博文
网络统计数据跟踪与智能甄别研究
||
张利华
(成都信息工程学院管理学院,四川610103)
摘要:统计信息作为与国民经济密切相关,对国计民生有重大影响的信息资源,是我国社会经济信息的主体,理应成为国家宏观决策和调控的依据。充分利用现代信息科技积极预防、规避统计失真,提高统计工作质量和政府统计权威,是目前国家统计改革的重点。本文在分析统计失真历史现象基础上,重点探讨了网络统计数据跟踪这种基于互联网的统计数据质量甄别策略的基本原理、智能甄别系统结构以及实施该策略的诚信激励等建议。
关键字:统计失真;统计信息化;数据跟踪;标签文件;智能甄别
[中图分类号] C816,C819
前言
统计数据作为认识论层次的统计信息,是人类对客观现实的量化反映,从原始社会的“结绳记事”到奴隶社会的“城邦纪要”,标志着人类使用数字、通过统计量化的方法来认识客观世界的开始。进入封建社会,统计越发成为国家管理的重要工具,成为封建统治者了解国情,评判封建官僚政绩的有力武器,但由于当时的大众传媒缺乏,信息传递技术相对落后,在利益的驱使下,利用对统计数据的控制来标榜政绩,以此满足地方官员自身升官进爵需要的现象层出不穷,天下相率为伪,统计失真现象屡禁不止。
一 统计失真是一种普遍存在的社会现象
统计数据作为与国民经济密切相关,对国计民生有重大影响的经济信息资源,目前已成为国民经济管理、各地党政领导政绩考核的重要依据。新中国成立后,20世纪50年代末,在极左路线指引下,为“跑步进入共产主义”虚报统计数据、浮夸农业生产情况。“文革”期间,强调“一切为政治服务”,把统计当成政治游戏,全国上下摊派产值、随意篡改统计数据的现象时有发生。
为更好发挥统计信息服务社会经济的作用,国家于1986年就制定了《国家统计信息自动化系统建设“七五”规划》,提出从“微机起步,由小到大,人机结合,逐步完善”的统计信息自动化系统建设方针。“九五”期间,在总结过去十年统计信息自动化系统开发经验,结合系统工程原理和信息科技最新发展动向,我国开始实施国家统计信息工程(SSIE State Statistical Information Engineering)。从系统工程的角度重新审视统计信息化工作,对现有统计信息化成果进行规范和系统化,初步建立以国家统计局为枢纽、连接64个节点的国家统计信息系统主干网络,有力地促进了统计工作的信息化、网络化。但2000年2月,伴随着1999年国民经济和社会经济统计公报的发布以及各地经济增长结果的陆续见报,统计失真再次成为舆论关注的焦点。引发了社会对统计数据质量和政府统计权威等方面的深层探讨。
从以上发生的统计失实历史观察,统计失真作为一种普遍存在的社会现象,其诱因主要有两个方面,一是存在主观故意,二是有客观环境的庇护。其中,客观环境决定主观故意,反过来,主观故意又影响客观环境,因此,要预防、规避统计失真现象,加强对统计客观环境的认识和改造是关键。为此,国家进一步加大了利用信息技术改造统计工作环境的工作力度,从统计信息工程基础建设入手,首先,利用先进的互联网技术对统计信息主干网络进行“提速”和“延伸”,成功开发网上统计数据直报系统;其次,重新规划并建立了具有较强抗干扰能力、独立的“国家统计快速调查系统”,以加强对统计数据真实性的审核;然后,利用基于数据库的信息管理技术构建了具有国民经济和社会信息资源枢纽作用的“国家统计数据中心”,形成规范统一的“统计工作信息化平台”,以期更好地预防、规避统计失真,提高统计数据质量和政府统计权威。
根据信息系统工程原理,要实现利用先进的信息技术改善、优化客观工作环境这一目标,组织管理体制特别是信息管理机制必须与信息技术的应用相适应,使整个组织管理工作处于高效、透明的发展态势。分析我国现行统计工作管理体制,主要采用“统一领导,分级负责”的集中型统计管理体制,该体制形成于计划经济时期并延续至今,从横向上看,政府综合统计和部门统计是平行运行的“双轨制”,彼此之间各行其职,联系并不紧密,统计信息化的加速很容易加剧综合统计与部门统计之间的信息分化,形成信息孤岛,因此,建立规范统一、资源共享的“统计工作信息化平台”是必要的。从纵向上看,上级统计部门只负责安排统计任务,而工作经费主要由各地方政府财政拨付,下级统计部门则负责执行统计任务,进行统计调查、分析、报告、监督,向上级报表、接受公众信息咨询,不难看出,由于经费主要由各地方政府财政拨付,在利益的趋势下,业务主管部门管理职能被相对弱化,使地方政府控制统计数据成为可能,难以保障统计机构、统计人员依法独立行使统计调查、统计报告、统计监督的职权。稍有不慎,很容易加剧中央和地方统计数据不对称,成为诱发统计失真现象的沃土。特别是在统计网络日渐发达的今天,一旦统计数据失实,则“垃圾进、垃圾出”,其不良后果及影响将会更加严重。因此,积极规避统计失真,实现中央对地方所提供统计数据质量的有效甄别,必须在高速运转的“统计工作信息化平台”基础上,增强统计数据流通的透明性,使得整个网络所流通的统计数据具有真实性、有效性、可考证性,建立相应的网络统计数据跟踪机制和智能甄别系统,确保统计数据质量。
二 网络统计数据跟踪原理
所谓数据跟踪,就是在各数据提供者、数据处理者和数据使用者之间建立一个基于“标签文件”的逻辑链条。该逻辑链条实现的前提是,必须为每个数据文件嵌入一个可记录、但不可更改其来源、处理过程、引用和被引用信息的标签文件。即数据提供者所提供的数据文件一经系统接收,系统都会自动为其生成一个可记录其流转渠道、再处理过程、引用和被引用情况的、不受用户操纵、影响的标签文件,该标签不仅可标明该数据文件由谁提供,流转所到之处经由谁的何种处理,除此之外,还可对该数据文件引用了哪些数据文件、被哪些数据文件所引用等情况进行标示。这也意味着,对于系统而言,不仅要保存用于存储统计数据的数据文件,还需要存储有关该数据文件的标签文件。和往常一样,保存后的数据文件均可以被其它数据文件引用,也可以在再处理过程中引用其它数据文件中的数据,和以往不同的是,这些录用、引用、再处理、再引用的过程信息都会被系统所记录。自动保存到相关数据文件对应的标签文件中,这样,不管数据经过多少层流转和处理加工,统计主管机构都可以通过查阅该数据文件对应的标签文件来划分下级统计机构的业绩和责任,统计每个数据提供者所提供数据的利用率,明确相关责任人。
网络统计数据甄别系统是一个专门审查辨别网络统计数据真伪优劣,考核鉴定信源信息能力和品质的系统,是实现数据跟踪机制的基础保障。整个系统的核心部件是智能甄选器,而标签系统、标签生成器、标准库、方法库、数据仓库、网站系统和数据接收系统的协同工作为核心部件提供了一个良好情报、存储环境。其中,标准库、数据仓库、方法库和标签库分别承担着存储“甄别标准”、“数据元”、“数据甄选方法”、“标签文件”的任务;而标签生成器则相当于智能甄选器的情报系统,也是这个系统核心部件运行的触发装置;标签系统则相当于数据文件的指针集,他为智能甄选器带来了用户需用数据的情报,有了这个指针集,一方面避免了数据在客户端的重复存储,另一方面也使得数据需求管理的逻辑化、简约化、规范化。其基本工作原理及系统结构如下:
第一步,系统接收统计数据提供者提交的数据文件,并自动生成标签文件。
第二步,系统智能甄选器调用模糊分析模块对数据文件进行聚类。首先,模糊分析模块对数据文件中的数据进行标准化;然后,建立模糊相似矩阵,求得动态聚类图;最后,提取同类数据文件的相似特征及相似度,生成数据典型样本集,作为甄别标准存入标准库。
第三步,系统智能甄选器调取模糊识别模块,对新进入的数据文件特征进行提取,形成甄别线索,作为到标准库中搜寻相应甄别标准的依据,如果搜寻到具有较高相似度的标准,则匹配后更新,如不存在,则返回第二步建立一个新的标准。
第四步,当用户点击网页上的数据文件的视图时,系统智能甄选器自动调取模糊决策模块,引导用户构建用户数据需求模板,辅助用户筛选统计数据。
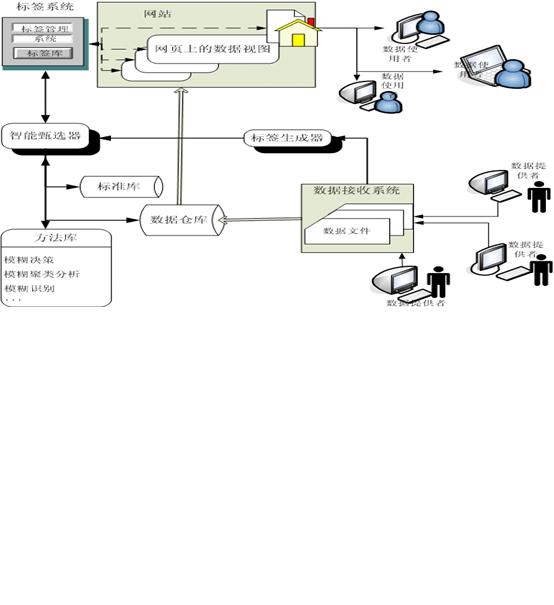
图1 网络统计数据甄别系统结构
三 网络统计数据甄别系统的组成部件
网络统计数据甄别系统主要由数据接收系统、标签生成器、数据仓库、标准库、方法库、智能甄选器、标签系统、公众网站基本部分组成,其中:
数据接收系统。数据接收系统直接面向数据提供者,是系统获取数据,优化甄别标准的前提和保障。
标签生成器。它是系统核心部件智能甄选器运行的触发器,主要对数据提供者提交的数据文件的关键特征,如数据提供者、统计对象、统计时间、统计方法等进行著录和保存。
数据仓库。数据仓库是集中存储统计数据的地方,与数据文件不同的是,它并非按照数据提供者最初提交的文件模式存储数据,而是在系统甄选器的指挥下,对数据文件进行清理,分解,最后以数据元的形式重新定位、保存统计数据。
标准库。标准库主要存储甄别标准。由于标准库中存储的标准是动态可维护的,每次系统的甄选行为都可能会改变系统既有的甄别标准。
方法库。方法库包含了各种模糊识别、分析、决策的方法。其中,模糊识别方法主要根据数据文件的特征,将数据进行识别并分类,生成各种类型的元数据。模糊分析方法的主要作用是构建并求解模糊矩阵。模糊决策方法则是辅助用户集中意见、协调对比和综合评判数据的信度和效度,作为数据筛选的依据。
智能甄选器。智能甄选器具有调用方法库,分析数据类型、生成甄别标准、控制各大存储部件和情报系统协调工作的功能。主要由感知识别机、推理机、控制器组成。其中,感知识别机可采用人工神经网络技术。而推理机则最好采用模糊推理方式,依据从标准库提取的甄别标准推导数据的真实度和效度,他具有根据不同的数据对象合理选择、定位、运用不同标准的作用。控制器是协调方法库、标准库、数据仓库、标签库协同工作的指挥中心。
标签系统。标签系统分为标签库和标签管理系统,其中,标签库主要存储标签生成器生成的各种标签文件,它包含指向若干数据文件的指针集。标签管理系统是建立在标签库之上的,用于对用户数据需求和系统内部存在的所有统计数据进行调配、链接。标签文件是单独存放在标签系统中的,里面嵌入了相应的地址指针,该指针将标签文件于数据文件相链接。这样只要查看标签文件,就可以追踪到与数据文件相关的来源、处理、引用、被引用信息,了解该数据来自何处,经历了哪些处理,利用率如何。
公众网站系统。网站系统直接面向公众,是统计信息用户与智能甄别系统的接口。
结束语
要预防和规避统计失真,确保统计数据质量,必须建立起与之相适应的数据跟踪机制,选用适合的数据库管理系统产品,设计具有较高存取效率和实用价值的统计数据库是实现该机制的主要技术保障,针对统计数据文件及其标签文件的特点,最好选用oracle数据库产品,利用其强大的存储和日志管理、用户权限设置功能来实现数据跟踪的设想,除此之外,还应注意信息管理机制与信息技术的应用的匹配与适应,建立相应的诚信管理激励机制。诚信管理激励机制是建立在数据跟踪机制基础上的诚信激励制度和基于诚信档案的业绩考核制度。通过为每一位统计工作人员建立一个可供晋级和评优决策参考的诚信档案,不仅有助于上级统计机构对下级统计机构的工作业绩的考核,还可以更大程度确保统计数据质量。具体实施时,首先可根据工作人员生产出来的统计信息产品的施用效果来建立诚信档案,同时利用数据跟踪过程中产生的标签文件和数据跟踪规则来查找相应数据提供者、加工处理者,并计算其参与度。然后,根据参与度来增强或减少该工作人员诚信档案里的诚信积分,诚信积分达到一定程度者方能继续上岗并获取升迁、评优、增长薪资的机会。对于诚信积分数停滞不前甚至持续下降的工作人员,则严格按照统计法规进行惩罚,并限时整改,效果不佳者则可调换工作岗位或者撤销其工作资格。
参考文献
[1]国家统计信息工程“九五”建设规划、“十五”国家统计信息化建设规划、“十一五”国家统计信息化建设规划纲要 国家统计局计算中心 国家统计局内网
[2]朱胜 统计学原理[M].北京:中国统计出版社 2002年8月
[3]吴喜之编著《统计学:从数据到结论》[M].北京:中国统计出版社 2006年10月
[4]党跃武 谭祥金主编《信息管理导论》[M]北京:高等教育出版社 2006年1月
[5]王万森 编著 人工智能原理及应用[M]. 北京:电子工业出版社 2000年9月
[6] J.E.Stiglitz ,“The Theory of Screening, Education and the Distribution of Income,”Amer. Econ. Rev., June 1975, 65, 283-300
[7] 曾鸿 张利华 张仕斌 信息甄别—信息时代的数据矿工[J] 统计与信息论坛 2003年第5期
https://wap.sciencenet.cn/blog-520919-403102.html
下一篇:我的人生理想...