
引用本文
祁晓博, 陈佳明, 史颖, 亓慧, 郭虎升, 王文剑. 基于主动−被动增量集成的概念漂移适应方法. 自动化学报, 2025, 51(5): 1131−1144 doi: 10.16383/j.aas.c240503
Qi Xiao-Bo, Chen Jia-Ming, Shi Ying, Qi Hui, Guo Hu-Sheng, Wang Wen-Jian. Concept drift adaptive method based on active-passive incremental ensemble. Acta Automatica Sinica, 2025, 51(5): 1131−1144 doi: 10.16383/j.aas.c240503
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c240503
关键词
概念漂移,数据流分类,增量学习,在线集成
摘要
数据流是一组随时间连续到来的数据序列, 在数据流不断产生的过程中, 由于各种因素的影响, 数据分布随时间推移可能以不可预测的方式发生变化, 这种现象称为概念漂移. 在漂移发生后, 当前模型需要及时响应数据流中的实时分布变化, 并有效处理不同类型的概念漂移, 从而避免模型泛化性能下降. 针对这一问题, 提出一种基于主动–被动增量集成的概念漂移适应方法(CDAM-APIE). 该方法首先使用在线增量集成策略构建被动集成模型, 对新样本进行实时预测以动态更新基模型权重, 有利于快速响应数据分布的瞬时变化, 并增强模型适应概念漂移的能力. 在此基础上, 利用增量学习和概念漂移检测技术构建主动基模型, 提升模型在平稳数据流状态下的鲁棒性和漂移后的泛化性能. 实验结果表明, CDAM-APIE能够对概念漂移做出及时响应, 同时有效提高模型的泛化性能.
文章导读
大数据时代, 数据流在医疗诊断、欺诈监测、气象预测等多个领域大量涌现[1−3]. 相较于传统的静态数据, 数据流通常以流的形式按时间顺序依次到达, 具有时序性、动态性、无限性、不可重现性等特点[4−6]. 数据流挖掘研究是为使在线学习模型更好地应对实时数据流中的动态变化, 提高模型的适应性和泛化性能[7]. 概念漂移是数据流挖掘中常见的一种现象, 其典型特征是样本的输入特征和输出标签之间的关系会随时间发生不可预见的变化[8−11].
概念漂移会使基于历史数据训练的学习模型难以适应当前的实时数据变化[12−13]. 例如在信用卡欺诈检测中, 欺诈者更新一些伪装技术, 使欺诈特征随时间推移发生变化, 导致过去归为正常的交易记录可能在未来变成欺诈交易[14]; 在气象预测中, 相似的气温、压强、空气湿度等因素可能随季节变化造成不同的天气状况, 若模型更新不及时, 就会使当前的天气预测情况发生滞后[15]. 在工业生产及故障诊断领域, 工况或环境变化可能导致故障特征改变. 若故障诊断模型未能实时更新, 误诊和漏诊问题随时间累积, 可能引发生产中断、经济损失等问题. 因此, 在数据流挖掘中, 提高学习模型对概念漂移的适应能力, 维持其在数据变化下的准确性和有效性, 对于实际应用具有重要意义.
目前, 处理概念漂移数据流的方法大致分为主动检测方法和被动适应方法两类[16]. 主动检测方法通过监测模型的性能表现或数据变化判断概念漂移, 能够及时发现数据分布的变化, 迅速做出响应以保持模型的准确性, 但是可能会错误地将随机波动识别为概念漂移, 导致不必要的模型调整; 被动适应方法通过对模型的不断调整来适应概念漂移, 即使在数据分布缓慢变化的情况下也能保持较好的性能, 但可能会忽略重要信息, 并且鲁棒性较差. 集成学习是常用的被动适应方法, 通过特定的结合策略, 将基于不同时序数据的多个基模型集成为一个泛化能力更强、性能更优的模型, 并通过灵活的指标调整以有效适应概念漂移[17−18]. 然而, 现有集成方法大多只能解决某一类型的概念漂移, 泛化能力不强, 对其他类型的概念漂移效果较差. 并且由于替换策略, 过拟合的基模型可能会替换掉泛化性能较好的基模型, 从而导致模型不稳定. 此外, 在概念漂移刚发生时, 集成模型中存在较多携带历史数据的基模型, 使模型难以迅速适应概念漂移.
为应对上述问题, 本文提出一种基于主动−被动增量集成的概念漂移适应方法(Concept drift adaptation method based on active-passive incremental ensemble, CDAM-APIE). 该方法采用在线增量集成策略和漂移检测方法, 构建被动集成模型和主动基模型. 被动集成模型通过对数据块中的单一训练样本进行预测并动态调整基模型权重, 有利于对数据分布变化进行快速响应. 同时, 利用增量学习和概念漂移检测技术构建主动基模型, 提升模型在平稳数据流状态下的鲁棒性和漂移以后的泛化性能. 本文的主要贡献如下:
1)通过实时调整权值、周期性更新模型, 提高模型适应不同类型概念漂移的能力;
2)主动方法与被动方法相结合, 提高模型对概念漂移的适应能力和泛化性能;
3)使用增量学习方法, 缓解数据块大小对基模型性能的影响, 提高基模型的稳定性.
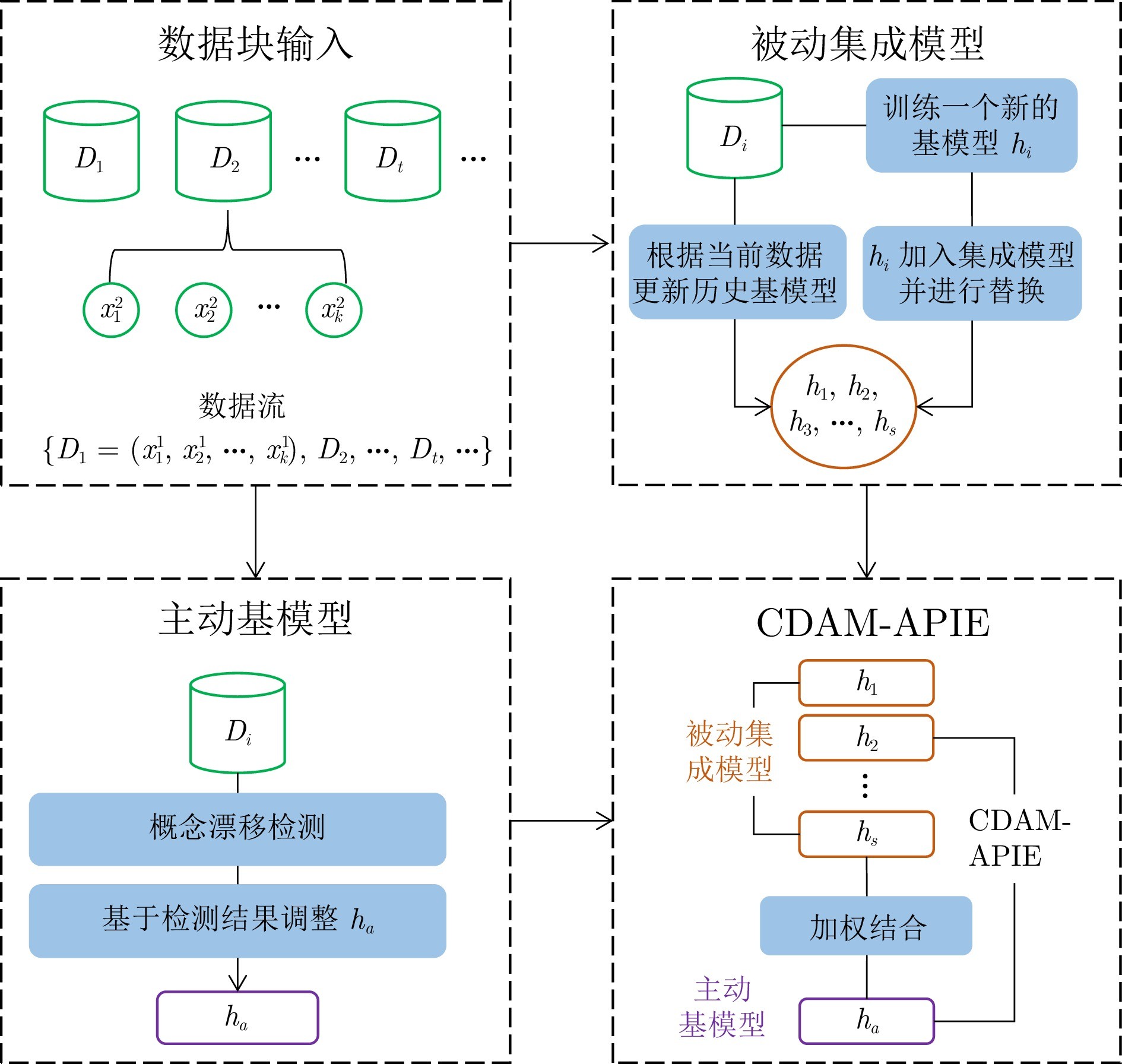
图 1 CDAM-APIE整体框架
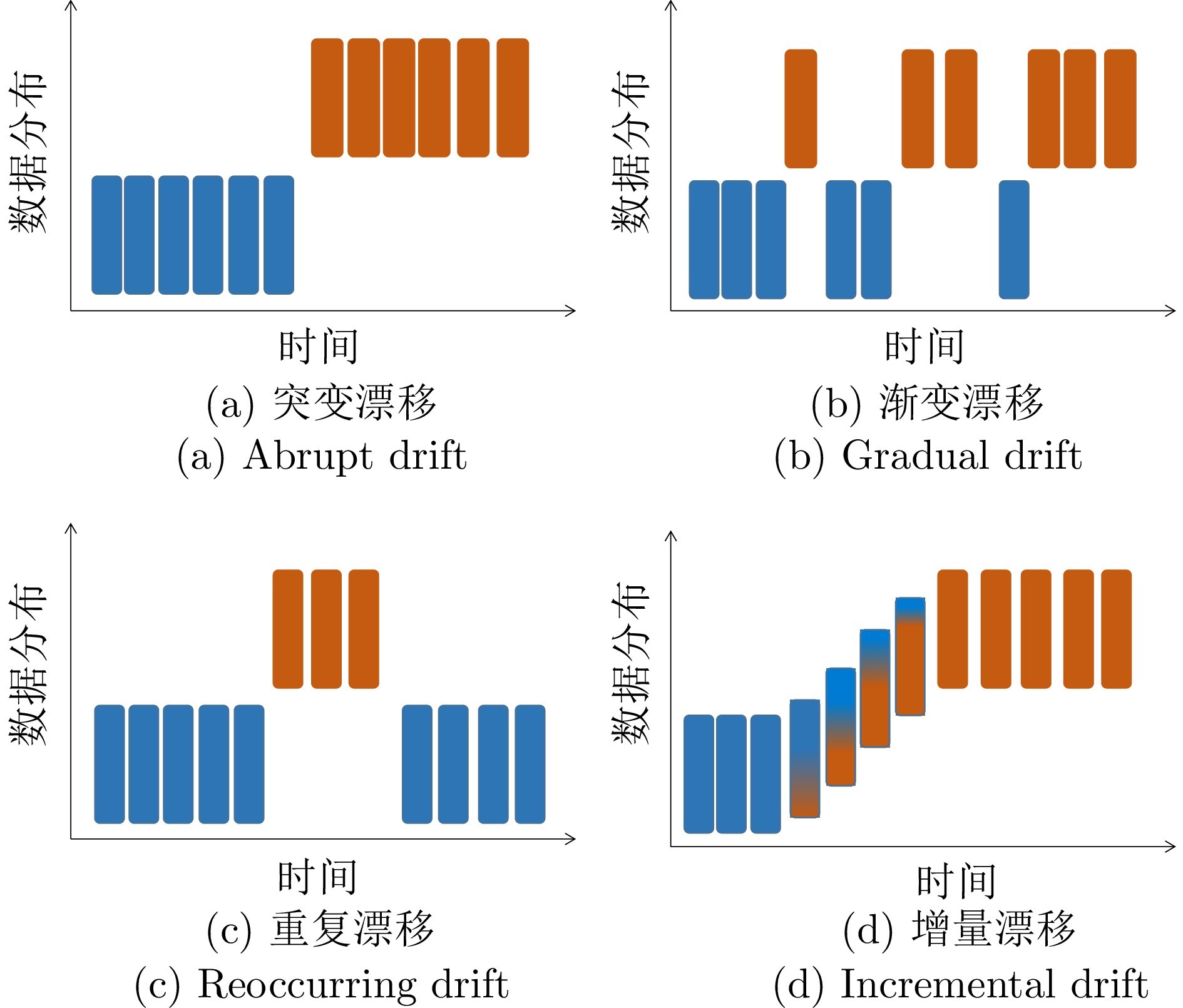
图 2 四种类型的概念漂移
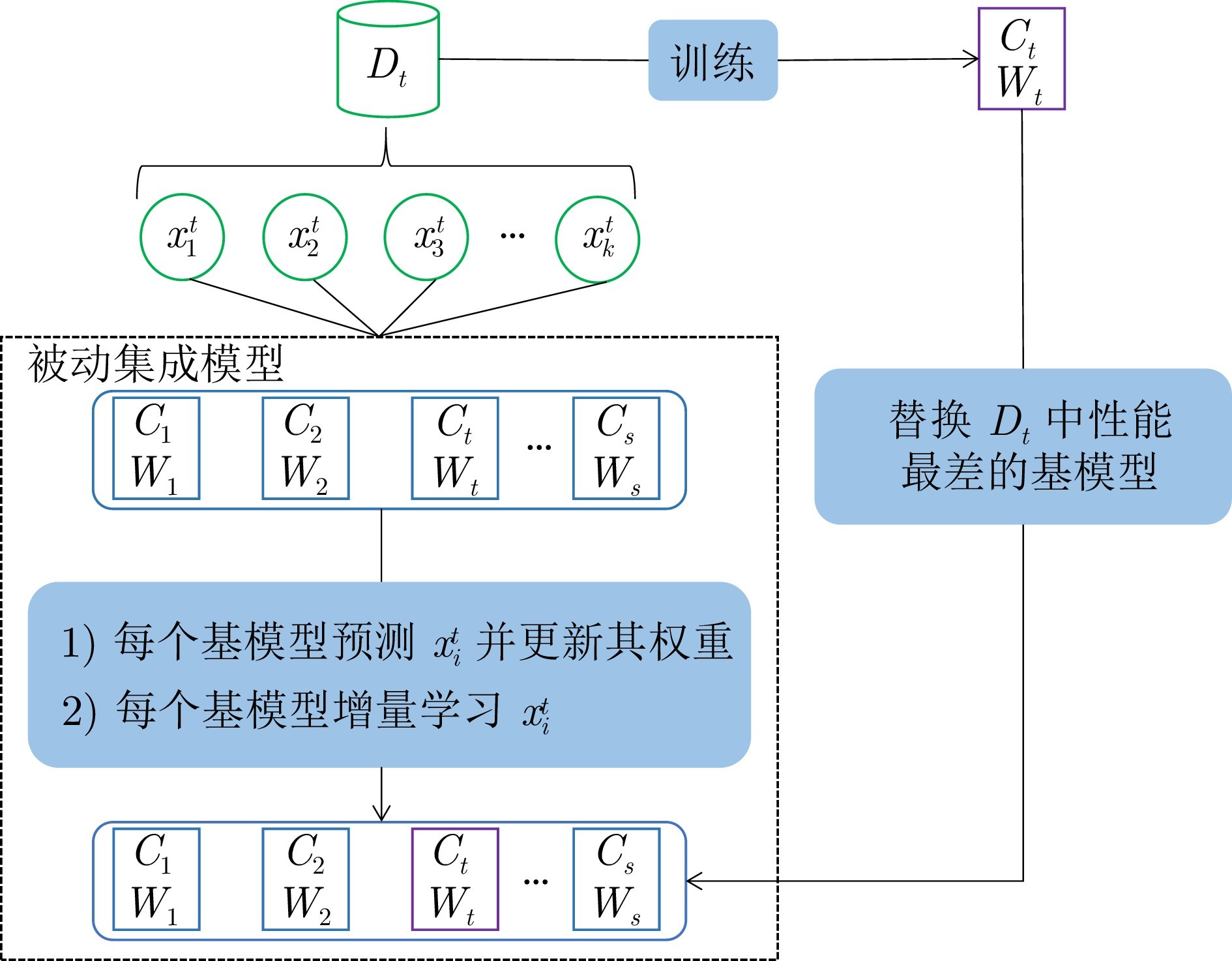
图 3 被动集成模型的过程
现有方法通常只能对某种特定类型的概念漂移做出有效应对, 且无法及时响应数据流, 为此本文提出CDAM-APIE方法. 该方法首先结合基于块和单样本集成方法的优势, 能够更好地适应不同类型的概念漂移; 其次将被动和主动方法进行动态加权结合, 提高模型的泛化性能和适应能力. 此外, 增量学习用于缓解数据块大小对基模型性能的影响, 提高模型的鲁棒性. 实验结果表明, CDAM-APIE通过动态加权的方式调节两个模块, 充分利用两个模块在不同数据集上的优势, 使模型在平稳状态下保持较高性能并在数据流发生概念漂移后也能快速适应新的数据分布, 对多种类型的概念漂移都具有较好的效果. 然而, 数据流中通常还伴随着数据不平衡等问题, 我们计划未来对含有概念漂移的非平衡数据流继续进行更进一步的尝试.
作者简介
祁晓博
太原师范学院计算机科学与技术学院副教授. 主要研究方向为数据挖掘与机器学习. E-mail: xbqi@tynu.edu.cn
陈佳明
太原师范学院计算机科学与技术学院硕士研究生. 主要研究方向为数据挖掘与机器学习. E-mail: 20222551035@stu.tynu.edu.cn
史颖
山西大学计算机与信息技术学院博士研究生. 主要研究方向为图像处理与机器学习. E-mail: sy@tynu.edu.cn
亓慧
太原师范学院计算机科学与技术学院教授. 主要研究方向为数据挖掘与机器学习. E-mail: qihui@tynu.edu.cn
郭虎升
山西大学计算机与信息技术学院教授. 主要研究方向为数据挖掘与计算智能. E-mail: guohusheng@sxu.edu.cn
王文剑
山西大学计算智能与中文信息处理教育部重点实验室教授. 主要研究方向为数据挖掘与机器学习. 本文通信作者. E-mail: wjwang@sxu.edu.cn
转载本文请联系原作者获取授权,同时请注明本文来自Ouariel科学网博客。
链接地址:https://wap.sciencenet.cn/blog-3291369-1492343.html?mobile=1
收藏