博文
细胞标志物数据库:singleCellBase
||
细胞标志物数据库:singleCellBase
单细胞技术的发展为细胞异质性提供了前所未有的见解,在理解生物系统的内部方面取得了进展。这项革命性的技术使我们有更多的机会以单细胞分辨率来阐明不同组织的复杂细胞组成,这比生物样本中的大量细胞收集更具优势。单细胞RNA测序(scRNA-seq)已经阐明了从免疫学到肿瘤学的细胞间异质性,有助于追踪原始细胞的起源和谱系,以及提供恶性造血的高分辨率剖析。scRNA-seq数据分析中的细胞类型注释(阐明细胞群体的细胞类型或细胞状态)是研究人员最具挑战性的任务之一。细胞类型注释的常见方法通常包括自动和手动细胞注释。自动细胞注释速度更快,但对子类型无效,并且并不总是导致高分辨率注释,如SingleR、Cellassign等。然而,手动细胞注释总是费时费力,并且非常依赖于先验知识。最近,Clarke等人推荐了一项分三步进行的工作包括自动细胞注释、手动细胞注释和验证。在这种情况下,手动细胞注释似乎是不可替代的,通常被视为黄金标准方法。
细胞类型注释的任务至少有四个关键挑战。首先,细胞类型注释费时费力,需要全面的文献综述来扩展细胞类型和基因先验知识。对于不同细胞类型的标记基因没有深入了解的用户来说,这似乎是一个非常耗时的过程。其次,对后续分析的任何修订(如轨迹参考、细胞间通信和参数调整)都需要手动重新评估细胞类型注释,这是整个研究的基础。第三,注释不容易在独立实验室生成的各种数据集之间迁移,经常导致重复努力的浪费。在不同科研团体内,数据规范任务很难就标准工作达成一致。最后,尽管存在细胞类型的本体,但注释标签通常具有特异性。我们仍然缺乏将这些本体系统地应用于scRNA-seq数据的工具和经验,从而实现前所未有的单细胞分辨率。总的来说,这些挑战阻碍了细胞类型注释共识框架的进展,该框架依赖于定义它们的标志性基因。目前为止,具有手动细胞类型注释先验知识(即标记基因和细胞类型的关系)的数据库包括PanglaoDB、Tabula Muris和CellMarker,它们都只包括人类和小鼠。
目前,标记基因和细胞类型之间的高质量、已知的关系极其有限,尤其是对于除人类和小鼠之外的多种物种。在这里,介绍一个新数据库:singleCellBase(图1,http://cloud.capitalbiotech.com/SingleCellBase/)。该数据库是一个包含多个物种的标记基因和相应细胞类型的数据库,综合收集了9027个条目,涵盖2610种细胞类型与21,044个基因(细胞标记)相连,以及涵盖33个物种的381种疾病/状态和524种组织类型。singleCellBase将有助于研究人员精确注释感兴趣的细胞类型,并进一步揭示scRNA-seq研究中特定细胞亚群的生物学功能。
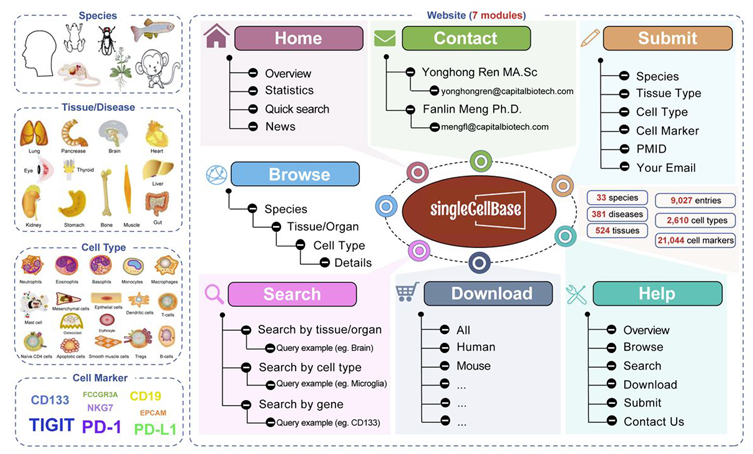
图1 singleCellBase基本框架
参考文献
[1] Meng F, Qin W, Liu K, et al. singleCellBase: a high-quality manually curated database of cell markers for single cell annotation across multiple species. Research Square; 2022. DOI: 10.21203/rs.3.rs-2039534/v1.
以往推荐如下:
5. EMT标记物数据库:EMTome
8. RNA与疾病关系数据库:RNADisease v4.0
9. RNA修饰关联的读出、擦除、写入蛋白靶标数据库:RM2Target
13. 利用药物转录组图谱探索中药药理活性成分平台:ITCM

https://wap.sciencenet.cn/blog-571917-1383886.html
上一篇:分子组织生物学的空间组成
下一篇:R神经网络包综述:准确性和易用性