
 精选
精选
大型语言模型(LLM)的崛起在过去几年引发了人工智能领域的飞跃式发展。尤其是 2022 年底 OpenAI 推出的 ChatGPT,短短两个月内月活用户就突破一亿,成为史上用户增长最快的消费者应用 (ChatGPT sets record for fastest-growing user base - analyst note | Reuters)。ChatGPT 所展现的强大自然语言对话和内容生成能力,如一场“核爆”引发全球对于通用人工智能的极大关注,各行各业开始思考如何将这类大模型应用到实际业务中。紧随其后,OpenAI 发布了更先进的 GPT-4 模型,能够理解更复杂的指令,并支持图像等多模态输入。这场由 ChatGPT 引领的LLM浪潮,不仅催生了大量类似产品和开源模型,也让“ AI 更自主地完成复杂任务”成为下一个技术探索热点。在这种背景下,由 LLM 驱动的 Agent(智能代理)概念逐渐兴起,成为 AI 技术爱好者和产业从业者共同关注的前沿方向。
从 Copilot 到 Agent:概念演进Copilot(协作助手)与Agent(智能代理)是近期 AI 应用发展的两个重要概念。二者在定位和功能上有差异:Copilot一般指能够辅助人类完成任务的智能助手,它与用户并肩工作,在人类指令下提供建议、自动化部分流程,但始终由人来掌控最终决策 (AI Co-Pilot vs Agentic AI – Key Differences)。例如,GitHub Copilot 可以根据开发者当前的代码上下文自动补全代码片段,但不会自行决定要编写哪个功能;微软 Office Copilot 能帮助撰写文档或生成幻灯片,也是根据用户提示进行内容生成。本质上,Copilot 更像是人类的副驾驶,增强人类能力但不取代人做主导。
与此相对,Agent(智能代理,智能体)则代表了一种更加自主的 AI 系统。Agent可以在给定高层目标后自主决策下一步行动,具备自主规划和任务执行能力 (What is an AI Copilot? How is It Different From an AI Agent?) (AI Co-Pilot vs Agentic AI – Key Differences)。智能代理不仅能像 Copilot 那样提供建议,还能在必要时自行调用工具、执行操作,完成整个任务流程,而只需较少的人为干预 (What is an AI Copilot? How is It Different From an AI Agent?) (What is an AI Copilot? How is It Different From an AI Agent?)。一句话,Agent更强调全流程的任务负责:从理解目标、制定计划、执行步骤、到最终达成目标,均可由 AI 系统自主完成 (AI Co-Pilot vs Agentic AI – Key Differences)。例如一些自主代理可以根据用户的一个高阶指令(如“帮我规划一次欧洲旅行”),自己上网搜索信息、调用日历和邮件 API 安排行程,最后给出完整的旅行计划。这样的自主性是 Copilot 所不具备的。可以说,Copilot 是在人类驾驶下的辅助,而 Agent 更接近一种自主驾驶的 AI。正因如此,Agent 被视为 AI 应用形态的下一步演进,能释放 AI 更大的潜力。
需要指出的是,Agent 并不是全新的概念。在经典 AI 文献中,“智能体”概念由来已久,只是以前的智能体往往采用规则算法或狭窄AI,而如今的 Agent 则借助 LLM 的通用智能和推理能力,实现了以自然语言为思维和行动媒介的自主智能体 (Introduction to LLM Agents | NVIDIA Technical Blog)。
LLM 驱动的 Agent在2023年随着 AutoGPT、BabyAGI 等agent早期开源项目而进入大众视野 (Introduction to LLM Agents | NVIDIA Technical Blog)。这些系统展示了在几乎无人干预下,AI 代理可以基于一个开放目标,不断生成行动方案、调用工具执行、并迭代调整,最终完成复杂的问题求解。这标志着从 Copilot 到 Agent 的理念飞跃:AI 不只是辅助,而是开始展现出一定程度的自主性和连续决策能力。下一节我们将深入剖析,实现这种自主智能代理所需的核心技术能力。
Agent 关键技术能力要让 LLM 驱动的 Agent 真正拥有自主解决问题的能力,背后涉及多项关键技术和架构设计。本节将从Agentic Flow(代理流程)、工具使用(API 调用与计算机操作)、自主规划以及多模态能力四方面解析智能代理的核心能力。
Agentic Flow:智能代理流程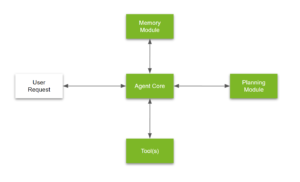 Figure 1. General components of an agent
Figure 1. General components of an agent
from developer.nvidia.com
LLM智能代理的一般架构示意图(made by ChatGPT o3)
Agent接收用户请求(目标),经由中心的“Agent Core”协调记忆模块、规划模块和工具执行等组件,最终产生对用户的回应或实际行动结果。如图所示,Agent Core(代理核心)是大脑,负责总体决策和流程控制;它一方面与用户需求和长期/短期记忆交互,另一方面调用规划模块来分解任务并选择合适的工具执行 (Introduction to LLM Agents | NVIDIA Technical Blog) (Introduction to LLM Agents | NVIDIA Technical Blog)。
典型的代理流程如下:首先,Agent 读取用户指令和当前上下文,将其转化为内部的目标表示;然后通过Reasoning(推理)过程思考如何完成任务,可能将大任务分解为子任务;接下来进入Planning(规划)和Decision(决策)阶段,确定需要调用的工具或采取的行动序列;随后,Agent执行具体Action(行动)例如调用某个API或函数、检索信息等,并观察获得的结果 (Plan-and-Execute Agents);Agent 将观察结果存入记忆或用于更新下一步策略,如此在“思考-行动-观察”的循环(即 Agentic Loop)中不断迭代,直到达到任务目标或满足终止条件 (Plan-and-Execute Agents)。
在整个过程中,LLM 充当了核心推理引擎,结合提示(Prompts)来决定每一步该做什么。相比简单的一问一答式对话,这种 Agentic Flow 使得 AI 可以多步连贯地处理复杂任务,正如人类解决问题时需要反复思考、尝试、纠正一样。为了支持这一流程,Agent 通常需要配套短期记忆(记录当前对话和思考链)和长期记忆(存储长期知识或历史),以确保决策具有连贯性和智能性 (Introduction to LLM Agents | NVIDIA Technical Blog) (Introduction to LLM Agents | NVIDIA Technical Blog)。通过精心设计提示和上下文,LLM Agent 可以在这种循环中保持方向感,不断朝着最终目标逼近。
工具使用与计算机操作赋予 Agent 行动能力的关键是在需要时调用外部工具或执行计算机操作的能力。这通常通过为 LLM 提供插件接口、API 调用权限甚至直接的计算机操作权限来实现。当仅靠语言模型自身难以完成任务时,Agent 可以调用预先定义的一系列工具,例如访问网络API、数据库查询、运行代码、控制第三方应用等 (Introduction to LLM Agents | NVIDIA Technical Blog)。
OpenAI 的 ChatGPT 插件和函数调用机制就是让模型产生特定格式的输出以调用工具函数,从而查询实时信息或执行计算任务。例如,当用户问天气如何,Agent 可以调用天气API获取实时数据;又如面对复杂的算术或数据分析任务,Agent 可调用 Python 代码执行并返回结果。这种Tool Use能力极大拓展了 Agent 的能力边界,使其不仅能“思考”,还能真正“动手”。
目前常见的工具类型包括:搜索引擎(用于信息检索)、知识库/RAG检索(基于向量数据库查资料)、浏览器(访问网页)、编程解释器(执行计算和代码逻辑)等 (Introduction to LLM Agents | NVIDIA Technical Blog)。一些 Agent 框架还结合了传统的RPA(机器人流程自动化)技术,使LLM能够控制鼠标键盘去操作应用界面,实现如自动表单填写、跨系统数据搬移等复杂操作流程。需要注意的是,在调用工具时,Agent 必须先通过决策模块判断何时需要工具以及选择何种工具,这通常由LLM根据当前任务状态和预设的工具列表自主决定 (Agents | Mistral AI Large Language Models)。因此,工具使用能力依赖于LLM对自身能力边界的“自知”,知道何时该借助外力。总体而言,让Agent学会用工具,就像教会AI使用人类的双手和眼睛,它是实现从语言到行动的桥梁,也是当前Agent技术最具实用价值的方面之一。
自主规划与决策自主规划(Planning)是智能代理得以自主完成复杂任务的核心支柱。LLM 通过连贯的推理,可以对给定目标进行分解和计划:将复杂任务拆解成更小的子任务,确定执行顺序,并动态调整策略 (Introduction to LLM Agents | NVIDIA Technical Blog)。
早期的 Agent 实现(如 ReAct)采用逐步推理,每一步只考虑当前可以采取的一个动作 (Plan-and-Execute Agents);而更先进的方法则引入了显式的规划步骤,例如先让LLM输出一个完整计划再逐一执行 (Plan-and-Execute Agents)。
自主规划能力使Agent在面对开放式目标时能够有条理地前进,而不至于漫无目的或陷入死循环。此外,决策优化与自主推理也是近年来的研究重点。一种称为“自我反思(Reflection)”或“自我批评(Critic)”的技术被引入,让Agent在行动过程中审视自己的思路和结果,发现偏差并加以修正 (Introduction to LLM Agents | NVIDIA Technical Blog)。比如,Agent 执行一系列步骤后可以调用内部的“Critic”模型来检查当前方案是否走偏,从而避免一直沿着错误方向行动。这类似于人类在解决问题时停下来反思。目前一些实验表明,加入反思循环的Agent在复杂推理任务上的成功率明显提升。
另一个趋势是引入树状思维(Tree-of-Thoughts)等算法,让LLM能在内部探索多个解题路径并比较选择最佳方案,而非贪婪地逐步生成。总体看来,自主规划与决策能力的不断增强,正让Agent变得越来越善于长程思考和自主纠错,从而胜任更复杂、更开放的任务场景。
多模态理解与处理能力人类智能的重要体现是可以综合运用多种感官信息;类似地,智能代理也正朝着多模态(Multimodal)方向发展。传统的 LLM 只处理文本,而多模态 LLM Agent 可以同时理解和生成包括图像、音频、视频在内的多种数据形式 (Gemini - Google DeepMind) (Google Gemini and LLMs: A New Frontier for Multimodal AI - Medium)。
具备多模态能力的 Agent 意味着它不仅能“读”文本,还能“看”图、“听”声,从而在更多元的任务中大显身手。典型例子是 OpenAI 的 GPT-4 已支持图像输入,可以根据一张图片回答问题或描述内容 (Introducing Gemini 2.0: our new AI model for the agentic era - Reddit);Google 最新发布的 Gemini 模型更是从架构上原生支持多模态,在训练时就融合了文本、代码、图像、音频、视频等不同模态的数据,从而具备跨模态的推理能力 (Introducing Gemini: Google’s most capable AI model yet) (Introducing Gemini: Google’s most capable AI model yet)。
多模态Agent能够执行如下任务:根据照片内容回答用户问题、观看一段监控视频后给出分析报告、听取语音指令并执行任务。这样的能力在实际应用中非常关键:例如在医疗领域,Agent可以同时阅读医学影像和医生的文字记录来提供诊断支持;在客服场景中,Agent可以查看用户上传的截图来判断问题所在。需要注意,多模态并不止于感知输入,Agent 也可以生成多模态输出,例如生成图片或语音。这通常通过将LLM与扩展模型(如扩散图像生成模型、文本转语音模型)结合实现。得益于多模态能力,LLM Agent 正在从“语言专家”成长为“全能型AI”。
多模态 LLM Agent 可接受音频、文本、图像、视频等多种输入,并以多模态配合的形式给出综合输出 (Understanding Multimodal LLMs - by Sebastian Raschka, PhD) (Understanding Multimodal LLMs - by Sebastian Raschka, PhD)。例如,用户给出一张物品照片并询问“这是什么?它有什么用途?”,多模态 Agent 能够先识别图像内容(如图中电话机),再结合知识以文本回答其功能。综合来看,多模态能力将大幅拓展 Agent 在真实世界场景中的适用性,使其更加接近人类智能的广度。
行业案例分析随着 LLM 和 Agent 技术的演进,产业界涌现出多个具有代表性的应用和探索案例。以下将分析几家领先企业的进展以及垂直行业中的专用 Agent 应用。
OpenAI(GPT-4 Turbo):作为引爆本轮热潮的OpenAI,在Agent方面的布局主要体现在为其通用模型赋能工具使用和多模态能力上。GPT-4 Turbo 是 OpenAI 在 2024 年底推出的改进版模型,不仅大幅扩充了上下文窗口,还原生支持图像输入和语音输出,实现真正意义上的多模态 (OpenAI Announce GPT-4 Turbo With Vision: What We Know So Far)。更重要的是,OpenAI为GPT系列模型引入了函数调用和插件机制,使ChatGPT从一个纯语言对话助手升级为具备Agent雏形的系统。借助函数调用,开发者可以预先定义工具接口,让GPT在回答问题时自动调用这些工具,获取实时结果再返回给用户。这一能力已经在ChatGPT插件中得到验证,例如Browsing插件让GPT能上网搜索,Code Interpreter插件让其能运行代码并返回结果。OpenAI官方将这套能力称为“扩展GPT的眼界和手脚”,使其可以访问外部信息源并执行操作 (Introduction to LLM Agents | NVIDIA Technical Blog)。可以说,OpenAI 正在把ChatGPT由一个静态问答模型,转变为一个可执行复杂任务的平台型智能代理。
目前,GPT-4 已被广泛用于开发各种自主代理实验,如开源的 Auto-GPT 就是基于 GPT-4 API 实现,让 AI 连续自主执行用户给定目标的一系列操作。这些探索也反过来推动OpenAI不断改进其模型的可靠性和自主决策能力。因此,OpenAI 在Agent领域的显著特点是:以通用大模型为核心,通过插件和API扩展实现代理功能,并逐步增强模型的推理和多模态表现,为各行业构建AI代理打下基础。OpenAI 最新的智能体表现是基于其推理模型o3的 Deep Research 功能,可以就任何题目自动搜寻资料、研读并汇总融合成全面完整、信息可追溯的综述性调查报告。(本文就是 o3 deep research 完成。)
Google Gemini:作为谷歌与DeepMind融合后的产物,Gemini 被定位为面向“代理时代”的下一代大模型 (Introducing Gemini 2.0: our new AI model for the agentic era)。
根据Google官方介绍,Gemini从一开始就按多模态通用智能来设计,能够无缝理解和生成文本、代码、图像、音频、视频等多种模态数据 (Introducing Gemini: Google’s most capable AI model yet)。Gemini在2024年底发布的版本很快取得各类基准测试的领先成绩,展现出卓越的推理和问题求解能力 (Introducing Gemini: Google’s most capable AI model yet) (Introducing Gemini: Google’s most capable AI model yet)。相比前代的PaLM或GPT系列,Gemini的一大亮点是其原生的代理能力。Google在介绍中提到,Gemini不仅擅长对话和问答,还能用于驱动各种AI Agent应用,例如作为机器人控制的“大脑”或复杂软件的自动化脚本助手 (Gemini - Google DeepMind)。DeepMind更展示了一个名为Astra的研究原型,体现Gemini如何作为通用AI助手在多任务环境中充当智能代理 (Gemini - Google DeepMind)。
Google正将Gemini融入其生态系统(如 GCP 云服务等),为开发者提供强大的平台来构建各类智能代理。从某种意义上说,Gemini体现了行业对于“一个模型搞定一切”的追求:既是强大的LLM,又天生适配多模态Agent场景,被誉为谷歌迈向AGI(通用人工智能)愿景的重要一步。
Mistral AI:这是一家崛起于欧洲的开源大模型创业公司,尽管成立不久却在Agent领域引人注目。2023年,Mistral发布了参数规模仅7B的开源模型 Mistral 7B,以小巧模型实现媲美更大型号的性能,展示了高效模型的潜力。更值得关注的是,Mistral AI 正在构建一个完整的平台,帮助用户定制和部署专用的AI代理 (Mistral AI Agent - AI Agent Review, Features & Alternatives (2025))。其官方文档提供了易用的 Agent 创建接口,支持通过简单的高层指令和示例来配置代理行为 (Agents | Mistral AI Large Language Models) (Agents | Mistral AI Large Language Models)。开发者既可以使用 Mistral 提供的 Web 界面拖拽组件生成 Agent,也可通过编程使用其 Agents API 将智能代理集成进自身应用 (Agents | Mistral AI Large Language Models)。Mistral 强调其代理能够利用公司内的专有模型(如精调后的领域模型)以及连接企业自有数据源,打造定制化的企业 AI 助手 (Agents | Mistral AI Large Language Models)。例如,一家金融机构可以用 Mistral 平台快速创建一个熟悉本行内法规和数据的AI代理,帮助完成合规检查和报告生成等任务。
作为开源力量的代表,Mistral AI 正把尖端的LLM能力平民化,让各行业的团队都能“掌控未来”,将大模型部署在自己的环境中 (Mistral AI | Frontier AI in your hands)。其背后的趋势是:开源高效模型 + 易用代理开发平台,为垂直领域AI代理的诞生提供了肥沃土壤。这也为大模型生态引入更多创新和竞争,促进整个Agent技术的成熟。
垂直行业专用 Agent:除了通用模型公司,许多领域也在开发专业的智能代理,以满足行业特定需求。例如在金融领域,一些 AI 代理可以连接实时行情和企业财务数据库,帮助分析海量金融数据、生成投资报告,甚至给出个性化的投资建议 (Applications of LLM Agents in various industries)。它们还能自动执行例行的合规审查、风险评估等任务,大幅提高运营效率 (Applications of LLM Agents in various industries)。又如在医疗领域,有医疗智库开发了医生助手Agent,能辅助医生检索最新医学文献、根据患者病历提供诊断支持 (Applications of LLM Agents in various industries)。它可以读取患者的症状描述和检查报告,然后查询知识库给出可能的诊疗方案建议。在法律行业,一些法律科技公司推出了法律Agent,可以快速查找相关案例法条、起草法律文件甚至为律师的辩论准备要点。大型律师事务所开始试用这类工具来提升工作效率。在客服服务领域,采用LLM的智能客服Agent已经相对成熟,不仅能回答FAQ,还能处理复杂问题、根据上下文调取用户历史进行个性化响应 (Applications of LLM Agents in various industries) (Applications of LLM Agents in various industries)。
总的来说,各垂直行业的专用Agent往往结合了领域知识图谱和行业数据,使其在专业任务上更加可靠。通用大模型提供“大脑”,行业数据赋予“场景知识”,再加上工具接口实现行动,这成为许多行业解决方案的典型架构。可以预见,随着LLM成本降低和定制手段增多,各行各业都会培育出自己的“AI代理”,就像如今几乎每个行业都有专用的软件系统一样。
以上大厂和新创主要是提供基于大模型的专用智能体构建平台,对于终端使用者,智能体构建的 agents 与传统 apps 没有不同,但内部的差异表现在:1. agents 是 LLM-native,就是说智能体apps,背靠大模型,天然具有语言能力,典型表现在自然语言的用户接口上; 2. 智能体平台开发的 agents 无需工程师编码,而是通过自然语言指令让大模型编程实现,这为 agents 的涌现创造了条件。
2025 年 Agent 发展趋势展望未来,LLM 驱动的智能代理技术在 2025 年及以后有几大值得期待的发展方向:
1. 多Agent协作与自治体系:目前大多数Agent还是单体在工作,而未来复杂任务可能需要多个智能体分工合作。
多Agent系统的理念是构建一个“AI团队”,让不同专长的Agent各司其职,通过通信协作完成单个Agent无法胜任的复杂目标 (Multi Agent LLM Systems: GenAI Special Forces) (Multi Agent LLM Systems: GenAI Special Forces)。例如,一个软件工程Agent团队可以包括架构设计Agent、编码Agent、测试Agent,它们相互交流检查,从而自动完成一整个软件项目。
多Agent协作也意味着需要一个调度或仲裁机制(如元代理或“首席Agent”)来分配任务、整合结果。研究者已在探索让一个主Agent对任务进行分解(Task Decomposition),并启动多个子Agent分别解决子问题,最后汇总答案的框架。这类似于人类的项目管理和团队合作,只不过执行者变成了一群AI。
同样的理念也可扩展到人机协作的混合团队中:未来办公室里也许人类同事和AI代理共同协作完成工作,各自发挥所长。实现多Agent协作需要解决Agent间通信协议、共享记忆和冲突解决等问题,但一旦成功,将显著提升AI系统处理复杂任务的规模和鲁棒性。正如有分析指出的,多智能体LLM系统有望像“梦之队”一样将各自专长结合,产生远超单一模型的效能 (Multi Agent LLM Systems: GenAI Special Forces) (Multi Agent LLM Systems: GenAI Special Forces)。
多智能体代理体系结构中,一组 Agents 通过共享记忆协同,在数字业务环境和物理环境中协作完成复杂目标 (The Anatomy of Agentic AI | International Institute for Analytics)。这种架构体现了未来Agent网络化的发展趋势:多个Agent既能各自独立感知、决策,又能通过共享记忆和消息传递实现协同工作,联手处理跨领域、跨环境的复杂任务。
2. 自主推理与决策能力提升:未来的Agent将在自主智能方面取得长足进展,包括更强的连贯推理、更可靠的决策和更少的人为干预需求。
我们预计LLM模型本身的能力还将持续提升,让模型拥有更接近人类专家的推理深度。同时,一系列辅助手段会进一步强化Agent的自主性和智能性:长短期记忆机制将更完善,避免上下文窗口限制带来的“健忘”问题,使Agent在长对话或长任务链中保持一致性;“自我反思 (self-reflection)”机制将成为Agent标配,让Agent学会自主检查和调整自己的思路,在遇到困难时懂得改进方法 (Introduction to LLM Agents | NVIDIA Technical Blog);还有研究者提出让Agent具备“内省”能力,即模型能对自己的回答进行不确定性评估,从而在不够自信时请求额外信息或帮助,而非给出错误答案。所有这些改进都指向让Agent变得更聪明、更可靠。到2025年,我们有望见到一些Agent在特定任务上达到并超越人类专家水平(例如复杂策略游戏AI、金融投资AI顾问等),因为它们可以不眠不休地优化自己的决策。
值得一提的是,如何让Agent的决策更“可解释”和“可控”也将是趋势之一。随着Agent变得更自主,人们会希望了解它是如何做出某个决定的,以及如何干预纠正。这将促进Agent系统在可解释AI、安全限制机制等方面的发展,确保自主智能在带来便利的同时不会偏离人类意图 (Building Effective AI Agents | Anthropic \ Anthropic) (Building Effective AI Agents | Anthropic \ Anthropic)。总而言之,更高的自主推理与决策力将推动Agent从“能用”进化到“好用”,应用范围和复杂度将大幅拓展。
3. 融合实体世界,虚实一体的智能代理:2025 年的另一个重要趋势是LLM Agent将从数字世界走向物理世界,与机器人等实体系统相结合,成为现实生活中的“智能体机器人”。
目前已经有科技公司在探索将大语言模型用于机器人控制,例如Google DeepMind开发了RT-2模型,将LLM知识用于机器人操作决策,让机器人可以根据人类自然语言指令执行一系列物理操作 (LLMs Meet Robotics: The Rise of AI-Driven Machines in 2024 | Entrepreneur) (LLMs Meet Robotics: The Rise of AI-Driven Machines in 2024 | Entrepreneur)。MIT的研究也提出了用语言描述代替视觉训练的方法,成功让机器人执行“把衣服拿去洗衣机”等多步操作 (Researchers use large language models to help robots navigate | MIT News | Massachusetts Institute of Technology) (Researchers use large language models to help robots navigate | MIT News | Massachusetts Institute of Technology)。这些进展表明,LLM代理有潜力成为通用机器人的大脑,大幅降低机器人对复杂环境的适应难度。
未来,配备LLM Agent的大型机器人可以在工厂、仓库中自主协作完成生产任务;服务型机器人可以听懂人类口头指令,灵活应对家庭中的杂务。甚至在自动驾驶、无人机等领域,语言模型代理也可用于高层决策规划,让交通AI能够理解人类乘客的需求和偏好。从虚拟走向现实也带来新的挑战,如物理世界的不可预测性、安全约束以及实时性要求等,需要在Agent中加入传感器数据处理、实时规划、容错等模块。然而,一旦突破这些障碍,“AI代理+机器人”将开启前所未有的应用场景。
可以想象,未来我们身边可能环绕着各种各样的智能代理:手机里的虚拟助理与家里的机器人管家相互通信,共同维护我们的数字和物理生活。可以说,物理世界的融合将使Agent从软件层面的助手,进化为拥有“身躯”和行动力的真正智能体。
结论综上所述,由大型语言模型驱动的智能代理正引领着新一轮的AI应用变革。从最初协助人类的Copilot,到如今初具自主性的Agent,我们看到了AI系统在自主决策、持续任务和多模态处理方面的长足进步。
时至 2025 年,相关技术组件如LLM、工具接口、多智能体架构等日趋成熟,已经为孕育“爆款”级别的Agent产品奠定了基础。可以预见,各行业将很快出现能够大幅提升生产力的AI代理,从而推动业务模式的革新与效率飞跃。当然,我们也应保持理性,关注Agent技术带来的新挑战,如可靠性、安全性和伦理风险,并在技术演进中逐步建立规范和治理。然而,展望未来,LLM生态与Agent技术的融合前景令人振奋——一个人机共生、多智能体协作的时代或将加速到来。正如业内分析所言,随着技术的演进,智能代理的应用范围几乎是“无限且不断扩张”的,人类将持续发现新的方式将其融入工作和生活 (Applications of LLM Agents in various industries)。我们有理由相信,LLM 驱动的 Agent 将在未来几年释放出更大的潜能,成为数字时代不可或缺的基础设施和创新源泉,值得所有AI技术爱好者和从业者持续关注和投入。
【相关】
转载本文请联系原作者获取授权,同时请注明本文来自李维科学网博客。
链接地址:https://wap.sciencenet.cn/blog-362400-1476565.html?mobile=1
收藏