
aBIOTECH | 阮珏团队开发跨文件数据筛选工具Filterx

在生物信息学分析中,处理多个文件的数据并根据数据出现的次数或频率进行筛选是一项常见任务。例如在植物群体遗传学或肿瘤研究中,可能需要从多个VCF文件中筛选出80%样本支持的变异位点,或仅提取在父系中出现的k-mer序列。然而,现有工具通常只能处理单个文件,难以应对多文件间的数据匹配与过滤需求,且内存占用较高,严重影响研究人员的分析效率。
近日,中国农业科学院农业基因组研究所阮珏团队在aBIOTECH 发表了题为“Efficient data filtering with multiple group conditions: A command tool for bioinformatics data analysis” 的论文,介绍了一款名为Filterx的命令行工具。该工具能够高效地在多文件间匹配和筛选数据,并简化了跨文件数据筛选的流程。
Filterx采用流式处理方式,从多个有序的类表格文件中读取数据,并根据用户自定义的规则(如数据出现的文件个数或频率)实时进行匹配,最终输出符合条件的数据(图1)。该工具设计了一套易于使用的命令行规则,支持为每个文件指定相应的列以完成匹配。它不仅能够处理同类型文件的多文件数据,还支持跨不同类型文件的数据处理。用户无需编写代码,Filterx即可在低内存占用下快速实现多文件间的数据匹配与过滤操作。此外,该工具集成了zlib库,支持读取gzip格式的压缩文件。Filterx采用C语言开发,兼容Windows、Linux和MacOS操作系统。详细的软件使用文档和使用案例可参考:https://github.com/dwpeng/filterx-c。
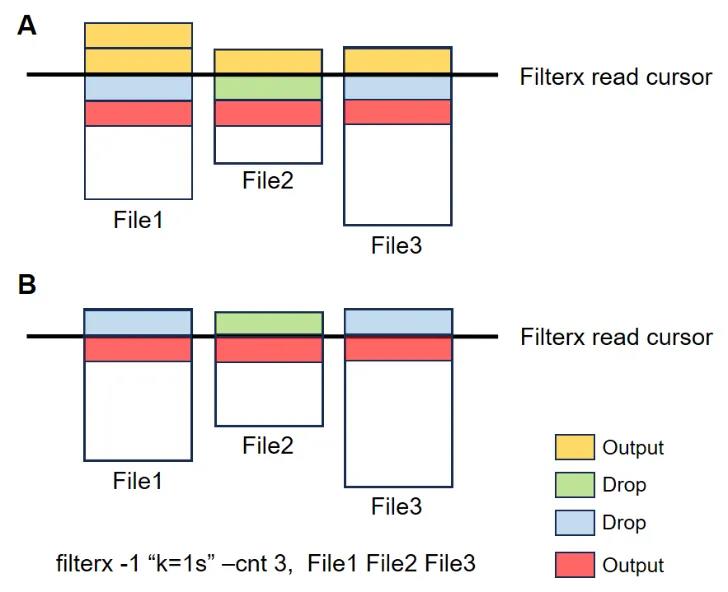
图1 filterx处理流程图
中国农业科学院农业基因组研究所阮珏研究员为该论文通讯作者。基因组所与华中农业大学联培硕士生邓文鹏为该论文第一作者,基因组所科研助理李阿伦、基因组所与爱尔兰都柏林大学联培博士生常建业,云南省烟草农业科学研究院谢贺副研究员参与了该研究工作。该研究获得中国烟草总公司科技计划项目资助。
引用本文:
Deng, W., Chang, J., Li, A. et al. Efficient data filtering with multiple group conditions: a command tool for bioinformatics data analysis. aBIOTECH (2025). https://doi.org/10.1007/s42994-025-00207-6
相关阅读:
aBIOTECH | 中国农科院作科所开发无监督的深度学习算法对植物单细胞RNA测序数据进行聚类
aBIOTECH | 李慧慧团队利用大规模进化信息和机器学习算法成功预测植物盐胁迫相关基因
aBIOTECH | 刘羽飞团队基于高光谱与深度学习技术实现水稻恶苗病早期高效监测
aBIOTECH封面文章 | 刘羽飞课题组联合王蒙岑课题组综述利用先进技术在不同观测尺度上预测水稻病害的现状与展望
aBIOTECH | 高俊祥团队开发拟南芥和水稻组织特异性regulon的推断与排序方法
aBIOTECH | 屠焰/马涛团队通过优化Kraken2工具提高微生物物种分类性能
转载本文请联系原作者获取授权,同时请注明本文来自李楠科学网博客。
链接地址:https://wap.sciencenet.cn/blog-3458049-1479675.html?mobile=1
收藏