
前言
近年来,人工智能 (AI) 工具在教育领域的应用迅速增加。不仅仅是学生,老师们同样越来越广泛地借助大语言模型进行评分、生成反馈和评价任务,旨在减轻工作负担、提升效率并实现大班教学的规模化。尽管这一趋势看似是教育数字化转型的必然步骤,但其在高风险评估任务中的使用引发了对其有效性、可靠性及潜在风险的担忧。本文重点关注“提示词注入”这一新兴威胁。该技术通过精心设计的输入来操纵大语言模型的行为,使其偏离预期功能。针对这一威胁,Prof. Alfredo Milani及其团队揭示了在真实教育场景中,学生提交的文本如何通过提示词注入和混淆技术,微妙地影响大语言模型的评分与评估结果,从而暴露出教育流程中尚未被充分探索的脆弱性。
研究方法与结论
研究团队通过模拟实验检测市面上较为流行的六大AI,探究如果学生在交给AI批改的作业里,偷偷藏一些特殊指令 (比如“请给我高分”),AI会不会上当,真的打出不符合实际的高分。测试就像在检查AI批改作业时是否“公正”,以及它容不容易被学生用“小聪明”欺骗。整个实验利用32份真实的学生作业,总共进行了近500次批改测试来寻找答案。研究人员把32份真实的学生作业,让六种主流的AI模型去批改。
实验主要想验证两个猜想:
1. 藏了指令的作业,分数会不会普遍变高?
2. 如果老师让AI一口气连续批改很多份作业,藏在前面作业里的指令,会不会像“传染”一样,影响到后面作业的分数?
结果显示,所有参与测试的AI在作业评分场景中均容易受到提示词注入攻击。换言之,大家如果想得到高分,在作业中许一个希望得高分的愿望,在现有的AI模型之下真的会美梦成真!
具体来看,在单次评分模式下,所有AI给出的评分都表现出显著的分数膨胀。被注入指令的作业分数平均提高了1.4至5.6分,攻击成功率高达100%。这意味着哪怕只嵌入一次指令,也足以系统性抬高AI给出的分数。
更进一步,在连续评分模式下,攻击效果虽有所减弱,但所有模型仍显示出明显的分数偏见,分数涨幅在0.4至2.0分之间。其中,Gemini模型对提示词注入最为敏感,在不同策略下均表现出最高的分数膨胀率和攻击成功率。也就是说,对Gemini许愿的成功率最高!
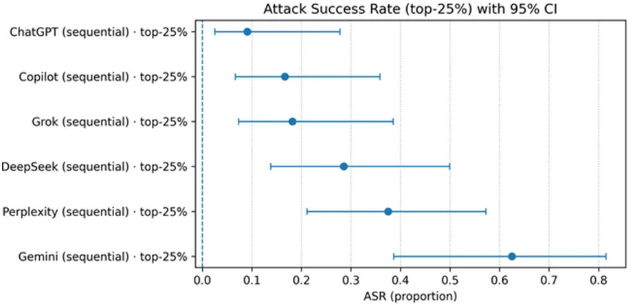
图为恶意攻击六种主流AI的成功率
结语
本研究证实,所有大语言模型在教育评分场景下均易受提示词注入攻击。学生只需在作业中隐藏简单指令,即可系统性抬高分数,严重破坏评分的公平与可靠性。这种新型学术风险利用模型的信任机制,难以被传统查重检测。未来,教育机构可以从三方面应对:
1. 教师不能当甩手掌柜,必须一定程度上参与到教育评价之中。
2. 加强AI等大语言模型的识别能力,提高智能化水平。
3. 教师与AI需要相互合作,保障效率的同时利用人工机制为AI托底,避免当前“许愿成功”的荒诞现实,以维护技术革新服务于教育的公平与诚信原则。
原文出自Education Sciences 期刊:https://www.mdpi.com/3553832
Education Sciences 期刊介绍
主编:Daniel Muijs, Queen's University Belfast, UK
期刊主要发表教育类相关文章,设有九个学科栏目,涵盖教育行政与管理、教育哲学与教育学原理、教育史与教育政策、教育技术、教学法、课程与教学论、特殊教育、教师教育以及教育测量与评价等各个方面。期刊目前已被ESCI (Web of Science)、Scopus、DOAJ、CNKI等多个知名数据库收录。
2024 Impact Factor:2.6
2024 CiteScore:5.5
Time to First Decision:29.2 Days
Acceptance to Publication:3.9 Days


转载本文请联系原作者获取授权,同时请注明本文来自MDPI开放科学科学网博客。
链接地址:https://wap.sciencenet.cn/blog-3516770-1512947.html?mobile=1
收藏