博文
《经典融智学》第一章,言和语的关系数据库
||
如何从《新版融智学》(图文+音频)获得大跨界的启迪而积极准备撰写《经典融智学》?
目录
序言,人类近未来的希望
绪论,人类认知巨大飞跃
第一部,言识软硬形式化系统工程,大跨界,实践融智学
第一章,01,言和语的关系数据库
第二章,02,跨学科知识中心平台
第三章,03,智能化双字棋盘软件
第四章,04,智能化驻行载器硬件
第二部,教管学用社会化系统工程,大跨界,实践融智学
第五章,05,教是为了不教
第六章,06,管是为了不管
第七章,07,学是为了不学
第八章,08,用是为了不用
第三部,五大范畴,大跨界,驾驭十大学部,理论融智学
第九章,09,从自然到人工,物
第十章,10,从心理到社会,意
第11章,11,从人文到数学,文
第12章,12,从神学到哲学,道
第13章,13,从交叉到综合,理义法暨序位 ,
结语,有趣的生涯过程优化,及其有益效果,展示
作者:邹晓辉Geneculture
《新版融智学》第一章,文本(基于它可撰写《经典融智学》第一章,汉英经典双语版)
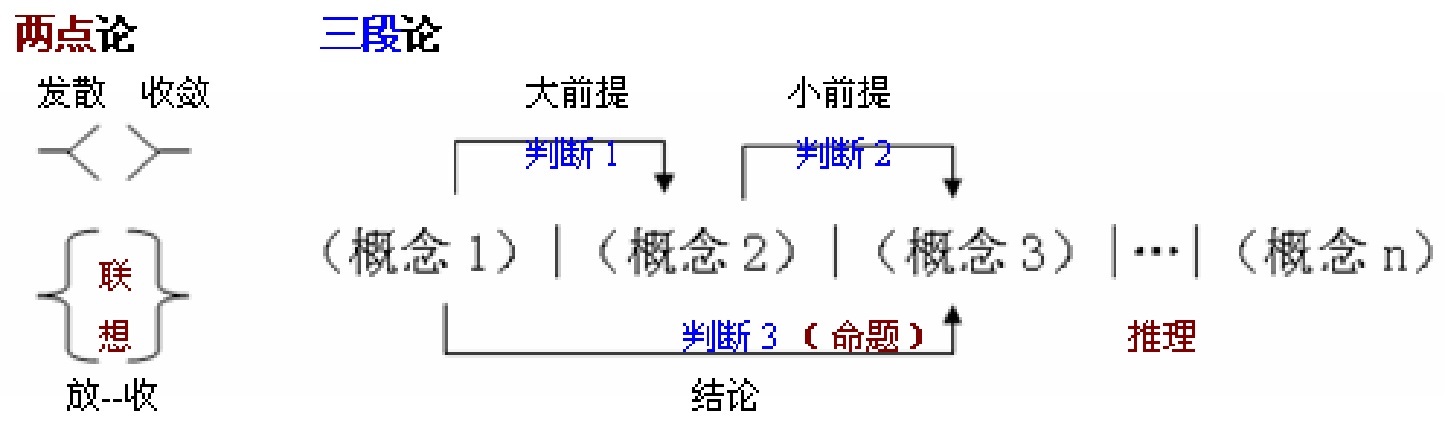
各位大家好好, 今天我们开始《融智学导读》的第一章内容的细化, 以及构成《新版融智学》的第一章,我们把这个题目是言和语的关系数据库,这里实际上涉及到三个内容,言和语的关系属于普通语言学的内容,但是它是往数据库方向走,它要往认知语言和形式语言,即要从这方面来对接,最后,才是和计算机的结合,它是这样的,由于融智学是人机交互、协作和协同的一整套学问,所以,它是一个大跨界的课程。 从2023年开始我们开启了本科、硕士、博士这种认知水平的融智学讲席,它就正式开始,前面两课做了预热旨在温故知新且继往开来。 融智学导读是已经预印本正式发行了,大家可在网上可以查得到可以看。但是新版融智学还没有所以在这里开始作为讲义来讲,我们在清华大学在线课堂开的融智学公益课2023年春季课程之后即可整理其文本的经典和大家一起来分享我们的研究成果和它的应用方向。 首先我们来看一下这个目录,很简练,就是三节,也就是说新版融智学和融智学导读,它在框架结构上几乎是一样的,但是,在展开的细节深入上会不一样,在讲课过程当中,会逐步充实细化它。第一节是言和语的关系,它是普通语言学的内容,也就是说普通语言学这个一直没有变成语言科学,有语言哲学,有语言学,但是语言科学一直没有形成,因为它的研究对象不明确。为此,我们早期做了很多工作,其中这里看有三个图,而实际上有一组图,两点论和三段论的关系,实际上是中西方基于语言不同的两种思维方式的差距。
亚里士多德的三段论,它是大前提、小前提和结论,大前提的一个判断由两个概念构成,小前提的另一个判断也由两个概念构成,结论的那一个判断还要把第一个概念和最后一个概念衔接起来构成,即下一个结论。也就是说,要把一二三个概念要连通。这样整个推理的一个基本思路就形成了,如果要延长推理过程的逻辑链,就会延至多即n个概念,所以说他这套演绎体系就会比较复杂。上堂课我们讲到在古希腊的演绎体系当中,亚里士多德的《工具论》和《形而上学》实际上都讲的是逻辑的问题,是思维的问题。不知怎么搞的,人们把它翻译成哲学。实际上哲学只是一个理性的反思,如果仅仅用哲学来看问题的话,实际上翻译有很大的问题,因为哲学的原意是爱智慧的意思,爱智慧的人是哲人,爱智慧的学问叫哲学,说白了它就是一个逻辑自洽的宏观的大框架,让哲学家可以无限的思考,放开,发散,但是真正的要害(演绎推理的基础)就在三段论,这就是为什么亚里士多德(这个名下)建立的形式逻辑三段论至今有效(形式推演过程可检验),在人脑这种思维方式当中被制定了。但是中国的思维方式和它不一样。中国文言的基于汉字的思维方式,是两点论,或发散、或收敛,中间产生联想,放和收是两点论,它与三段论怎么衔接呢?这是关键。也就是说早期的理论融智学,这是一个突破口。那么具体到普通语言学来讲,那么普通语言学的研究对象不明确,但是人是有语言会说话的动物,人们天天都在说不能因为你这个理论没有建立,人们就不说话就不思考了?就是说思维科学没有建立起来,语言科学没有建立起来,都在建立的过程当中,但是人们的思维,人们的说话,人们的语言已经是有几千年了,甚至更早,对不对?到再早都无法考证了,是吧?这就说明实践一定是在前面,理论一定是在后面,有了理论反转来指导实践会上一个台阶,它的意义在这个地方,我们的课的意义也在这里。 第一节我讲言和语的关系,大家说我们只知道语言和言语,不知道什么言和语。 专门听过融智学课的人,才会明白,我们就会展开我们的附录的一系列正式发表的文章,在后面也会一一介绍。这个言和语的关系为什么它是个突破点,而这个突破为什么可以把语言科学、思维科学以及信息科学找到突破? 这边大家看到一个 Understanding Model C是一个截图,这边是数字而那边汉字,但是它们的底层都是01,都是数字计算器,我这么来把它展示,想给大家引入一个基本的思考方式,就融智学的思考方式,它一定是一边是人的思考,一边是机器的运算和操作。机器的运算和自动化的批处理,遵循的是什么法则?人脑这种自由选择这种发散与收敛,不管两点论也好,三段论也好,或者是还有其他什么论也好,一句话就是两个极端,那么这两个极端它怎么衔接?有没有衔接点? 在人们的实际应用当中,我们有字典,有词典,有语法手册,早期我在这里做过一个突破,当我的语言学导师把我带进语言学以后,我本来是在信息学上的突破,在中英对照在探缘的时候,和我的北大的语言学导师缘分是2000年,之前建立缘分是远程的,2000年见了面,他把他专著送给我。我就沿着这个途径在他的启发下就做了一个深层次的探索,于是有了这一本专著叫《字本为中文信息处理的基础》,这篇代表性的文章主题是字本为与中文信息处理。字是汉语的基本结构单位,就是我的老师徐通锵教授的基本观点。他这个基本观点有它的渊源,最后我们在后面的附录部分来详解,这里点到为止,这是普通语言学的,是人脑的,基本结构单位是非常重要的,那么信息处理我们前面的课已经谈到,它是有计算机以后才把信息处理这个事情给凸显了出来,人脑也做信息处理,但是,光有人脑没有电脑的时候没那么突出,有了电脑以后双脑有比较了,这个东西突出出来了。人脑的信息处理能力是心理学研究的智力,电脑的信息处理功能就是计算机科学探索的人工智能,融智学从这个角度来讲就非常的清晰,中文信息处理已经和计算机科学和人工智能的最前沿直接对接了。字本位理论是和语言学、普通语言学的最前沿对接,第一篇附录论文实际上是讲的这个东西,在应用层面上是什么关系呢?就是解析字与字组的关系,字人人都知道,是吧?因为汉字是我们每一个中国人,母语是汉语的人,脑袋里面是有深刻印象的,他从小到大他都是先识字,再组词,然后,再造句,是这么一个过程。字组纯粹是从形式上来考虑的,从形式上考虑,内容的组合,排列组合,是吧?字与字组的关系,这里为什么打个引号?因为,这样讲人们不太明白,要深入的讲了以后就引出我们的言和语的关系,字和字组的关系是言和语的关系的特例,这样讲就明确了。探索是什么?探索的是汉语形式化的新路。为什么要探索汉语的形式化新路?汉语好好的,你探出一个新路干什么?因为最早的计算机到了中国是不能用的,回忆我年轻的时候,当时我们单位是铁道部麾下的机关,IBM送了我们几十台电脑,拿到后大人都不会用。当时邓小平有句话从娃娃抓起,于是我们就把电脑赠送给幼儿园了,幼儿园也不会用,都是英文,老师都搞不懂,学生咋搞懂。当时我们的科研所也分了几台在探索。直到有一天中国下了大力气,组织了一大批人,这个事情是钱伟长挑头中文信息处理,中国成立了中文信息处理专委会。专委会第一届主任鲁川,我们后来也认识并交流了,后来当然它现在已经好多届了,都是老同志,包括微软的黄昌宁等等,总之有很多学者都介入进来了,直到有一天,我们的电脑能够处理汉字了,这个时候大家都感觉到中文信息工作是有用的,国外全是英文的,它不是一个简单的翻译问题,它是要么汉化,要么外挂,也就是说它实际上是个翻译问题,怎么让计算机会呢?就挂上去,比如说,美国的操作系统拿来,是纯英文的,那会儿人家没有搞中文的。当然,后来我们有一个朋友就专门给微软做字库,微软花钱10万美金买一套,就这样,微软它也有中文处理,大家还记得吗?早期在美国有叫王安的,他们父子搞了一个中文信息处理的东西,实际上微软的word就是从王安父子那里得到启发,学习才发展起来的。中文信息处理对整个西方的操作系统,语言处理尤其是应用系统,比如说它的office也是一步步发展起来的, Word这一块中国有金山,当时有好多人都在不同的角度想去做,实际上它的核心技术就三块,一个是要给一个标准,因为计算机的底层标准是ASCII码,是美国标准信息交换码,16进制的,它是把26个字母和阿拉伯数字结合,再加上一些助记符,特别的符号,构成了英语的键盘。电脑键盘的标准就是基于ASCII码来的,ASCII码是个美国标准,英美标准,它是不考虑咱中国人的,所以中国人就必须要和它衔接,衔接的时候要在标准上和它对接,怎么对接?通过二进制来对接,多进制转化,后面会提到,这就叫底层。过去有一个王码是输入码,五笔字型,那会叫万马奔腾,是怎么输入去,这是一套思维思维方式,一套技术体系,怎么显示又是另外一套,比如说王选的激光照排,它是显示,是另外要做字库放进操作系统里去的,包括我们也探究过,过去殷步九华罗庚的关门弟子是我们一个老朋友,那时他就做字库,他和王选认识,干字库的,早期四通也是干字库起家的,从这方面讲,国外的机子买过来,植入一套字库,有字库就可以显示,有输入码就可以输入打字,中间有一个标准就把它们三方面衔接起来,这三套体系建立起来,我们才能进行人机交互,才能用汉语,不是声音,是文字字符,后面事情还挺多。这条路开始它走得很艰难,因为它是外挂上去的,把操作系统拿来,专家们就把它翻译,然后给它外挂上去。现在安装一套系统以后,要选一个语言包,各国语言都是外挂的,都要选语言包,这时微软就自动就给你配套了,你选中文的语言包,操作系统界面就换成中文的了,选法语了就换成法语的了,那叫语言包,这就叫外挂,挂上去的,而不是直接的。还有一种就是汉化,啥叫汉化?所谓汉化就是自己还要做一套,比如说,现在金山的办公系统和微软办公系统不一样,微软办公系统的中文处理是外挂的,操作系统也是,office也是外挂的,但是金山这个汉化它就是直接用汉语来做的,它不同于前面说的外挂,它也可以处理英文,也可以处理中文,但是它这个中文就是直接处理,所以金山为什么早期它要搞机器翻译,就是因为他要做这个事情。这两套方式都有一个致命的地方,要依托美国标准,没有中国标准,中国搞了个GB,那只是对字的汉字的字库的管理,输入法的管理,衔接管理。对外挂汉化给一个标准而已。它不是计算机底层的标准,它不一样,底层的标准是通过基本输入输出系统(Basic Input/Output System),即通过 Bios来重新启动电脑,调动配置,全都靠底层技术,不懂得底层技术就弄不了,电脑坏了尤其是软件需要重装,就要启动BIOS,进而安装操作系统,办公系统Office和其他工具软件等等,没有BIOS都谈不上,我们要装操作系统要装要调整,就要从BIOS进去,这是一个什么概念呢?汉语形式化思路是什么?就要设计一种底层可以直接和汉语对接的,如果按美国标准来做,它实际上它或者是翻译或者是外挂的,它严格讲没有自己的东西,我探索的汉语形式化新路就是要有自己的东西,很多人走这条路没走通,我在这里走通了,典型示例即从一字精解到字字精解,这是对人的;后面是对机器的。什么意思?通过典型示例实现专家知识获取,汉语形式化是什么?是让它做到形式化理解,自然语言要形式化理解,机器只能形式化理解,它不能像人那样做基于内容的理解,机器它没有头脑,它更不可能有感情,它没有思想,说白了,它就是要你给它一套程序,无论是你给它编进去的程序,还是它自己通过机器学习自动生成的程序,都要依据程序来操作,就是这个情况,所以在附录这一块实际上就和我们第一节要讲的内容,你看,我们上面有个义项字典,用例辞典,语块手册,当时我做了这套功夫,对幼儿园、小学、初中、高中、大学、大专、本科、研究生、硕士乃至成年人,对人的整个语言素养的提升,整个思维的提升,也就是说除了有国际国内这种标准化的义项字典,用例辞典和语块手册,实际上每个人可建构自己的,每个学校也可建构自己的这一串串的东西,为什么要有这些区分,这些公式,这里就不展开,后面再讲。后面我的专著里面,会提供参考文献,有些前面已讲清楚,就不再在这里重复了。 这是第一节,简单介绍一下,等会展开第二节,言和语的形式化理解,推进了一步,推到了形式化理解,实际上这就把认知语言学和形式语言学结合了,就不再仅仅限于普通语言学。这个知识的跨度,越来越大,讲普通语言学是人文社科,讲形式语言学,已经是有逻辑数学,讲到认知语言学,把心理因素加上去了,甚至有心理学和心智哲学这些附加的学科也都加上去了,基本上八大学问都得加上去,还得加上交叉学科和综合学科。所以说融智学前面介绍过的十大学部在这里,每一章都要和十大学部发生关系,用传统思维模式,单独的哲学不行,单独的自然科学不行,单独的社会科学不行,单独的人文艺术不行,单独的工程技术也不行,单独的逻辑以及单独的数学都不行,必须做大跨界的整合,这是融智学的一个特点。所以说,言和语的形式化理解在这里导进去就导出来了八大形式,不限于汉语,不限于中文的文字和机器语言的数字,加上字式图表音像立体活体八大形式体系的理解以后,就是形式化理解,然后,在这个基础上,才能处理这种八大学问体系,以及十大学部,人类的整个知识。这是第二章我讲跨学科知识中心的平台的时候再讲,这里就点到为止。第三节我们讲了言和语的关系数据库,最后把这个东西落实到机器,可以把专家的知识重现,能够把千千万万的专家的知识语言理解的这种方式给它植进去,也就是说把人的语言和机器的语言要对接,甚至把八大形式要对接,这是不是一种未来的超级宏?计算机它是不一样的,它这个附录二我们就强调字和词的义项分析,就认了汉语研究的逻辑起点,与其说是字本位,不如说是言本位。因为,这里涉及字本位,引起了争论,因为,字和词分别代表中西方两套思维模式,两套语言体系,它的基本结构单位有很多人就绕不过来,因为现代汉语已经把词引进了中国,但是就不能把词这个东西当成是中国的,实际上它是舶来品,也就是在文言文里面没有word这一说,这个概念都没有。也就是整个现代汉语过去是文言的,中国落后到什么程度,只能用文言,白话文的发展是经过很漫长的时间的,我注意到历史,到多少时代以后才有现代汉语的,民国时期的那些语言大家,那些文学大家讲的话都是倒文不白的,都是夹杂着文言的,是吧?包括朱自清这么有名的大师都是倒文不白的,鲁迅更是,还有其他人就不用说了。举例来说,作为我们当代的中国人,我们要理解我们的历史,要知道我们的老祖宗的优点和不足,要知道人类的优点和不足,再知道机器的优点不足,才能做融智学要做的事情,才能引领未来的近未来的发展方向,才能实现人类认知的第二次大飞跃。所以说这里从附录三来讲,一种基于双语自动转换的间接形式化方法,这是从计算机实现这个角度编程这个角度来讲的。间接形式化模型和间接形式化方法,这个已经是在国际国内交流的了,有中英文的。这个已经是即直接是东西方对接这个角度的了,直到附录5大数据与人机对话,语必在言的集合里选择,已经彻底敲定,也就是说整个体系不仅建立起来了,而且它的落地的顶天立地的整个途径都通了。所以说,今天这堂课就步入了新版融智学的详细内容。 这一个课开始,第一章我们现在来讲第一节,我们来看看第一节言和语的关系怎么来理解,也就是说言和语的定义及其相互关系的理论模型,言单音节的字,把它作为语言的基本结构单位,与其混音节的字组,它是派生的结构单位,它第一类情况就是自然语言,第二类情况是机器语言,是两个极端,中间还有各种编程语言,各种各样的语言都可以用这个模型,而这个模型,我们上堂课讲的,也就是说,语言学家索绪尔是公认的世界的当代语言学的鼻祖,洪堡在他之前,洪堡没有排除歧义,洪堡那里有一个著名的歧义,word is a world,他说:一个词就可以是一个世界,也就是洪堡的观点就看到了语言的复杂性,到了索绪尔他那里,他区分了语言和言语,他说语言学应该研究语言,应该不要过多去考虑言语,因为,言语是千变万化的,是人们生活应用当中即日常应用当中的东西,很多东西,后来,基于经验科学方法又发展成了言语学,完全是一种社会科学,就是要做统计、做分析就可以了。也就是说在西方有语言学,现在已经慢慢派生出了言语学,融智学在这里另辟蹊径,走出了一套人机结合的一个突破点,不局限于人文这种文科的思考,也不局限于纯粹理工科的思考,而且是把文理打通思考,就是把语言的言和言语的言拿出来,作为基本研究对象,再把语言的语和言语的语拿出来作为派生的对象,这样一下子就奠定了语言科学的基础,而且把语言科学和早期的语言学和现在的语言哲学就都区分开来了,这一步研究对象明确就区分开来了。因为任何一门严谨的学科,它要成立有4个要件,第一研究对象要明确,第二它学科性质要明确。也就是说语言科学和语言学的区别在哪里?和语言哲学区别在哪里?和语言学的区别在于什么呢?语言学它研究语言,而语言是一个大杂烩,所以说,它不能成为科学。而融智学的语言观把言和语做了划分,言作为基本对象,这里就可以产生语言科学。从言到它的形式化路径就可以通过分层集合,就可以对整个语义进行形式化分析,但是对它的内容这块抛开,因为它内容这块涉及到语言哲学,涉及到语言哲学的交叉地带,那么这一块语言学是个理性的反思,对各种各样的话语进行反思。比如说维特根斯坦的语言游戏实际上应是言语游戏,现在明确应该是言语游戏,不是语言游戏,因为索绪尔已经探索了,每个大师他都是有顶级成果的,也就是索绪尔之所以能成为语言学之父,不是简单的,他有几个基本区分,第一个最根本的就是语言和言语的区分,然后有一串串区分,五六个区分,奠定了他的普通语言学。但是为什么索绪尔在有生之年没有出版他的普通语言学教材书本,他就讲了三次课,也就是他还没有拿定,说白了他还在探讨的过程当中,就像我们要出版新版融智学,我们要先讲课,为什么讲课?讲课就是一个话是要说出来,然后再反馈过来,再不断的去完善它,因为表达,是要让别人知道,不仅仅只是自己清楚,自己清楚就不用讲课了,要让别人去让千千万万的人清楚,这可不是一个简单的事情,是吧?所以说与这里它像我们这里最后就发现我们这个工具就很管用,就是我们把分类集合,有标志集合、有属性集合,有特征集合,这就和各种各样的语言学流派,这个语言哲学流派就找到了对接点,因为,复杂的地方在派生对象在语这里,但是在形式这个角度它们都很简单,基本形式就是单音节、双音节和多音节,后面,我们结合例子会讲典型案例就是自然语言和机器语言两个典型,自然语言我们选了中文一字、二字、三字这个关系,同样数字也有一字二字三字关系,所以说你看这个模型相当的理想,我中英文都交流过相当的完美,这个是一个得意之作,有这么一个模型,就把语言学和语言哲学和现实生活当中的语言和理论上的语言认知的探讨,形式的探讨,计算的探讨,非计算的探讨等等统计的都有定性的东西,就是说学科之间的界限给划清楚了,最关键它有个基本概念体系的框架就奠定了一个理论体系,它得有个基本框架是吧?基本范畴基本概念是吧?只要奠定范畴是基本概念,基本范畴是范畴更根本的东西,是吧?所以说,一定要在这上面来突破。有了这个东西以后,同时它也是个架构,从方法论的角度,它有四要件,研究对象、学科性质、基本概念、基本方法,这个模型就已经浓缩了,单把这个模型讲透就已不得了了,它会产生很多东西,这是一个高度凝练的东西,点到为止。好,那么这边我们给了一个我们在融智学的导读里面给过一个图1-1,这图个1-1是什么意思呢?是我20多年前做的也就是20年整整20年了,做的什么?一个言和语的关系数据库,也就是说,我把汉字汉语表达的词放进我的库里面,然后不重复的汉字得到一个双列表,从到做就按拼音字母来排,每一个汉字不重复的给它一个唯一的ID,计算机就帮助我就给它赋值,计算机就认数字,我们人就认汉字,发音方言可能有多个音,是不是?就另外再外挂,外挂它的语音库,是吧?另外对它的解释,外挂它的词汇词,词库,根本的根据性的基准参照系就有了。有了基准参照系以后,然后我们把一字组、二字组、3字组到4字组及多字组,把它一分出来,这样就得到一个以中文为例的全球语言定位系统,这是我2002年完成的,在北京大学完成的。这一个全球定位系统它价值连城,从某种意义加上它的理论,它是无价之宝,它任何一个局部调用都可以对大中小学的语文教材,语文课程,所有人写的文章,所有人说的话,进行颠覆性的协作和重构,可以得到一个AI辅助的强大的背景。为什么可以得到呢?我的ID是十进制的,所以我这边给了一个表,是吧?计算机只能二进制的,而且计算机在10进制转换还有一个8进制,它为了转换的方便,它还有一个8进制,为什么有个8进制?因为在计算机的国际标准底层码的时候,它是8位来排的,是吧?另外为什么还有个16位,就是因为ASCII码是标准,所以我举了这4个例子,将来就是多种进制之间的换算关系的实例的一览表在这里,广义双语支撑的三类双语的数据库,这三类双语实际上就是我全球语言定位系统的一个应用场景,就是6大应用场景,3组6大类,为什么叫六大类?狭义的双语举例,例如英汉双语成为翻译的应用场景,另类双语专家的话和老百姓的话就是知识常识的应用场景,广义双语算术和语文,这是人机交互的应用场景,这是三大应用场景,三类双语。这样,回过头来就理解言和语的关系,在系统工程融智学特有的双重形式化数据库里展现,它们是可检验的。导读的时候,我是这么讲的,就是说,语言学创立者索绪尔不仅区分了语言和言语,而且还发现了语言与棋的系统的相似性。语言就是棋,棋就是语言,就这一块,我做了深究,如果你把语言当围棋,尤其是汉语,把汉语的字作为基本单位明确以后就非常明确每一个汉字就是一个棋子,所有的汉字,即n个汉字或者换成p个汉字,就完全满足了算术的p进制,它就是一套p进制,在数学上、算术上,这样它就可以和任何一个进制之间进行自动换算。于是计算机的批处理自动化处理这一块就打通了这个通道。那么这样再建立的超级计算机,那就超越了任何时代之前的计算机,也就是说这一块批处理自动实现。唯一需要的一点就是这三大应用场景的帮助。在这三大应用场景的帮助下,可把我们人类的语言思维能力,知识的创造能力和这种软件的创造能力这三大应用环境结合来,也就在这种人机交互的过程当中,可以把未来的近未来的新型的超级计算机这个底层操作系统,整个BIOS系统到底层上面的操作系统乃至各种各样的应用系统,整个颠覆了,它是这么一个概念。事实上它就是棋就是一个超级棋,所以说,我们把超级的全球语言定位系统,把它重启,很多人不懂,哪有那么大的棋盘,展开有多大,康熙词典差不多5万个汉字,你展开5万个汉字,你做一个字典,一个房间都摆不下,你一栋楼都摆不下,只有在计算机网络时代,才能敢想这个事情,才能实现这个事情,也就是说,我才把它做出来的,就这个小小的U盘上,就可以把它装上,是不是?这是什么概念?是吧?把它放在云端,所以说,我伯克利大学的校友,也就是专家认为它很值钱,但是很多人没有看到它的价值,没关系,我没有功夫去管,我们继续往前走,这不仅为融智学奠定了再进一步区分言和语的理论基础,而且还为汉字棋和数字棋的结合而形成双字棋,发挥了积极的启迪作用。也就是说智能化双字棋盘软件,三类双语应用场景将在第三章专门系统的来介绍。我曾经做过几个实验,带了本科生,带了硕士生,带了博士生,做了一些局部,都是211和9 85学校的,但是他们只能在一个局部理解这种超级棋,他跟不上,为什么?一个人太年轻,知识不够,是吧?他们老师专家也跟不上,为什么?因为,在既有的教学体系,不会把八大学问十大学部的知识贯通来思考,不会,你这么做,他们会把你当成疯子,你学那么多知识干啥?没有必要,你看他们是完全是为了用来学,当然没有必要了。所以说,最大的学问是无用的学问,无用的学问是最大的学问,所谓无用的学问是什么意思?就是说你无用才能大用,是这个概念,就是说不要去考虑太过于具体的运用目标,当你整个知识全线贯通以后,你回到任何一个点上,把相关的约束条件一加上,它就是大用,比如说,我的智能化双字棋盘,它就把这三类双语,很多人不明白,我当时带的博士生他也不明白,但是最后让他翻译也翻译不了,我要亲自翻译让他来带他还是不太明白,是不是?我想他现在都不太明白,他如果再重新听课,慢慢去思考他会好一点。为什么我这三类全部当时我都在考虑,我当时是一步步的走来的,几十年走来的。现在我今天讲这个课非常明确讲,它这三类双语实际上就是三类双语的应用场景,刚才我讲到这样形成一种协同,那也是到最近也不能怪他是吧?当时我也考虑也也是局限到有些点。直到最近我们讲发了顶级文章,各方面文章出来以后,把这种顶级的突破以后,就是人类三大奥妙之最突破以后,才发现:语言、知识、软件这三重性是人脑电脑都需要遵循的。那么在人脑电脑都要遵循的这三重性上,三大基本定律上突破,自然就整个前途就光明了,思绪就畅通了是吧?所以讲到这里了,点到为止,我们往下走,我们还是在第一阶段是往下走一点, 人机各自的语言特点,我们从这里来讲,人的语言特点是什么呢?言和语的关系以及人类语言有组字成语的典例,汉字汉语。这是我早期概括的,就是发表在北京大学出版社的世纪大辩论的论文专著上把它介绍了,其中这篇就是邹晓辉对汉语下的一个定义。汉语是一个组字成语的典例系统,引入了法律的思维,典是法典,例是案例,实际上语言是一种行为,它不仅是思维,它是思维的工具,也就是人说话是一种行为,是一种言语行为。这种言语行为在调用语言的这种言语行为,它是有典可依有例可查的。它的典和例怎么把它总结出来的呢?我们总结的人能够懂得8言8语,是吧?机器只认数字,不懂人类的系统。语言、语辞、语链、语块、语读、语句、语段、语篇8语就出来了。这里要感谢我的老师了,我的老师他就区分了字辞块读句5个结构单位。我就跟他讲,我要增加一个链,他说可以的,他说他这都还没下定论,可以增加,我说把整个虚字组构成的叫链。我的老师徐通锵在世的时候,他会讲他可以他肯定我说把这个辞因为我的老师已经把它讲明确了,就是实字组成的就叫辞你也对应上了,但是这个块就是虚实结合的就叫语块,这样就在短语这个层面,在词汇和短语这个层面就汉语,和西方语言不一样,但是又能对接,是吧?西方有实词,有虚词,有短语或者叫词组,这块在 Word和在phrase这个层面就对上了,但是由于汉语它的早期的汉语它没有词word是从西方引进的,所以说在汉语这里就混杂了,就乱了,它是用汉字表现出来的一个多国语言,也就是说现代汉语实际上是一个多国语言,为什么?人们不理解他只是用汉族的面孔呈现,汉语的发音拼音呈现,实际上里面很多内容都是外来的舶来品,是吧?不仅是像那种坦克、卡克这样的早期的实词,现在的这种computer,这都是舶来品, computer是一个词,中文用三个字叫计算机, computer又叫电脑,中国的电脑和计算机就两个词在英文当中一个词computer,但是实际上在中文思考的不一样,中文思考电脑它是比喻是像人脑一样能有思维能力的,是从人工智能这个角度考虑的,计算机它就是一个工具,中文它会有自己的理解,比如讲很多东西你就慢慢去谈,比如宇宙飞船这个一个单词,比如说飞机我们两个字,人家一个词,是吧?很多知识都是外来的,所以严格讲这些都是外语,只是用了中文表现,所以说,翻译把这个东西让人偷了懒同时也让人把思维给断了。所以说严格讲每个人都需要形成一个双语和多语思维的方式,实际上我们已生活在一个多余的空间,是不是?全世界的语言我们要搞人类共同体,人类共同体什么概念?就是人类的语言的一个大杂烩的观念体系、语言体系、思想体系、知识体系、交融的一个东西,它现在还没有依据,我们来找它的立法依据,找出它的典和例。我们这里找汉语的,是吧?我们汉语的语就给它树了一个例子,就出来了,我们的发言就给它典,就给它出来了。比如说我们把单音节的字叫音字区别于字音,如果讲字音是对音素和拼音语音去研究,英语我们讲语言,我们讲音字是讲单音节的字,我们对它的内部的这个字的内部,它有语素是文字,它有偏旁部首,就是文字学的研究对象,但是我们所以说它叫字形,是文字学的研究对象,那么形字它是语言学研究,所以,在区分上就帮助我的老师化解了一一对他始终困扰的问题,人家说你临了临了你怎么语言和文字、语言学和文字学都区分不了了,实际上我们知道他大脑里面是认真区分的,他把语言学和文字学认真区分,只是在这里没有表述清楚,因为他如果用字音、字形、音形意,这就搞乱了。这个意义是什么?是意象,是词典学的研究对象,这个音是语音学的研究的,你看我的画法它也不同,音字、形字,都是言的一种形式,实字,虚字是言的形式,象字、实字是言的形式,用字、解字是言的形式,因为,它是八言,但是它的这个音往下走,它的音节到音素到语音,这是语音学的研究对象,是吧?从形到部首笔画到字就是文字学的研究对象,你看,它不一样,分开了,实字讲的是语义学的研究对象,虚字实际上是语法和语义关系研究的一个突破,语义和语法在这里有交叉,所以说,进一步的它有形式和内容,这也是国际上一直没有突破的。我们这里在后面会讲到,象字它是语言学,是我们的语言的一个特例对象,语言就象字简称,解释语言叫释字。汉字它可以这么来,语言有很多规律,语用学的研究对象用字,义项辞典学的研究对象解字,这就是音字、形字、实字、虚字、像字、释字、用字、解字。这八字实际上是八言,这个字是语言的特例,因为这是语言学,就不强调字,字只是载体,所以说,一强调就会把它和文字给搞混淆,所以说我们叫八言不叫八字,讲八字你又和算命的八字又搞混了,八言就很准了,八言八语非常精准,基于融智学的语言观提炼出来的八言八语基本研究对象就和派生研究对象的关系的清清楚楚,是吧? 微观语言学、中观语言学乃至宏观语言学,整个语言科学体系就提起来了,纲举目张,八言八语,基本单位就明确了,是不是?基本单位结构单位派生单位都清楚,它和虽然有了学问怎么对接,释字对接的解释语言,是吧?象字对接的是对象语言,用字对接的是微观语用学,它有组辞法,虚字对接的是语法学,实质对接的是语义学,是吧?这就很清楚了,对吧?这就一下子理解了这8种字形形式对接的是内部语素,字形对接的是笔画,拼形造字是文字学,音字对应的是音韵学,它是语言学的范畴,再往下字音是对接语音学的音素和拼音,你看,这就划分了,把这学科的界限能划分,这就叫立法了,是吧?也要给立法,给语言去的言语运用,被人们调用的过程要给它立法,将来辞块链足够,相当于西方语言学的构词法和词法的部分,那就形成了。内部语术这里也是属于构词的范围,所以在下面平行造字属于文字的范围,你看这个图思维导图写的,那时还没有思维导图软件,我自己做了。那会儿思维导图什么知识图谱还没这个概念,是吧?我们已上来用了,所以说很多东西事先就都用了。这样虚实结合的这种外部语术,这是块的构造办法,就是在继承当中求发展,这样把下面的句法这里就就很清楚了,就立法了。段和篇有章法,起承转合,2009年在上海举行汉语独特性和汉语教学的国际会议上,我就特意讲了,古代汉语它有字法有章法就是没有词法和句法,没有,如古代汉语句号都没有,它都是逗号,一逗到底的,是不是?要私塾先生来断句逗,我爷爷就是一个私塾先生,古文没有词法,因为它没有word这个词的概念,它是引进来的,词法句法这一套属于西方语言引进来的,它是不一样的,所以说我们现在是生活在一种杂多的世界里,这种杂多的语言现象它需要立法来解决它,所以它需要,语言和言语是两个范畴。我就讲到这里,这样就把上面的八言八语再讲一句,机器是怎么看呢?机器人通过人机交互界面是最能体现,因为机器只是数字,我们最优化的字库原理,我解剖了现有的字库以后,做了一个分析,于是,我定义了两个概念,一个叫线串性结构的字,一个叫层面性结构的字。我的老师非常欣赏我这一点,他说你这个好,你这个和我其他学生的观点都不一样,你这比我的观点都发展了,你区别得很清楚了,就是说语言学的字是线串型结构,它的特征是言,是单音节;层面型结构的字是文字学的字,它的特征是由笔画和偏旁部首组成,于是,我这两个结构就得到了两个数据库,一个就是线串型结构,它有个节点切分这两个交叉就是语言文字产生叠交,这个层面型结构,一层一层的主义的义,我给它解剖三个笔画,两个笔画,一个笔画到点,你看到一个笔画都没有,就给它进行了分层透视,它是透视,这样这是一个造字的过程,字造出来的每一个字都可以这么透视,然后把这个字结合起来,用它是个语言的过程,非常清楚。这边这个是我做的超级的言和语的关系数据库,所以说就言单音节的字和语混音节的字组的关系,这种结构化数据就提炼出来了。后面做这个东西就是水到渠成了,当时我做得很顺,一个人就把它完成了,海量的工作在机器帮助下就完成了,举例,往下走,就是人机各自的特点。 我们讲第二节言和语的形式化理解,走到这一步,前面是讲到人脑的这一块,觉得要开始往电脑方面转换了。导读的时候我是这么写的,形式语言学和形式语义学的先驱塔斯基,波兰人后来也到了美国伯克利大学,区分了对象语言和解释语言,解释语言另一个翻译又叫元语言,你看这个翻译解释和语言是不是就是中国翻译它这不一样,现在的这种元宇宙的元也是这个元是吧?一元人民币的元也是这个元,有没有歧义是不是?但是元宇宙的元和元的意思是相通的,就是启迪了融智学创立了言和语的形式化理论。首先以汉字汉语为例,把单音节的言及汉字视为对象语言,就开始往计算机过渡,进而把混音节的语即汉语的语视为解释语言即一系列的元语言,所以元宇宙可以有一系列,但是,唯一的宇宙只有一个。这就理解了元也就是一个,但是你也可以n多个,结合克莱尼的小字符串的形式理论,克莱尼是图灵的师兄弟,两人都是一个博士导师。图灵是英国人在美国普林斯顿拿的博士学位,克莱尼和他是师兄弟,克莱尼曾经做过美国数学学会的会长,觉得数学技术很好,这些人都是对计算机早期发展作出重大贡献的人。他的小字符形式理论很多人不了解,它是决定整个计算机的形式化表达的基础及其典型示例。融智学定义了汉字汉语和数字数据,请注意汉字汉语数字数据,这个数据可以是字式图表音像立体活体八大形式体系,汉语不同,它只有这个字,有音字有形字,是不是?它有音有形它可以有八言,是吧?它有八言,还有八言特征是吧?这样的广义文本就是广义双语,对于这个东西这就为后面整个应用和跨学科大跨界铺平了道路,为后续定义孪生图灵机及形式化理解模型奠定了基础。来看下面两个图,这都是从我造好的库里面抽取出来做的,当时就间接形式化的基本的研制单据的字对象语言和派生的混音节的解释语言。
你看我这两个图很有意思,这是基于我做的库,为了说明我的老师他要我讲清楚要我去参加的国际国内会议,要我把我的观点告诉同行,好在这个都已经是正式出版了,这正式已经在08年就出版了,一个是07年,一个08年,是吧?这个时候这样才被推荐了参加2009年的国际会议,文章5年以后到2013年才出版,因为出版一般是5年的时间差。2004年的会议2008年出版了我参加2004会议的文章,我投的三篇文章一人只能一篇,我不能三篇,老师让我把三篇合成一篇,一般的人一篇就是几千字,我那个是2万多字,因为我老师要我把它压缩成15,000字,后来说给你2万字,压阵的一篇文章,最长的一篇文章,从它取出很多图,这里就讲,你看,我这里就把文字学的字和语言学的字,即层面型结构和线串型结构表述得清清楚楚。也就是说这种线串型结构我就用了一个排列,层面型结构用另外一个排列,这样我就造了两个库,这两个库的关系就清楚,到这里就不多讲了,因为这个是操作性的,所以当时很多文章的审稿的看着文本不太好懂,尤其是文科的教授看起来更费劲,纯理科的也不能一下子都看得懂,纯理工科的他就跟现有的计算机体系他也不太看得懂,他看到一部分,所以说这样,这就是我的研究成果为什么它的推广会相对缓慢,也就是说越大的突破推广会越缓慢,这个到了我这个年龄已经能理解了,深深地理解这个道理了。它推广得缓慢,但是在推广,它普及得缓慢,但是在普及,这就说明什么?它有用,它好,而且,他真正是找到了关键。你看一看,双列表很特别,是不是?你看红颜色的字它这个关系,你看我把字做了一个区分,笔画字、损形字、变形字、字中字、标准字,其实我给它立了一个法,分了5类,按人来讲给它分5类,但是如果按电脑来,就是一笔画二笔画三笔画,它是这么来的,所以说我现在就可以分到01234给它分5个数据库5个表,再在上面,然后我才产生了它的后面的字,是吧?言辞链快读句6个,是吧?加上这4个,加上1234这就10个,加上0即11个,加上后面的段落和篇章,13个表,当时我这13个表是震惊了一批老专家暨中老专家的,在微软研究院做了交流,黄昌宁邀请我去,然后清华大学北京大学都做了交流,做专门做在北京大学俞仕文老先生感谢他邀请我去,所以首先我的老师就不用说了,支持我,已经发表了,现在我的老师徐通锵,还有我的师兄妹,然后在清华大学在张钹院士的团队,陈群秀陈教授也邀请我去,然后袁春法教授还给我写了一个很好的评语,鲁川教授中国中文信息处理的专委会第一任的主任,鲁传教授也给我写了很好的评语,所以说这是很有意思,就是要专家认可,专家认可是小众的,大众认可程度,到现在回过头来看这个东西已经很成熟了,完全基于它,如果大家理解了商业来做自然语言理解,再来做自然语言的深层对比,那就完全不同了。当时也没有经验,是吧?一个是学术交流,一个在现场做那些软件的,那些具体卖电脑的,都不卖软件的,不想这么多的事情,都急功近利看眼前的,不管是国内国外都这样的,所以说这个事情被耽误了。不过还好我自己做了一个根本的东西,我已经完成了。这中间的过程当中,很多人不明白,不过没关系我也给他们打太一级拳,一个点一个点地来检验,我就把它当成一个游戏,不要带功利目的,于是,到现在为止,彻底的清楚了。 形式化理解的双重形式化特点 把它凸显,尤其这篇文章是一个划时代的,a库b库c库 understanding model a,understanding model b,understanding model c这三个模型一出来,三对孪生图灵机奠定了国际标准,也就奠定了未来的人机协同的国际标准,这个图再附上表和思维导图。这里我讲一讲:为什么说它能奠定?比如说,三对孪生图灵机,其中一个叫图灵机,图灵机是整个数字计算机的标杆,任何计算机都达不到,图灵机是理想的计算机,它是物理和数学结合的产物,是图灵脑袋里设想的:什么东西可计算,什么东西不可计算,它这个计算是和操作结合的,他拿一个两头开放的带子,它是一格一格的,然后,他拿个读写头去读和写,把它写上一个0或擦掉写上一个1,就这么一个操作的过程,把它设计成一个机器,这就是最原始的理论计算机原理。冯诺伊曼给他加上一个存储系统,所以说,为什么现在的数字计算机叫图灵冯诺伊曼结构,它有CPU,干什么?高速运算,它有内存块,里面又分了几种,一种是瞬间暂存,你关机就不存在了如内存条;另一种是关了机还还存在那里的如BIOS就植入进去即做成了芯片,还有硬盘,移动硬盘,外面U盘和光盘等等,通过这些途径,数据存在外面让它来调用,但是核心的操作的底层的东西,它是要植入芯片的,也就是我们买计算机买来的时候,实际上它的底层是设计好了的,它的BIOS是植入芯片的,你只要是懂BIOS,你会这一套模式,任何计算机裸机拿过来,你可以装任何操作系统,甚至你可以自己编一个操作系统,我做过实验,还在几个国家做了对比,所以,我很有信心,在临界点突破以后,就是极限以后。 还有一个阶段就是我的老师塞尔,他是个奇葩天才,他的语言非常流畅,他在美国威斯康星本科就得到奖学金,到英国牛津大学拿了哲学的博士学位,他在上世纪1980年发表了一篇顶级文章,奠定了强弱人工智能的区分的基础。其中有个典型案例就叫中文屋论题Chinese room他是一个不懂中文的人,即中文只懂一点点皮毛的人,却因为中文房间这个假设这个命题而闻名世界,全世界计算机AI前沿的人都知道这个事情即知道图灵测试的人暨知道他是计算机科学界、人工智能学界和心智哲学的创始人,从语言哲学到心智哲学的创立,创造心智哲学。人机这两个极端,我把character放进孪生图灵机去做双重形式化实验,从而就把塞尔老师的中文屋给形式化地创造了出来。 我造了三类孪生图灵机涵盖了一系列的中文计算机,就是这个意思,只是我这个是理论的,我这个也可以说还不完全是理论,因为它们是可用的模型,是以数据库的形式来体现的。 如果从底层到自己的数据库,那么操作系统就是我们自己的,举这个例子,接下来我就得了两个极端,一头以算术语言为标杆,图灵机是代表,另一头以自然语言即汉字中文为标杆,形式化中文屋是代表。图灵和塞尔分别代表两大类人,一大类是理工科思维模式,一类人是人文学科思维模式,当然他们有交叉,但是主要是一个方面。于是我站在这两个巨人的肩上,这两大类人的肩上,就全世界的人文和理工两大类思维模式的巨人肩上,就提炼出了 ABC三个思维模型,三个形式化理解模型,第一种模型全部是由01数字暨机器语言做图灵测试,分分钟通过,也就是说,人工智能如果在算术领域还没有计算机,刚一想出来就已是世界上最牛的了,无人能替代。所以说,你怎么造?它是个标杆,因为,图灵做了三个事情,一个事情就是破解德军密码,两个标杆,一个是发明了图灵机,一个则是创立了图灵测试,假设塞尔就在图灵测试基础上不用英文,用中文来测,就假设你通过了,C模型实际上就是我把塞尔的这套对图灵测试的理解造的形式化中文屋,中间这个B模型是我自己的新模型,它可以把字式图表音像立体活体全部放进去,做图灵测试,因为人工智能的标杆人工智能怎么判定,要通过图灵测试来判定,不仅仅是文本的输入,我就把它从自然语言扩展到文本语言,进一步扩展到了广义语言、广义文本和广义声音,突破是很大的。
再讲一讲言和语的形式化理解,我就把这个ABC三类模型用了全等于、约等于和相似于,用了数学表达,很精准,它的底层全部是01,这个设计很巧妙。Number,Symbol,Character分得很清楚,就不多讲了,表达得太清楚了,如果你还不理解就是相应的知识不够,要么就重听,书读百遍其义自见,要么就扩展一点知识。我们讲这个图1和图1-2的a那边上上面我就用p进制,我用了一个全称变量,是弗雷格的全称变量,还有一个存在变量E反过来,全称变量是大写的字母A倒过来,这样我就做到一个什么?就分别用于对狭义和广义的言和语的具体符号形式的枚举表示。为什么要讲枚举?计算机最大的特点是可枚举,可计算,也就是说枚举计算操作算法是一回事,从不同的角度或层面表达的,不同的角度表达的。 首先我就对双重形式化的特点的理解,进而才便于对微观的言和语的关系数据库的理解去推。前面那个图我已经造出来的,最后才便于宏观的理解全称量词符号和和存在量词符号,分别用于对狭义和广义的言和语的具体符号形式的枚举表示。其中A库即全球语言定位系统GLPS是打通各种进制之间符号体系相互转换的关键和枢纽,第三节连贯起来讲,这里点到为止,上面,我用了10进制的自然人、二进制的计算机,16进制的美国标准信息交换码,所有的进制的就是z标准即中国标准,中国标准就是z标准,实际上就立法了,法和典给它立起来了,自然语言计算严格立法,将来全称变量它直接就按一系列平均值来算,就涵盖了所有的存在量词,存在量词就是言语的调用,也就是平均值以内的,它就是对语言的,把它枚举,这样一下子就把人和计算机两者的优势给它定得准准的,怎么用才派生出各种各样的典型案例。 宏微贯通来谈谈,我把库放在这里,这里有个宏观模型,三类思维模型,这里来的一个语言模型,中间有宏微贯通的整个历史发展过程,最早我脑袋里的七个汉字概括的人类整个知识的顶层分类模型,图1-2,第一章第二节的内容,言和语的形式化理解,这个核心是算数的数字和中文的汉字的类的定义,在语言模型里面就定了宏微贯通,言和语的形式化理解涉及到宏微贯通的颠覆性创新。关于颠覆性创新,在去年我专门有一讲,实际上讲了两讲,一个是颠覆性创新能力,感兴趣的人可回头去搜一搜,听一听,有些不清楚可以问我,我可直接提供链接。全称量词,它所记录的是所有汉字的ID构成的集合,正好和p进制的数字集合等价,这样的假设以及已在言和语的关系数据库中验证并证成,由此就得到了全球语言定位系统GLPS的特点是宏微贯通的。简单的说就像微观物理学它包括宏观物理学,宏观不包括微观,适于这个图1-2的b所示的左右两方面分别对应的内容信息和形式信息,忽略它们就会陷入语义泥潭,即遭遇最大的歧义而难以区分,试问:方方面面的专家都区分不了的语义内容的分歧,如何让计算机 AI来区分?不可能的,何况AI擅长的是语义形式信息处理,因为,本质上,AI只能做形式化理解,提示语法形式和语义形式具有一致性,但在内容上却不具有语法内容和语义内容的一致性,它不完全具有一致性,很多地方是没有一致性的。点到为止。 第三节言和语的关系数据库,导读的时候我是这么写的,在计算机辅助信息处理,不仅在中文信息处理过程中,而且在字式图表音像立体活体八大形式的信息处理过程中,都有结构化、半结构化、非结构化三类大数据。其中电子表格也就是结构化的数据,是本研究关注的焦点,为什么?把这个问题想一想,后面我会解答。例如我亲自实操建构的,做出来言和语的关系数据库,就用到了上述三节导读的关键内容,这里给一个标准:字式图表音像立体活体。
ASCII标准对数字文字小字符集做了普及,汉字的拼音和小字符是通的,但是汉字的笔画和它不通,所以,我们用了一个GB国标,国际上怎么办?不同语言,用了一个Unicode就是国际统一代码,Z标准把它一网打尽,相当于国际法或国际标准意义上的立法,法就有了,典在哪里?典就在我的库里选,言和语的关系搞清楚就立法了,有法有典,点到为止。 全球语言定位系统是个什么概念?就是说总库是全球语言定位,你看这个图我的三类双语是一个应用场景,调用它就产生了各种调用界面,C库可以换n多种形式,可以千变万化。这只是由老子《道德经》做了一个例子,这一段话非结构化的随意的自然语言文本,把它做成汉字棋是半结构化的;数字棋是纯结构化,三类大数据都可以处理。批处理和人机交互处理都非常方便,再调用它就产生各种各样的软件。它就像A库是GLPS,B库是GKPS,C库是GSPS,D库是GHPS硬件全球定位系统,总库最根本的是全球语言定位系统,这个地方突破之后,在它后面就是调用它就产生了知识,再把它本体化虚拟化去做各种各样的本体展示,就构成了全球软件定位系统,它的分库可按各级各类识字教育的识字量设定,如果说识字量是基础,那么词汇量和短语以及各类术语乃至俗语的数量,在形式上就是派生的,因而,均可自动化生成与采集的匹配即可统计学习,这是什么概念,就可机器学习,就可深度学习,就可自动编程,将来把人机交互和自动编程,把基于规则的编程方法和基于统计的编程方法就对接了,图1-3的言和语的关系数据库是全局的独立完成,它的应用是局部的可经过多类研究验证,可以产生n多种无穷无尽的,所以说 GLPS它不仅是基础,而且还是枢纽甚至是关键,因为它调用通过人机交互、协作、互助乃至协同或批处理而构建出全球知识定位系统和全球软件定位系统,它们将在接下来的第二章第三章分别加以介绍,最后一句话总结,就是把脑和智的二元结构,语言、知识、软件即思维的三重性,抽象为2+3结构,这种颠覆性创新就在于它不仅颠覆了旧的脑智观,而且,还颠覆了旧的软硬件观。 今天的主要内容就讲到这里,下面是参考文献。后面对参考文献的每一个的摘要进行了讲解, 在这里你看徐通锵徐老师对我的研究,这里他有几段话,他引用了赵元任(他曾是美国语言学会主席)汉字汉语是没有词的,字是中国人心目中的中心主题,这是附录一致谢我的老师。附录二就介绍了我的字和词的义项分析,探寻了汉语研究的逻辑起点,“与其说是字本位,不如说是言本位”,扭转了乾坤。把这种非学术性义项导致人与人之间的零和博弈,互相不卖账。什么字本位、词本位、句本位,各种本位搞得一团混乱,人都已经去世了,还在那里混乱,后面的人也搞不清楚。我就把它区分了学术性义项和非学术性义项,日常的常识一样区别,常识领域一定是众说纷纭,到了学术领域还会众说纷纭,但是学术领域的众说纷纭和常识领域众说纷纭,稍微有点不同,学术领域的众说纷纭,都是你要持之有理,持之有据。常识里面的这种义项也分两类,持之有理,持之有据,没有办法再去乱说。所以,这就需要把各家各派,学界各派代表在这里都有了,我就不再点名了,这上面文字说了,都表示致谢。 附录3,重点讲一下我所到过的大学和学界的支持者,这个是我的一种基于双语自动转换的间接形式化方法,是我的一个发明。我也不多讲,我主要讲人类语言学研究发展的历史,也就100年左右,对中国来讲从《马氏文通》开始引进西方语言学的观点,当时马建忠把词叫做字,因为中文里面没有词,他就把词叫字,他就把word翻译成字,实际上是一个错误,后面就以谬传谬了,但是他做了一件漂亮的事情,他就把这种过去的中国人讲读经典,他就对很多句子几千个例句,他就借用西方的语法学来进行了分析,那么后面有几个人继承了他在那基础上有了发展,一个是毛泽东的老师黎锦熙,他写了一个《新著国语文法》,提倡的是句本位,他发现英语是句子基本单位。实际上后来我的老师告诉我英语是双本位,是词和句两个基本单位。到了朱德熙《语法讲义》提出词组本位或短语本位,他从美国语言学里面学的东西结合中国进行了分析,发现汉语的词组和句子是等价的,它的结构很多地方是相似的。到了我的老师这里已经明确提出了字本位,在其基础上避免争论,我就把它升华为言本位,为了避免大家在文科圈子绕不出来,我就做了一个对象语言和解释语言的关系。从古至今中国都是以单音节的字为基础,来构造辞、链、块、读、句,中国的词和西方的词(外语叫word)是做不到一一对应的,这是自然人大脑的思考方式。 下面我从自然语言的形式信息处理殊途同归,从这个角度就是人机互补双脑协作这个角度,古文的字就Zi拼音,现代汉语的词Ci是中文的,英文就是word,计算机电脑的,从理论上划分,然后,这边我把字分成一字、二字、三字、四字、多字,它整个形式化推演关系画了一个图,根据我做的库做了一个抽象,字ID就是形字和音字做了区分,形字是层面性结构,是文字的符号处理,形字以上的音字是线串型结构,是语言的,不仅仅是和美国标准对接,和世界标准对接,而且也是中国标准的一个未来模式。
然后下面附录4我再讲一下这个图,这是我的间接形式化方法与间接计算模型,我在这里找到了一个基因文本,即:发现了文化基因及其系统工程的形式化表达方式,所以这里做了两个典型案例,一个是数字语言即机器语言的,一个是汉字汉语自然语言的,两个典型案例,分别都有:单一集合、分成集合和标志集合(或者叫属性集合叫特征集合),它们都能够用三类孪生图灵机自动处理。于是,这个基因文本分了子全域、超子域、目标域这些等等,它是一种概括的方式,这样就可以化繁为简,以简预繁,于是,得到这几个方程,一个方程实际上是一系列新狭义信息方程的应用,点到为止。 附录5,大数据与人机对话:语必在言的结合里选取。 三类孪生图灵机的形式化理解标准,然后,对基础的库,对研发有关数据库,就看出来这里整个理论上,清清楚楚,实践上也可以兑现。顶天立地,这条路就通了,也就是工程融智学的第一章,言和语的关系数据库,到此就讲完了,谢谢收看并聆听,各位再见! | ||||
https://wap.sciencenet.cn/blog-94143-1421390.html
上一篇:[转载]新版融智学2023春讲授2024春回访
下一篇:清华大学雨课堂公益课融智学导论系列讲座直播音频:融智学导论(上,中,下)