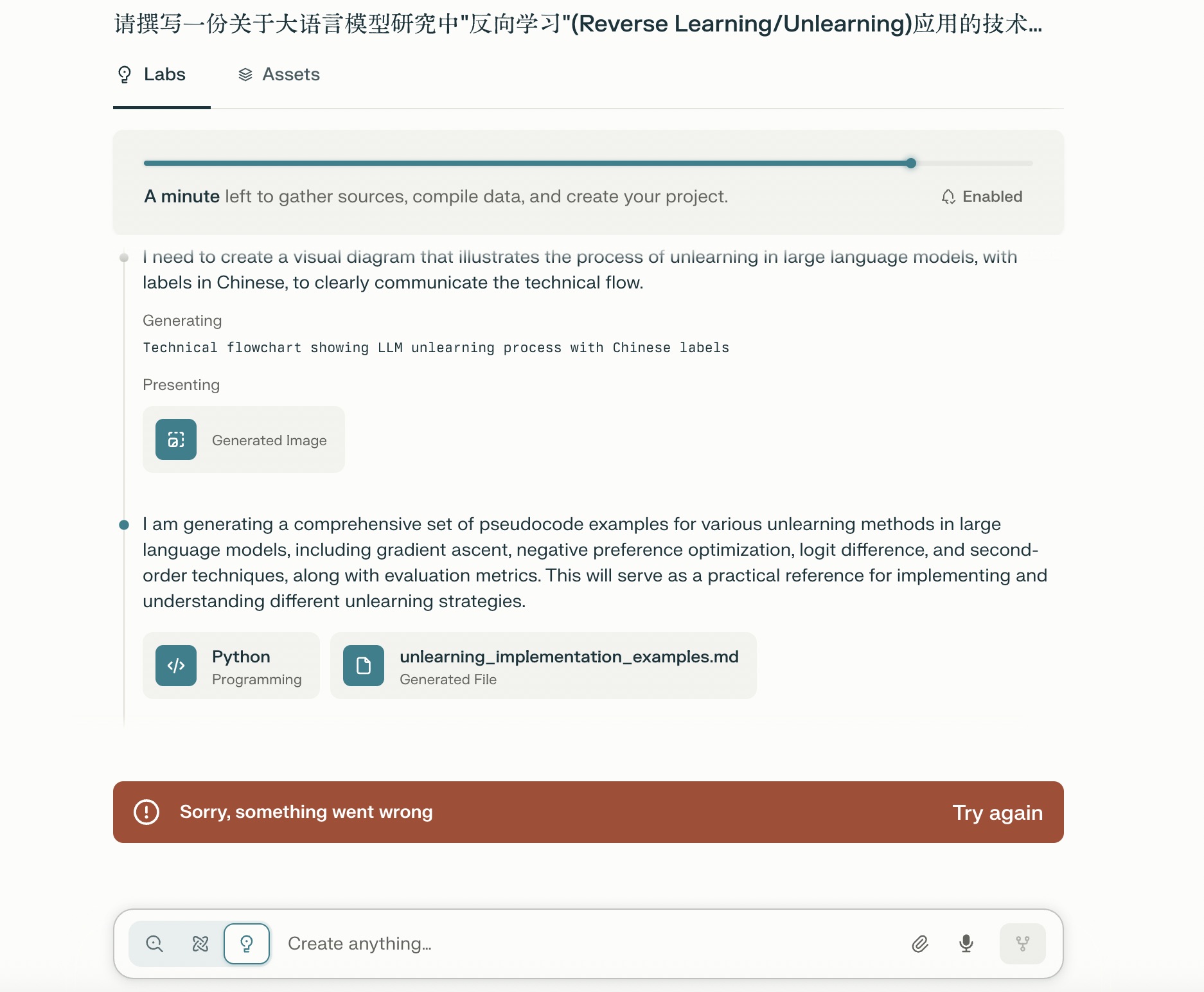
但是你且不用如此的沮丧,因为只需要刷新一下页面,你会发现完整的报告就显现出来了。
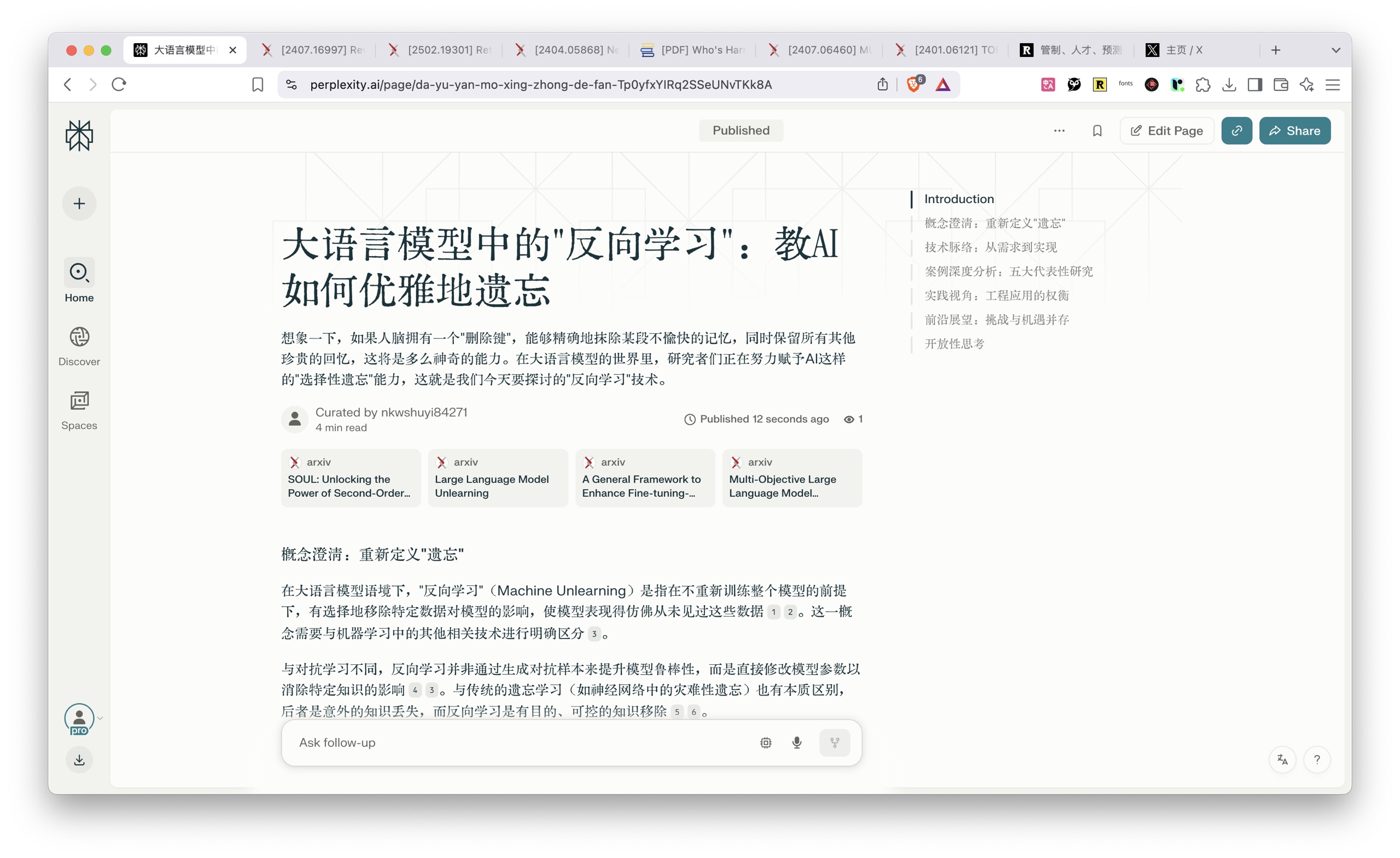
我从头到尾给你翻阅一下。


这可以算是图文并茂引用来源丰富了吧,这还不算,在 perplexity labs 当中,你其实可以选择多种不同的导出选项。
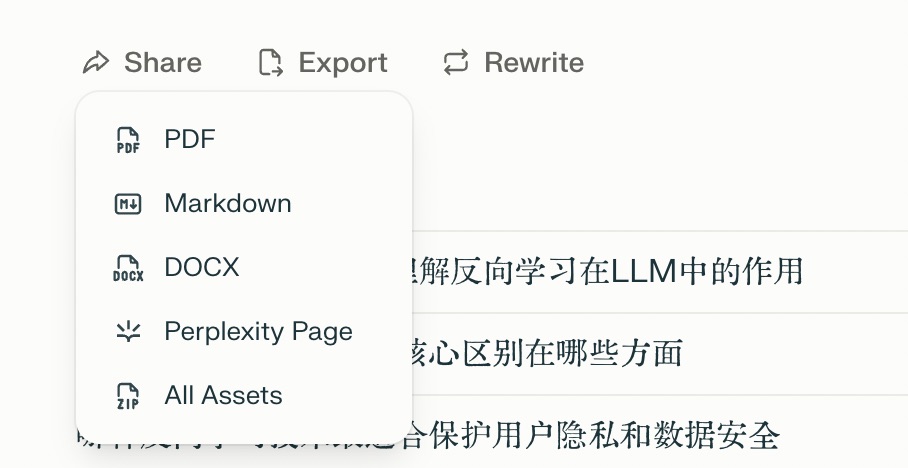
例如这个是 word 版本,你可以在其上进行二次加工,因为所有的内容都是可以编辑的。
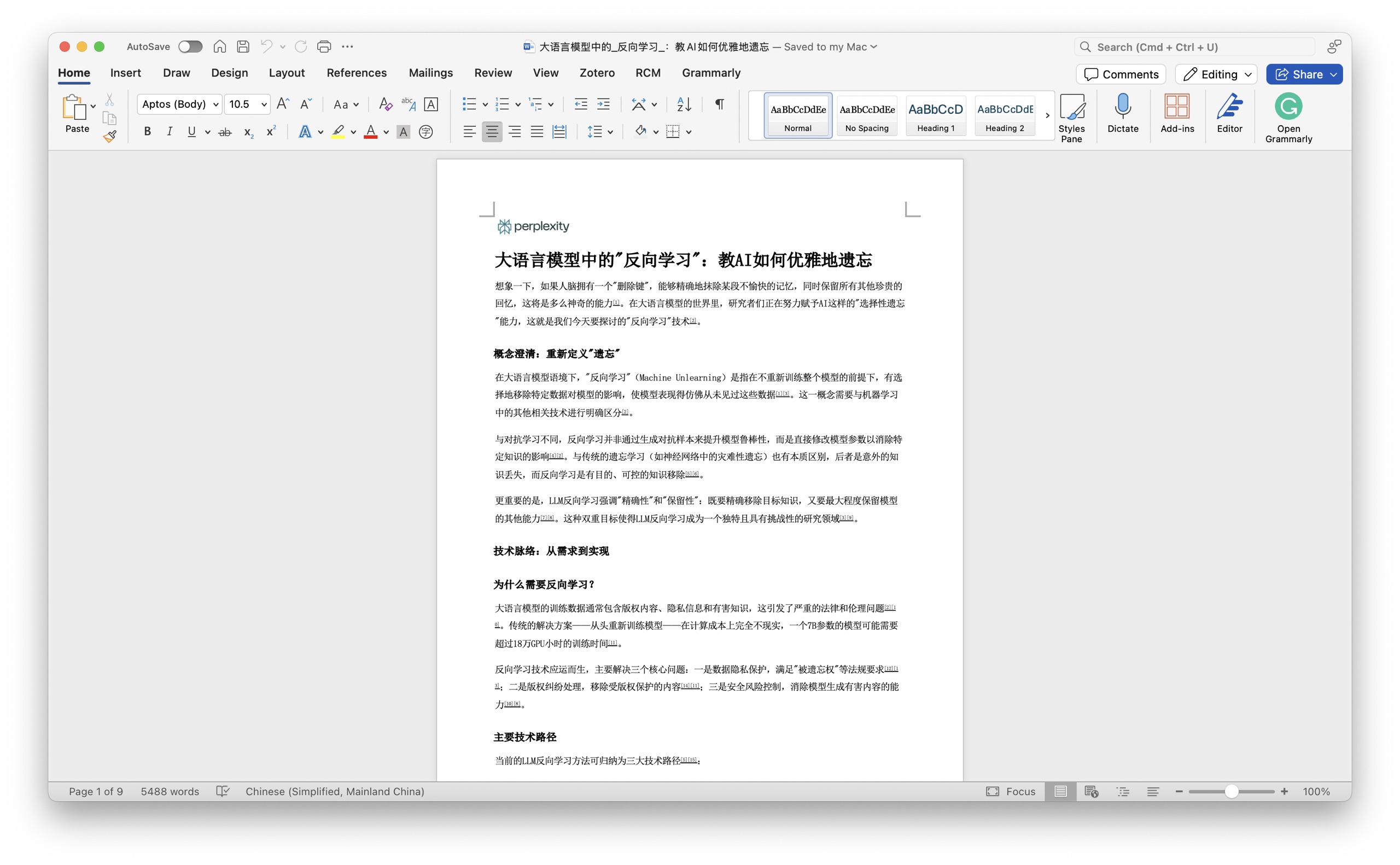
下面这个是 PDF 版本。如果你觉得结果可以直接展现,拿出来分享给别人看也是可以的。
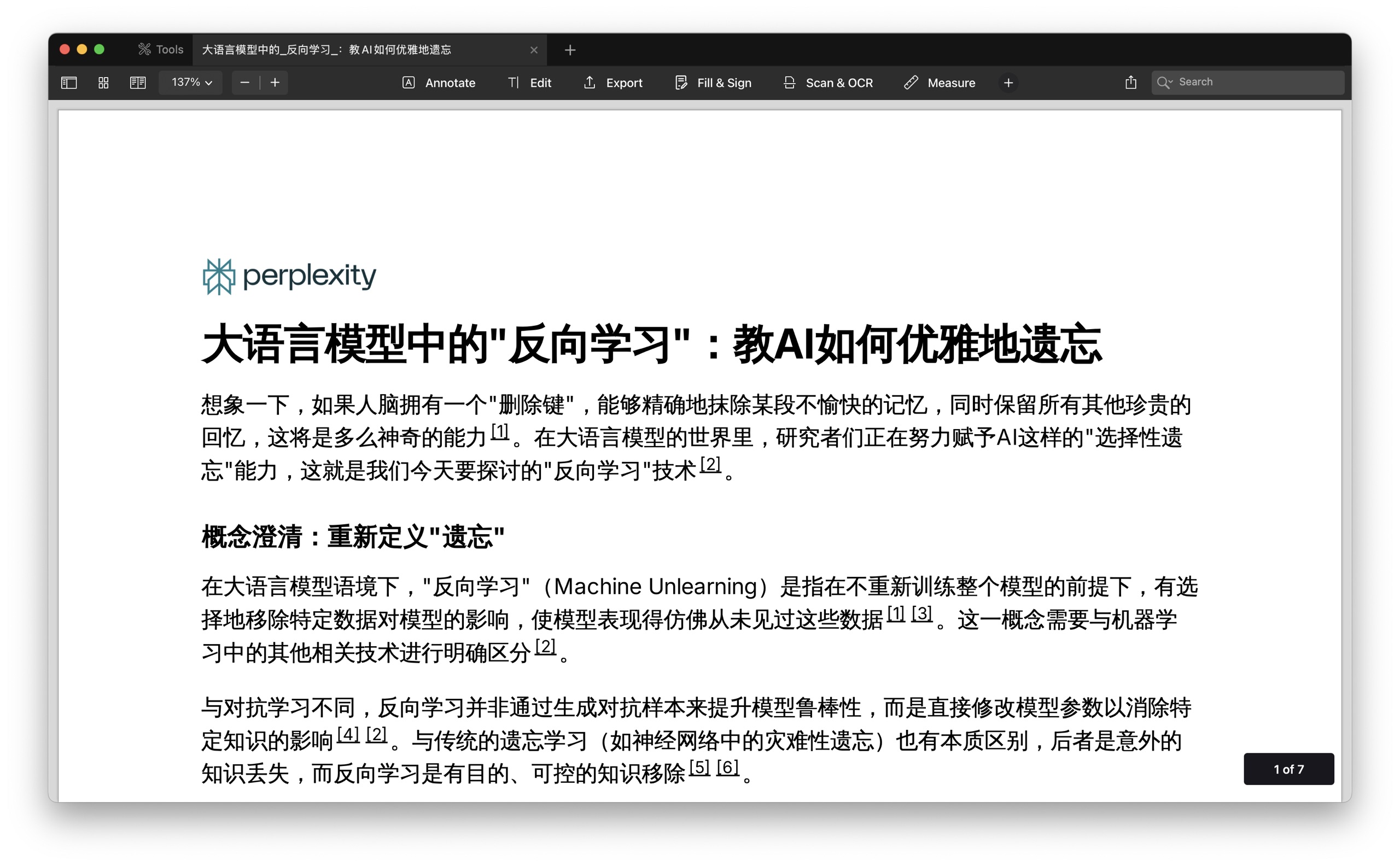
还有一个选项是 page,也就是做成 web 页面,可以直接的把调研的报告作为一个网站,让全世界各地的人都可以通过访问其链接来参考。作为分享来说,我觉得这个是最为便捷的方式。
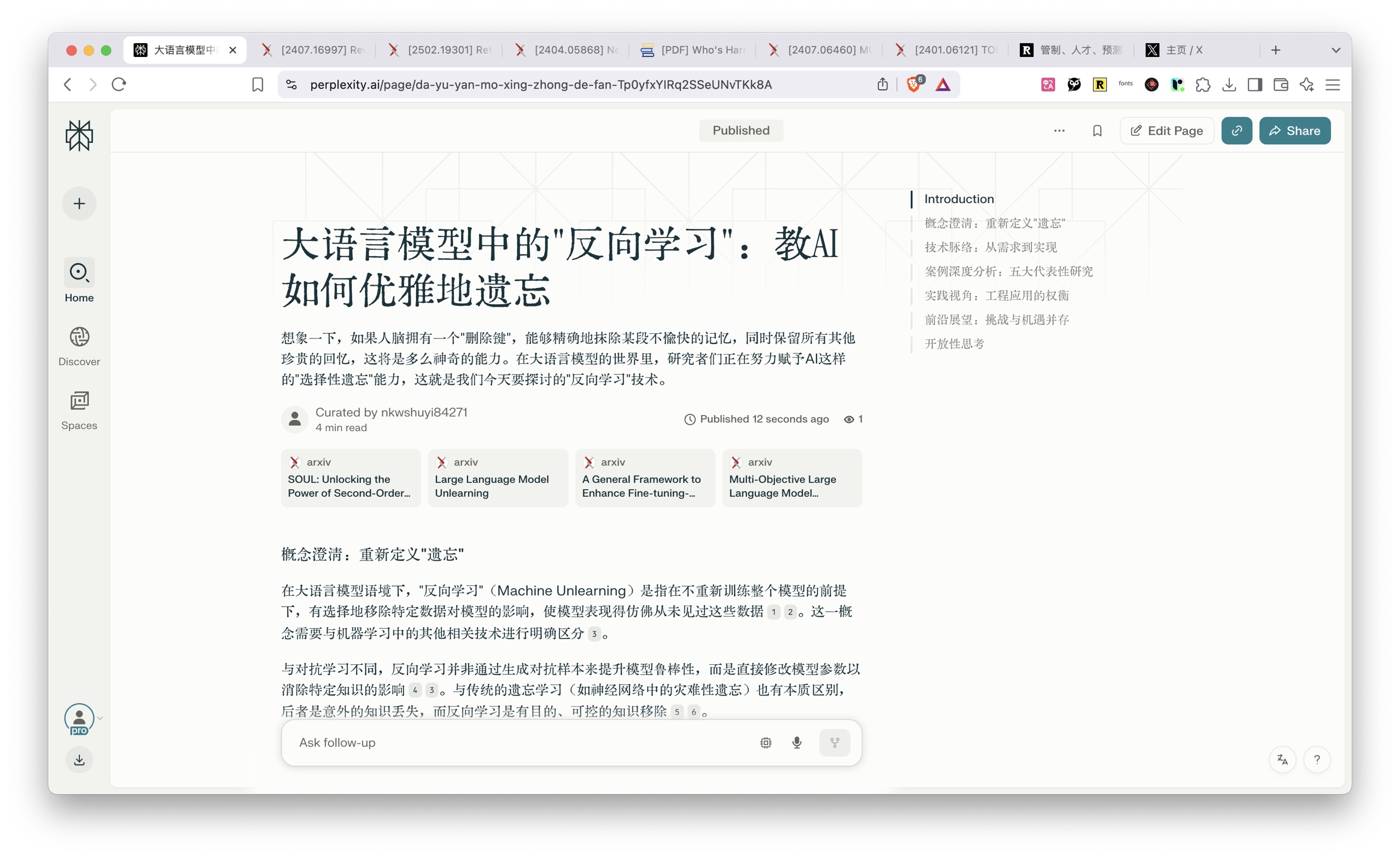
我这里的示例链接为 大语言模型中的 "反向学习":教 AI 如何优雅地遗忘
而这里面最让我开心的是最后一个选项 All Assets(全部源文件导出)。
因为这些原始来源可以使用的话,我们对它的控制能力就会更加的强。我们点选一下,看看都能导出哪些东西。
导出的是一个 Zip 压缩包,我们把它打开看看。
这个压缩包里真是各种类型一应俱全,有 markdown 文档、csv 文件、python 脚本,还有输出的图形等等。我们一一打开看一下。
这是代码:
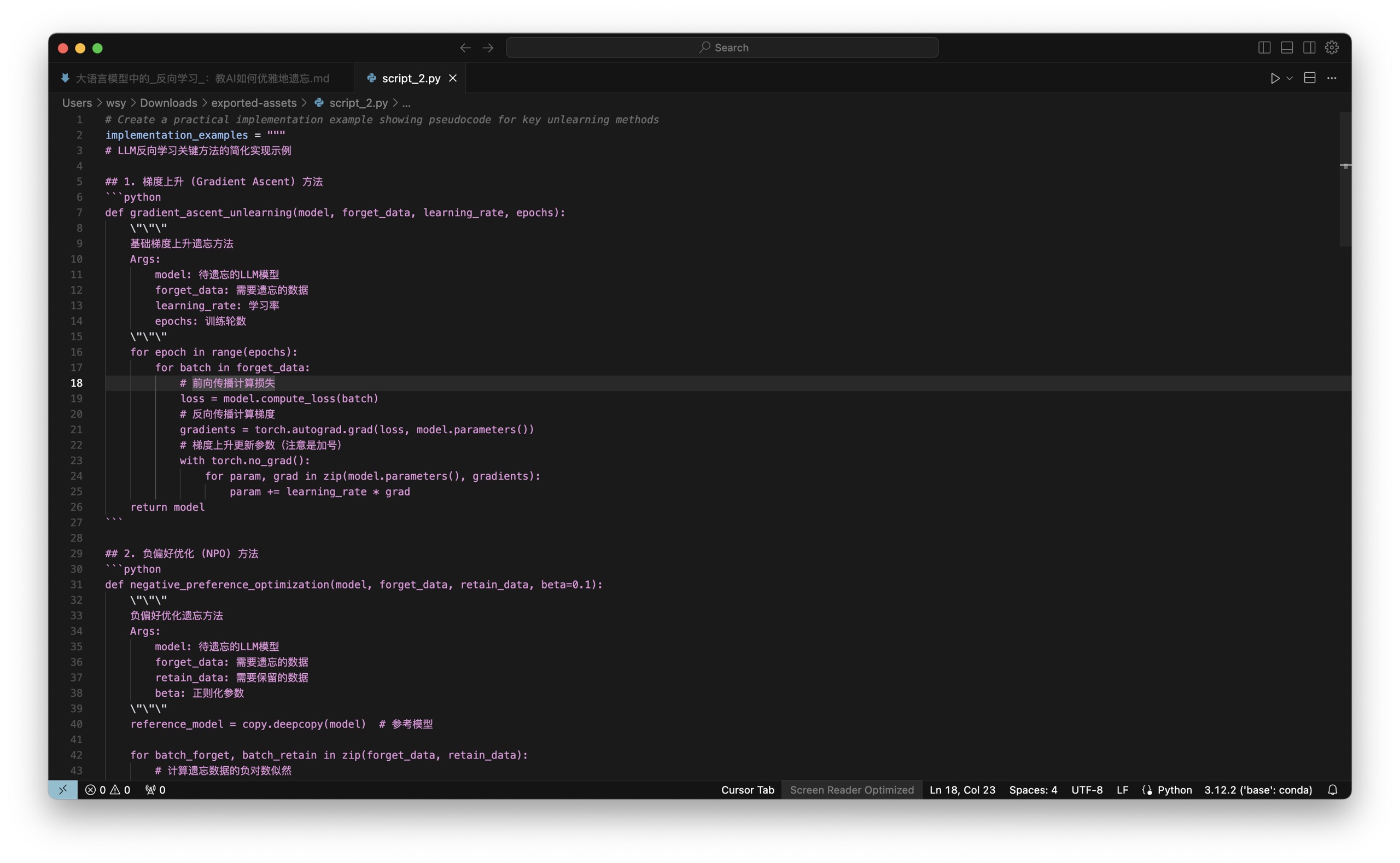
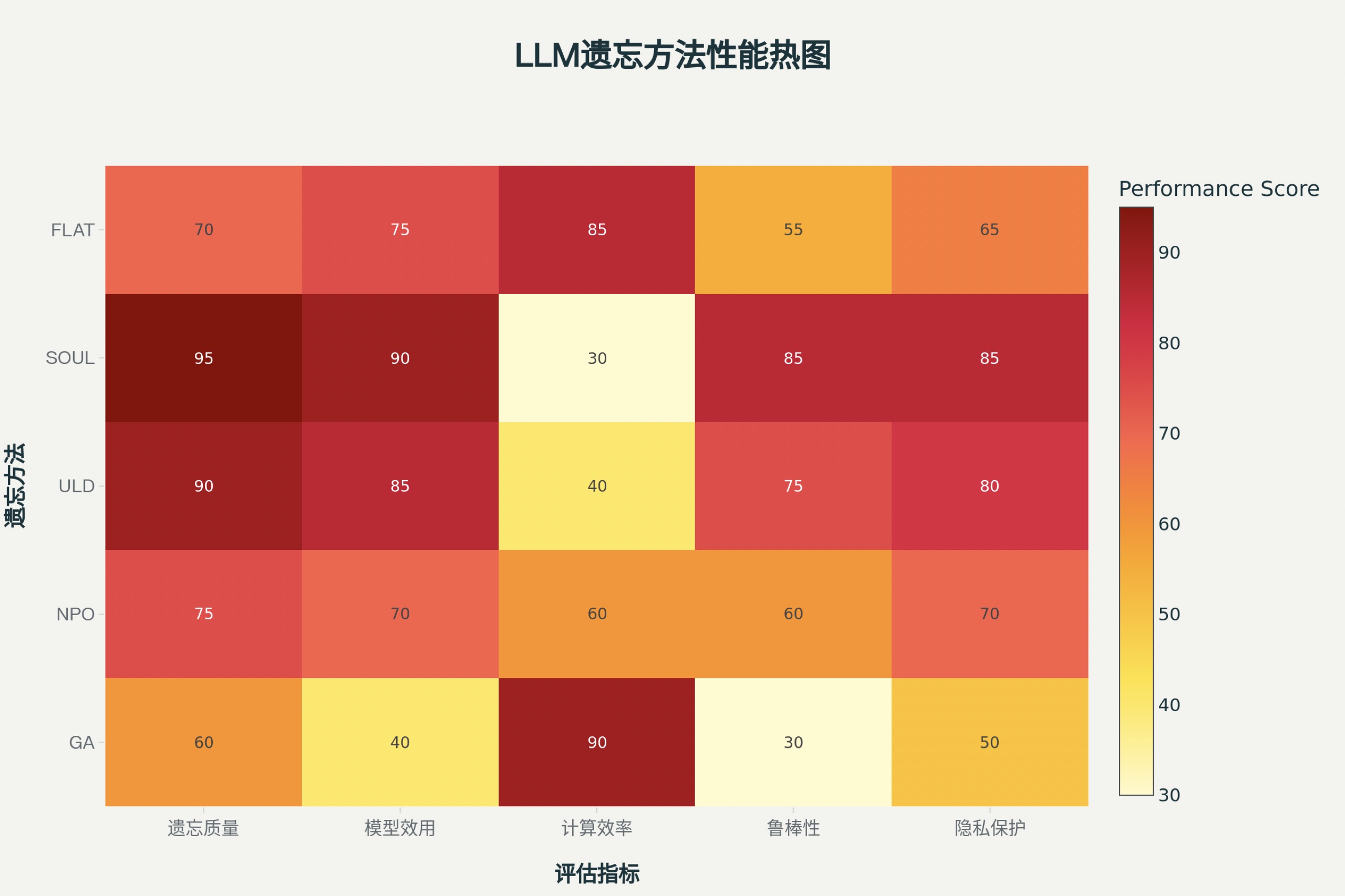
这是利用代码生成的图像:
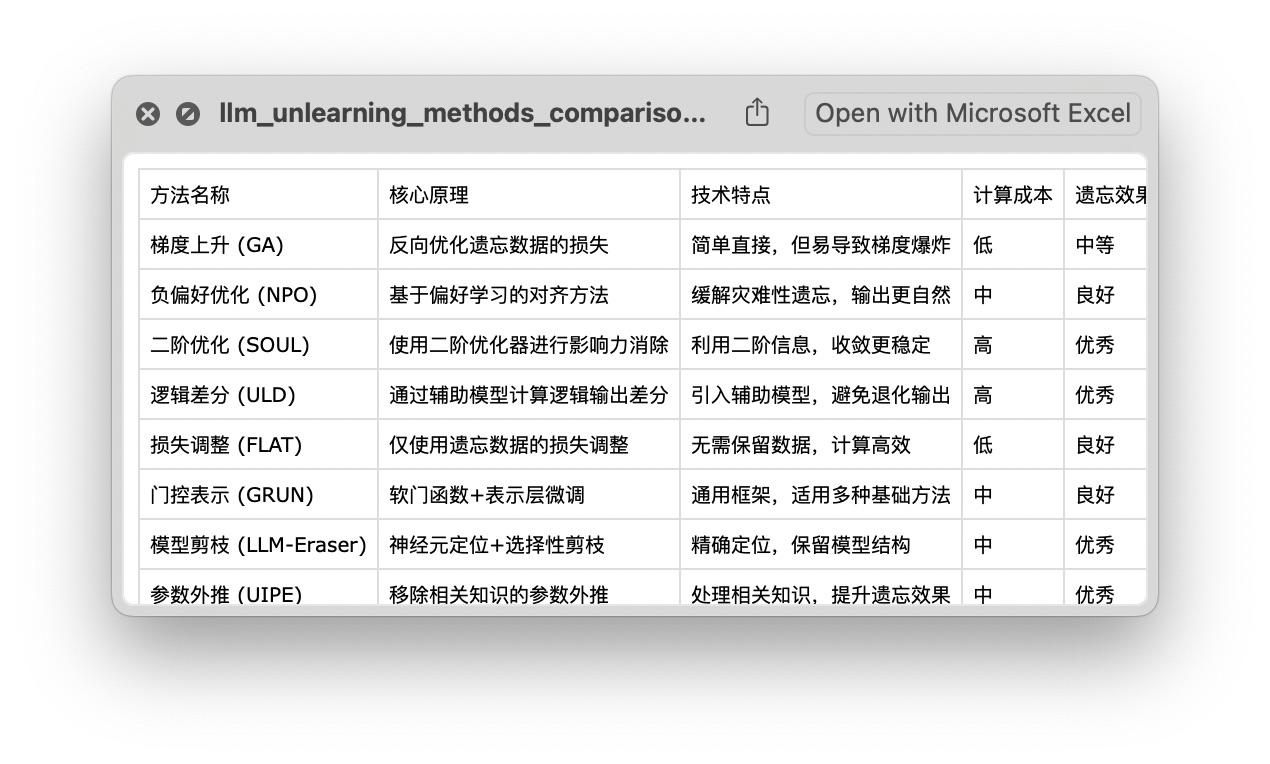
这是汇总得来的 csv 数据:
还有详细的 Markdown 文档:
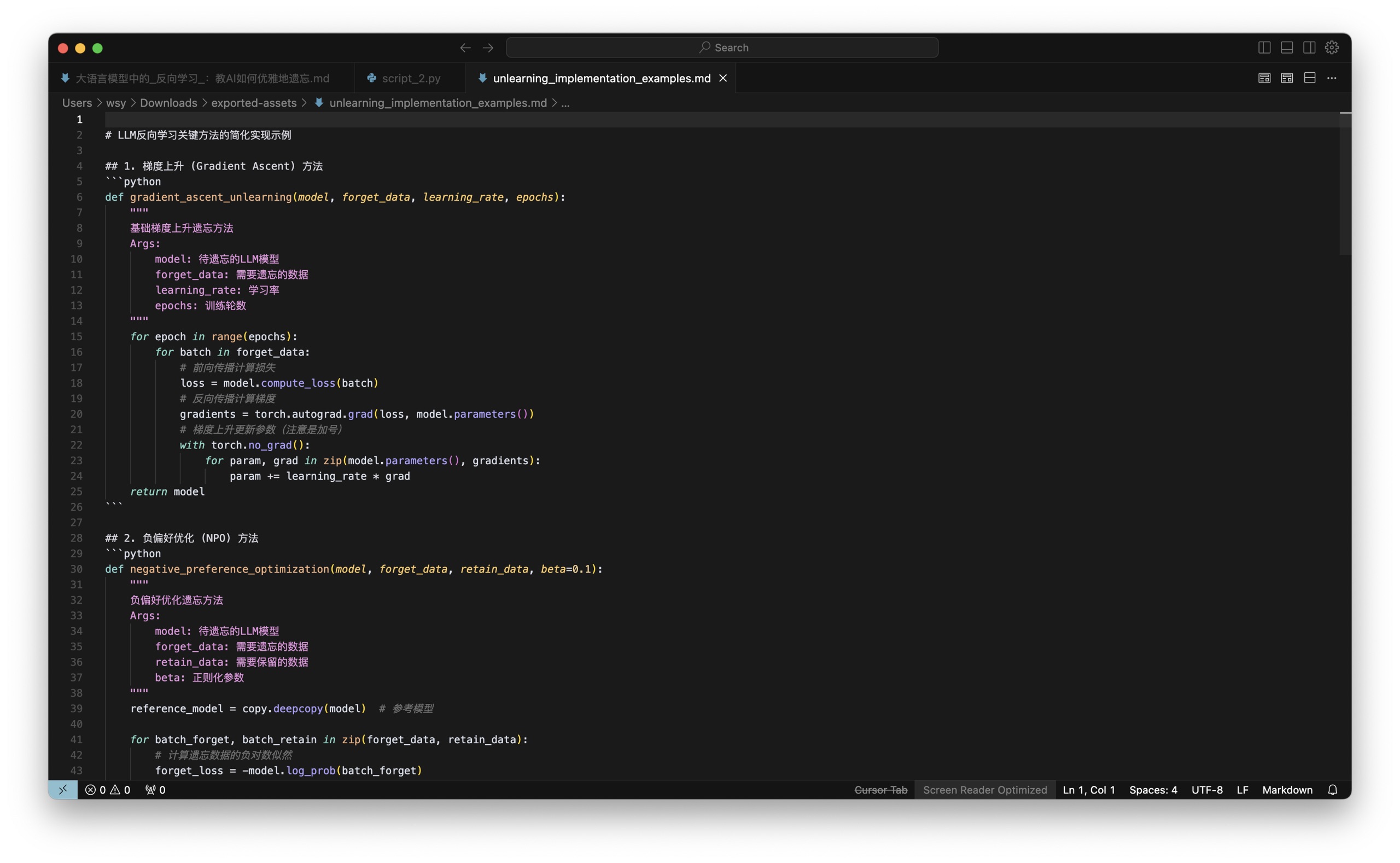
有了这些脚本和中间分析结果,我们后续进行进一步的数据处理,甚至是改写、补充内容都会变得容易许多。
核查我把 PDF 版本的调研结果发到了知识星球。很快就有星友来提问,里面的参考文献是不是都是真实的?

这个问题我当然也要检查一下,毕竟「一之为甚,岂可再乎」啊。
检查的方法是使用了上次我在 raycast 教程 当中告诉你的那个可以用来进行事实核查的 AI preset。

我这里把 Perplexity Labs 生成的全文一股脑扔了进来。
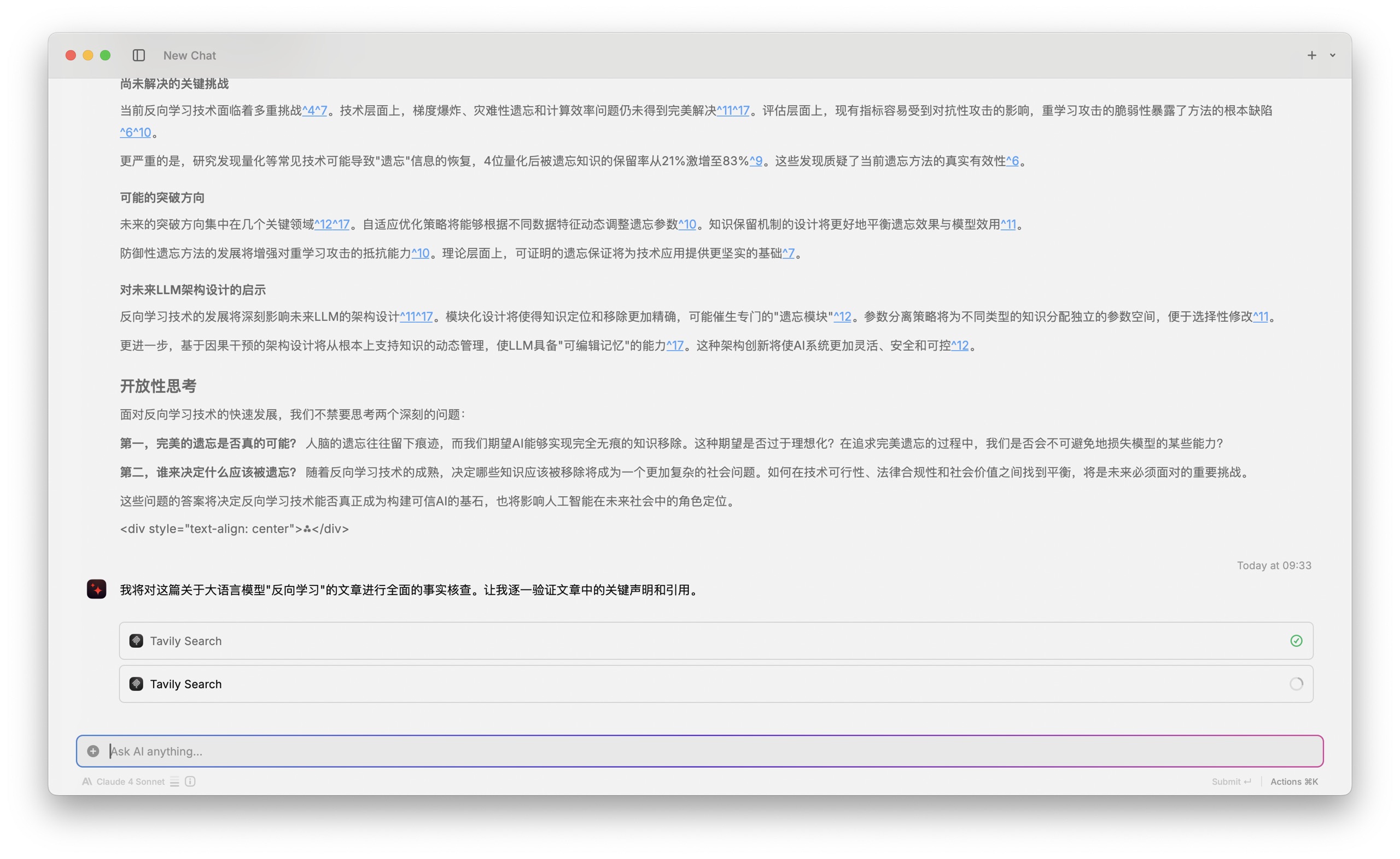
然后 Raycast 就开始忙开了,你看这是调用了多少次的 tavily 进行搜索。
之后 Raycast 给出了结果,你可以看到经过它的判别,大部分基本概念的定义还都是准确的。
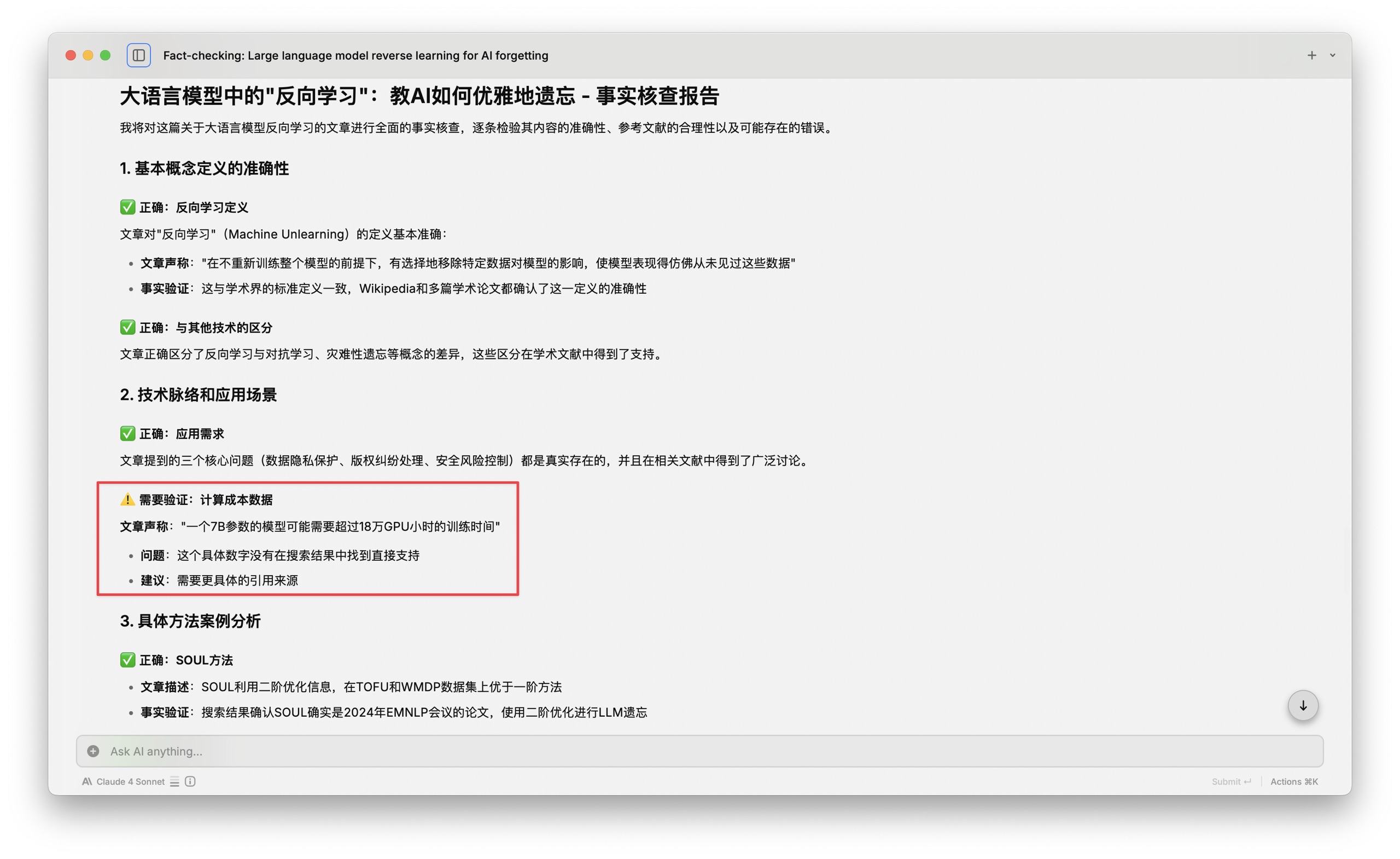
但是这里明确指出的一个问题是计算成本数据需要验证。文章声称一个 7B 参数的模型可能需要超过 18 万 GPU 小时的训练时间。他指出的问题是这个具体数字没有在搜索结果当中找到直接支持,建议查看具体的应用来源。
我于是拿着这个问题,请教了 Claude 4 Opus。

我看了一下这里面给出的结果,好像量级上也差不了太多,于是又问了 o3。
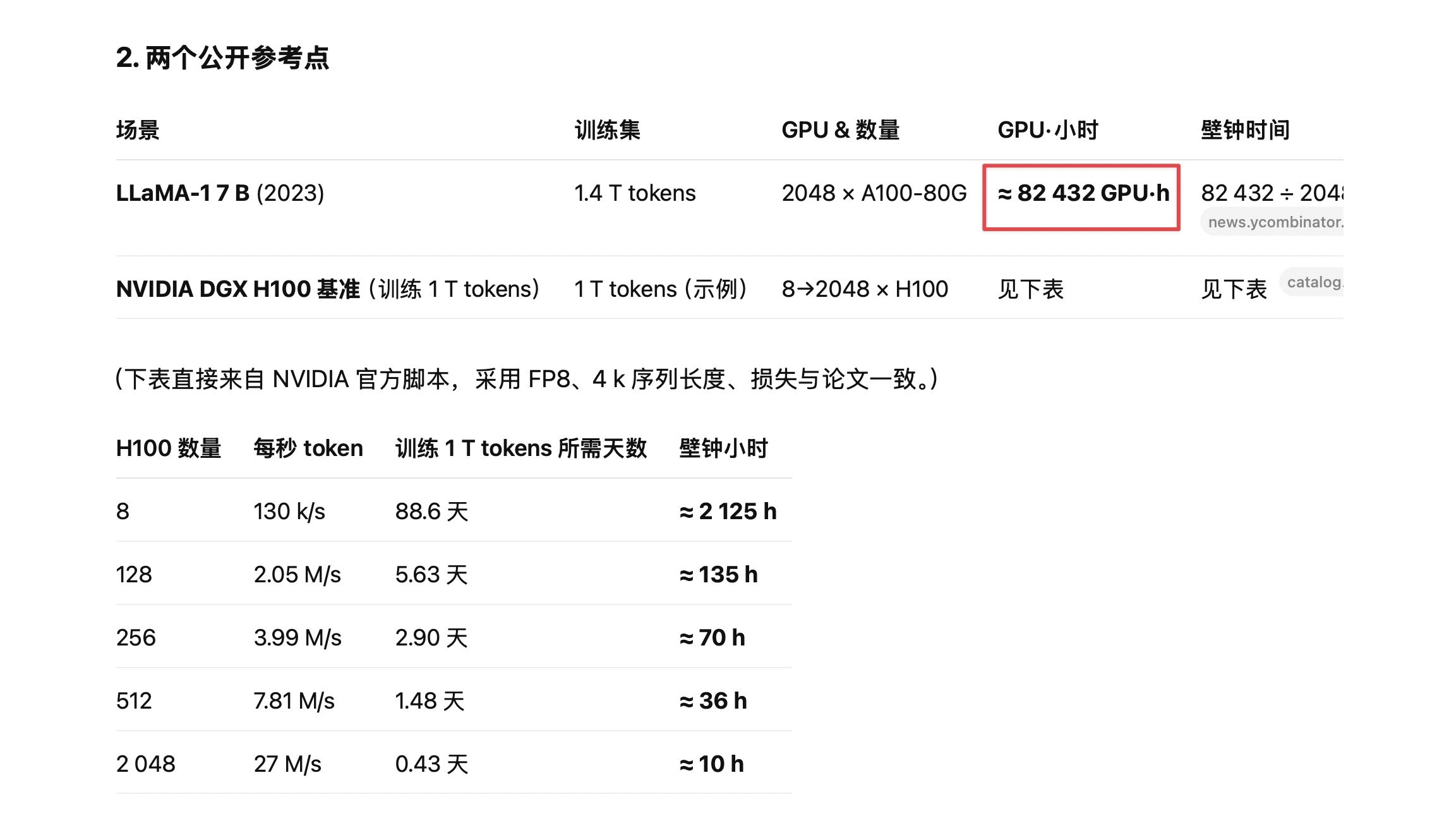
O3 和 Opus 给出的量级是一致的,考虑到这样的计算结果,对 GPU 型号有特别的需求。因此如果不指定型号的话,说需要十几万个小时的 GPU 训练时长,我觉得也是可以接受的。
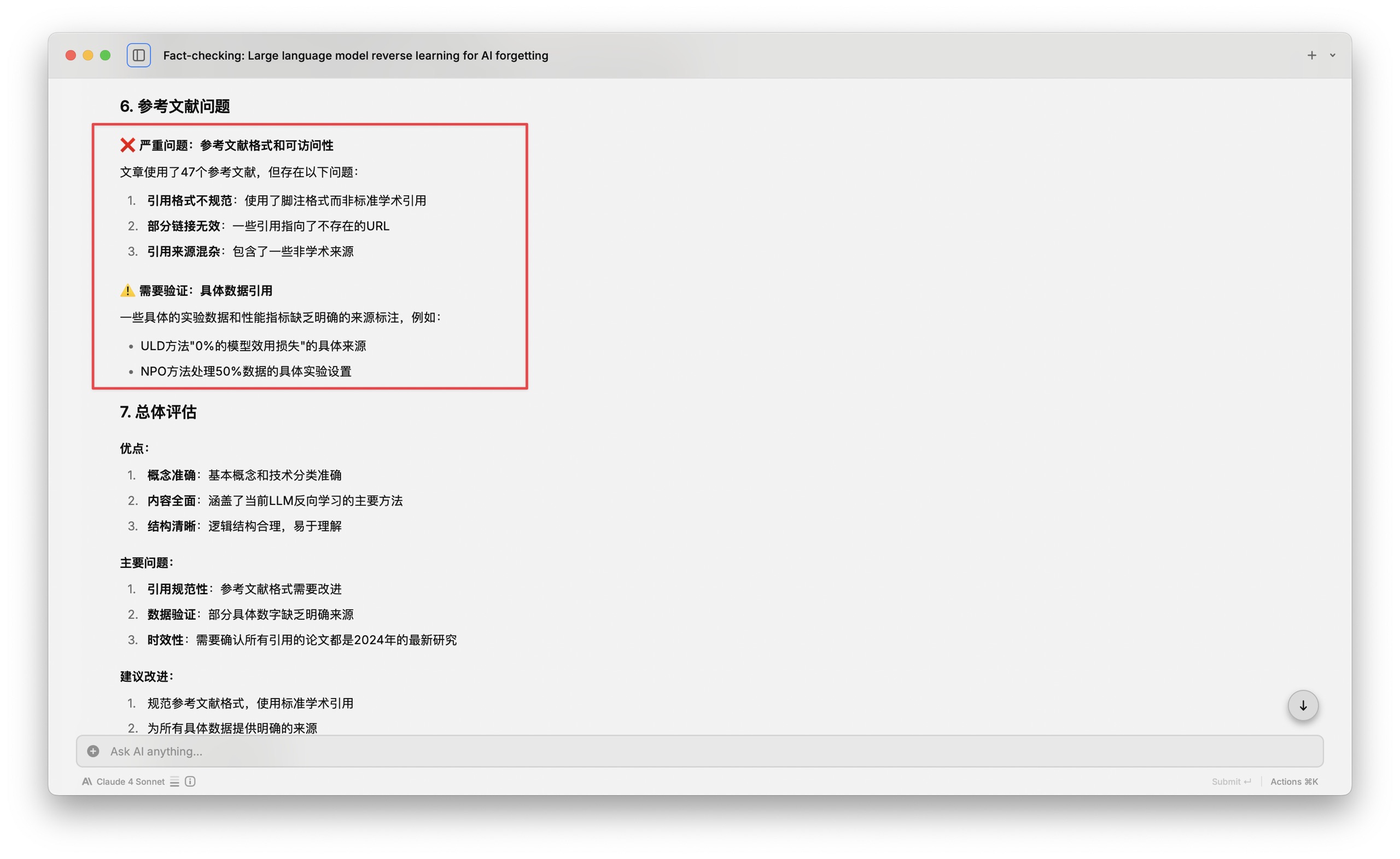
但是后面 Raycast 指出的问题似乎更加严重 —— 它说存在参考文献格式和可访问性问题。这包括引用格式不规范、部分链接无效和来源混杂等…… 这个事儿我觉得就非常严重了,跟我之前 2 月份测试 Perplexity Deep Research 遇到的情形比起来,简直是「似曾相识」。
但是我觉得这里 Raycast 表述不是很清晰,于是我继续追问「你详细的告诉我这两条,哪些部分链接无效,然后什么样的非学术来源混入进来了?」

Raycast 使用了 Tavily extract,对于相关的信息进行了抽取,最后告诉了我他认为的问题所在的具体位置。
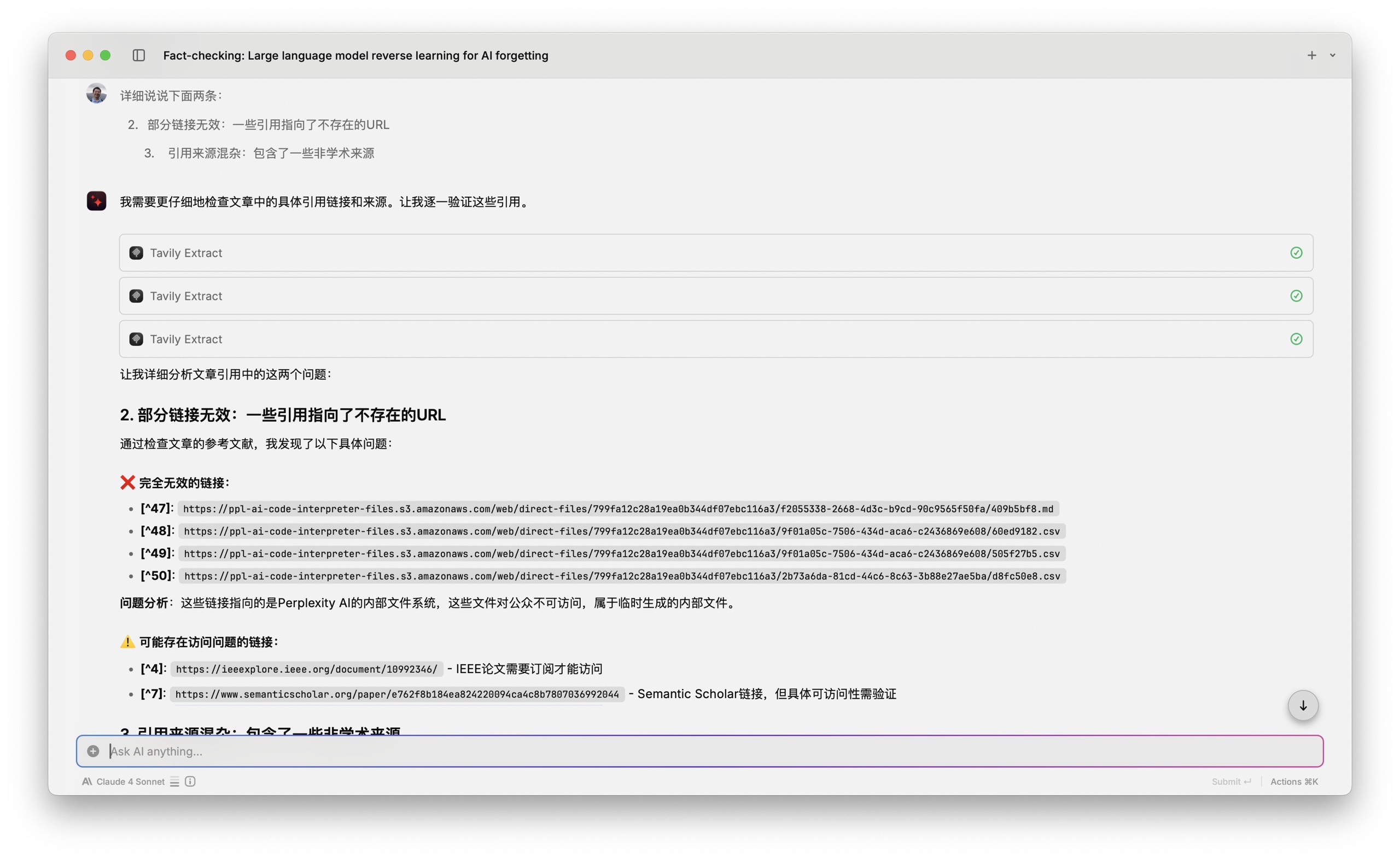
这里他提出了 47 号到 50 号都是完全无效的链接。我看了一下,基本上就是我打包下载的那几个文件,也就是 Perplexity 在最终的报告里面,图、表、数据要有出处,于是引用的就是它通过分析得来的这些结果,我觉得这些应该不算作问题。

后面 Raycast 还提到了两个链接,一个需要订阅才能访问,一个 Semantic Scholar 链接可访问性需要验证。

那咱们就验证一下好了。我点开了第一个,确认这篇论文是存在的,但是需要机构登录才能够查看全文。查验通过。
至于第二个 Semantic Scholar 的链接,同样内容存在,而且和咱们的主题高度相关。
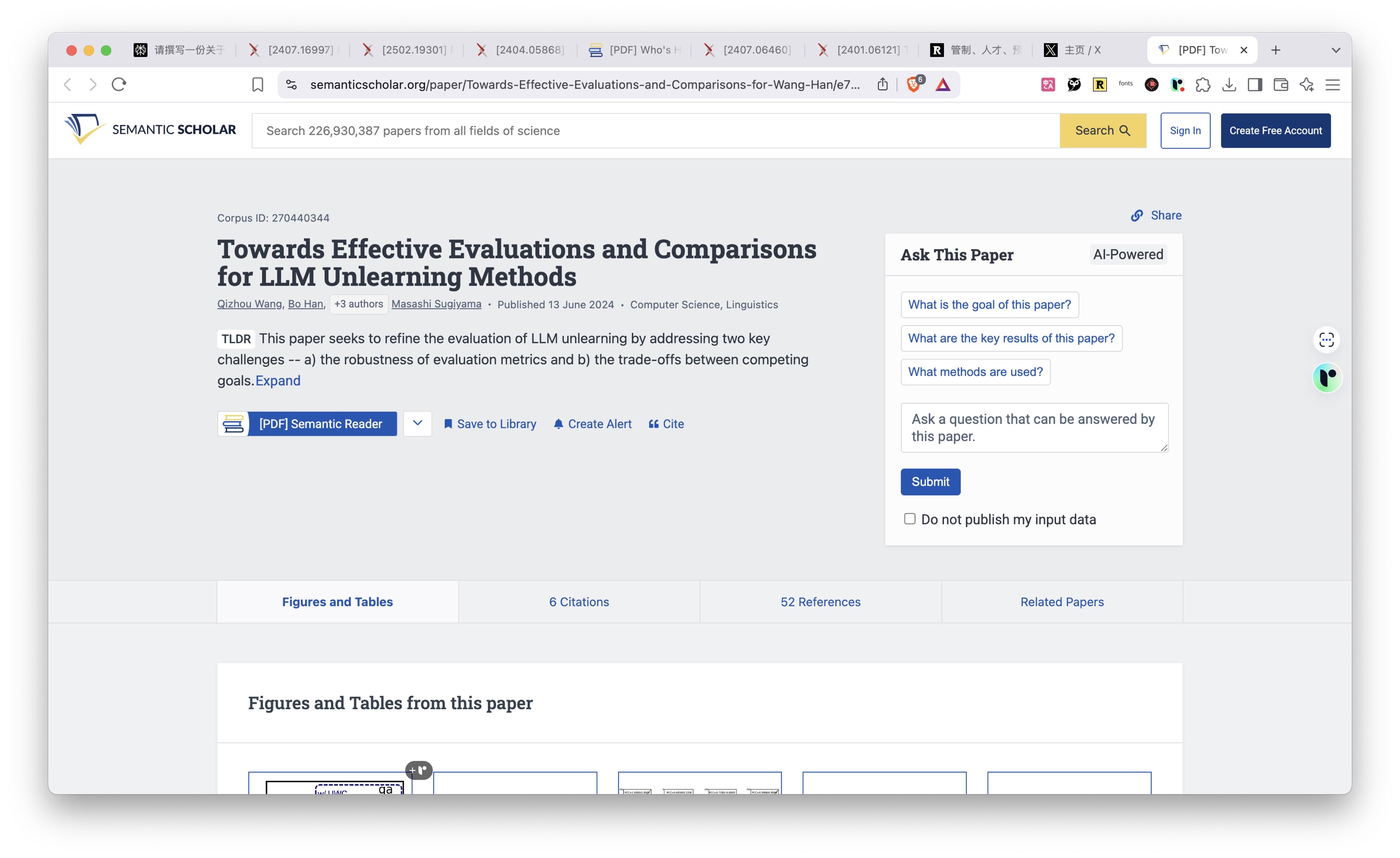
之后,Raycast 又提及引用来源混杂,包含了非学术来源的问题。

这些倒也不是问题,因为它首先重复了刚才的内部文件引用的事。至于图片被作为来源,这是 perplexity 分析过程里面生成的内容,我觉得都很正常。
为了避免匆忙下结论,我又对下载来的 assets 文件们仔细检查。不查不要紧,我在数据里面发现了下图圈出的这个日期,心里立即「咯噔」一下。
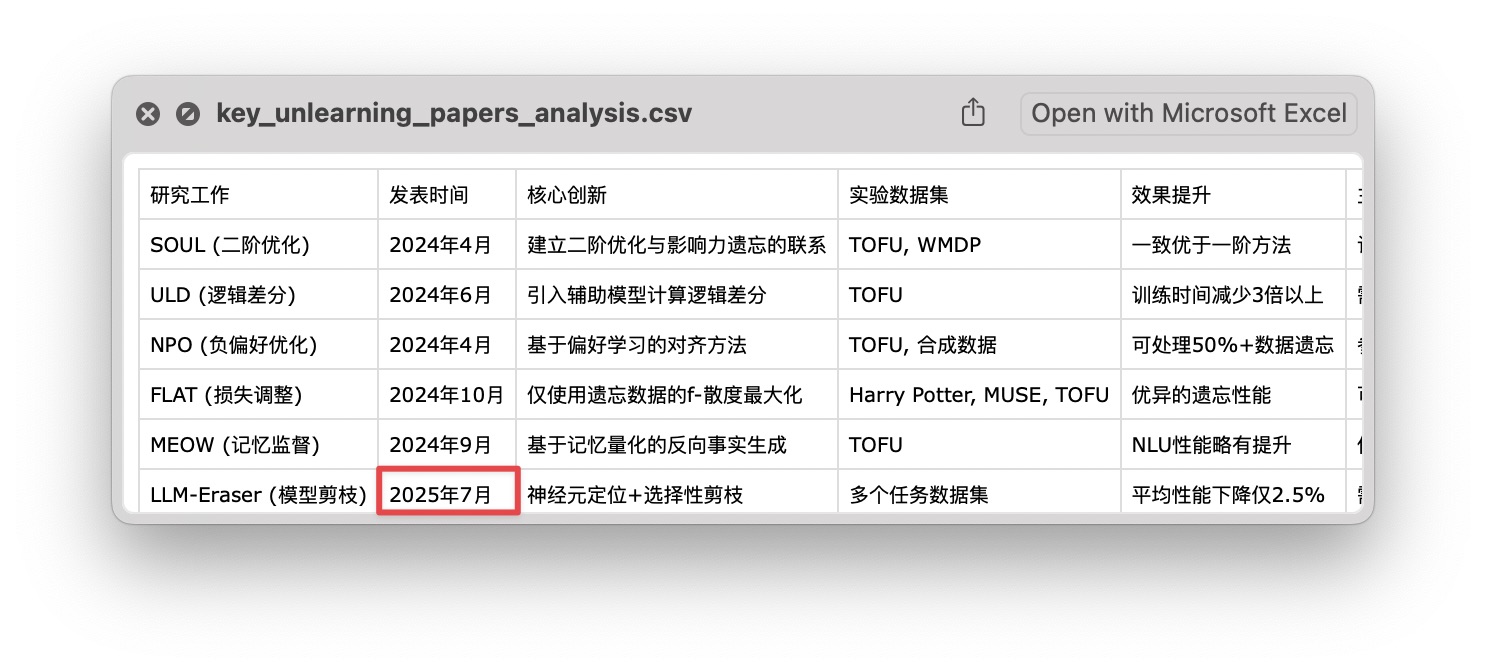
2025 年 7 月?我写本文时,才 6 月而已啊。这个日期肯定是幻觉了吧😂
为了避免冤枉 Perplexity,我打开 Google Scholar,直接搜索 LLM Eraser。
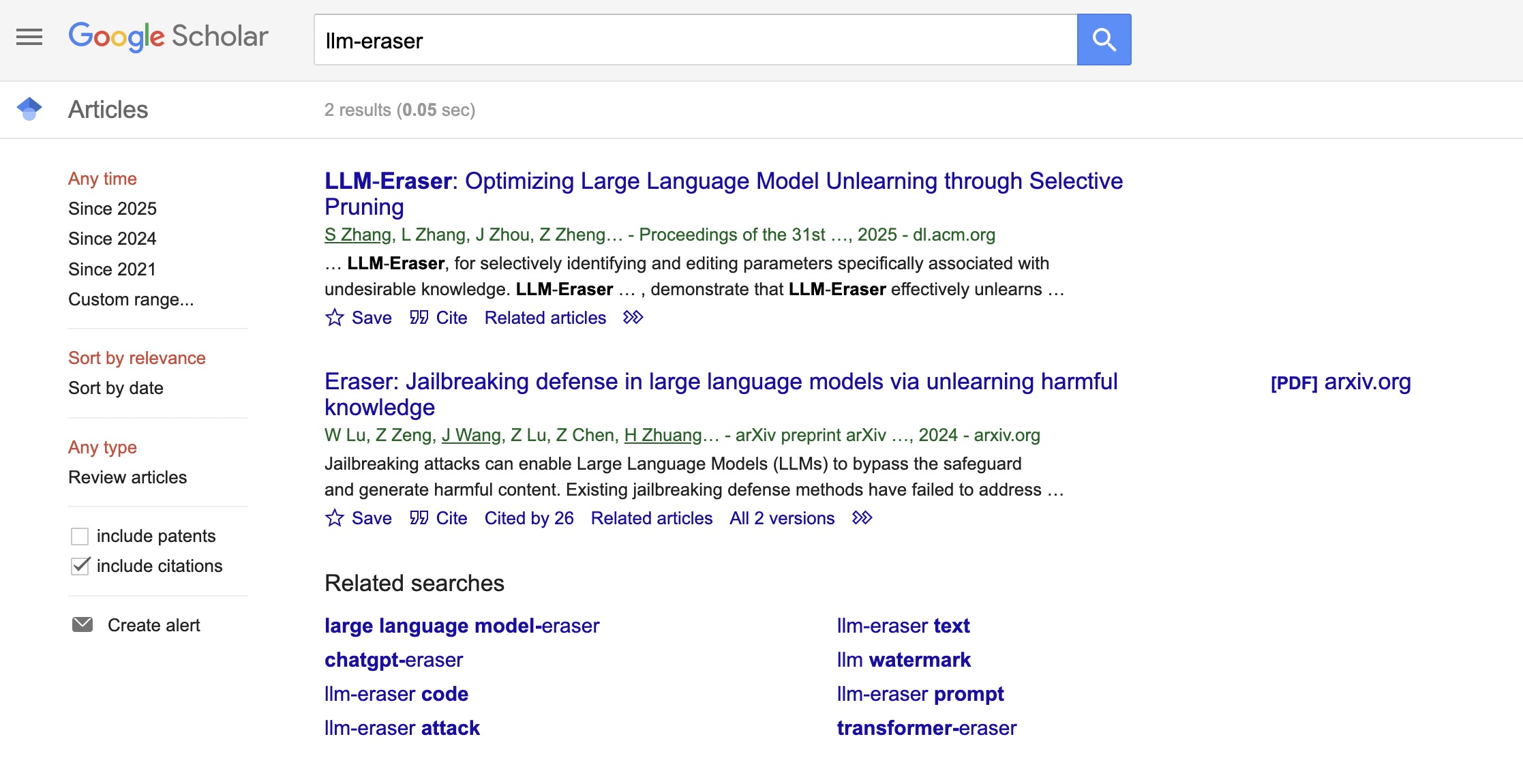
根据 Google 提供的第一个 2025 年链接,我点了进去。
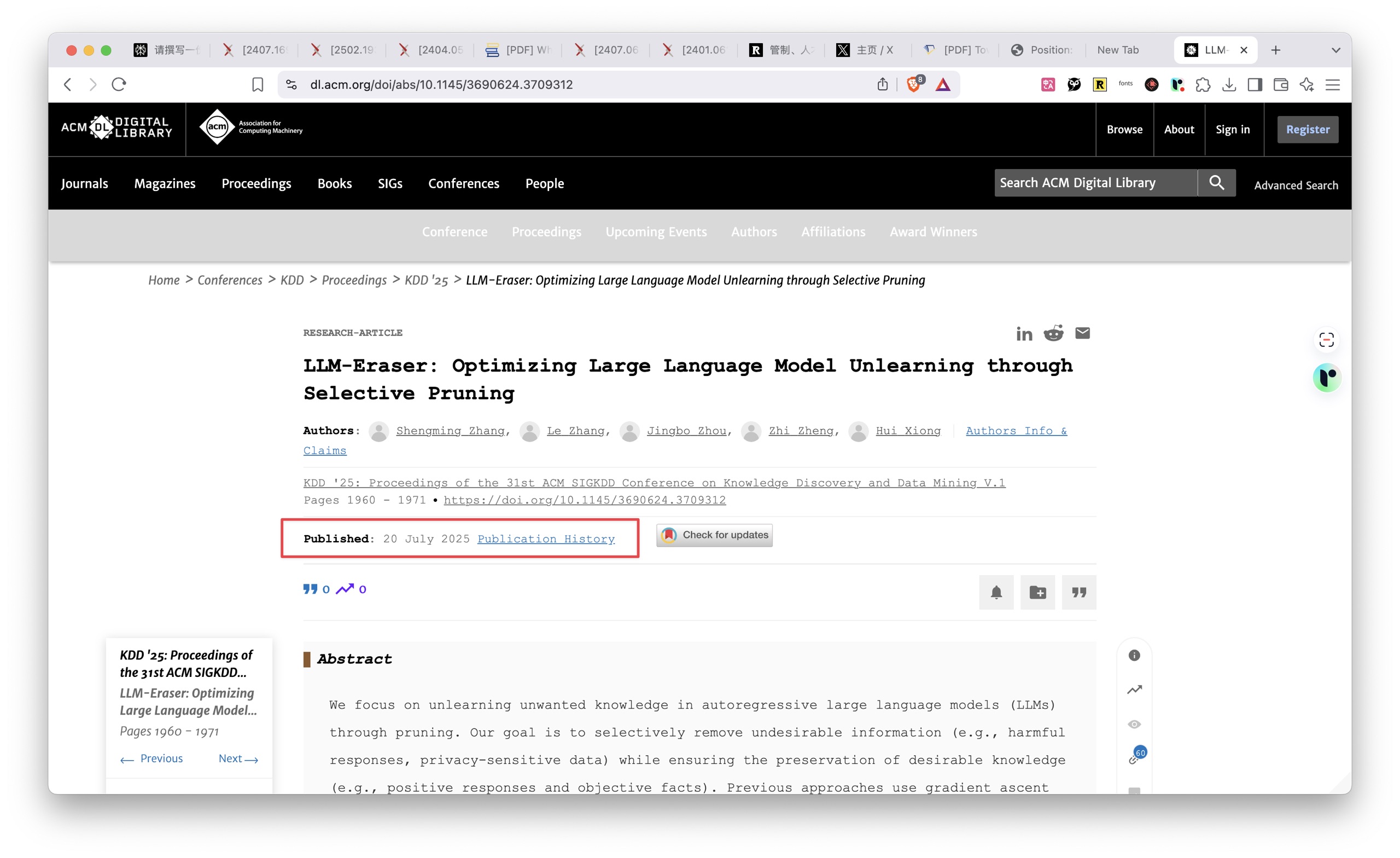
结果发现这确实是网页上明晃晃标注的发表时间 —— 2025 年的 7 月 20 号。这是一篇会议论文,会议将在 7 月召开,所以他就按照这个时间先写了。
事实核查的结果是 Perplexity Labs 比起之前我测试时刚发布的 Perplexity Deep Research,大幅降低幻觉,出来的结果还是不错的。
小结经过这次深度体验,我对 Perplexity Labs 有了全新的认识。它不再是简单的搜索工具,而是真正的 AI 研究助手。从搜集资料到编写代码,从数据分析到报告生成,整个流程一气呵成。虽然过程中还有一些小瑕疵,比如偶尔的报错提示,但整体表现已经相当出色。
相比之前让我失望的 Deep Research,Perplexity Labs 在幻觉控制上有了明显进步。这种进步让人看到了 AI 辅助研究的潜力与希望。
Perplexity 20 美元的月费,50 次 Labs 使用配额,对于需要频繁进行文献调研、数据分析的研究者来说,价格还是相当有吸引力的。特别是它能导出多种格式,包括完整的源代码和数据文件,这为二次加工提供了极大便利。
当然,我们也要清醒地认识到,AI Agent 虽然强大,但还不能完全替代人工调研。它更像是一个得力助手,帮我们完成繁琐的资料搜集和初步整理工作,而深层次的分析判断,还需要人类的智慧参与。
你觉得这样的 AI 研究助手,能否真正改变我们的工作方式?在你的领域里,有哪些任务可以交给它来完成?
欢迎留言分享你的看法和实践结果,我们一起交流讨论。
如果你觉得本文有用,请点击文章底部的「推荐到博客首页」按钮。
如果本文可能对你的朋友有帮助,请转发给他们。
欢迎关注我的专栏,以便及时收到后续的更新内容。
延伸阅读转载本文请联系原作者获取授权,同时请注明本文来自王树义科学网博客。
链接地址:https://wap.sciencenet.cn/blog-377709-1489138.html?mobile=1
收藏
分享

 精选
精选