
《AI与声音的迷思》系列之一
为什么AI歌声能打动人,却未必“拥有情感”?
——从“大头针”现象谈起
马金龙
(中国科学院)
【引言】当算法学会“唱歌”
“明知是AI,却还是听哭了。”
最近,一位名为“大头针”的AI歌手在网络悄然走红。它翻唱的《泪海》《你看你看月亮的脸》等作品,以令人动容的“破碎感”和“故事感”引发热议。评论区有人惊叹“比真人还有感情”,也有人困惑地问:“这真的只是程序吗?”
这个现象将我们推向一个既熟悉又陌生的问题:当AI唱得“很有感情”时,我们究竟在谈论什么?
随着Suno、MusicLM等AI音乐平台的快速发展,机器创作的歌声越来越具感染力。但作为研究者,我们需要厘清一个基本事实:“能够表达情感特征”与“具有情感体验”并不是同一回事。
本文将从三个核心问题展开:
l 歌声中的“情感”究竟是什么?
l AI如何生成“有感情”的歌声?
l 为什么我们会被AI的歌声打动?
一、情感首先是可测量的声音结构人类如何歌唱?
从语音科学角度看,歌唱是多系统协同的复杂过程:呼吸系统提供动力,声带振动产生声源,声道塑造音色,最终由听者感知。这就是经典的“声源-滤波器模型”(Source-Filter Model)(图1)[1]。
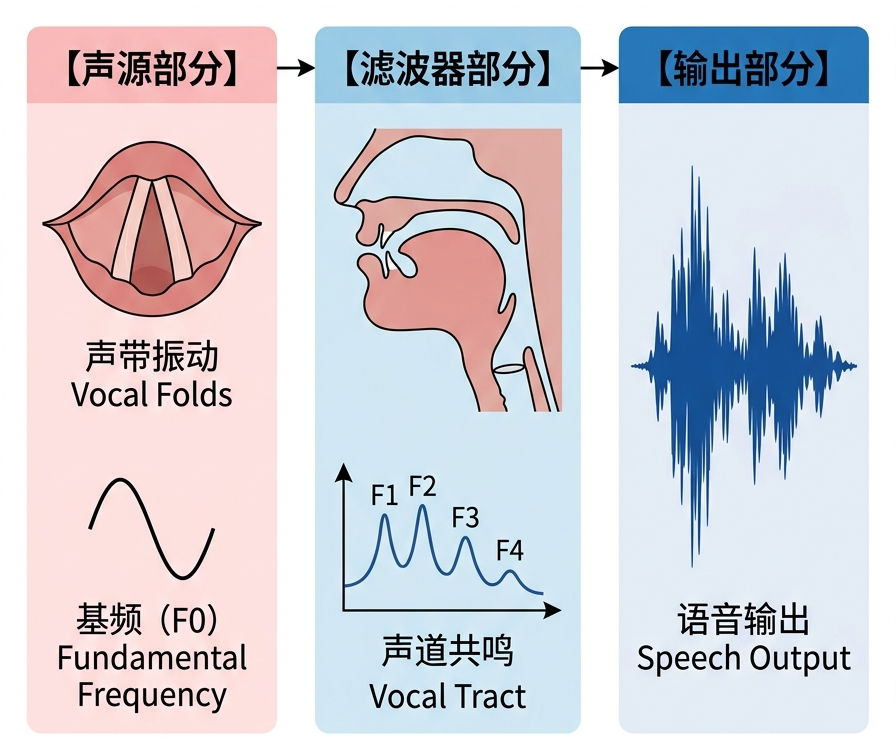
图1 声源-滤波器模型示意图
一个形象的类比:声带振动如同吉他琴弦产生基础音,声道则像可调节的音箱,通过改变形状塑造最终音色。人类歌唱的情感表达,很大程度上体现在对这个“音箱”的精细调节。
但真实发声远比模型复杂。声道形态、喉部状态、口型、发声强度、共鸣条件的微妙变化,都影响着声音细节。正因如此,人类歌声中的“情感”不只是“唱准音、对节奏”,更体现为大量动态而细微的声音差异。
情感的声学“指纹”
我们对语音情感研究的文献综述发现,不同情感状态确实对应着可测量的声学特征(表1)[2]:
表1 不同情感状态的声学特征
情感状态 | 典型声学特征 | 物理机制 |
悲伤 | 基频下降、颤音变慢(4-5 Hz)、气息增大 | 喉部肌肉松弛、声门闭合不全 |
愤怒 | 基频升高、能量集中、发声强度大 | 呼吸压力增强、声道紧张 |
温柔 | 音量减小、高频泛音少、连音增多 | 声带闭合轻柔、声道放松 |
换言之:听众能从歌声中感受到情感,是因为这些情感状态会在声音层面留下相应“指纹”——音高颤动、气息控制、音色变化等。
这个发现很关键:它意味着情感表达在一定程度上可以被“解码”为声学参数的组合,这也为AI学习情感表达提供了可能性。
二、区分两个层面:体验 vs. 表征
在人类歌唱中,情感通常影响呼吸控制、音高变化、节奏处理、音色明暗及共鸣调节等多个方面。也就是说,情感不仅存在于主体内部,也会通过发声过程表现为可观察、可分析的声学特征。
但需要强调:这不意味着情感可被简单还原为一组参数。更准确的说法是:
情感一方面涉及主体的主观体验(包括生理唤醒、认知评价、主观感受等复杂过程),另一方面会在表达中呈现为若干具有规律性的声音特征。前者属于体验层面,后者属于表征层面——二者相关,但不等同。
这一区分之所以重要,是因为今天很多关于AI的讨论,往往恰恰在这里发生混淆:只要机器生成的结果足够逼真,人们就容易推断它也拥有了与人类相似的内部状态。
然而,从“表达特征可被模拟”推导出“主体体验已经存在”,在逻辑上并不充分。
【思想实验:中文房间】
想象一个不懂中文的人被关在房间里,通过查阅详细规则手册,能对中文问题给出完美中文回答——外界会认为房间里有人“理解”中文。但这个人真的理解吗?
哲学家塞尔(Searle, 1980)用这个实验指出:语法操作不等于语义理解。同样,AI掌握了情感表达的“语法规则”,但不等于拥有情感的“语义体验”[4]。
当然,这一论证本身也有争议。丹尼特(Dennett)等哲学家反驳:如果系统行为在所有可观察维度上都无异于“有意识主体”,我们是否有理由否认其意识?这场争论至今未有定论[5]。
涌现的可能性
这里引出一个关键问题:当AI系统复杂度足够高时,是否可能“涌现”出真正的情感体验?
目前主流观点认为[6,7]:仅仅增加参数量和训练数据,并不必然导致主观体验产生。就像再复杂的天气模拟系统也不会“感到”寒冷,高度逼真的情感表达系统也未必拥有情感本身。
三、AI学的是“表达形式”,不是“情感经验”技术演进:从拼接到生成
AI歌声生成经历了快速演进(表2):
表2 AI歌声生成演进代次及其状况
技术代次 | 代表模型 | 核心特点 | 情感表达能力 |
第一代 | 拼接TTS | 预录音片段拼接 | 僵硬、不自然 |
第二代 | WaveNet (2016) | 自回归逐样本生成 | 初步自然但情感单一 |
第三代 | VITS (2021) | 端到端变分推断 | 音色自然、情感可控性增强 |
第四代 | DiffSinger (2022) | 扩散模型 | 细节丰富、可呈现“破碎感” |
第五代 | Suno等 (2023-) | 多模态大模型 | 从文本直接生成完整歌曲 |
数据来源:[3]
核心机制:统计学习
当前主流技术依赖数据驱动:通过海量样本学习“输入特征—输出声音”的统计关系。典型流程为(图2):
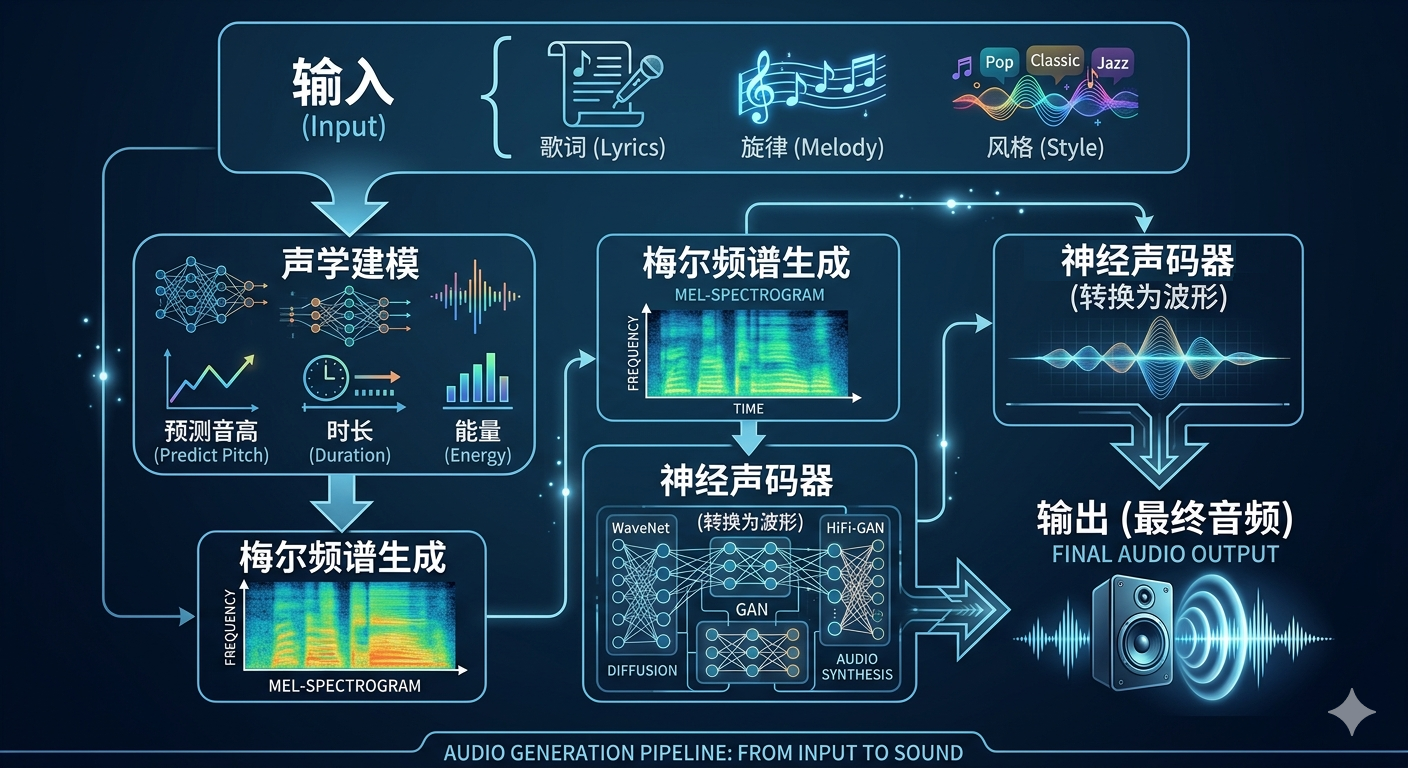
图2 “输入特征—输出声音”的统计关系流程图
关键点:这类系统并不重建人体发声的生理过程,而是逼近结果。更具体地说,AI学习的是:什么样的音高变化、节奏分布、音色细节,更容易被识别为“深情”“伤感”或“温柔”。
以DiffSinger为例[3],系统通过扩散概率模型逐步将噪声“去噪”成歌声波形。这一过程虽然数学上精妙,但本质上仍是对“什么样的波形听起来悲伤”这一统计规律的学习,而非对“悲伤体验”本身的模拟。
训练数据的局限
值得注意的是,AI所学的“情感规律”来自训练数据的统计分布,这导致:
l 文化局限性:基于英语流行音乐训练的模型,难以准确表达中国戏曲的“水磨腔”
l 风格同质化:倾向复制主流风格,可能抑制创新
l 情感刻板化:“悲伤=慢速+低音+颤抖”的简化模式导致套路化
因此,AI歌声系统即使不具备主观情绪体验,依然可以在输出上呈现较强的情感表达特征。它完成的是表达形式的学习与再生成,而非情感经验本身的产生。
四、一半是算法,一半是你的大脑
如果AI没有情感体验,为什么它的歌声仍能打动人?答案不仅在生成端,更在感知端。
主动的解释过程
人类对声音的理解从来不是被动接收,而是主动解释的过程。当外部信号呈现熟悉的结构特征时,听者会自然地进行情感归因。这在文学、电影、音乐中都很常见:即便对象非真实主体,我们依然可能产生真实情感反应。
神经科学的证据
功能性磁共振成像(fMRI)研究显示:听到“悲伤歌声”时,即使知道是合成的,已有研究[10]表明,听到悲伤歌声时,ACC和脑岛会激活。基于预测编码理论[8],当AI歌声具有相似声学特征时,理论上也应触发类似脑区反应——尽管这一假设仍需专门的实证研究验证。
这可用预测编码理论解释:大脑根据过往经验预测感官输入,当接收到符合“悲伤歌声”模式的信号时,自动调用相应情感记忆和生理反应。
换言之:情感体验发生在听者大脑中,而非音频文件里。
因此,AI歌声的“情感感”相当部分来自听者大脑对声音结构的解释、归类与共情。更稳妥的表述是:当前AI系统已能高效生成具有情感表达特征的歌声,而听者则在这些声音结构中主动建构出了情感意义(图3)。
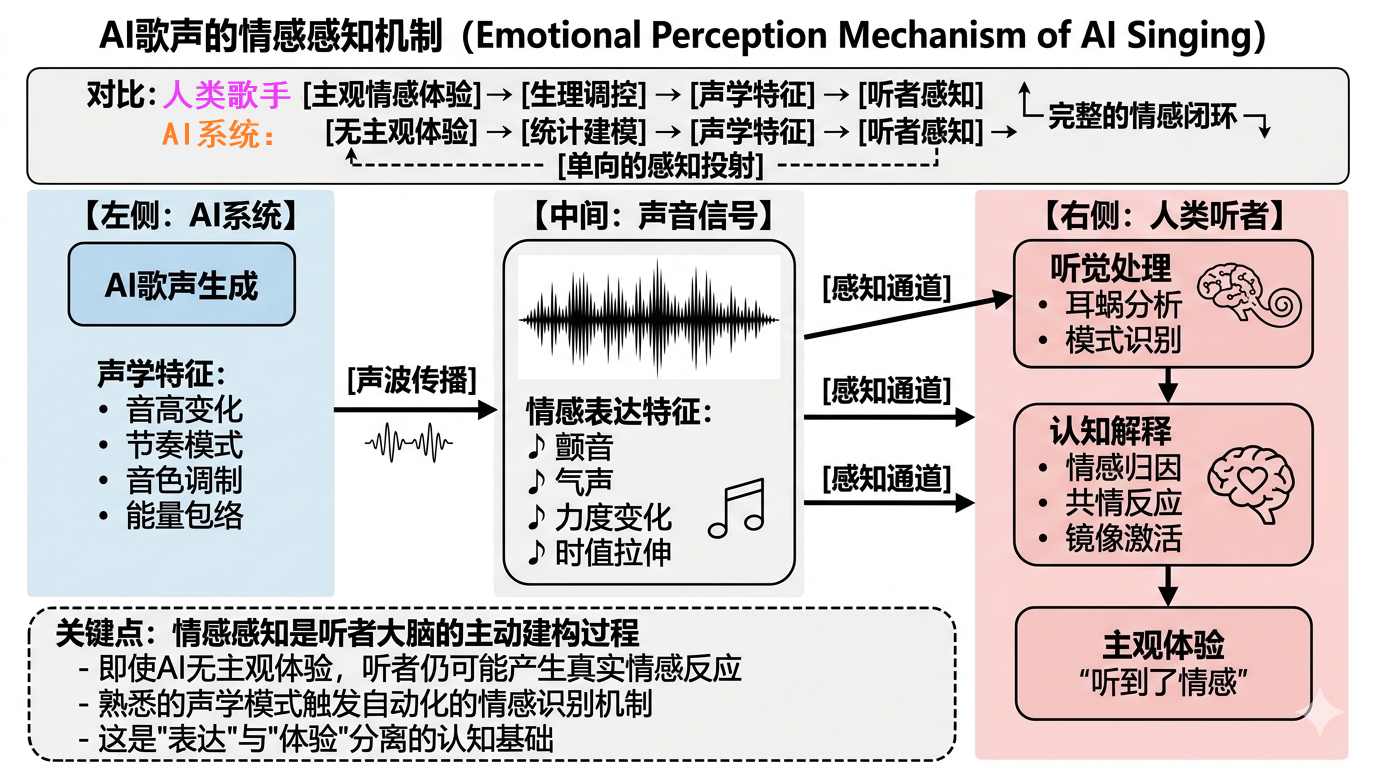
图3 AI歌声的情感感知机制
更稳妥的表述或许是:当前AI系统已经能够高效地生成具有情感表达特征的歌声,而听者则在这些声音结构中主动建构出了情感意义。
“恐怖谷”现象
并非所有AI歌声都能成功触发共鸣。当合成效果“几乎但未完全”接近真人时,反而引发不适——这类似机器人的“恐怖谷效应”[9]。
在声音领域,这种不适可能来自:
l 呼吸点不自然、音节衔接机械
l 局部细节精致但整体情感弧线断裂
l 音色过于规整,缺少真人声带振动的微小随机性
有趣的是,“大头针”受欢迎恰恰可能因为其“破碎感”——那些“不完美”反而被解读为“真实情感流露”,从而跨越了恐怖谷。这提示:情感真实性的感知,有时并不依赖技术上的完美,而在于符号层面的“可信度”。
五、区分“结果相似”与“过程相同”
关于AI表达能力的讨论中,最需警惕的倾向是:把“结果相似”误认为“过程相同”。
计算器能算出正确答案,但不“理解”数学;AI能生成动人歌声,也不自动意味着“体验”情感。这在哲学上称为“功能等价”与“实现等价”的区别。
塞尔的“中文房间”实验正是这一观点的经典阐述:语法规则的操作不等于语义理解,声学参数的操控也不等于情感的体验[4]。
哲学争议
当然,这一论证本身有争议。丹尼特等哲学家指出:如果系统行为在所有可观察维度上都无异于“有意识主体”,我们是否有理由否认其意识?布洛克进一步区分了“现象意识”与“通达意识”,认为即使系统具有信息处理能力,也未必拥有主观体验[11]。
至少就当前主流AI歌声系统而言,我们仍缺乏充分理由将其视为具有与人类相似的情感主体性。它们已能在相当程度上组织声音、模拟表达,却不因此自动拥有情绪体验、意图结构和自我感受。
当然,问题不会永远停留在今天的技术形态。随着发声生理模型、物理建模方法及更复杂交互机制进入歌声生成系统,未来对“发声过程”的模拟可能更深入。届时,关于表达、主体性与情感关系的讨论,也可能比今天更复杂。而这,也让这一技术问题最终上升为认识论层面的哲学议题。
六、AI歌声:技术现象与认识论镜子
在我看来,AI歌声的意义,不在于证明机器“拥有情感”,而在于迫使我们重新审视长期默认的前提。
过去我们认为:凡是具有强烈感染力的表达,背后必然有真实体验的主体。但AI提醒我们:某些被视为“人类特征”的表现形式,实际上可以被学习、重构、再生成。
这不削弱人类情感的意义,反而帮助我们认识:人的独特性,不仅在于能表达某种效果,更在于表达背后的完整体验过程、生命经验、意图结构与主体历史。
从主体性到关系性
AI歌声挑战了我们关于“主体性”(subjectivity)的传统理解。传统观点认为,情感表达必然预设一个统一、连续、具有自我意识的主体。但AI的存在提示我们:
l 表达是否必须有主体? 暴风雨可被形容为“愤怒”,算法音乐可以“忧伤”——这些“情感”是客观存在,还是观察者投射?
l 主体性是二元还是连续谱? 从MIDI音序器到神经网络,“创作主体性”是在某个临界点突然涌现,还是逐渐增强的连续体?
l 身体性(embodiment)的必要性? 如果系统具有虚拟“身体模型”,是否可能发展出某种“拟身体情感”?
这些问题已超出技术范畴,触及心灵哲学、美学和伦理学的核心[5,12]。
实践伦理挑战
除了形而上学问题,AI歌声还带来紧迫的实践伦理挑战:
1. 情感劳动外包:AI“情感陪伴”会否加剧人际疏离?如AI虚拟偶像(洛天依、初音未来)的粉丝经济
2. 真实性贬值:完美表达可批量生成时,真实情感会否失去特殊价值?如音乐行业对AI生成作品的版权争议(Drake与AI Drake之争)
3. 算法操控风险:精准控制声学参数“设计”情感反应,是否构成新型操控?如情感识别技术用于广告定向投放的隐私问题
这些提醒我们:技术发展不仅是能力扩展,也是价值观重塑。
结语:重新理解“被打动”
因此,面对AI的“深情歌声”,更合适的态度不是急于判断“机器是否有情感”,而是认真区分:哪些属于情感表达的形式层面,哪些属于情感体验的主体层面。
从这个意义上说,AI歌声不仅是技术现象,更是认识论的镜子。它让我们重新看到:人类“被打动”的经验,本身包含着表达、感知与解释三者间极为复杂的关系。
这一问题,值得在人工智能、艺术实践与认知科学的交叉领域继续深入探讨。
【下期预告】
在辨析了AI“情感”的哲学问题后,下一篇我们将聚焦更具体的技术现实:
为什么像Suno这样的平台,能用“你的声音”唱出你根本唱不上去的歌?
l 高音上不去?AI帮你“拓展”音域
l 颤音控制不了?算法精准模拟
l 气息不够长?波形可以无限延续
声音克隆技术如何实现?它在赋予我们前所未有的表达能力的同时,又对我们的“声音身份”提出了怎样的挑战?
当你的声音可以唱任何歌,“你的声音”还属于你吗?
敬请关注系列之二:《AI如何“克隆”你的声音?——从技术到伦理》
参考文献
[1] Fant, G. (1960). Acoustic Theory of Speech Production. The Hague: Mouton.
[2] Juslin, P. N., & Laukka, P. (2003). Communication of emotions in vocal expression and music performance: Different channels, same code? Psychological Bulletin, 129(5), 770-814.
[3] Liu, J., Li, C., Ren, Y., Chen, F., & Zhao, Z. (2022). DiffSinger: Singing voice synthesis via shallow diffusion mechanism. Proceedings of the AAAI Conference on Artificial Intelligence, 36(10), 11020-11028.
[4] Searle, J. R. (1980). Minds, brains, and programs. Behavioral and Brain Sciences, 3(3), 417-424.
[5] Merleau-Ponty, M. (1945/2012). Phenomenology of Perception (D. A. Landes, Trans.). London: Routledge.
[6] Chalmers, D. J. (1995). Facing up to the problem of consciousness. Journal of Consciousness Studies, 2(3), 200-219.
[7] Dehaene, S., Lau, H., & Kouider, S. (2017). What is consciousness, and could machines have it? Science, 358(6362), 486-492.
[8] Friston, K. (2010). The free-energy principle: A unified brain theory? Nature Reviews Neuroscience, 11(2), 127-138.
[9] Mori, M., MacDorman, K. F., & Kageki, N. (2012). The uncanny valley. IEEE Robotics & Automation Magazine, 19(2), 98-100.
[10] Koelsch, S. (2014). Brain correlates of music-evoked emotions. Nature Reviews Neuroscience, 15(3), 170-180.
[11] Block, N. (1995). On a confusion about a function of consciousness. Behavioral and Brain Sciences, 18(2), 227-247.
[12] Clark, A. (2008). Supersizing the Mind: Embodiment, Action, and Cognitive Extension. Oxford: Oxford University Press.
作者简介:
马金龙,中国科学院研究人员。研究方向包括语音科学、声学建模、人工智能生成与声音表达,聚焦于声道共鸣的非线性波动机制及其在AI歌声合成中的应用。
联系方式:963153629@qq.com
转载本文请联系原作者获取授权,同时请注明本文来自马金龙科学网博客。
链接地址:https://wap.sciencenet.cn/blog-312-1530434.html?mobile=1
收藏