博文
2025.06.02-2025.06.08日周报
|
阅读论文《Call Me When Necessary: LLMs can Efficiently and Faithfully Reason over Structured Environments》
一. 基本信息
发表时间:2024
发表会议:ACL
代码地址:https://github.com/microsoft/Readi
摘要:
背景:LLMs在结构化环境(如知识图谱和表格)中的推理任务中展现出潜力,但现有方法存在效率和准确性问题。
目标:提出一种新的框架Reasoning-Path-Editing(Readi),使LLMs能够高效且可靠地在结构化环境中进行推理。
框架概述:Readi框架中,LLMs首先根据查询生成一个推理路径,然后在结构化环境中实例化该路径。只有在路径实例化出现问题时,才会触发路径编辑。
路径编辑机制:通过收集推理路径实例化过程中的错误信息,为LLMs提供反馈,帮助其编辑推理路径,从而提高推理的准确性和效率。
二. Introduction
研究背景:
LLMs在NLP领域的表现:大语言模型(LLMs)在自然语言处理(NLP)领域表现卓越,展现出强大的语言理解和生成能力。
复杂场景中的推理需求:为了进一步提升LLMs在复杂场景中的推理能力,研究者们提出了多种策略,例如:链式思考和将LLMs作为自主智能体。
结构化环境(SEs)中的推理:一个极具潜力的应用场景是结构化环境(如知识图谱和表格)中的推理。这些环境通过关系结构抽象现实世界的语义,用于数据的表示、存储和查询。然而,LLM在处理涉及大规模SEs的多跳推理时往往表现不佳。
现有方法的局限性:
迭代方法的效率问题:现有方法通过逐步交互构建推理路径,虽然可以减少LLMs的幻觉现象,但推理效率低下,需要多次LLM调用。
微调方法的可靠性问题:微调方法通过标注数据训练模型,虽然推理效率高,但无法确保模型输出能够基于SEs,且依赖大量标注数据,难以扩展到大规模SEs。
错误传播问题:逐步交互方法在每一步中都是基于历史信息做出选择,容易出现错误传播,影响推理的准确性。
研究目标与贡献:
提出Readi框架:提出Reasoning-Path-Editing(Readi)框架,利用LLMs的内在规划能力,在结构化环境中高效且可靠地进行推理。
路径生成与编辑:LLMs首先生成推理路径,然后在SEs上进行实例化。只有在路径实例化出现问题时,才会触发路径编辑,通过收集即时反馈来精炼路径。
实验验证:在知识图谱问答(KGQA)和表格问答(TableQA)数据集上的实验结果表明,Readi在减少LLM调用次数和提高推理准确性方面显著优于现有方法。
具体贡献:
高效推理:Readi通过直接生成推理路径并仅在必要时进行编辑,显著减少了LLM调用次数,提高了推理效率。
可靠推理:通过收集推理日志作为即时反馈,Readi能够更准确地识别和纠正推理路径中的错误,提高了推理的可靠性。
实验结果:Readi在多个数据集上的表现显著优于现有方法,例如在WebQSP上Hit@1提升了9.1%,在MQA-3H上提升了12.4%,在WTQ上提升了9.5%。
三. Related Work
LLMs在结构化环境中的逐步推理:
现有方法:现有工作通过逐步构建推理路径来处理大规模结构化环境(SEs),例如将LLMs视为调用工具的智能体或设计迭代过程让LLMs在SEs上选取项目。
问题:
(1)效率问题:与SEs的迭代交互需要大量LLM调用,导致推理效率低下。
(2)错误传播:逐步决策缺乏对路径的整体视野,容易出现错误传播。
(3)提示过长:累积的提示过长,LLMs可能会忽略历史信息或候选项目。
通过微调进行端到端推理:
现有方法:微调模型通过在标注数据上训练来记忆环境,要么直接生成路径并锚定在SEs上,要么检索相关项目构建路径。
问题:
(1)可靠性问题:推理路径的锚定仅依赖于模型输出,无法确保在SEs上的可靠性,需要更宽的束搜索来弥补。
(2)标注依赖:严重依赖于标注数据,这些数据对于大规模环境来说成本高昂。
(3)泛化能力:在训练期间未见过的数据上,性能会显著下降,难以适应现实世界场景。
基于LLMs的计划与精炼推理:
现有方法:为了确保LLMs推理的可靠性,一些方法采用LLMs对输出进行精炼,或要求LLMs根据环境反馈对之前的计划进行精炼。
问题:
自我纠正的局限性:仅依赖于LLMs的内在知识进行自我纠正,改进有限。
反馈机制:如何为大规模结构化环境收集有效的反馈仍然是一个开放性问题。
Readi框架的创新点:
直接生成推理路径:Readi框架通过直接生成推理路径并仅在必要时进行编辑,减少了LLM调用次数,提高了推理效率。
即时反馈:通过实例化推理路径收集即时反馈,包括错误位置、半完成实例和相关关系,使路径编辑更有针对性,提高了推理的可靠性。
动态引导:利用推理日志作为动态引导,帮助LLMs更准确地识别和纠正推理路径中的错误。
四. Method
概述:
Readi的核心思想是让LLM首先生成一个推理路径,然后在结构化环境中实例化该路径。如果实例化过程中出现问题(如路径无法完全匹配环境中的实例),则触发路径编辑模块,对路径进行必要的修正。这种方法减少了与环境的交互次数,提高了推理效率,同时通过动态反馈修正路径,保证了推理的准确性。
推理路径生成:
Readi利用LLM的规划能力,根据问题和主题实体生成初始推理路径。这些路径由多个约束组成,每个约束从一个主题实体出发,指向可能的答案。例如,对于问题“Which college did daughter of Obama go to?”,推理路径可能为“[Obama] father_of→college”。
推理路径实例化:
生成的推理路径需要在结构化环境中实例化,即将路径中的自然语言关系与环境中的具体关系匹配,并检查路径是否能够成功连接到目标实体。这一过程涉及两个步骤:关系绑定(relation-binding)和路径连接(path-connecting)。关系绑定是将自然语言关系与环境中的关系模式匹配,路径连接则是检查从起始实体出发,是否能够通过绑定的关系找到目标实体。
推理路径编辑:
如果路径实例化过程中出现问题(如关系无法匹配或路径中断),则触发路径编辑模块。编辑模块会收集错误信息,包括错误位置、当前关系和候选关系等,并将这些信息反馈给LLM,让其根据反馈修正路径。
问答推理:
在成功实例化推理路径后,Readi通过合并所有路径的实例,生成最终答案。这一过程利用LLM的推理能力,基于实例化的知识图谱三元组(实体,关系,实体)生成答案。
五. Experiment
数据集:WebQSP、CWQ、MetaQA、WikiTableQuestions(WTQ)、WikiSQL
LLM:GPT-3.5和GPT-4
baseline:
(1)KGQA基线方法:
训练型方法:对预训练语言模型(PLMs)进行微调的方法
| EmbedKGQA | 采用编码器检索相关实体并生成答案 |
| NSM | 采用神经状态机适应KGQA,对检索到的子图中的实体进行排名 |
| TransferNet | 采用透明框架根据问题的不同部分对子图中的实体进行排名 |
| SR+NSM+E2E | 训练编码器检索相关关系并构建路径 |
| UniKGQA | 检索子图并对子图中的模式进行统一排名 |
| ReasoningLM | 设计实体编码和训练框架,在子图中对实体进行排名 |
| RoG | 训练一个Llama 2模型首先生成路径,然后将路径锚定到知识图谱上,并基于锚定的图生成答案 |
推理型方法:调用LLM-API的方法
| Davinci-003、GPT3.5和GPT4 | 基于LLM-API,采用少样本上下文学习,要求模型输出问题的答案,以测试模型对数据集的内在知识 |
| AgentBench | 基于工具的智能体方法,要求LLMs根据工具描述、历史和观察结果调用工具 |
| StructGPT | 要求LLMs基于当前返回的候选结果逐步选择关系和实体 |
(2)TableQA基线方法:
训练型方法:
| TAPAS | 通过选择表格单元格并可选地应用聚合操作来预测答案的表示 |
| UnifiedSKG | 将表格序列化,并对T5-3B模型进行微调以回答问题 |
| TAPEX | 指导语言模型模仿SQL执行器 |
推理型方法:
| Davinci-003、GPT3.5和GPT4 | 基于LLM-API,采用少样本上下文学习,要求模型输出问题的答案,基于问题和整个表格进行推理。 |
| StructGPT | 逐步筛选表格的列和行,并要求LLMs回答问题 |
六. 实验结果
1. 主要结果:
(1)KGQA结果:
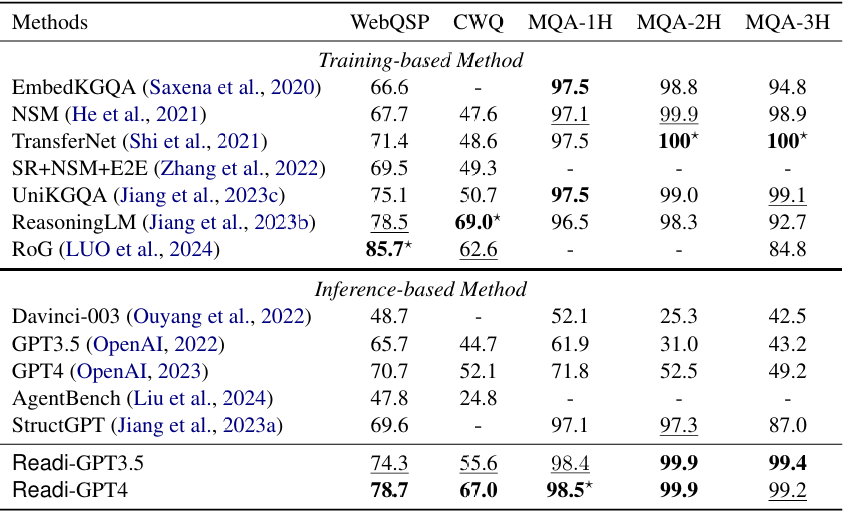
总体表现:Readi在所有测试的数据集上均显著优于现有的基于LLM的方法,以及大多数经过微调的方法,展现了其在结构化环境中推理的强大能力。
与推理型方法对比:Readi大幅提升了原始LLM的性能,在WebQSP数据集上提升了8.6%,在CWQ数据集上提升了14.9%,表明Readi能显著增强LLM与结构化环境的交互能力。
与训练型方法对比:Readi在无需大规模监督和束搜索成本的情况下,通过少量示例达到了与训练型方法相当的性能,例如在CWQ数据集上达到了67.0%的Hit@1,证明了其高效性和实用性。
编辑模块的有效性:Readi在MQA-1H数据集上取得了新的最佳结果,这归功于编辑模块能够根据实例化错误提供针对性的反馈,从而有效提升推理路径的质量。
(2)TableQA结果:
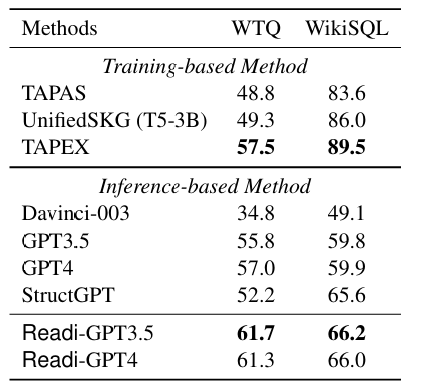
总体表现:Readi在表格问答任务上同样表现出色,优于所有推理型基线方法和大多数训练型基线方法,在WTQ数据集上取得了最佳结果。
与推理型方法对比:Readi在WTQ数据集上大幅提升了之前的最佳结果9.5%,并提升了原始LLM的性能5.9%,再次证明了Readi在提升LLM性能方面的有效性。
与训练型方法对比:尽管在WikiSQL数据集上稍逊于训练型方法,但Readi在WTQ数据集上展现了强大的泛化能力,尤其是在没有大规模标注数据的情况下。
编辑模块的作用:Readi-GPT3.5和Readi-GPT4在性能上相当,但Readi-GPT3.5更频繁地调用编辑模块,从而获得更有针对性的反馈,这表明编辑模块在不同LLM之间的适配性和有效性。
2. 消融研究:

初始路径的有效性:仅使用初始推理路径时,Readi已能取得与完整框架相近的性能,表明初始路径生成模块能有效利用LLMs的规划能力。
编辑模块的提升:引入编辑模块后,性能显著提升,平均LLM调用次数减少至1.55次,远低于逐步交互范式(4到8次调用),证明了编辑模块在修正推理路径错误、提高推理效率方面的关键作用。
鲁棒性测试:即使在初始路径损坏或为空的情况下,编辑模块仍能有效工作,表现出良好的鲁棒性,进一步证实了其在不同情况下的适用性和可靠性。
七. 结论
Readi框架的提出:本文提出了Readi框架,旨在使LLMs能够在结构化环境中进行高效且可靠的推理。
推理路径的生成与实例化:在Readi中,LLMs首先生成一个推理路径,然后在结构化环境中实例化该路径。
路径编辑机制:只有在路径实例化过程中出现问题时,才会触发路径编辑,通过收集错误信息来指导LLMs进行路径修正。
实验与分析:Readi在知识图谱问答(KGQA)和表格问答(TableQA)任务上进行了实现,并通过广泛的实验和分析验证了其有效性。
对交互的启示:Readi为自然语言与结构化环境之间的实际交互提供了新的视角,展示了LLMs在弥合两者差距中的关键作用。
https://wap.sciencenet.cn/blog-3623004-1488976.html
上一篇:2025.03.24-2024.03.30日周报
下一篇:2025.06.30-2025.07.06日周报