博文
Angel:一种新型分布式机器学习系统|《国家科学评论》
|||

Reporting global advances in science
《国家科学评论》(National Science Review,NSR) 最近发表了由北京大学崔斌(通讯作者)、余乐乐、江佳伟联合腾讯蒋杰、刘煜宏共同撰写的研究论文“Angel: a new large-scale machine learning system”(https://doi.org/10.1093/nsr/nwx018), 介绍了一种新的支持大数据分析的分布式机器学习系统——Angel。
文章回顾了近期学术界和企业界关注的机器学习系统,着重介绍了Angel系统的设计思想和实现细节,并通过对多个大规模数据集上不同机器学习算法和系统的比较,验证了Angel系统在分布式机器学习方面的有效性。Angel系统的原代码已在GitHub上开源 (https://github.com/Tencent/angel)。
Angel是一个基于参数服务器(Parameter Server)理念的分布式机器学习框架,它能让机器学习算法轻松运行于高维度模型之上。Angel围绕模型共享的核心理念,将高维度的大模型合理地切分到多个参数服务器节点,并通过高效的模型更新接口和运算函数以及多变的同步协议,实现各种高效的机器学习算法。得益于其良好的设计,Angel既能独立运行、高效执行多种机器学习算法,亦能作为PS服务,支持Spark和现有的深度学习框架,为其加速。它基于工业界的海量数据进行了反复的实践和调优,具有广泛的适用性和稳定性,模型维度越高,优势越明显。
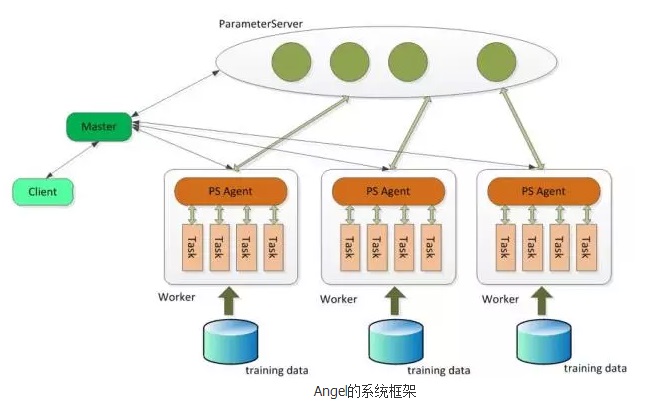
Angel的系统框架
现有的机器学习系统都是针对不同类型的机器学习任务而搭建的。数据流系统Hadoop和Spark适合通用的数据处理任务和构建机器学习流水线,但缺乏参数共享机制,存在单点瓶颈性能问题;图计算系统GraphLab、GraphX和Tux2等将机器学习计算抽象成图结构,可以利用图结构的特性进行加速,但只适合具有稀疏图结构的算法;深度学习系统TensorFlow、MXNet和Caffe2等利用Parameter Server或者Allreduce方法进行分布式神经网络的训练,其特点是能够利用GPU对神经网络的计算进行加速,但缺乏对稀疏图结构的优化和支持。
Angel在设计中对分布式机器学习的共性进行了抽象和提炼。文章认为分布式机器学习的核心部分在于参数共享,如果可以提供高效的参数共享机制,则能够为各类机器学习任务进行扩展和加速。因此,Angel提供了PS服务的能力,支持两种运行模式。其中一种模式称为PS Service模式,Angel只启动Master和Parameter Server,具体的计算任务交由其他计算平台(如Spark、TensorFlow等)完成,这种模式下Angel只负责提供Parameter Server的功能;在另外一种模式中,Angel还会启动Worker,由Angel负责完成模型的训练。Angel提供PS服务的能力,使其能处理多种类型的机器学习任务,提供更方便的机器学习开发体验。
此外,Angel还能提供:(1)多种参数同步协议,用于在不同的集群环境中进行加速;(2)易用且丰富的接口,用于方便算法的开发;(3)数据并行与模型并行的能力,提高算法的扩展性;(4)高效的容错机制,为任务在复杂环境中的运行提供保障。经过在真实数据集上的对比,Angel在多种机器学习算法上的性能优于XGBoost、Spark、Petuum、TensorFlow等常用机器学习系统。目前Angel已经被应用于腾讯视频点击预测和广告推荐等实际业务中。
Angel的开源系统由北京大学-腾讯协同创新实验室开发,兼顾了工业界的高可用性和学术界的创新性,已经在GitHub全面开源,集成和优化了Logistic Regression、SVM、KMeans、LDA、MF、GBDT 等多种机器学习算法。Angel目前基于Java和Scala开发,未来还会加入Python等多种语言接口,方便使用。将来,Angel的PS Service能力会得到进一步利用,支持图计算和深度学习框架。
文章信息:
Jie Jiang, Lele Yu, Jiawei Jiang, Yuhong Liu and Bin Cui. Angel: a new large-scale machine learning system. National Science Review (2017) https://doi.org/10.1093/nsr/nww065
作者介绍

崔斌
北京大学计算机系教授、博士生导师、网络与信息系统研究所所长。研究方向包括数据库系统设计和性能优化、数据挖掘、大数据管理等。已发表学术论文100多篇,其中50余篇发表在一流国际会议和期刊,包括ACM SIGMOD、VLDB、IEEE ICDE、TKDE等。主持和承担多个科研项目,包括国家自然科学基金、核高基项目、863计划等。担任中国计算机学会数据库专委会秘书长,VLDB理事会理事,IEEE TKDE、VLDB Journal、Information Systems、DAPD等国际期刊编委,担任过数十个国际会议的程序委员会委员,包括一流国际会议SIGMOD、VLDB、ICDE、KDD等。2008年获得微软亚洲研究院的“微软青年教授奖”,2009年获得中国计算机学会“CCF青年科学家奖”,2014年获教育部自然科学二等奖,2016年入选教育部长江学者特聘教授。
https://wap.sciencenet.cn/blog-528739-1065076.html
上一篇:系统科学丨于景元:从系统思想到系统实践的创新
下一篇:学科著作丨脉冲激光沉积类金刚石膜技术