博文
生物学的数据分析步骤
||
概要:
本节将展示如何选择最合适的方法来分析生物学实验。
如何确定合适的数据检验方法:
要决定如何分析数据,最好的办法是采用系统的、分步的方法。作者推荐一下步骤:
1. 具体说明你所期望解决的生物学问题;
2. 将该问题分别以生物学的零假设(null hypothesis)和备择假设(alternative hypothesis)两种形式表达;
3. 将该问题分别以统计学的零假设和备择假设两种形式表达;
4. 找出哪些变量(variables)与该问题相关;
5. 确定每一个变量属于哪种变量类型;
6. 设计的实验可控制混淆变量(confounding variables),或使其随机化;
7. 根据变量的数量和种类、符合预期的参数假设以及所需要检验的假设,选择最好的数据检验方法;
8. 允许的情况下,进行功效分析(power analysis)来确定合适的样本大小;
9. 做实验;
10. 检验数据是否与之前所选的数据检验的假设相符(首要是对可测量变量进行正态分布normality检验与方差齐性homoscedasticity检验)。如果不相符,则选择一个更合适的检验方法;
11. 用所选的检验方法运行数据分析,并说明结果;
12. 有效地展示你的结果,通常附图与表。
只要你能坚持读下去,整个过程中的每一部分你都会学到很多知识。其中很重要的一点:做实验是第九步而非第一步。做实验之前,你必须想很多、计划很多并做很多决定。如果你准备工作做得好,那么实验就很容易去理解、分析说明,也容易解释你所期望解决的问题,无论该问题是大是小。如果你一拍脑袋就把实验做了,那事后就难免需要更多复杂、艰涩的数据检验方法,结果难以解释,同时也容易造成试验对象过多(浪费资源)或是试验对象过少(无效试验)的问题。
下面举例子,Verrelli and Eanes (2001)测定了黑腹果蝇Drosophila melanogaster个体的糖原含量。果蝇编码葡萄糖磷酸变位酶(phosphoglucomutase, PGM)的基因座具有多态性。在PGM蛋白序列的第52个位点上,有一个缬氨酸Valine或丙氨酸Alanine。在第484个位点上,有一个缬氨酸或亮氨酸Leucine。四个氨基酸的四种排列组合就出现了(V-V,V-L,A-V,A-L)。
1. 问题来了,“PGM基因座上的氨基酸多态性是否影响个体的糖原含量?”。生物学的问题通常与生物过程有关,即“X的变化是否造成了Y的变化?”,就好比你想知道某一种药是否对改变了血压;土壤的pH是否影响了蓝莓灌木的生长;Rab10蛋白是否介导对纤毛的膜运输。
2. 这个问题的生物学零假设是“不同的氨基酸序列不影响PGM的生化特性,因此糖原含量不受PGM序列的影响”。生物学备择假设为“不同的氨基酸序列影响了PGM的生化特性,因此糖原含量受到了PGM序列的影响”。通过对两种假设的比较思考,你需要确定你的实验会针对命题的不同答案得出不同的结果。
3. 统计学零假设为“拥有不同PGM序列的果蝇有相同的糖原平均含量”,统计学备择假设则为“拥有不同PGM序列的果蝇有不同的糖原平均含量”。生物学假设与生物过程相关联,而统计学假设则与数字相关联。在这种情况下,糖原含量非等即差。检验统计学零假设是该书的主要目的,会给你一个清晰的结果,你也会因此肯定或否认该统计学的假设。否认统计学零假设是否足以回答命题,这很难说明白也十分主观。对实验结果可能存在的其他解释,作为所在领域的专家,你必须考虑你的解释有多让人信服。
4. Verrelli和Eanes认为该实验有两个相关的变量,糖原含量与PGM序列。
5. 糖原含量是测量性变量,可作为数字记录并存在许多可能的数值;而PGM序列为名义变量(nominal variable),仅存在4个可能的值(V-V,V-L,A-V或A-L),并以文字的形式记录。
6. 其他变量也很重要,比如年龄,在哪个瓶里孵化等。因此所有果蝇均使用同龄个体,并随机从各个孵化瓶内抽取个体。我们要尽可能发现混淆变量并加以处理,假设Verrelli和Eanes使用了年龄不同的果蝇,事后使用统计学方法进行校准。这样做会使后面的分析更复杂,得出的结果也更难解释清楚,同时也可能产生与年龄和糖原含量相关的奇怪的结果。这对强化解释命题起到南辕北辙的作用。
7. 因为我们的目的是要比较由名义变量划分的各组之间测量型变量的平均值,组数大于2,因此单向方差分析one-way ANOVA是比较合适的检验方法。当你知道你所要分析的变量及其类型,可选的检验方法其实通常就只有一两个了。
8. 功效分析需要用于估算糖原含量的标准偏差(一般可从前人的研究中找到),和效应尺度是否充分(该实验想要观察到的不同基因型间糖原含量的变化)。在该实验中,拥有不同基因型的个体在糖原含量有任何的差异都是有意义的,因此实验在时间条件允许下,尽可能使用更多果蝇个体。
9. 做实验:拥有不同PGM序列的果蝇中的糖原含量被测定了。
10. 所选的方差分析假设可测量变量——糖原含量符合正态分布(分布符合钟形正态曲线)与方差齐性(不同PGM序列的糖原含量的变化幅度是相等的),且通过柱形图发现数据符合前述的假设。如果数据与方差分析的假设不相符,则Kruskal-Wallis检验或Welch’s检验更好。
11. 单向方差分析通过表格、网页及电脑程序运行完成,方差分析的结果P 值小于0.05。说明拥有PGM序列的果蝇中的糖原含量与含有其他序列的果蝇显著不同。
12. 结果可归纳成表格,但用图表示更为直观:
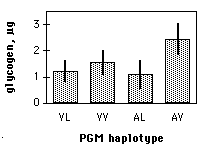
果蝇中Drosophila melanogaster.的糖原含量
每一条柱代表相同序列12只
果蝇体内糖原含量的平均值
细线表示95% 置信区间
本文翻译自:
http://www.biostathandbook.com/analysissteps.html
参考文献:
Verrelli, B.C., Eanes, W.F., 2001. The functional impact of Pgm amino acid polymorphism on glycogen content in Drosophila melanogaster. Genetics. 159, 201-210. (Note that for the purposes of this web page, I've used a different statistical test than Verrelli and Eanes did. They were interested in interactions among the individual amino acid polymorphisms, so they used a two-way anova.)
https://wap.sciencenet.cn/blog-3477253-1289234.html