
引用本文
任璐, 柯亚男, 柳文章, 穆朝絮, 孙长银. 基于优势函数输入扰动的多无人艇协同策略优化方法. 自动化学报, 2025, 51(4): 824−834 doi: 10.16383/j.aas.c240453
Ren Lu, Ke Ya-Nan, Liu Wen-Zhang, Mu Chao-Xu, Sun Chang-Yin. Multi-USVs cooperative policy optimization method based on disturbed input of advantage function. Acta Automatica Sinica, 2025, 51(4): 824−834 doi: 10.16383/j.aas.c240453
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c240453
关键词
多无人艇协同,近端策略优化,多智能体强化学习,输入扰动
摘要
多无人艇(Multiple unmanned surface vehicles, Multi-USVs)协同导航对于实现高效的海上作业至关重要, 而如何在开放未知海域处理多艇之间复杂的协作关系、实现多艇自主协同决策是当前亟待解决的难题. 近年来, 多智能体强化学习(Multi-agent reinforcement learning, MARL)在解决复杂的多体决策问题上展现出巨大的潜力, 被广泛应用于多无人艇协同导航任务中. 然而, 这种基于数据驱动的方法通常存在探索效率低、探索与利用难平衡、易陷入局部最优等问题. 因此, 在集中训练和分散执行(Centralized training and decentralized execution, CTDE)框架的基础上, 考虑从优势函数输入端注入扰动量来提升优势函数的泛化能力, 提出一种新的基于优势函数输入扰动的多智能体近端策略优化(Noise-advantage multi-agent proximal policy optimization, NA-MAPPO)方法, 从而提升多无人艇协同策略的探索效率. 实验结果表明, 与现有的基准算法相比, 所提方法能够有效提升多无人艇协同导航任务的成功率, 缩短策略的训练时间以及任务的完成时间, 从而提升多无人艇协同探索效率, 避免策略陷入局部最优.
文章导读
无人艇作为一种常见的自主无人系统, 在海上巡逻[1]、水质监测[2]、海上救援[3]和海上资源探测[4]等任务中发挥着重要作用. 由于单无人艇在续航、载荷和任务多样性方面存在限制, 难以满足日益复杂的海上作业需求, 因此多无人艇(Multiple unmanned surface vehicles, Multi-USVs)协同作业受到了广泛关注. 其中, 多无人艇协同导航是实现多艇协同作业的关键, 近年来被广泛研究[5-11]. 现有的无人艇控制方法通常需要建立精确的动力学和运动学模型. 在开放未知海域, 洋流、风速和暗礁等因素也使得多无人艇系统对自主协同导航提出更高的要求. 因此, 如何通过无人艇之间的相互协作, 以最快速度和最低成本成功导航至多个目标点是当前极富挑战性的难题.
近年来, 多智能体强化学习(Multi-agent reinforcement learning, MARL)在解决复杂的多智能体决策问题上展现了巨大的潜力[12-16], 受到研究者们的广泛关注. 许多经典的MARL算法被提出, 如值分解网络[17] (Value decomposition networks, VDN)、单调值函数分解[18] (Monotonic value function factorisation, QMIX)、多智能体确定性策略梯度[19] (Multi-agent deep deterministic policy gradient, MADDPG)、多智能体近端策略优化[20] (Multi-agent proximal policy optimization, MAPPO)、反事实多智能体策略梯度[21] (Counterfactual multi-agent policy gradients, COMA)等. 在此基础上, 研究者们对多无人艇系统进行了深入研究[22]. Wang等[23]基于MADDPG算法, 针对多无人艇系统的协同目标入侵问题, 提出一种可扩展的MARL算法, 实现了多无人艇系统规模的自适应调节. Xia等[24]针对无人艇舰队的协同多目标狩猎问题, 提出一种基于MADDPG的部分可观测多目标搜索近端策略优化算法. Zhao等[25]利用确定性策略梯度(Deep deterministic policy gradient, DDPG)算法, 提出一种随机制动的MARL方法, 实现了欠驱动多无人艇编队的路径跟踪. 同样地, 基于MADDPG策略, 文献[26]针对多无人艇目标跟踪问题, 通过V型概率数据提取和Safe DDPG动作约束方法, 有效地实现了多无人艇的目标跟踪任务. 针对多无人艇协调追逐问题, Gan等[27]提出基于MA-POCA的MARL方法, 构建了障碍辅助追逐框架, 显著提高了多无人艇系统的协同追逐效率. 类似地, 针对多无人艇追逃游戏, 文献[13]提出一种分布式捕捉策略优化方法, 通过双向门控循环单元特征网络提取观测序列以及虚拟障碍和课程学习, 提升策略的泛化能力与收敛速度, 从而实现了多无人艇的捕捉. 这些基于数据驱动的MARL算法是通过智能体与环境交互收集大量的经验数据, 从而有可能从这些经验数据中学习出接近最优的协同策略. 高质量的经验数据通常能使模型的训练过程事半功倍, 而这些数据的获取依赖智能体在当前策略的基础上对环境进行进一步探索. 然而, 过度的探索又会使系统无法充分利用已有的策略来获取最大化的奖励, 从而导致性能下降. 因此, 如何平衡智能体对环境的探索与对当前策略的利用是提升学习效率的关键.
在强化学习算法中, 注入噪声是一种常见的提升探索的手段[28-31]. 例如, 文献[28-29]通过在动作输出增加噪声来模拟输出扰动, 使智能体以一定概率访问环境中的其他状态. 文献[30]在策略的模型参数上(如神经网络权重)增加噪声, 使得策略避免陷入局部最优, 从而提高其探索能力. 而文献[31]则是在优势函数输出端增加噪声来对策略的优化目标进行扰动, 从而间接提升策略在接下来与环境交互过程中的探索能力. 这些方法通过添加噪声影响策略的优化过程或其动作输出, 从而帮助智能体发现未知的高奖励区域. 尽管现有的方法在提升智能体探索能力上卓有成效, 但是无法从根源上解决探索与利用之间存在的矛盾. 此外, 在多智能体系统中, 由于智能体之间相互作用, 若仅在个体上增加噪声, 可能会破坏多体之间的协作关系. 因此, 本文在集中训练和分散执行(Centralized training and decentralized execution, CTDE)框架基础上, 从提升优势函数的泛化性能出发, 考虑从优势函数的输入端增加噪声来模拟扰动, 提出一种基于优势函数输入扰动的多智能体近端策略优化(Noise-advantage multi-agent proximal policy optimization, NA-MAPPO)方法. 这种方法通过将学习出的泛化能力更高的优势函数作为各智能体策略的优化目标, 在提升智能体各自策略探索能力的同时, 保证联合策略对多智能体之间协作关系的利用, 从而提升多智能体系统对整个环境的探索效率. 通过在模拟多无人艇协同导航任务中的实验验证, 本文所提方法与基准算法相比, 有效提升了多无人艇协同导航任务的成功率, 缩短了策略的训练时间以及任务的完成时间. 另外, 本文方法不仅能够实现多无人艇的多分配导航任务, 而且能够进一步推广至多无人机、多机器人等多智能体系统中, 协助各类智能体实现协同控制任务, 并提高方法性能.
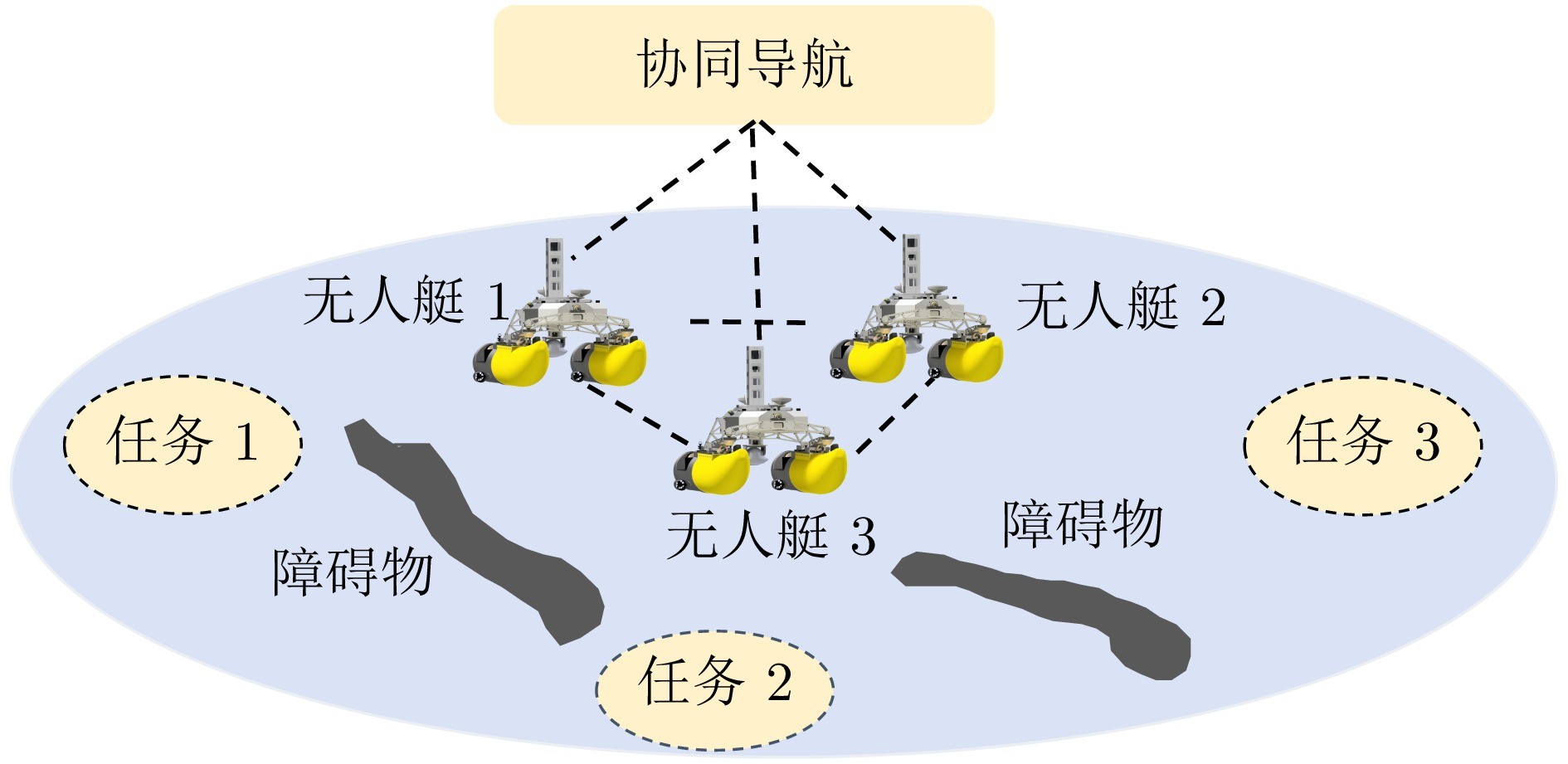
图 1 多无人艇协同导航示意图
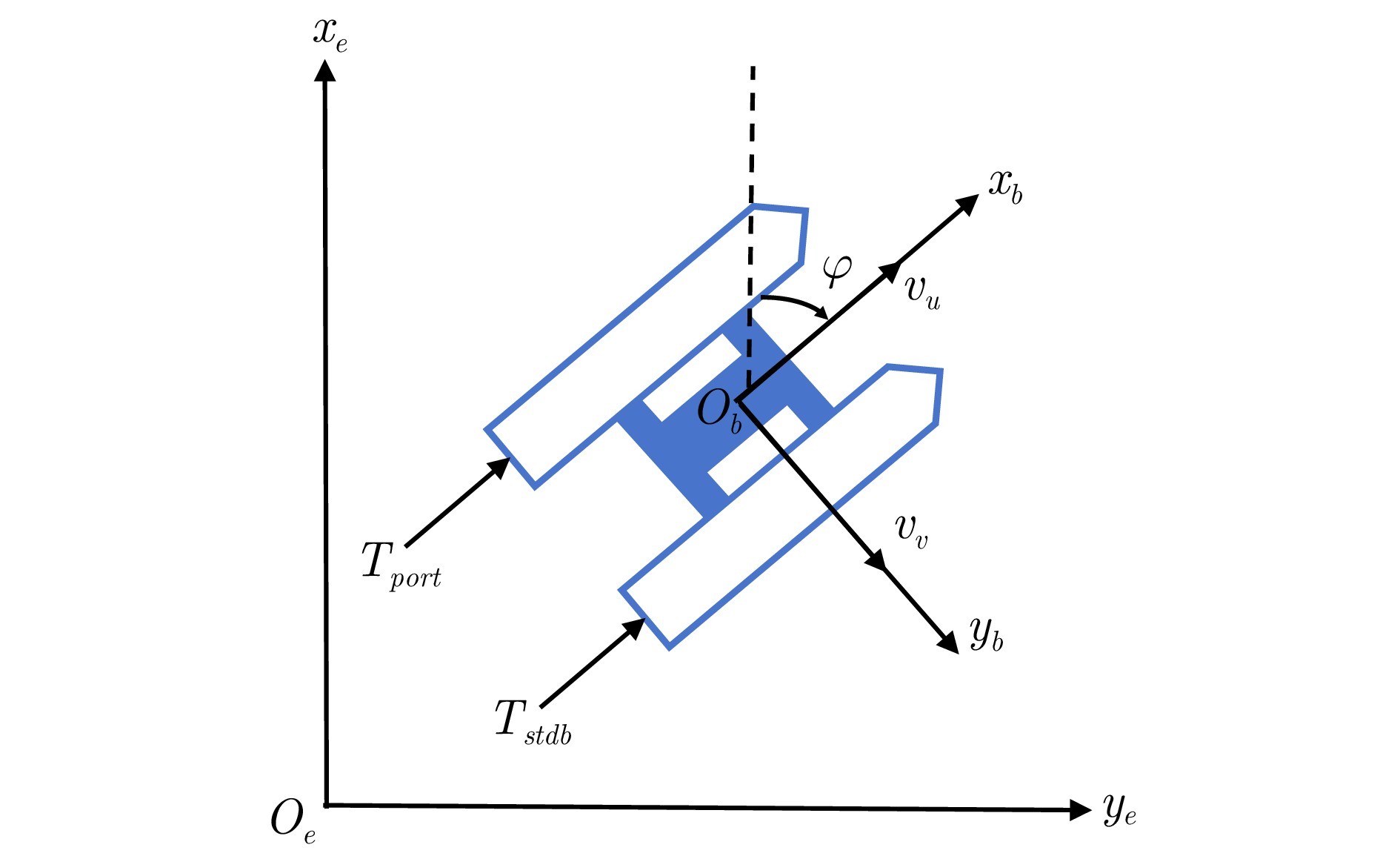
图 2 无人艇的惯性坐标系和体固定坐标系
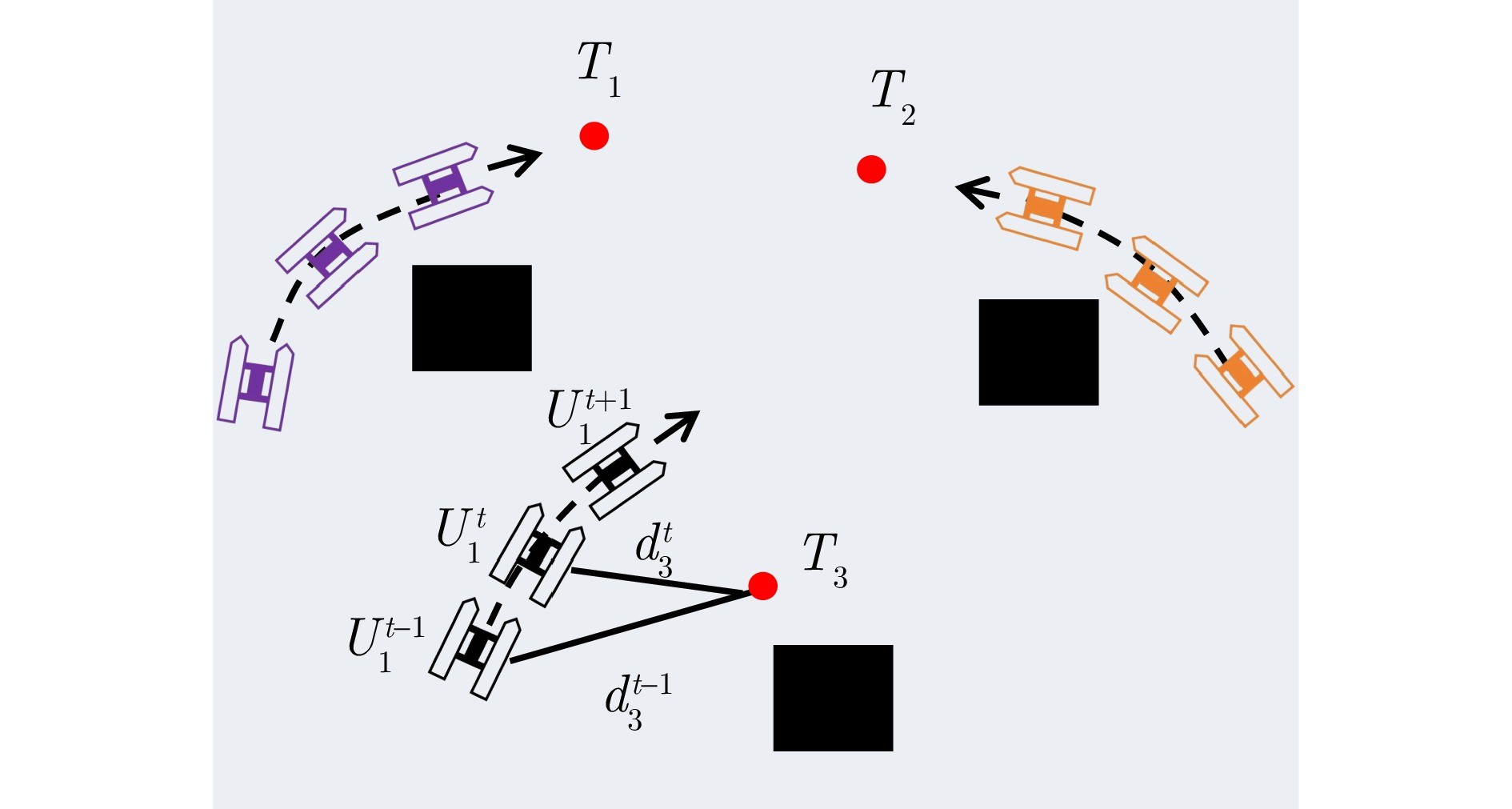
图 3 奖励函数示意图
本文提出一种基于优势函数输入扰动的多智能体近端策略优化方法. 在集中训练和分散执行框架基础上, 通过在优势函数输入端注入扰动, 有效提升了优势函数的泛化能力, 促进了策略对未知奖励区域的探索. 与现有的基准算法相比, 所提方法能够有效提升多无人艇协同导航任务的成功率, 缩短策略的训练时间以及任务的完成时间, 有效缓解了多无人艇协同策略易陷入局部最优的问题.
作者简介
任璐
安徽大学人工智能学院讲师. 2021年获得东南大学控制科学与工程专业博士学位. 主要研究方向为多智能体系统一致性控制, 深度强化学习和多智能体强化学习. E-mail: penny_lu@ia.ac.cn
柯亚男
安徽大学人工智能学院硕士研究生. 主要研究方向为多智能体强化学习, 船舶运动控制. E-mail: yanan_ke@stu.ahu.edu.cn
柳文章
安徽大学人工智能学院讲师. 2021年获得东南大学控制科学与工程专业博士学位. 主要研究方向为深度强化学习, 多智能体强化学习, 迁移强化学习和机器人. 本文通信作者. E-mail: wzliu@ahu.edu.cn
穆朝絮
安徽大学人工智能学院/安徽省安全人工智能重点实验室教授. 主要研究方向为强化学习, 自适应学习系统和智能控制与优化. E-mail: cxmu@tju.edu.cn
孙长银
安徽大学人工智能学院教授. 1996年获得四川大学应用数学专业学士学位, 分别于2001年、2004年获得东南大学电子工程专业硕士和博士学位. 主要研究方向为智能控制, 飞行器控制, 模式识别和优化理论. E-mail: 20168@ahu.edu.cn
转载本文请联系原作者获取授权,同时请注明本文来自Ouariel科学网博客。
链接地址:https://wap.sciencenet.cn/blog-3291369-1486918.html?mobile=1
收藏