
该脚本已上线密码子学院平台,链接:【脚本】:批量下载fasta文件和gbk文件
GenBank数据库是在科研工作中经常用到的数据库之一,它由美国国家生物技术信息中心(the National Center for Biotechnology Information,NCBI)建立和维护。该数据库包含了所有已知的核酸序列和蛋白质序列,以及与它们相关的文献著作和生物学注释。
对于经常要从GenBank数据库中下载物种的基因组fasta文件和gbk文件的研究者来说,在刚刚入门生信时,往往习惯于使用浏览器一条一条进行下载,这样的方法面对少量的序列或许还可以执行,但如果面对成百上千条序列就成了“灾难”。
所以如何批量下载fasta文件和gbk文件呢?我们在Biopython模块下发现了可以实现该功能的子模块,并将其打包成了一键化脚本,大家一起来学习一下吧!
一、脚本运行环境
• 安装python解释器:安装教程
• 安装biopython模块
# 使用pip安装pip install biopython # 使用conda安装conda install -c bioconda biopython
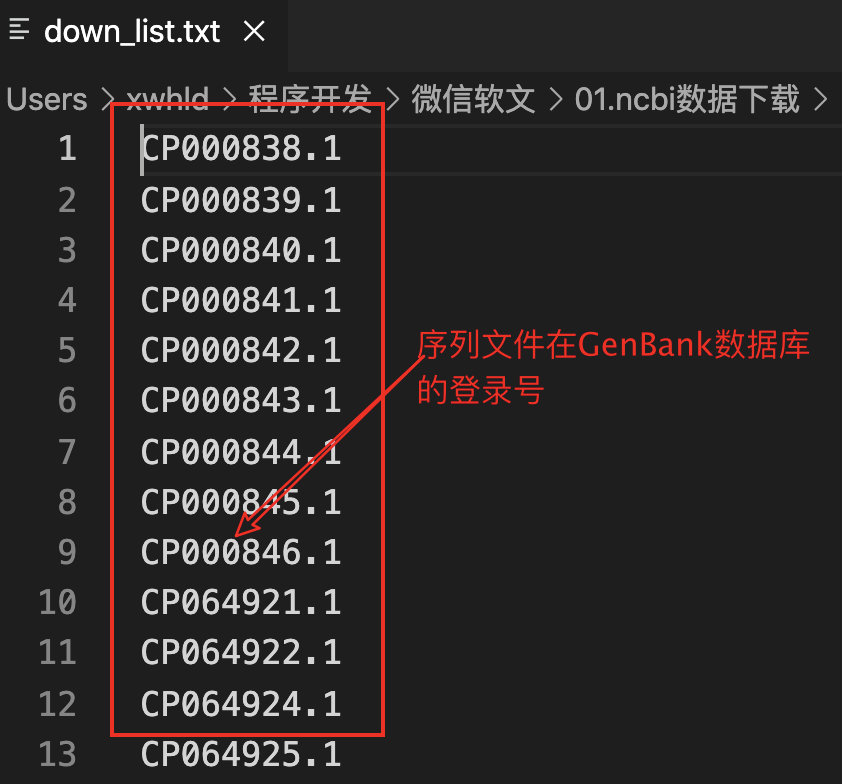
二、准备list文件
二、查看脚本参数
python GenBank_download.py -h

三、实战演练
# 下载序列fasta文件python GenBank_download.py -f fasta -a down_list.txt# 下载序列gbk文件python GenBank_download.py -f gb -a down_list.txt
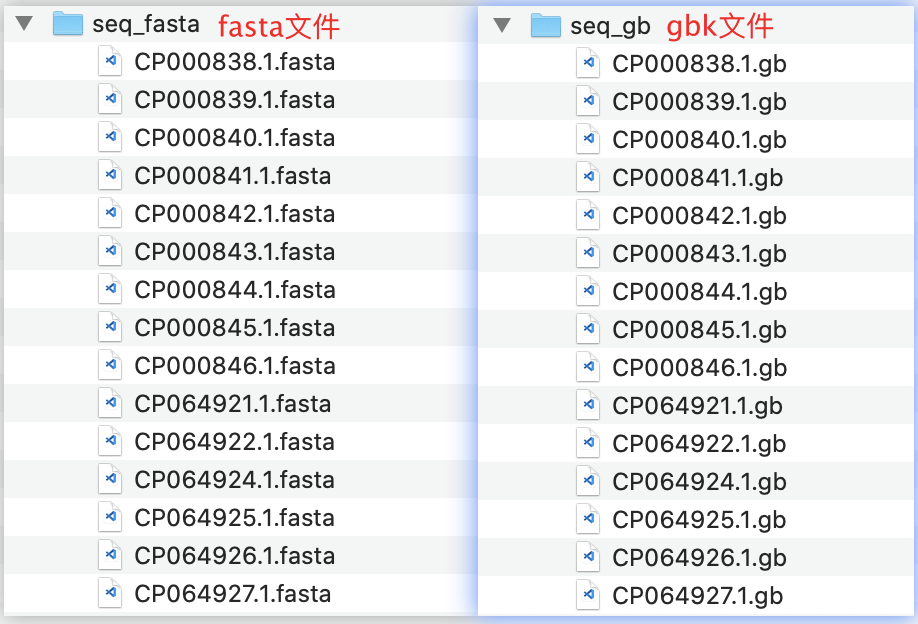
四、结果展示
五、注意事项
01 脚本需要依赖于Biopython模块,请提前安装,否则脚本无法运行。
02 脚本只能下载序列的fasta文件和gbk文件,如原核生物基因组fasta文件,无法下载gbk文件中的蛋白序列和CDS序列。
03 对于基因组较大的真核生物,如人基因组,gbk文件有多个染色体组成,不包含基因组fasta文件,这样的序列号无法下载基因组fasta文件。
04 脚本下载序列的gbk文件和fasta文件等同于浏览器下载的gbk文件和fasta文件。
转载本文请联系原作者获取授权,同时请注明本文来自牛祥娜科学网博客。
链接地址:https://wap.sciencenet.cn/blog-3447233-1481383.html?mobile=1
收藏