博文
提示学习在计算机视觉中的分类、应用及展望
|
引用本文
刘袁缘, 刘树阳, 刘云娇, 袁雨晨, 唐厂, 罗威. 提示学习在计算机视觉中的分类、应用及展望. 自动化学报, 2025, 51(5): 1021−1040 doi: 10.16383/j.aas.c240177
Liu Yuan-Yuan, Liu Shu-Yang, Liu Yun-Jiao, Yuan Yu-Chen, Tang Chang, Luo Wei. The classification, applications, and prospects of prompt learning in computer vision. Acta Automatica Sinica, 2025, 51(5): 1021−1040 doi: 10.16383/j.aas.c240177
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c240177
关键词
计算机视觉,提示学习,视觉−语言大模型,预训练模型
摘要
随着计算机视觉(CV)的快速发展, 人们对于提高视觉任务的性能和泛化能力的需求不断增长, 导致模型的复杂度与对各种资源的需求进一步提高. 提示学习(PL)作为一种能有效地提升模型性能和泛化能力、重用预训练模型和降低计算量的方法, 在一系列下游视觉任务中受到广泛的关注与研究. 然而, 现有的PL综述缺乏对PL方法全面的分类和讨论, 也缺乏对现有实验结果进行深入的研究以评估现有方法的优缺点. 因此, 本文对PL在CV领域的分类、应用和性能进行全面的概述. 首先, 介绍PL的研究背景和定义, 并简要回顾CV领域中PL研究的最新进展. 其次, 对目前CV领域中的PL方法进行分类, 包括文本提示、视觉提示和视觉−语言联合提示, 对每类PL方法进行详细阐述并探讨其优缺点. 接着, 综述PL在十个常见下游视觉任务中的最新进展. 此外, 提供三个CV应用的实验结果并进行总结和分析, 全面讨论不同PL方法在CV领域的表现. 最后, 基于上述讨论对PL在CV领域面临的挑战和机遇进行分析, 为进一步推动PL在CV领域的发展提供前瞻性的思考.
文章导读
近年来, 自然语言处理(Natural language processing, NLP)领域普遍采用“预训练+微调”的学习范式, 在多个NLP应用任务上取得不错的效果. 该范式首先在大规模数据上进行大语言模型(Large language model, LLM)的预训练, 然后在基于特定任务的数据集上进行微调. 随着LLM不断发展, 其参数量和对计算资源的需求也呈现出急剧上升的趋势. 以GPT系列模型为例, 从GPT-1 到GPT-3 的演进中, 其参数量从 1.17 亿激增至 1750 亿, 同时也带来性能的显著飞跃[1]. 此外, 自 2023 年以来, 一系列LLMs被推出, 模型的参数规模也越来越大, 如谷歌的PaLM 2 (参数量 3400 亿)、英伟达的Nemotron-4 (参数量 3400 亿)、X.AI的Grok-1 (参数量 3140 亿)及华为的PanGu-Σ (参数量 10850 亿)[2]. 然而, 这种趋势给“预训练+微调”的学习范式带来巨大的挑战. 首先, 巨大的参数规模使得微调更新预训练模型的所有参数以适应特定的下游任务变得越来越难; 其次, 预训练与下游任务之间存在的域差异性导致大模型难以很好地迁移到其他任务[3].
为解决这些挑战, 一种新的学习范式——提示学习(Prompt learning, PL)被提出, 即“预训练+提示+预测”[4]. 在NLP领域中, PL通过在训练样本中添加若干辅助信息, 如精心设计的自然语言, 来帮助预训练大模型适应于特定的下游目标任务. 此过程中, 预训练模型的参数保持冻结, 特定任务所需的标记数据和计算资源需求大大降低. 例如, OpenAI发布的ChatGPT, 在无需额外微调的情况下, 只需学习简单的文本提示就能在各种下游任务中表现出卓越的语言理解、处理和生成能力. PL在NLP领域的巨大成功, 吸引了越来越多计算机视觉(Computer vision, CV)研究人员的关注和研究.
与NLP领域类似, CV领域的迅猛发展也在很大程度上得益于视觉和多模态基础大模型的发展, 而这些大模型所面临的微调挑战同样显著. 例如, DINOv2[5]是一个在 1.42 亿张图片上自监督训练的视觉基础模型, 具有超过 10 亿个参数; LVM[1]是一个具有最高达 30 亿参数的视觉基础模型. 多模态大模型Yi-VL使用约一百万个图像−文本对来训练最多 340 亿参数, 在多模态理解与生成任务中表现卓越. 表1展示了近年来视觉和多模态大模型的发展及其参数量的变化趋势. 可见, 在CV领域, 预训练基础模型也朝着越来越大的方向发展, 而高维的图像和视频数据使得微调这些模型的难度也越来越大. 因此, 如何利用PL以提升这些基础大模型在不同CV任务上的性能和泛化能力, 降低对标记数据和计算资源的需求成为当前CV领域研究的重点. 最近, 已有工作将PL成功应用在CV领域, 并验证了其可行性. 如CLIP[6] (Contrastive language-image pretraining)通过精心设计的文本提示, 不仅在图像分类上表现出色, 还成功应用于多种下游任务中. SAM[7] (Segment anything model)通过文本或视觉提示能够在无需额外训练的情况下, 灵活执行各种图像分割任务. 随着PL在CV领域研究的继续深入, 更多创新性的PL方法将会涌现, 并不断提升不同下游任务的性能, 推动CV领域的发展.
为深入探索PL在不同CV任务中的工作原理, 廖宁等[8]对近年的视觉PL进行了综述, 讨论在单模态视觉模型和多模态视觉−语言模型中的提示方法及应用. 不同于他们将PL方法按照应用模型进行分类, 本文进一步分析不同的PL方法本身的模态性质, 将它们分为文本提示、视觉提示和视觉−语言联合提示三个类别. 此外, 本文还在CV的多个应用领域讨论不同的PL方法, 并在三个广泛应用的CV任务上进行结果分析, 充分论证不同PL方法的优缺点. 本文对PL在CV领域的研究和应用进行系统全面的综述. 首先对CV领域的发展现状及问题进行论述, 而后分析引入PL方法的优势并给出其正式定义. 其次, 按照不同的模态对现有PL方法进行分类总结, 并对每种提示方法的原理和优缺点进行分析. 然后梳理CV常见下游任务中PL的典型应用, 如图1所示, 对各种下游任务中的PL方法进行分类分析. 接着收集多个代表性PL方法和非PL方法在具体视觉任务中的实验数据, 并进行详细的对比和分析. 最后探讨当前PL在CV任务中存在的挑战和潜在的研究方向.
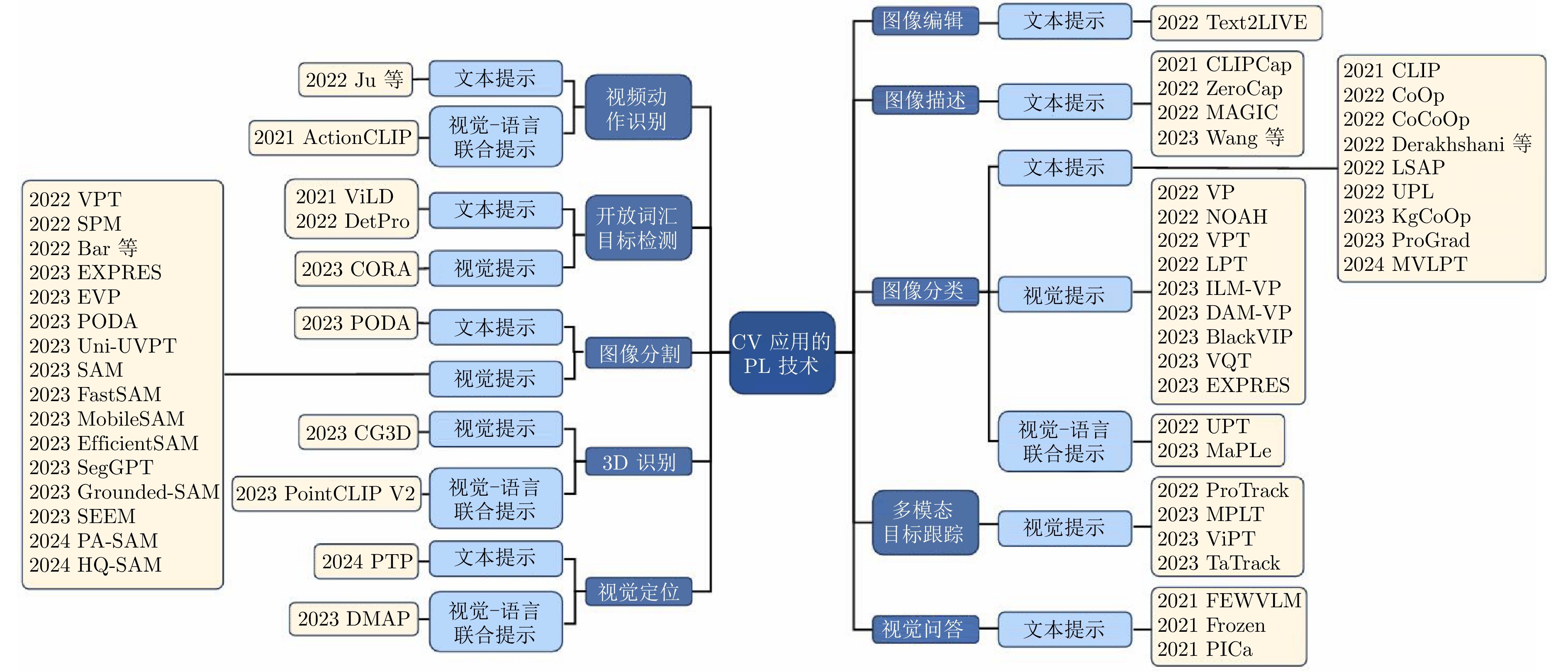
图 1 基于PL的CV应用概述
与同类文献相比, 本文的主要贡献如下: 1)提供一个PL在CV领域应用的全面系统的综述, 对PL的发展过程、基本原理、作用机制进行详细探讨. 根据不同的输入模态, 将现有文献中的PL方法分类为文本提示、视觉提示和视觉−语言联合提示, 并分别讨论它们的基本原理和优缺点. 此外, 本文系统地讨论PL在CV领域下游任务中的典型应用, 根据提示类型阐述不同PL方法在具体下游任务中的作用机制. 2)针对多个CV下游任务进行实验数据的收集和定量分析, 对比代表性PL方法与非PL方法之间的性能差异以及需训练的参数量的差异, 从量化的角度探讨PL方法的优异性. 3)基于CV领域PL方法的基本原理讨论现有PL方法和发展现状, 详细讨论现有PL方法应用于CV任务时面临的挑战和机遇, 对PL方法在CV领域的未来发展提供一些见解, 为未来探索新颖的PL方法以及进一步促进不同类型的PL方法的交互与融合提供指引.

图 2 NLP中的提示流程
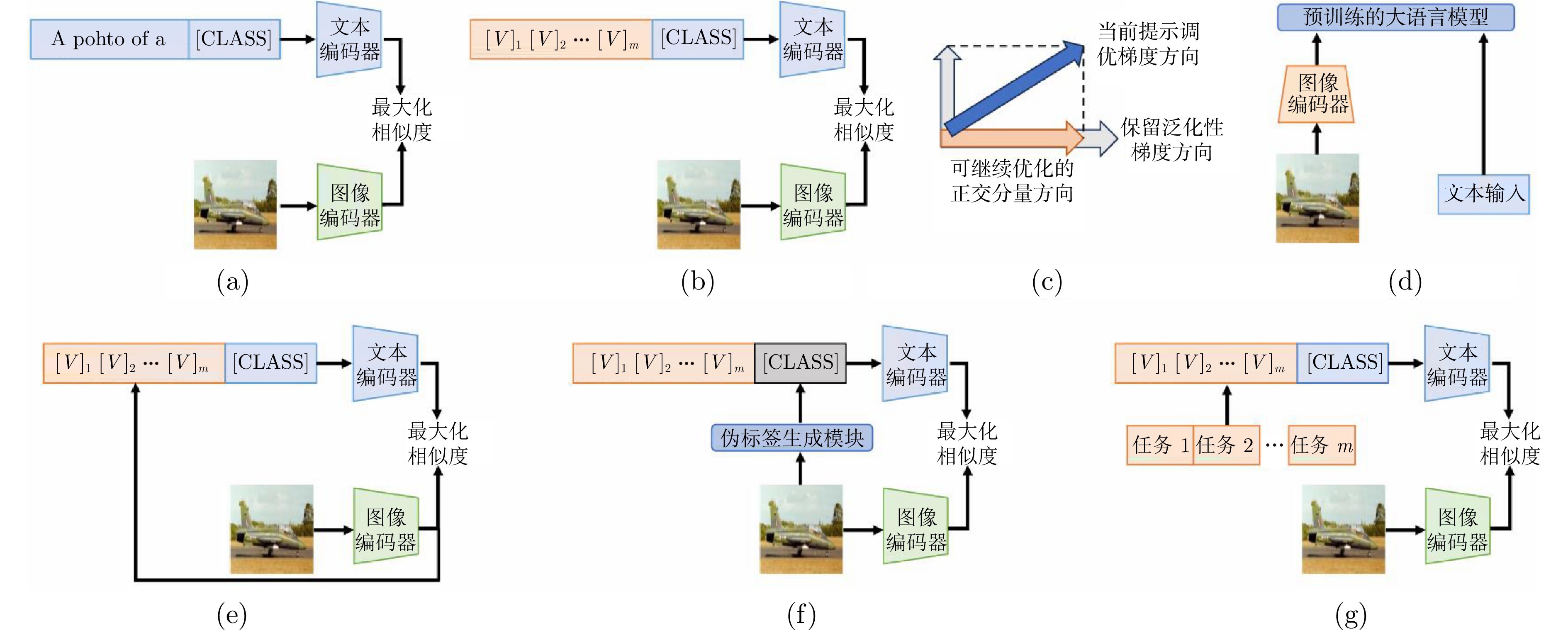
图 3 文本提示((a)基于手工设计的文本提示; (b)连续提示; (c)基于梯度引导的文本提示; (d)基于视觉映射到语言空间的提示; (e)基于图像引导的文本提示; (f)基于伪标签的文本提示; (g)基于多任务的文本提示)
传统的“预训练+微调”范式存在对计算资源和标签数据需求高、计算难度大的问题, 尤其是随着模型规模和复杂度的提高, 这些问题变得更加严峻. PL作为一种能有效替代微调的方法, 对于提升模型性能和泛化能力、重用预训练模型以及降低计算量起到了关键作用. 因此, 本文首先对PL的发展历程进行梳理, 并总结分析在CV领域中不同类型提示方法的原理和优缺点. 随后, 针对不同的视觉任务, 按照提示类型对经典的PL方法进行总结. 在实验部分, 进一步对代表性的PL方法和非PL方法进行实验对比和分析, 验证PL方法在提升模型准确率和泛化性方面的优势. 最后, 基于上述分析, 总结现有PL方法在CV领域存在的挑战, 并对PL的未来发展方向提出一些见解. 相信本文能够帮助研究人员全面深入地了解PL方法在CV任务中的工作机制, 为推动PL方法在CV领域的进一步发展提供参考.
作者简介
刘袁缘
中国地质大学(武汉)计算机学院副教授. 主要研究方向为计算机视觉. E-mail: liuyy@cug.edu.cn
刘树阳
中国地质大学(武汉)计算机学院硕士研究生. 主要研究方向为人脸情感识别. E-mail: 20171003670@cug.edu.cn
刘云娇
中国地质大学(武汉)计算机学院硕士研究生. 主要研究方向为遥感图像分割. E-mail: luyunjiao@cug.edu.cn
袁雨晨
中国地质大学(武汉)计算机学院硕士研究生. 主要研究方向为聚类分析. E-mail: 1202321648@cug.edu.cn
唐厂
中国地质大学(武汉)计算机学院教授. 主要研究方向为多视图学习. E-mail: tangchang@cug.edu.cn
罗威
中国舰船研究设计中心高级工程师. 主要研究方向为舰船人工智能. 本文通信作者. E-mail: csddc_weiluo@163.com
https://wap.sciencenet.cn/blog-3291369-1489752.html
上一篇:好文分享│IEEE Fellow、东南大学曹进德教授及其合作团队成果
下一篇:SignBrain: 无线可穿戴脑电采集技术