ВЉЮФ
[зЊди]жЦдьвЕЩњВњЙ§ГЬжаЖрдДвьЙЙЪ§ОнДІРэЗНЗЈзлЪі
||
жЦдьвЕЩњВњЙ§ГЬжаЖрдДвьЙЙЪ§ОнДІРэЗНЗЈзлЪі
ГТЪРГЌ1,2, ДоДКгъ1, еХЛЊ3, ТэИъ4, жьЗяЛЊ1, ЩЬауЧл1, амИе,1
1 жаЙњПЦбЇдКздЖЏЛЏбаОПЫљИДдгЯЕЭГЙмРэгыПижЦЙњМвжиЕуЪЕбщЪвЃЌББОЉ 100190
2 АФУХПЦММДѓбЇЃЌАФУХ 999078
3 ББОЉКНЬьжЧдьПЦММЗЂеЙгаЯоЙЋЫОЃЌББОЉ 100039
4 жаЙњЙЄвЕЛЅСЊЭјбаОПдКЃЌББОЉ 100102
еЊвЊЃКЫцзХЯжДњжЦдьвЕЯђзХздЖЏЛЏЁЂаХЯЂЛЏЁЂжЧФмЛЏЗНЯђПьЫйЗЂеЙЃЌЩњВњЙ§ГЬжаЛсВњЩњДѓСПЕФЖрдДвьЙЙЪ§ОнЁЃЖдЖрдДвьЙЙЪ§ОнЕФгааЇДІРэКЭЩюЖШЭкОђПЩЮЊЩњВњжЦдьепЬсЙЉИќгааЇЕФЩњВњЕїЖШЁЂЩшБИЙмРэЕШВпТдЃЌДгЖјЬсИпЩњВњжЪСПКЭаЇТЪЁЃеыЖджЦдьвЕЩњВњЙ§ГЬжаЖрдДвьЙЙЪ§ОнЕФДІРэЗНЗЈгыММЪѕЕШНјааЯЕЭГадЕФзлЪіЃЌЪзЯШУїШЗСЫжЦдьвЕЩњВњЙ§ГЬЖрдДвьЙЙЪ§ОнФкШнМАЗжРрЃЛЦфДЮЃЌВћЪіСЫЖрдДвьЙЙЪ§ОнДІРэжаЪ§ОнВЩМЏЁЂЪ§ОнМЏГЩМАЪ§ОнЗжЮіИїИіНзЖЮгІгУЕФЪ§ОнДІРэЗНЗЈКЭММЪѕЃЌВЂЗжЮіСЫИїжжЗНЗЈгыММЪѕЕФгХШБЕувдМАгІгУЃЛзюКѓЃЌЖдЩњВњЙ§ГЬжаЖрдДвьЙЙЪ§ОнДІРэЗНЗЈКЭММЪѕНјаазмНсЃЌжИГіСЫЯжНзЖЮЖрдДвьЙЙЪ§ОнДІРэЗНЗЈМАММЪѕУцСйЕФЬєеНКЭЗЂеЙЧїЪЦЁЃ
ЙиМќДЪЃК Ъ§ОнДІРэ ; ЖрдДвьЙЙЪ§Он ; ЩњВњжЦдь
ТлЮФв§гУИёЪНЃК
ГТЪРГЌ,ДоДКгъ,еХЛЊ, ЕШ. жЦдьвЕЩњВњЙ§ГЬжаЖрдДвьЙЙЪ§ОнДІРэЗНЗЈзлЪі[J]. ДѓЪ§Он, 2020, 6(5): 55-81.
CHEN S C, CUI C Y, ZHANG H, et al. A survey on multi-source heterogeneous data processing methods in manufacturing process[J]. Big Data Research, 2020, 6(5): 55-81.
1 в§бд
дкШЋЧђаХЯЂММЪѕПьЫйЗЂеЙЕФБГОАЯТЃЌЫцзХПЦбЇММЪѕЕФбИУЭЗЂеЙКЭЩчЛсаХЯЂЛЏГЬЖШЕФВЛЖЯЬсИпЃЌШЫРрЩчЛсЙВЯэЕФЪ§ОнЕФЪ§СПДѓДѓдіМгЃЌЙВЯэЕФЪ§ОнЕФаЮЪНДѓДѓЗсИЛЁЃОнЯЃНнЙЋЫОгыЙњМЪЪ§ОнЙЋЫОЃЈIDCЃЉЙВЭЌЗЂВМЕФЁЖЪ§зжЛЏЪРНчЁЊЁЊДгБпдЕЕНКЫаФЁЗАзЦЄЪщЃЌШЋЧђЪ§ОнШІЙцФЃНЋДг2018ФъЕФ33 ZBдіжС2025ФъЕФ175 ZBЁЃЦфжаЃЌАзЦЄЪщжажИГіЃЌдкШЋЧђЪ§ОнШІжаЃЌжЦдьвЕЪ§ОнЫљеМЗнЖюзюДѓЃЌдЖдЖГЌЙ§ЦфЫћаавЕЁЃЭЌЪБЃЌАщЫцзХжаЙњЁАжЧФмжЦдь 2025ЁБЙњМвеНТдЕФЪЕЪЉЃЌЙЄвЕжЦдьвЕУцСйжиДѓЕФБфИязЊаЭЃЌДѓЪ§ОнГЩЮЊЬсЩ§жЦдьвЕЩњВњСІЁЂДДдьСІЕФЙиМќЁЃЫцзХжЧФмжЦдьЕФЗЂеЙЃЌздЖЏЛЏЁЂаХЯЂЛЏЁЂжЧФмЛЏЕШММЪѕЩјЭИЕНжЦдьвЕЩњВњЙ§ГЬЕФИїИіЛЗНкЃЌДгЙЄвЕЯжГЁЕФДЋИаЦїЁЂЩшБИЕНжЦдьЩњВњЙ§ГЬжаЕФИїИіаХЯЂЯЕЭГЃЈШчжЦдьжДааЙмРэЯЕЭГЁЂЩњВњМрПиЯЕЭГЁЂЩшБИдЫааЮЌЛЄЯЕЭГЁЂВњЦЗжЪСПМьВтЯЕЭГЁЂФмКФЙмРэЯЕЭГЕШЃЉЃЌОљЛсВњЩњДѓСПВЛЭЌНсЙЙРраЭЕФЪ§ОнЁЃвдвЛИіЕфаЭЕФЗФжЏжЦдьГЕМфЮЊР§ЃЌЦфвЛЬьЕФЪ§ОнСПНЋДяЕН84 GBЃЌЖјвЛЬЈАыЕМЬхЩњВњЛњЦївЛЬьЕФЪ§ОнСПЩѕжСПЩвдДяЕНTBМЖБ№ЃЌетаЉЪ§ОнАќРЈЖўНјжЦЁЂЮФБОЁЂЪгЦЕЁЂвєЦЕЕШЪ§ОнЁЃЖјКЃСПЕФЪ§ОнжадЬКЌзХДѓСПгаМлжЕЕФаХЯЂЃЌЖдетаЉаХЯЂЕФЬсШЁгаРћгкжИЕМШЫУЧдкЩњВњжЦдьЁЂЩшБИЙмРэКЭЩњВњЕїЖШЕШЙ§ГЬжазіГіе§ШЗЕФОіВпЃЌДяЕНгХЛЏжЦдьСїГЬЁЂЬсИпаЇФмЕФФПЕФЃЌДйНјжЦдьвЕЩњВњЙ§ГЬЕФШЋУцжЧФмЛЏЃЌДгЖјЬсИпЩњВњжЪСПКЭаЇТЪЁЃ
ШчЭМ1ЫљЪОЃЌВњЦЗЕФжЦдьСїГЬАќРЈбаЗЂЩшМЦЁЂЮяСЯВЩЙКЁЂЩњВњжЦдьЁЂВњЦЗЯњЪлМАВњЦЗЪлКѓ5ИіНзЖЮЃЌУПИіНзЖЮЕФЪ§ОнЖМОпгаЪ§ОнРДдДЖрбљЁЂЪ§ОнжЪСПЕЭЁЂЪ§ОндЬКЌаХЯЂИДдгЁЂЪ§ОнЪЕЪБадИпЕШЬиЕуЃЌЖјДгКЃСПЪ§ОнжаЗЂОђжИЕМжЦдьвЕбаЗЂЩшМЦЁЂЩњВњжЦдьЁЂЯњЪлЪлКѓКЭОгЊЙмРэЕШЙ§ГЬЕФжЊЪЖКЭЙцдђЃЌашвЊДѓСПЕФФЃаЭЫуЗЈЕШЪ§ОнДІРэЗНЗЈЕФжЇГХЁЃгШЦфЪЧдкВњЦЗЩњВњжЦдьЙ§ГЬжаВњЩњЕФЪ§ОнЃЌЦфВЛНіЪ§ОнСПЪЎЗжХгДѓЃЌРДдДЗсИЛЁЂРраЭЖрбљЁЂНсЙЙИДдгЃЌЖјЧвгЩгкжЦдьвЕВЛЭЌЕФВПУХКЭЯЕЭГжЎМфЪ§ОнЕФРДдДЁЂДцДЂаЮЪНЕШИїВЛЯрЭЌЃЌЪ§ОндДжЎМфДцдквьЙЙадЁЂЗжВМадКЭзджЮадЃЌЪ§ОнРраЭМШАќРЈЪ§зжЁЂЙиЯЕаЭЪ§ОнЕШНсЙЙЛЏЪ§ОнЃЌвВАќРЈЭМЯёЁЂвєЦЕЕШЗЧНсЙЙЛЏЪ§ОнЁЃвђДЫЃЌетЖджЦдьвЕЩњВњжЦдьЙ§ГЬжаКЃСПЪ§ОнЕФДІРэЗНЗЈКЭММЪѕЬсГіСЫИќИпЕФвЊЧѓЁЃЮЊСЫГфЗжЗЂЛгжЦдьвЕЖрдДвьЙЙЪ§ОнаХЯЂЕФЧБСІЃЌИќМгИпаЇЕиНјааЪ§ОнДІРэЃЌБиаыдкУїШЗЖрдДвьЙЙЪ§ОнИХФюЕФЛљДЁЩЯЃЌЖдЖрдДвьЙЙЪ§ОнЕФДІРэЗНЗЈКЭММЪѕеЙПЊЩюШыЧвЯЕЭГадЕФбаОПЁЃ
БОЮФЪзЯШУїШЗСЫжЦдьвЕЩњВњЙ§ГЬжаЖрдДвьЙЙЪ§ОнЕФИХФюКЭРраЭЃЛЦфДЮЖдЩњВњЙ§ГЬжаЖрдДвьЙЙЪ§ОнДІРэЕФЙ§ГЬНјааСЫЛЎЗжЃЌЭЌЪБЖдИїИіНзЖЮЕФЪ§ОнДІРэЗНЗЈКЭММЪѕМАЦфдкжЦдьвЕЩњВњЙ§ГЬжаЕФгІгУНјааСЫЩюШыЗжЮігыЬжТлЃЛзюКѓЃЌЖдЩњВњЙ§ГЬжаЖрдДвьЙЙЪ§ОнДІРэЗНЗЈМАММЪѕНјааСЫзмНсЃЌВЂЖдЯжНзЖЮУцСйЕФЬєеНМАЮДРДЕФЗЂеЙЧїЪЦНјааСЫЗжЮігыЬжТлЁЃ
2 жЦдьвЕЩњВњЙ§ГЬжаЕФЖрдДвьЙЙЪ§Он
ЁЖДѓЪ§ОнЃКЯТвЛИіДДаТЁЂОКељКЭЩњВњСІЕФЧАбиЁЗеыЖдЩчЛсЖдДѓЪ§ОнЕФЙизЂМАгІгУашЧѓЃЌЖдКЃСПЪ§ОнЕФДІРэММЪѕНјааСЫНщЩмКЭзмНсЁЃЛљгкЖдВЛЭЌРДдДЁЂЖржжНсЙЙЪ§ОнЕФзлКЯбаОПЕФЦШЧаашвЊЃЌЖрдДвьЙЙЪ§ОнетвЛИХФюЫцжЎВњЩњЃЌЦфжївЊАќРЈСНИіЬиеїЃКвЛЪЧЪ§ОнРДдДОпгаЖрдДадЃЛЖўЪЧЪ§ОнжжРрМАаЮЬЌОпгаИДдгадЃЌМДвьЙЙадЁЃ

ЭМ1 жЦдьСїГЬЕФ5ИіНзЖЮ
ЖрдДвьЙЙЪ§ОнРДздЖрИіЪ§ОндДЃЌАќРЈВЛЭЌЪ§ОнПтЯЕЭГКЭВЛЭЌЩшБИдкЙЄзїжаВЩМЏЕФЪ§ОнМЏЕШЁЃВЛЭЌЕФЪ§ОндДЫљдкЕФВйзїЯЕЭГЁЂЙмРэЯЕЭГВЛЭЌЃЌЪ§ОнЕФДцДЂФЃЪНКЭТпМНсЙЙВЛЭЌЃЌЪ§ОнЕФВњЩњЪБМфЁЂЪЙгУГЁЫљЁЂДњТыавщЕШвВВЛЭЌЃЌетдьГЩСЫЪ§ОнЁАЖрдДЁБЕФЬиеїЁЃ
СэЭтЃЌЖрдДвьЙЙЪ§ОнАќРЈЖржжРраЭЕФНсЙЙЛЏЪ§ОнЁЂАыНсЙЙЛЏЪ§ОнКЭЗЧНсЙЙЛЏЪ§ОнЁЃНсЙЙЛЏЪ§ОнжИЙиЯЕФЃаЭЪ§ОнЃЌМДвдЙиЯЕЪ§ОнПтБэаЮЪНЙмРэЕФЪ§ОнЃЛАыНсЙЙЛЏЪ§ОнжИЗЧЙиЯЕФЃаЭЕФЁЂгаЛљБОЙЬЖЈНсЙЙФЃЪНЕФЪ§ОнЃЌР§ШчШежОЮФМўЁЂXMLЮФЕЕЁЂJSONЮФЕЕЁЂE-mailЕШЃЛЗЧНсЙЙЛЏЪ§ОнжИУЛгаЙЬЖЈФЃЪНЕФЪ§ОнЃЌШчWORDЁЂPDFЁЂPPTЁЂEXLМАИїжжИёЪНЕФЭМЦЌЁЂЪгЦЕЕШЁЃВЛЭЌРраЭЕФЪ§ОндкаЮГЩЙ§ГЬжаУЛгаЭГвЛЕФБъзМЃЌвђДЫдьГЩСЫЪ§ОнЁАвьЙЙЁБЕФЬиеїЁЃ
ЫцзХздЖЏЛЏЁЂаХЯЂЛЏЁЂжЧФмЛЏЕШММЪѕдкжЦдьвЕжаЕФЙуЗКгІгУЃЌдкЩњВњЙ§ГЬжаБиШЛЛсВњЩњДѓСПЕФЖрдДвьЙЙЪ§ОнЁЃДгЪ§ОнЕФРДдДРДЫЕЃЌжЦдьвЕЕФжЦдьжДааЙмРэЯЕЭГЁЂЩњВњМрПиЯЕЭГЁЂЩшБИдЫааЮЌЛЄЯЕЭГЁЂВњЦЗжЪСПМьВтЯЕЭГЁЂФмКФЙмРэЯЕЭГжаЕФИїжжЛњЦїЩшЪЉЁЂЙЄвЕДЋИаЦїЕШдкдЫааКЭЮЌЛЄЙ§ГЬжаЖМЛсВњЩњДѓСПЕФЪ§ОнЁЃДгЪ§ОнНсЙЙРраЭРДПДЃЌетаЉКЃСПЖрдДвьЙЙЪ§ОнМШАќРЈЩшБИМрВтЪ§ОнЁЂВњЦЗжЪСПМьВтЪ§ОнЁЂФмКФЪ§ОнЕШНсЙЙЛЏЪ§ОнЃЌЛЙАќРЈЩњВњМрПиЯЕЭГВњЩњЕФДѓСПЭМЦЌЁЂЪгЦЕЕШЗЧНсЙЙЛЏЪ§ОнЁЃБОЮФзлКЯЦфЫћбЇепЕФбаОПЛљДЁЃЌеыЖджЦдьвЕЩњВњЙ§ГЬжаВњЩњЕФЪ§ОнЃЌАДееЪ§ОнРДдДКЭРраЭЃЌНЋЦфзіШчЯТЛЎЗжЃЌМћБэ1ЁЃЖдгкжЦдьвЕЩњВњЙ§ГЬжаЕФЖрдДвьЙЙЪ§ОнРДЫЕЃЌгЩгкЩњВњЙ§ГЬДцдкИДдгЕФБфЛЏЬѕМўЃЌвђДЫЖдЪ§ОнЕФШЋУцадЁЂЪЕЪБадЕФвЊЧѓНЯИпЁЃ
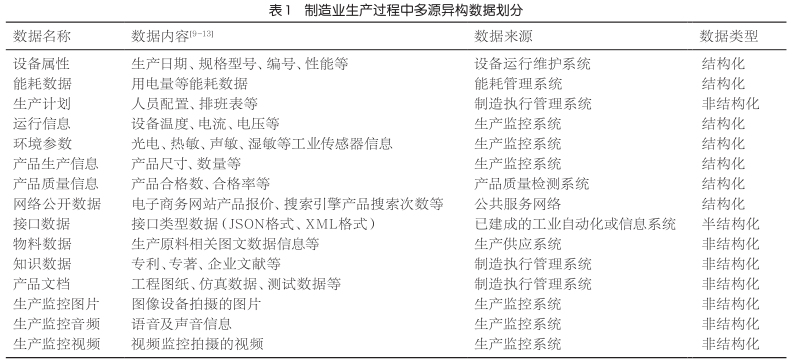
3 жЦдьвЕЩњВњЙ§ГЬжаЖрдДвьЙЙЪ§ОнДІРэ
дкжЦдьвЕЩњВњЙ§ГЬжаЃЌДгЧАЦкЕФЪ§ОнЙуЗКВЩМЏЃЌЕНзюКѓЪ§ОнЕФМлжЕЬсШЁЃЌЖрдДвьЙЙЪ§ОнДІРэЕФвЛАуСїГЬАќРЈЪ§ОнВЩМЏЁЂЪ§ОнМЏГЩМАЪ§ОнЗжЮіЁЃЪ§ОнВЩМЏжївЊЪЕЯжДѓСПдЪМЪ§ОнзМШЗЁЂЪЕЪБЕФВЩМЏЃЌЮЊЪ§ОнМЏГЩНзЖЮЬсЙЉдЪМЪ§ОндДЁЃЪ§ОнМЏГЩжївЊЪЕЯжЪ§ОнЕФЪ§ОнПтДцДЂЃЌЪ§ОнЧхЯДЁЂзЊЛЛЁЂНЕЮЌЕШдЄДІРэвдМАЙЙНЈКЃСПЙиСЊЪ§ОнПтЃЌЮЊЪ§ОнЗжЮіНзЖЮЬсЙЉдЄДІРэЕФЪ§ОндДЁЃЪ§ОнЗжЮіжївЊРћгУЙиСЊЗжЮіЁЂЗжРрОлРрМАЩюЖШбЇЯАЕШММЪѕЪЕЯжЪ§ОнЕФМлжЕЭкОђЁЃЖрдДвьЙЙЪ§ОнДІРэЕФвЛАуСїГЬШчЭМ2ЫљЪОЁЃ
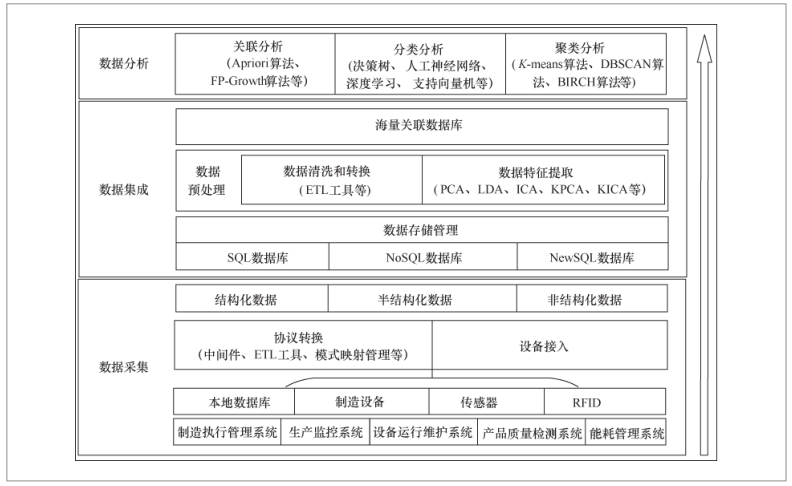
ЭМ2 ЖрдДвьЙЙЪ§ОнДІРэЕФвЛАуСїГЬ
3.1 Ъ§ОнВЩМЏ
Ъ§ОнВЩМЏЪЧЖрдДвьЙЙЪ§ОнДІРэЕФЛљДЁЃЌжЛгаЪЕЯжЖдЩњВњЙ§ГЬжаВњЩњЕФДѓСПдЪМЪ§ОнзМШЗЁЂЪЕЪБЕФВЩМЏЃЌВЂНЋЦфДЋЪфЕНЪ§ОнДцДЂЙмРэЦНЬЈЃЌВХФмЖдЩњВњЩшБИЁЂВњЦЗжЪСПЁЂЙЄзїЕїЖШЕШНјааМрПигыЙмРэЃЌДгЖјАяжњЩњВњЙмРэВПУХзіГіИќИпаЇЁЂОЋзМЕФОіВпЁЃ
еыЖдВЛЭЌРраЭЩњВњжЦдьвЕЩњВњЙ§ГЬжаЕФЖрдДвьЙЙЪ§ОнЃЌашвЊВЩгУВЛЭЌЕФЪ§ОнВЩМЏЗНЗЈКЭЙЄОпЁЃЪзЯШЃЌЖдгкРыЩЂжЦдьвЕжаЕФЩњВњЙ§ГЬЪ§ОнЃЌжївЊЪЙгУЩфЦЕЪЖБ№ЃЈradio frequency identificationЃЌRFIDЃЉММЪѕЖдЩњВњГЕМфжаЕФдВФСЯЁЂЩшБИЁЂВњЦЗаХЯЂЕШНјааЪ§ОнВЩМЏЁЃеыЖдЩњВњСїЫЎЯпЩЯЕФВњЦЗаХЯЂЃЌВмЮАЕШШЫЬсГіСЫвЛжжЮоЯпЩфЦЕЪЖБ№Ъ§ОнВЩМЏЕЅдЊФЃаЭЃЌПЩЛёШЁСуМўЕФзДЬЌЁЂЪБМфЕШЪЕЪБаХЯЂЃЌВЂдкДЫЛљДЁЩЯНЈСЂСЫеыЖдМгЙЄЙЄађЁЂЙЄађСїЁЂХњДЮгыХњСПЕФЮоЯпЩфЦЕЪЖБ№МрПиФЃаЭЃЌДгЖјЪЕЯжСЫЖдРыЩЂжЦдьГЕМфЩњВњЙ§ГЬЕФПЩЪгЛЏМрПиЁЃЖјЖдгкСїГЬЩњВњжЦдьвЕжаЕФЩњВњЙ§ГЬЪ§ОнЃЌжївЊвРППДЋИа ЦїМАЩЯЮЛЛњЖдЪ§ОнНјааВЩМЏЁЃГТПЊЪЄЬсГіСЫВЩгУЗжВМЪНПижЦЯЕЭГЃЈdistributed control systemЃЌDCSЃЉКЭПЩБрГЬТпМПижЦЦїЃЈprogrammable logic controllerЃЌPLCЃЉЕШИЈжњПижЦЯЕЭГКЭПижЦзАжУНјааЪ§ОнВЩМЏЕФЗНЗЈЃЌИУЗНЗЈЪЧЖдМЦЫуЛњЁЂЭјТчКЭЪ§ОнПтЕФзлКЯдЫгУЁЃДЫЭтЃЌдкСїГЬЩњВњжаЃЌвдМЦЫуЛњЮЊЛљДЁЕФЪ§ОнВЩМЏЯЕЭГЛЙгаЪ§ОнВЩМЏгыМрЪгПижЦЃЈsupervisory control and data acquisitionЃЌSCADAЃЉЯЕЭГЁЃЦфжаЃЌPLCжївЊгІгУгкЩњВњЯжГЁЕФЮТЖШВтПиЃЛDCSжївЊгІгУдкЖдВтПиОЋЖШМАЫйЖШвЊЧѓНЯИпЕФЩњВњЯжГЁЕФЪ§ОнВЩМЏЃЛSCADAдђШкКЯСЫPLCЕФЯжГЁВтПиЙІФмКЭDCSЕФзщЭјЭЈаХФмСІЃЌПЩвдЖдЗжЩЂЕуНјааПижЦЃЌДгЖјЪЕЯжЖдЗжВМЗЖЮЇНЯЙуЕФЩњВњЯжГЁЕФИВИЧЁЃЮїУХзгЙЋЫОдкPLCЕФЛљДЁЩЯМгШыСЫЭјТчвдМАШэМўЕШЃЌПЊЗЂСЫSIMATIC PCS7ЮїУХзгSCADAЯЕЭГЁЂSIMATIC WinCCЮїУХзгSCADAЯЕЭГЕШПижЦЯЕЭГЃЌЖјDCSГЇЩЬЛєФсЮЄЖћЙЋЫОвВдкЦфЯЕЭГжаШкШыСЫPLCЃЌвддіЧПЦфТпМПижЦЃЌПЊЗЂСЫЙ§ГЬжЊЪЖЯЕЭГЃЈprocess knowledge systemЃЌPKSЃЉЁЃЖдгкдкРыЩЂжЦдьвЕМАСїГЬжЦдьвЕжаОљЙуЗКДцдкЕФШежОЪ§ОнМАЖрУНЬхЪ§ОнЕШЃЌЭЌбљИљОнЦфИїздЕФЬиЕуВЩгУВЛЭЌЕФЪ§ОнВЩМЏЗНЗЈЁЃЖдгкжЦдьЩњВњЙ§ГЬВњЩњЕФШежОЪ§ОнЮФМўЃЌПЩвдВЩгУFlumeетвЛЗжВМЪНЁЂИпПЩППЁЂИпПЩгУЕФШежОВЩМЏДЋЪфЯЕЭГЁЃГТЗЩЕШШЫЬсГіСЫвЛжжЛљгкFlumeВЂНсКЯElasticsearchМАKibanaЕФаТаЭЗжВМЪНВЩМЏЯЕЭГЃЌИУЯЕЭГЪЪгУгкКЃСПШежОЪ§ОнЕФВЩМЏЁЃеыЖдЩњВњЙ§ГЬЖдвєЦЕЁЂЪгЦЕЕШЖрУНЬхЪ§ОнЕФМрПиЃЌгаРћгУЖрУНЬхСїДІРэв§ЧцжБНгзЅШЁЛђРћгУГЇЩЬЬсЙЉЕФШэМўПЊЗЂЙЄОпАќЃЈsoftware development kitЃЌSDKЃЉПЊЗЂЪ§ОнЕМШыГЬађЕФЪ§ОнВЩМЏЗНЗЈЁЃРюЗяНПдкКЃПЕЭўЪгЕФ8100ЯЕСаЭјТчгВХЬТМЯёЛњЕФЛљДЁЩЯЃЌЭЈЙ§ЕїгУКЃПЕЭўЪгЬсЙЉЕФSDKжаЕФЯрЙиНгПкКЏЪ§ЖСШЁЪЕЪБЪгЦЕСїЁЃСэЭтЃЌеуНгюЪгПЦММгаЯоЙЋЫОЕФIPСїУНЬхНтОіЗНАИПЩвдЭЈЙ§АВзАСїУНЬхЗўЮёЦїШэМўРДЖдЖрУНЬхЪ§ОнНјааЪЕЪБЗУЮЪМАДцДЂЁЃЖдгкетМИжжЕфаЭЕФЪ§ОнВЩМЏЗНЗЈЃЌБОЮФИљОнЦфУцЯђЕФЪ§ОнРраЭМАдкЩњВњЙ§ГЬжаЕФгІгУНјааСЫзмНсЃЌМћБэ2ЁЃ

СэЭтЃЌеыЖдЪ§ОнВЩМЏЕФаТашЧѓЃЌЯрЙибаОПвВЬсГіСЫаэЖргыЭјТчММЪѕЯрНсКЯЕФДДаТаЭЪ§ОнВЩМЏЗНЗЈЁЃТэМЊОќЕШШЫЬсГіСЫвЛжжЛљгкБпдЕМЦЫуЕФЩњВњЪ§ОнВЩМЏЗНЗЈЃЌРћгУЗфЮбЭјТчЖдЩњВњЩшБИНјааЭјТчЛЏИФдьЃЌВЂРћгУБпдЕЭјЙиЖдВЩМЏЕНЕФЩњВњЪ§ОнНјааБОЕиДІРэЁЃаэхЋжЎКЭбюаЁНЁЬсГіСЫвЛжжЛљгкащФтзЈгУЭјЃЈvirtual private networkЃЌVPNЃЉЕФдЖГЬЙЄвЕЪ§ОнВЩМЏЯЕЭГЃЌдквбНЈКУЕФVPNЛЗОГЯТЭЈЙ§гУгкЙ§ГЬПижЦЕФOLEЃЈOLE for process controlЃЌ OPCЃЉПЭЛЇЖЫНјааЪ§ОнВЩМЏЁЃ
ЖдгкФПЧАМИжжЕфаЭЕФЪ§ОнВЩМЏГЁОАЃЌЪЕМЪгІгУжаИљОнЦфВЩМЏЕФЪ§ОнРраЭМАвЊЧѓЕШЃЌВЩгУFlumeЁЂRFIDЁЂДЋИаЦїЕШВЛЭЌЕФВЩМЏЗНЗЈЃЌетаЉЗНЗЈОпгаВЛЭЌЕФгХЪЦЁЃЖјУцЖдФПЧАЪ§ОнСПбИЫйдіГЄвдМАЪ§ОнРраЭШевцИДдгЛЏЕФЮЪЬтЃЌДЋЭГЪ§ОнВЩМЏЗНЗЈФбвдТњзуИќОпЪЕЪБадЁЂИќОЋШЗЕФВЩМЏвЊЧѓЃЌвђДЫЃЌгыЮяСЊЭјЕШЧАбиММЪѕЯрНсКЯГЩЮЊЪ§ОнВЩМЏЕФЗЂеЙЧїЪЦЁЃ
3.2 Ъ§ОнМЏГЩ
ЖрдДвьЙЙЪ§ОнМЏГЩЪЧећКЯРДздЖрИіЪ§ОндДЕФЪ§ОнЃЌЦСБЮЪ§ОнжЎМфРраЭКЭНсЙЙЩЯЕФВювьЃЌНтОіЖрдДвьЙЙЪ§ОнЕФРДдДИДдгЁЂНсЙЙвьЙЙЮЪЬтЃЌДгЖјЪЕЯжЖдЪ§ОнЕФЭГвЛДцДЂЁЂЙмРэКЭЗжЮіЃЌЪЕЯжгУЛЇЮоВюБ№ЗУЮЪЃЌГфЗжЗЂЛгЪ§ОнЕФМлжЕЁЃЪ§ОнМЏГЩЕФЙиМќММЪѕАќРЈЪ§ОнДцДЂЙмРэЁЂЪ§ОнЧхЯДгызЊЛЛМАЪ§ОнНЕЮЌЁЃ
3.2.1 Ъ§ОнДцДЂЙмРэ
Ъ§ОнЕФДцДЂЙмРэЪЧЖрдДвьЙЙЪ§ОнДІРэЙ§ГЬжаЗЧГЃживЊЕФвЛИіЛЗНкЃЌбЁдёКЯРэЕФЪ§ОнПтПЩвдМѕЩйЪ§ОнМьЫїЕФЪБМфЃЌЬсИпЪ§ОнВщбЏЕФзМШЗЖШЃЌЪЧКѓајЪ§ОнДІРэЕФЛљДЁЁЃФПЧАГЃМћЕФЪ§ОнПтММЪѕАќРЈЃКвдMySQLЁЂOracleЁЂDB2ЁЂSQL ServerЕШЮЊДњБэЕФSQLЪ§ОнПтЃЌвдRedisЁЂHBaseЁЂMongoDBЁЂNeo4jЕШЮЊДњБэЕФNoSQLЪ§ОнПтЃЌвдМАNewSQLЪ§ОнПтЁЃ
УРЙњМзЙЧЮФЙЋЫОбаЗЂЕФOracleЪЧвЛжжИпаЇЁЂЪЪгІИпЭЬЭТСПЕФЙиЯЕаЭЪ§ОнПтЯЕЭГЃЌдкЪ§ОнСПДѓЁЂЖдЯЕЭГадФмЮШЖЈвЊЧѓИпЕФИжЬњЁЂУКЬПЁЂЦћГЕжЦдьаавЕгІгУЙуЗКЁЃУРЙњIBMЙЋЫОПЊЗЂЕФDB2ОпгаЩьЫѕадФмСМКУЁЂВщбЏадФмСМКУвдМАЯђЯТМцШнадКУЕФЬиЕуЃЌЪЪгУгкКЃСПЪ§ОнЕФДцДЂЙмРэЃЌдкеўИЎЁЂвјааЕШЙуЗКгІгУЃЌСэЭтдкБІИжЁЂБОИжЕШИжЬњЦѓвЕвВгагІгУЁЃжЦдьвЕЩњВњжЦдьЙ§ГЬжаВњЩњЕФКЃСПЖрдДвьЙЙЪ§ОнАќКЌНсЙЙЛЏЁЂАыНсЙЙЛЏКЭЗЧНсЙЙЛЏЖржжЪ§ОнЁЃгЩгкУцЯђНсЙЙЛЏЪ§ОнЕФДЋЭГЙиЯЕаЭЪ§ОнПтдкЩьЫѕадЁЂШнДэадЁЂПЩРЉеЙадЕШЗНУцДцдкЕФЙЬгаОжЯоадЃЌЕЅЖРЪЙгУФбвдТњзуЖдКЃСПЖрдДвьЙЙЪ§ОнНјааДцДЂЙмРэЕФвЊЧѓЃЌвђДЫNoSQLЪ§ОнПтГЩЮЊФПЧАбаОПгыгІгУЕФШШЕуЁЃ
ИљОнЪ§ОнДцДЂФЃаЭКЭЬиЕуЃЌNoSQLЪ§ОнПтПЩЗжЮЊ4жжЕфаЭРраЭЃКвдRedisЁЂMemcachedЮЊДњБэЕФМќжЕДцДЂЪ§ОнФЃаЭЃЌвдBigtableЁЂHBaseЮЊДњБэЕФСаЪНДцДЂЪ§ОнФЃаЭЃЌвдMongoDBЮЊДњБэЕФЮФЕЕДцДЂЪ§ОнФЃаЭЃЌвдМАвдNeo4jЮЊДњБэЕФЭМаЮДцДЂЪ§ОнФЃаЭЁЃRedisГЃБЛгІгУдкЩчНЛСьгђЃЌгУРДДцДЂгУЛЇЙиЯЕКЭМЦЪ§ЁЃгЩгкЩњВњЙ§ГЬжаЖрдДвьЙЙЪ§ОнЖдЪЕЪБадвЊЧѓНЯИпЃЌвђДЫRedisдкжЦдьвЕЪ§ОнДцДЂжаГЃБЛгУзїЛКДцЯЕЭГЃЌвдБЃеЯЪ§ОнДцДЂЕФЕЭЪБбгадЁЃдкЕчСІМЦСПВЩМЏЯЕЭГжаЃЌЛљгкRedisЕФЗжВМЪНаДЛКДцзгЯЕЭГгУгкЛКДцВЩМЏЕФМЦСПЪ§ОнЃЌдйХњСПаДШыЙиЯЕЪ§ОнПтЁЃдкДѓаЭЛњаЕЩшБИЕФЪ§ОнВЩМЏгыДцДЂжаЃЌамаЄРкЕШШЫдкЪ§ОнВуЛљгкRedisЪЕЯжСЫЪЕЪБЪ§ОнЕФНтЮіЛКДцЃЌЪЙЯЕЭГОпгаИпаЇЛКДцЪ§ОнЕФФмСІЁЃGoogle BigtableПЊдДЪЕЯжЕФHBaseОпгаРЉеЙадКУЁЂБИЗнЛњжЦЭъЩЦЕФЬиеїЃЌЕБжЦдьвЕЩњВњЙ§ГЬЩцМАЖрдДвьЙЙЪ§ОнЕФЭГМЦЗжЮіЪБЃЌПЩЪЙгУHBaseЖдРДздИїИізгЯЕЭГЕФЪ§ОнНјааЭЌВНећКЯДцДЂЁЃР§ШчЃЌдкЗжВМЪНЕчдДПижЦЯЕЭГжаЃЌПЩвдЪЕЯжИїИіЗжВМЪНЕчдДЯЕЭГЕФдЫаазДЬЌЪ§ОнжСHBaseЪ§ОнПтЕФЭЌВНЁЃВщбЏгябдЙІФмЧПДѓЕФЮФЕЕДцДЂЪ§ОнПтMongoDBЪЪКЯЪ§ОнСПДѓЁЂЪ§ОнФЃаЭЮоЗЈШЗШЯЁЂашвЊЖдНгЖрИіЪ§ОндДЕШЕФГЁОАЃЌЪ§ОнРДдДИДдгЪЧжЦдьвЕЩњВњЙ§ГЬЖрдДвьЙЙЪ§ОнЕФжївЊЬиЕужЎвЛЃЌвђДЫMongoDBГЃБЛгУгкЖрИіЪ§ОндДЛђзгЯЕЭГЕФЖдНгЁЃдкЙЄвЕЩњВњжаЃЌMongoDBПЩгУгкЖдЙ§ГЬЕФСЌајМрПиЃЛдкЛьФ§ЭСаавЕжаЃЌMongoDBгУРДДцДЂКЃСПЕФЛьФ§ЭСЩњВњЯћКФЪ§ОнЃЌВЂЪЕЯжЖрИіЯЕЭГжЎМфЕФЪ§ОнЖдНгЃЛдкЕчСІаавЕЃЌ MongoDBПЩвдЪЕЯжЕчЭјЭМаЮЕФЖрЪБЬЌЁЂЖрМЖЗжВМЪНДцДЂЁЃ
еыЖдЙЄвЕжЦдьвЕЙ§ГЬЪ§ОнВњЩњЫйТЪПьЃЌЪЕЪБадвЊЧѓИпЃЌЖдЪТЮёЕФдзгадЃЈatomicityЃЉЁЂвЛжТадЃЈconsistencyЃЉЁЂИєРыадЃЈisolationЃЉЁЂГжОУадЃЈdurabilityЃЉ ЃЈМДACIDЃЉвЊЧѓЕЭЕФЬиЕуЃЌЗыЕТТзЬсГіСЫNoSQLЪ§ОнПтКЯРэзщКЯЕФЙЄвЕРњЪЗЪ§ОнДцДЂЗНАИЁЃеыЖджЦдьвЕЩњВњЙ§ГЬЖрдДвьЙЙЪ§ОнЕФРДдДИќМгЖрбљЛЏЕФЗЂеЙЧїЪЦЃЌ NoSQLЪ§ОнПтгыЦфЫћММЪѕЯрНсКЯЕФДѓЪ§ОнЦНЬЈЛђНтОіЗНАИНќФъРДвВгаВЛЩйАИР§ЁЃедЕТЛљЕШШЫЬсГіСЫЛљгкDubboгыNoSQLЕФЙЄвЕСьгђДѓЪ§ОнЦНЬЈЃЌеыЖдЙЄвЕЖрдДвьЙЙЪ§ОнЕФНгЪеЁЂДцДЂЁЂМЦЫуЁЂЗжЮіМАеЙЪОЃЌИљОнВЛЭЌГЁОАЕФвЕЮёашЧѓЬсЙЉСЫЯргІЕФНтОіЗНАИЁЃЮФАєАєКЭдјЯзЛдЬсГіСЫвЛжжЛљгкДЋЭГЪ§ОнПтЖрБэМмЙЙгыNoSQLДѓЪ§ОнПтЯрНсКЯЕФаТаЭЪ§ОнДцДЂЗНАИЪЕЯжЪЕЪБЪ§ОнЕФЗжВМЪНДцДЂЁЃ
Г§ДЫжЎЭтЃЌ451 GroupЕФЗжЮіЪІAslett MЬсГіСЫNewSQLММЪѕЃЌЦфОпгаNoSQLЖдКЃСПЪ§ОнЕФДцДЂЙмРэФмСІЃЌЭЌЪБЛЙБЃГжСЫДЋЭГЪ§ОнПтжЇГжACIDКЭSQLЕФЬиадЃЌЕЋФПЧАгІгУЗЖЮЇДѓЖрЮЊзЈгаШэМўЛђЬиЖЈГЁОАЁЃЖдгкЩЯЪіМИжжЕфаЭЕФЪ§ОнПтММЪѕЃЌБЪепЖдЪ§ОнПтФЃаЭЁЂжЇГжЕФЪ§ОнРраЭКЭгІгУГЁОАЕШНјааСЫЖдБШЃЌНсЙћМћБэ3ЁЃ
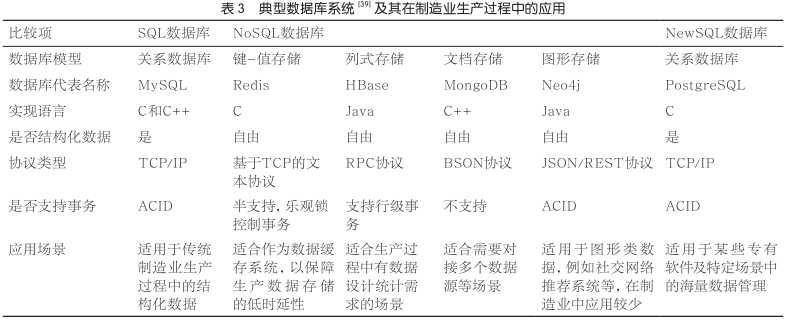
вдЩЯМИжжЕфаЭЕФЪ§ОнПтММЪѕОљгаЦфЬиЖЈЕФгХЪЦМАгІгУГЁОАЃЌЖјдкЬиЖЈИДдгЕФгІгУГЁОАжаЃЌЕЅвЛЕФЪ§ОнПтЭљЭљФбвдТњзуШЫУЧЖдЪ§ОнДцДЂЙмРэЕШЖрЗНУцЕФвЊЧѓЃЌРюЖЋПќКЭЖѕКЃКьЬсГіСЫЙиЯЕаЭЪ§ОнПтВЛФмЭъШЋБЛNoSQLЪ§ОнПтЬцДњЕФЙлЕуЃЌВЂЛљгкHibernate OGMНЈСЂСЫЭГвЛЕФSQLКЭNoSQLЪ§ОнПтЗУЮЪФЃаЭЃЌЪЙЕУСНРрЪ§ОнПтФмЙЛдкЭЌвЛИіПђМмЯТАДееЭГвЛЕФЙцдђНјааЖСаДЁЃвђДЫЃЌИљОнОпЬхЕФгІгУГЁОАЃЌбЁдёВЛЭЌРраЭЕФЪ§ОнПтНјааЛьКЯВПЪ№ЃЌЪЙЪ§ОнПтжЎМфаЮГЩЛЅВЙЃЌЪЧФПЧАЖрдДвьЙЙЪ§ОнДцДЂЙмРэЕФЗЂеЙЧїЪЦЁЃ
3.2.2 Ъ§ОнЧхЯДгызЊЛЛ
зМШЗПЩППЕФЪ§ОнЪЧНјаагааЇЪ§ОнЗжЮіЁЂЪ§ОнЭкОђЕФЧАЬсЁЃдкЪЕМЪЕФЩњВњЙ§ГЬжаЃЌгЩгкЖрдДвьЙЙЪ§ОнРДдДжкЖрЕФЬиеїЃЌВЩМЏЕНЕФЪ§ОнЕФжЪСПФбвдБЃжЄЃЌШБЪЇЕФЁЂДэЮѓЕФЁЂВЛвЛжТЕФЕШВЛЗћКЯЙцЗЖЕФЁАдрЪ§ОнЁБЦеБщДцдкЃЌЭЌЪБРДздВЛЭЌЯЕЭГЕФЪ§ОнЕФИёЪНвВВЂВЛЭГвЛЃЌетаЉЖМЛсИјЪ§ОнЕФгааЇЗжЮіДјРДРЇФбЁЃЪ§ОнЧхЯДЕФФПЕФОЭЪЧМьВтЪ§ОнжаДцдкЕФЁАдрЪ§ОнЁБЃЌЭЈЙ§Ъ§ОнЩИбЁЁЂЪ§ОнаоИДЕШЪжЖЮЬсИпЪ§ОнЕФжЪСПЁЃЖјЪ§ОнзЊЛЛжївЊЪЧНЋЖрдДвьЙЙЪ§ОнзЊЛЛГЩЭГвЛЕФФПБъЪ§ОнИёЪНЃЌВЂЭъГЩЖдВЛЭЌЪ§ОнжИБъНјаазЊЛЛЕФМЦЫуЁЃ
еыЖдЩњВњЙ§ГЬжаВЛЭЌЕФЮЪЬтЪ§ОнЃЌПЩвдИјГіВЛЭЌЕФЪ§ОнЧхЯДЗНЗЈЁЃгЩгкжЦдьвЕЩњВњЙ§ГЬжаЕФЖрдДвьЙЙЪ§ОнЭљЭљРДздЖрИіЪ§ОндДЃЌИїЪ§ОндДЭЈГЃОпгаВЛЭЌЕФЪ§ОнПтЯЕЭГЁЂНгПкЗўЮёЕШЃЌвђДЫЪ§ОнОпгаНсЙЙРраЭЖрбљЁЂБэДяаЮЪНВЛЭГвЛЕШЬиЕуЃЌетОЭЕМжТВЩМЏЕФЪ§ОнжаЛсДцдкЪ§ОнШБЪЇЁЂЪ§ОнДэЮѓЁЂЪ§ОнВЛвЛжТЕШЮЪЬтЁЃЖдгкШБЪЇЕФЪ§ОнЃЌДѓЖрЪ§ЧщПіЯТашвЊЪжЙЄНјааЬюШыЃЌФГаЉЧщПіЯТПЩвдЭЈЙ§ЭГМЦбЇЯАЕФЗНЗЈЖдШБЪЇжЕНјааДІРэЁЃВмСжеыЖдОпгаОлРрЬиеїЕФЪ§ОнМЏЃЌЬсГіСЫвЛжжЛиЙщВхВЙЕФШБЪЇжЕЧхЯДПђМмЁЃЖдгкДэЮѓЪ§ОнЃЌЪзЯШРћгУЭГМЦЗжЮіЕФЗНЗЈЖдПЩФмГіЯжЕФДэЮѓжЕНјааЪЖБ№ЃЌШЛКѓВХФмЖдДэЮѓЪ§ОнНјааЧхГ§ЃЌДяЕНЪ§ОнЧхЯДЕФФПЕФЁЃЖдгкВЛвЛжТЕФЪ§ОнЃЌПЩвдЛљгкЙиСЊЪ§ОнжЎМфЕФвЛжТадРДМьВтЪ§ОнЧБдкЕФДэЮѓЃЌВЂНјаааоИДЃЌвдЭъГЩЖдЖрЪ§ОндДЪ§ОнЕФЧхРэЁЃ
ЖдгкжЦдьвЕЩњВњЙ§ГЬжаЕФЖрдДвьЙЙЪ§ОнРДЫЕЃЌЕЅвЛЕФЪ§ОнЧхЯДЗНЗЈФбвдТњзуЪЕМЪашЧѓЃЌетОЭашвЊвЛИіЯЕЭГЕФЪ§ОнЧхЯДЗНАИЁЃETLЃЈextractЁЂtransformЁЂloadЃЉЙЄОпЪЧвЛРрГЃгУЕФДѓЪ§ОндЄДІРэЙЄОпЃЌгІгУЙуЗКЕФгаЙњЭтПЊдДЕФKettleЙЄОпЁЂIBMЙЋЫОЕФDatastageвдМАInformaticaЃЌЦфдкЪ§ОнЧхЯДЛЗНкЗЂЛгзХЪЎЗжживЊЕФзїгУЁЃвВгааэЖрбаОПШЫдБАДееВЛЭЌЕФашЧѓЖдETLММЪѕНјааСЫИФНјгыЭъЩЦЁЃжмхЋеТЕШШЫЩшМЦСЫвЛжжЛљгкЧјгђЛЎЗжЫуЗЈЕФETLИпаЇЪ§ОнЧхЯДЗНАИЃЌНтОігІгУETLЪБВњЩњЕФДѓСПДэЮѓЪєадЪ§ОнЕФЮЪЬтЁЃETLЙЄОпВЛНідкЪ§ОнЧхЯДЗНУцОпгаЙуЗКЕФгІгУЃЌЭЌЪБвВЪЧЪ§ОнзЊЛЛЕФжївЊЙЄОпЁЃЫяАВНЁЕШШЫЩшМЦСЫвЛжжПЩвдЦСБЮвьЙЙЪ§ОндДЗУЮЪВювьЕФЭЈгУETLЙЄОпЃЌЬсЙЉСЫДѓСПзЊЛЛзщМўРДСщЛюДІРэИДдгЕФгІгУГЁОАЁЃГТгёЖЋКЭвІЧрЬсГіСЫвЛжжгІгУгквЕЮёСїГЬЪ§ОнЕФзЊЛЛЙцдђЃЌЭЈЙ§ЩшМЦСїГЬЪ§ОнзЊЛЛЫуЗЈРДНЋСїГЬШежОжаЕФЪ§ОнПьЫйзМШЗЕизЊЛЛГЩЦРЙРЯЕЭГашвЊЕФБъзМЪ§ОнЁЃ
Г§ДЫжЎЭтЃЌеыЖдВЛЭЌЕФжЦдьвЕУХРрМАЪ§ОнВЩМЏЗНЗЈЃЌгаВЛЭЌЕФЪ§ОнЧхЯДЗНАИЁЃеыЖдRFIDВЩМЏЪ§ОнЪЕЪБадЧПЁЂЪ§ОнСПДѓЕФЬиЕуЃЌгрНмКЭЭѕюЃЬсГіСЫЛљгкЪБМфКЭЛљгкЪБМфМфИєЕФВМТГФЗТЫВЈФЃаЭЃЌПЩвддкЕЭФкДцЕФЧщПіЯТБЃжЄЪ§ОнгІгУЕФЪЕЪБадЁЃеыЖдЩњВњГЕМфжЦдьЮяСЊЛЗОГЯТВЩМЏЕНЕФЪ§ОнСЌајадЁЂШпградЧПЕФЬиЕуЃЌРЖВЈЕШШЫЬсГіСЫвЛжжЛљгкПЈЖћТќТЫВЈФЃаЭЕФЛЌЖЏДАПкММЪѕЃЌИУММЪѕИќМгЪЪгУгкRFIDБъЧЉвЦЖЏЕФЩњВњГЁОАЁЃетаЉбаОПеыЖдВЛЭЌЕФЩњВњжЦдьГЁОАЁЂВЛЭЌЕФВЩМЏЪ§ОнРраЭКЭЬиЕуЃЌЖдЪ§ОнЧхЯДЗНЗЈНјааСЫИФНјКЭЭъЩЦЃЌЪЙЦфИќМгЪЪгІЪЕМЪгІгУЕФашвЊЁЃ
ФПЧАЃЌЩюЖШбЇЯАКЭжкАќММЪѕПЊЪМдкЪ§ОнЧхЯДЛЗНкЕУЕНгІгУЁЃКТЫЌЕШШЫЬсГіСЫРћгУЩюЖШбЇЯАФЃаЭНтОіИДдгЪ§ОнЧхЯДШЮЮёЕФЗНЗЈЁЃеыЖдВЮгыепЫЎЦНВЮВюВЛЦыдьГЩЪ§ОнЧхЯДжЪСПНЯЕЭЕФЧщПіЃЌЭђвЋUЕШШЫЬсГіСЫдкОіВпНзЖЮРћгУГЩЪьМЦЫуЛњЫуЗЈРДЬсИпжкАќПЩППадЕФЗНАИЁЃЩюЖШбЇЯАПЩвдМѕЧсгУЛЇжЦЖЈЪ§ОнЧхЯДЙцдђЕФИКЕЃЃЌжкАќММЪѕНЋЪ§ОнЧхЯДШЮЮёЗЂЫЭЕНЛЅСЊЭјЃЌРћгУЙЋжкЕФВЮгыРДЬсИпЪ§ОнЧхЯДЕФаЇТЪЃЌЖўепгыДЋЭГЪ§ОнЧхЯДММЪѕЕФНсКЯЪЧЪ§ОнЧхЯДММЪѕдкЮДРДвЛЖЮЪБМфЕФЗЂеЙЧїЪЦЁЃЖдгкЪ§ОнзЊЛЛРДЫЕЃЌETLЙЄОпШдШЛЪЧЬсИпЪ§ОнжЪСПЁЂЦСБЮЪ§ОнВювьЕФЪзбЁЙЄОпЁЃвђДЫЃЌЖдETLЙЄОпздЩэЯжгаЕФРЉеЙадВюЁЂЕїЪдВЛБуРћЕШОжЯоадНјааИФНјКЭЭъЩЦЪЧЯТвЛВНбаОПгыПЊЗЂЕФжиЕуЁЃ
3.2.3 Ъ§ОнНЕЮЌ
ЖрдДвьЙЙЪ§ОнОпгажжРрЗБЖрЁЂНсЙЙИДдгЕФЬиЕуЃЌЮЊСЫДгдЪМЪ§ОнжаЬсШЁИќМгПЩППЁЂгааЇЕФЪ§ОнаХЯЂЃЌашвЊЯћГ§ЮоЙиЁЂШпгрЕФЬиеїЃЌЩњГЩаТЕФЬиеїЪ§ОнЃЌДгЖјЪЕЯжЖдИпЮЌЪ§ОнЕФНЕЮЌЁЃдкЯжДњжЦдьММЪѕЕФЗЂеЙжаЃЌжЦдьвЕЩњВњЙ§ГЬжаКЃСПЕФЖрдДвьЙЙЪ§ОнЭљЭљЮЌЪ§НЯИпЧвДѓСПЪ§ОнжЎМфДцдкНЯИпЕФЯрЙиадЃЌетИјЪ§ОнНЕЮЌДјРДСЫИќИпЕФФбЖШЁЃвЛАуРДЫЕЃЌПЩвдЭЈЙ§ЖдЪ§ОнНјааЬиеїбЁдёЛђепЬиеїЬсШЁРДЪЕЯжЪ§ОнНЕЮЌЁЃЬиеїбЁдёЕФЗНЗЈЭЈЙ§ЖддЪМЬиеїМЏКЯжаЕФдЊЫиНјаабЁдёРДЕУЕНдЪМЬиеїМЏКЯЕФзгМЏЃЌДгЖјЪЕЯжНЕЮЌЃЛЖјЬиеїЬсШЁЕФЗНЗЈдђЭЈЙ§ЖдВЛЭЌЬиеїНјаазщКЯРДЕУЕНаТЕФЬиеїМЏКЯЃЌДгЖјДяЕНЪ§ОнНЕЮЌЕФФПЕФЁЃ
ЬиеїбЁдёВЛИФБфЬиеїЕФКЌвхЃЌДгдЪМЬиеїЪ§ОнМЏжабЁдёОпгаДњБэадКЭЭГМЦвтвхЕФЬиеїЃЌвдЪЕЯжНЕЮЌЕФФПЕФЁЃЬиеїбЁдёЗНЗЈАќРЈЛљгкШЋОжЫбЫїЁЂЫцЛњЫбЫївдМАЦєЗЂЪНЫбЫїВпТдЕФЬиеїбЁдёЗНЪНКЭЛљгкFilterЁЂWrapperЕФЬиеїбЁдёЫуЗЈЁЃ
ШЋОжЫбЫїВпТдБщРњдЪМЬиеїМЏЃЌЭЈЙ§ЦРМлзМдђбЁдёТњзуЬиЖЈЬѕМўЕФЬиеїзгМЏЃЌЦфгХЕуЪЧПЩвдЕУЕНзюгХЬиеїзгМЏЁЃЕЋжЦдьвЕЩњВњЙ§ГЬжаЕФЖрдДвьЙЙЪ§ОнЭљЭљЪЧОпгаЖрИіЖРСЂЛђЯрЙиЪєадЕФИпЮЌЪ§ОнЃЌвђДЫдЫЫуГЩБОНЯИпЃЌдкЪЕМЪжаФбвдгІгУЁЃЫцЛњЫбЫїВпТдЪзЯШЫцЛњбЁдёЬиеїЃЌШЛКѓгУФЃФтЭЫЛ№ЫуЗЈНјааЫГађЫбЫїЃЌЛђгУвХДЋЫуЗЈНјааЮоЙцдђЫбЫїЃЌдйИљОнЗжРрЕФгааЇадЖдЬиеїИГгшШЈжиЃЌбЁдёШЈжиДѓгкЖЈвхуажЕЕФЬиеїЁЃгЩгкЫцЛњЫбЫївзЪмЫцЛњвђЫиЕФгАЯьЃЌВЛШЗЖЈадНЯИпЃЌВЛЭЌЕФВЮЪ§ЩшжУЖдЫцЛњЫбЫїНсЙћвВгаНЯДѓЕФгАЯьЁЃЦєЗЂЪНЫбЫїВпТдгжБЛГЦЮЊађЙсгХбЁЗЈЃЌПЩвдЪЕЯжзюгХЬиеїзгМЏгыМЦЫуИДдгЖШжЎМфЕФЦНКтЁЃЯрБШгкЧАСНжжЗНЗЈЃЌЦфИДдгЖШНЯЕЭЁЂаЇТЪИќИпЁЃГТНЈЛЊеыЖдЩшБИЙЪеЯжаЖдЪ§ОнМЏНЕЮЌЕФЮЪЬтЃЌЬсГіСЫвЛжжЛљгкЙиСЊЙиЯЕгыЦєЗЂЪНЫбЫїзщКЯЕФЬиеїбЁдёЗНЗЈЃЌЬиеїзгМЏЭЈЙ§ЫЋЯђЫбЫїЫуЗЈВњЩњЃЌВЂЭЈЙ§МЦЫуЪєаджЎМфЕФЙиСЊЙиЯЕРДЬоГ§ШпгрЪєадЃЌЬсИпСЫаЇТЪКЭзМШЗадЁЃ
ЛљгкFilterЕФЬиеїбЁдёжБНгИљОнЦРМлзМдђЖдЪ§ОнЕФЭГМЦЬиеїНјааЦРМлЃЌШЅГ§живЊГЬЖШЕЭЕФЬиеїЃЌбЁГіЕФЬиеїзгМЏвЛАуЙцФЃНЯДѓЃЌЪЪКЯзїЮЊЬиеїдЄЩИбЁЦїЁЃЛљгкWrapperЕФЬиеїбЁдёвРРЕКѓајЗжРрЫуЗЈЃЌНЋзгМЏЕФбЁдёПДзїЫбЫїбАгХЮЪЬтЃЌИљОнЗжРрЦїЕФзМШЗТЪРДЖдЬиеїзгМЏНјааЦРМлЃЌЦфЗжРраЇТЪгыОЋЖШЖМНЯИпЁЃжЦдьЙ§ГЬжаЕФЖрдДвьЙЙЪ§ОнЭљЭљЬиеїжкЖрЧвЙиЯЕИДдгЃЌЬяЮФвёЬсГіСЫеыЖдИпЮЌжЦдьЙ§ГЬЕФНсКЯЦЋзюаЁЖўГЫЛиЙщгыWrapperЬиеїбЁдёЕФЛьКЯЬиеїбЁдёЗНЗЈЃЌЭЌЪБеыЖджЦдьвЕЩњВњЪ§ОнГЃГіЯжЕФРрБ№МфВЛЦНКтЮЪЬтЃЌЬсГіСЫвЛжжЛљгкG-MeanЕФаТЕФЛьКЯЬиеїбЁдёЗНЗЈЃЌдкНЕЮЌФмСІКЭЗжРрадФмЗНУцОљШЁЕУСЫСМКУЕФНсЙћЁЃ
ЬиеїЬсШЁЭЈЙ§НЋдЪМЬиеїБфЛЛГЩОпгаОпЬхЮяРэвтвхЛђЭГМЦвтвхЕФЬиеїЃЌНЋИпЮЌЕФЬиеїЯђСПБфЛЛЮЊЕЭЮЌЕФЬиеїЯђСПЁЃгЩгкжЦдьвЕЩњВњЙ§ГЬжаЕФЖрдДвьЙЙЪ§ОнРДдДгкжЦдьЩњВњИїИіЛЗНкжаЕФЩшБИЁЂВњЦЗаХЯЂЕШЃЌОпгаНЯЧПЕФзЈвЕадМАЙиСЊадЃЌвђДЫдкНјааЪ§ОнЬиеїЬсШЁЪБЛсИќМгзЂжиЬиеїБГКѓЕФЮяРэвтвхвдМАЬиеїжЎМфЕФЙиСЊадЁЃДЋЭГЕФЬиеїЬсШЁЗНЗЈАќРЈЯп аджїГЩЗжЗжЮіЃЈprincipal component analysisЃЌPCAЃЉЁЂЯпадХаБ№ЗжЮіЃЈlinear discriminant analysisЃЌLDAЃЉЁЂЖРСЂГЩЗжЗжЮіЃЈindependent component analysisЃЌICAЃЉЁЂЗЧЯпадЕФКЫжїГЩЗжЗжЮіЃЈkernel principal component analysisЃЌ KPCAЃЉЁЂКЫЖРСЂГЩЗжЗжЮіЗЈЃЈkernel independent component analysisЃЌ KICAЃЉЁЃ
жїГЩЗжЗжЮіЗЈжївЊЭЈЙ§ЙлВтБфСПФкВПЕФЯрЛЅЙиЯЕРДећРэаХЯЂЃЌНЋПЩФмЯрЙиЕФдЪМЪ§ОнМЏзЊЛЛГЩЯпадВЛЯрЙиЕФаТЬиеїМЏКЯЃЌЪЕЯжИпЮЌЪ§ОнЯђЕЭЮЌЪ§ОнЕФбЙЫѕЁЃдкЗФжЏвЕжаЃЌСѕКЃОќЕШШЫРћгУБОЩЋВМЮЦРэЕФздЯрЙиадЬиеїЃЌВЩгУжїГЩЗжЗжЮіЗЈШЅГ§ЦфЯрЙиадЃЌЕУЕНСЫЮЦРэЕФжїГЩЗжЃЌНЋдкжїГЩЗжЗНЯђЩЯбљБОЭМЯёЕФбЙЫѕНсЙћзїЮЊЬиеїБфСПЃЌНјааЗжРрМьВтЃЌЕУЕНСЫНЯИпЕФЗжРрзМШЗЖШЁЃдкУКПѓОЎЯТЙЉЕчЯЕЭГЙЪеЯМьВтжаЃЌЙљЗявЧЕШШЫЭЈЙ§ЖдЪБЦЕгђБфЛЛЕФЛиТЗЕчСїЬиеїОиеѓЕФЦцвьжЕНјаажїГЩЗжЗжЮіЃЌЕУЕНСЫЙЪеЯЪЖБ№ЕФЬиеїЃЌНјвЛВНВЩгУвХДЋЫуЗЈгХЛЏЕФжЇГжЯђСПЛњЖдЙЪеЯЕчЛЁЬиеїЕФгааЇадНјааВтЪдЃЌПЩвдгааЇЪЖБ№ЕчЛњМАБфЦЕЦїИКдиЛиТЗЕФДЎСЊЙЪеЯЕчЛЁЁЃеыЖдЛњаЕзАБИжЦдьвЕЩњВњЙ§ГЬЖдМгЙЄЩшБИвРРЕГЬЖШИпЕФЮЪЬтЃЌвІЗЦЬсГіСЫвЛжжЖдБИМўдЄВтРэТлЕФДДаТадЬНЫїЃЌРћгУЛљгкжїГЩЗжЗжЮіКЭжЇГжЯђСПЛњЕФзлКЯЫуЗЈНјааашЧѓдЄВтЃЌДгЖјЪЕЯжЖдЩшБИБИМўашЧѓЕФдЄВтЁЃжїГЩЗжЗжЮіЗЈЪЪКЯДІРэГЪИпЫЙЗжВМЕФдЪМЪ§ОнЃЌЕЋЪЕМЪЩњВњЙ§ГЬжаЖрдДвьЙЙЪ§ОнЗжВМЕФИДдгГЬЖШдЖГЌИпЫЙЗжВМЃЌетЯожЦСЫжїГЩЗжЗжЮіЗЈЕФгІгУЁЃ
ЯпадХаБ№ЗжЮіЗЈЪЧгаМрЖНЕФЬиеїЬсШЁЗНЗЈЃЌНЕЮЌКѓдкаТЕФзгПеМфжаЪЙЭЌРрЬиеїОЁПЩФмНгНќЁЂВЛЭЌРрЬиеїОЁПЩФмЗжЩЂЃЌгыжїГЩЗжЗжЮіЗЈвЛбљЃЌвВЪЪКЯгУгкДІРэИпЫЙЗжВМЪ§ОнЁЃеыЖдФЃФтЕчТЗЙЪеЯеяЖЯжаЙЪеЯЪ§ОнЕФЬиеїЬсШЁЗНЗЈЃЌаЄгШКЕШШЫЖдФЃФтЙЪеЯЪ§ОндкжїдЊБфЛЛПеМфНјааЯпадХаБ№ЗжЮіЃЌВЂНЋзюгХХаБ№ЬиеїФЃЪНгІгУгкФЃЪНЗжРрЦїЃЌдкГфЗжМђЛЏФЃЪНЗжРрЦїФЃаЭМАНЕЕЭЯЕЭГдЫааГЩБОЕФЛљДЁЩЯЛёЕУСЫНЯКУЕФеяЖЯНсЙћЁЃСэЭтЃЌдкЭМЯёЪЖБ№Ъ§ОнЗжЮіжаЃЌЯпадХаБ№ЗжЮіЗЈвВЪЧвЛИіЪЎЗжОпгагХЪЦЕФЙЄОпЁЃдкЖдЧІЫсаюЕчГиXЩфЯпЭМЯёЕФЬиеїЬсШЁжаЃЌбюН№ЬУЕШШЫЗжБ№ВЩгУжїГЩЗжЗжЮіЗЈЁЂЯпадХаБ№ЗжЮіЗЈвдМАЖўДЮЯпадХаБ№ЗжЮіЗЈЃЌзюжеЕУГіЖўДЮЯпадХаБ№ЗжЮіЗЈдкИУЭМЯёЪЖБ№жаОпгаНЯИпЪЖБ№ТЪЕФНсТлЁЃ
ЖРСЂГЩЗжЗжЮіЗЈНЋдЪМЪ§ОнЗжНтЮЊШєИЩЖРСЂЗжСПЕФЯпадзщКЯЃЌИќЪЪКЯгУгкДІРэЗЧИпЫЙЗжВМЕФЧщПіЁЃбюГхЕШШЫВЩгУЖРСЂГЩЗжЗжЮіКЭжїГЩЗжЗжЮіСНжжГЃгУЗНЗЈЖджЦНЌдьжНЗЯЫЎДІРэЙ§ГЬжаЕФДЋИаЦїЙЪеЯНјааМьВтЃЌгЩгкжЦНЌдьжНЗЯЫЎДІРэЙ§ГЬжаЕФЪ§ОнГЪЗЧИпЫЙЗжВМЃЌICAЕФећЬхЙЪеЯМьВтТЪИпгкPCAЁЃеыЖдЙіЖЏжсГадкдыЩљБГОАЯТВњЩњЙЪеЯЪБЕФеёЖЏаХКХЃЌНЊЛГБѓРћгУЖРСЂГЩЗжЗжЮідкЪ§ОнЖРСЂадЗжЮіЗНУцЕФгХЪЦЃЌЬсГіСЫвЛжжЖРСЂдЊКЫFDAЃЈICA-KFDAЃЉЙЪеЯМьВтФЃаЭЃЌЬсИпСЫЙЪеЯеяЖЯЕФзМШЗТЪЃЌНЕЕЭСЫТЉМьТЪЁЃ
ЖдгкЭМЯёЪгЦЕЕШГЪЗЧЯпадЗжВМЕФЪ§ОнЃЌашвЊЪЙгУЗЧЯпадЕФЬиеїЬсШЁЗНЗЈЁЃКЫжїГЩЗжЗжЮігЩScholkopf BЕШШЫдкPCAЕФЛљДЁЩЯЬсГіЃЌНЋдЪМЪ§ОнЭЈЙ§КЫКЏЪ§гГЩфЕНИпЮЌЖШПеМфКѓЃЌдйРћгУPCAНјааНЕЮЌЁЃеыЖда§зЊЛњаЕНсЙЙжажсГазДЬЌЕФЪЖБ№ЃЌаЛЗцдЦЕШШЫЬсГіСЫСЃзгШКгХЛЏКЫжїГЩЗжЗжЮіЗЈЃЌЖджсГаЕФИДКЯЬиеїМЏНјааЬиеїЬсШЁЃЌМЬЖјгЩжЇГжЯђСПЛњЖдЪЖБ№ЬиеїМЏНјааЪЖБ№ЗжРрЃЌЬсИпСЫжсГазДЬЌЪЖБ№ЕФзМШЗТЪЁЃЖдгкаааЧГнТжДЋЖЏЯЕЭГЙЪеЯЃЌКихћКЭЭѕзкбхгУСЃзгШКгХЛЏЗНЗЈИФЩЦСЫКЫжїГЩЗжЗжЮіЗЈЖдЗЧЯпадЮЪЬтЕФЗжЮіЃЌаТЗНЗЈдкаааЧГнТжФЅЫ№ГЬЖШЕФЪЖБ№КЭеяЖЯжаШЁЕУСЫСМКУЕФНсЙћЁЃ
КЫЖРСЂГЩЗжЗжЮіЗЈвВЪЧРћгУЯрЭЌЕФЫМЯыдкICAЕФЛљДЁЩЯНјааРЉеЙЕФЃЌНќФъРДБЛЙуЗКгІгУдкЗЧЯпадЛьЕўЕФдДЗжРыММЪѕжаЁЃеыЖда§зЊЛњаЕНсЙЙжаЕФЙіЖЏжсГаЙЪеЯЃЌСѕМЮЛдЕШШЫЬсГіСЫвЛжжШЋЪИЦзКЭЖРСЂЗжСПЗжЮіЃЈITDКЭKICAЃЉЯрНсКЯЕФУЄдДЗжРыЗЈЃЌЖдВЩбљЕФЙіЖЏжсГаЙЪеЯаХКХНјаагааЇЕФаХдыЗжРыЃЌдкНЕдыЕФЭЌЪБФмЙЛИќМгШЋУцЁЂзМШЗЕиЬсШЁаХЯЂЃЌВЂНјаажсГаЙЪеЯеяЖЯЁЃеыЖдЛЏЙЄаавЕЕФШѓЛЌгЭЩњВњЙ§ГЬЃЌаэССЕШШЫЬсГіСЫЛљгкЛьКЯКЫКЏЪ§ЕФKICA-LSSVMЙЪеЯЗжРрЗНЗЈЃЌЬсИпСЫЙЪеЯеяЖЯЕФЫйЖШКЭзМШЗадЁЃ
Г§СЫЖдетаЉДЋЭГЕФЬиеїЬсШЁЗНЗЈНјаагХЛЏвдЭтЃЌеыЖджЦдьвЕЩњВњЙ§ГЬжаЪ§ОнЕФЬиЕуЃЌвЛаЉбаОПЬсГіСЫВЛЭЌЕФЗНЗЈЖдЪ§ОнЬиеїНјааЬсШЁЁЃеыЖдЩњВњЯжГЁДЋИаЦїЪБжгВюБ№МАЩњВњЩшБИдЫаадРэЕМжТЕФВЛЭЌЪ§ОндДжЎМфПЩФмДцдкбгГйЙиСЊЕФЮЪЬтЃЌеХЪиРћЕШШЫЬсГіСЫвЛжжУцЯђЪБбгЕФДЋИаЦїЪ§ОнЬиеїЬсШЁЗНЗЈЃЌРћгУЛљгкЦЄЖћбЗЯрЙиЯЕЪ§ЕФЧњЯпХХЦыЫуЗЈЕїећВЛЭЌДЋИаЦїЪ§ОнжЎМфЕФЪБМфЃЌЪЙЕУЕїећжЎКѓЕФЪ§ОнЯрЙиадДяЕНзюДѓЁЃУчАЎУёЕШШЫЬсГіСЫвЛжжЛљгкОжВПЯпадЧЖШыЃЈlocally linear embeddingЃЌ LLEЃЉЕФЗЧЯпадЙЪеЯМьВтаТММЪѕЃЌПЩвдгааЇЕиМЦЫу ГіБЃСєСЫОжВПСкгђНсЙЙаХЯЂЕФЪ§ОнЕФЕЭЮЌЧЖШыЁЃЩаГЌЕШШЫеыЖджЦдьЩњВњЙ§ГЬжаФГаЉВњЦЗжЪСПКЭЙиМќБфСПЪМжеФбвддкЯпВтСПЕФЮЪЬтЃЌЙЙНЈСЫвЛжжЛљгкРњЪЗВтСПЪ§ОнЧ§ЖЏЕФШэДЋИаЦїЃЌДгЖјЖдетаЉБфСПНјааЮШЖЈПЩППЕФдкЯпЙРМЦЁЃ
ЫцзХжЦдьвЕЖрдДвьЙЙЪ§ОнжаЗЧНсЙЙЛЏЪ§ОнЫљеМЗнЖюЕФдіЖрЃЌЖдЖрдДвьЙЙЪ§ОнЕФЬиеїЬсШЁдкЪ§ОнДІРэжаЕФживЊадвВДѓДѓдіМгЃЌЖјдкЮДРДвЛЖЮЪБМфФкЃЌЖдгкЖрдДвьЙЙЪ§ОнДІРэЦНЬЈРДЫЕЃЌЖдЪЕЪБЪ§ОнвдМАИпЮЌЖШЪ§ОнМЏЕФЬиеїЬсШЁШдШЛЪЧвЛИіЬєеНЁЃЭЌЪБЃЌгЩгкЙЄвЕЩњВњЛЗОГЕФИДдгадЃЌеыЖдЙЄвЕЩњВњЙ§ГЬжаЕФЪ§ОнНЕЮЌЃЌвЊИќЖрЕиНсКЯвЕЮёГЁОАБОЩэЃЌРћгУЯШбщжЊЪЖЛђепзЈМвжЊЪЖЖдЪ§ОнНјааНЕЮЌЁЃ
3.3 Ъ§ОнЗжЮі
Ъ§ОнЗжЮіЪЧЖрдДвьЙЙЪ§ОнДІРэЕФЙиМќЃЌЪЧжИдкЪ§ОнВЩМЏгыЪ§ОнМЏГЩЛЗНкЕФЛљДЁЩЯЖдЙЄвЕЩњВњЪ§ОнЕФаХЯЂКЭжЊЪЖНјааЬсШЁЃЌЦфФПЕФЪЧРћгУЪ§ОнЭкОђЁЂЛњЦїбЇЯАЁЂЭГМЦЗжЮіЕШММЪѕЖдМЏГЩЕФЖрдДвьЙЙЪ§ОнНјааЗжЮіКЭДІРэЃЌДгЖјЬсШЁГігаМлжЕЕФаХЯЂКЭжЊЪЖЃЌгУгкМьВтжЦдьЩњВњдЫаазДПіКЭЩњВњВњЦЗжЪСПМьВтЁЂжИЕМШЫдБзіОіВпЕШЁЃеыЖдЙЄвЕЩњВњжаЕФЪ§ОнЗжЮіММЪѕЕШЮЪЬтЃЌЦфЫћбЇепвВгаЯрЙибаОПЃЌЕЋБОЮФДгИќЙуЕФгІгУСьгђМАИќШЋУцЕФЗНЗЈЕФНЧЖШЖджЦдьвЕЩњВњЙ§ГЬжаЕФЪ§ОнДІРэЗНЗЈНјаазлКЯбаОПЁЃФПЧАЃЌЪ§ОнЗжЮіЛЗНкЕФЙиМќММЪѕАќРЈЙиСЊЗжЮіЁЂЗжРрЗжЮіКЭОлРрЗжЮіЕШЁЃ
3.3.1 ЙиСЊЗжЮі
Ъ§ОнЙиСЊЗжЮіОЭЪЧЗЂЯжБэУцПДРДЮоЙцТЩЕФЪ§ОнМфЕФЙиСЊадЃЌДгЖјЗЂЯжЪТЮяжЎМфЕФЙцТЩадКЭЗЂеЙЧїЪЦЕШЁЃГЃгУЕФЙиСЊЙцдђЭкОђЫуЗЈАќРЈAprioriЫуЗЈКЭFP-GrowthЫуЗЈЁЃ
AprioriЫуЗЈЪзЯШЭЈЙ§БщРњЪ§ОнПтШЗЖЈЦЕЗБЯюМЏЃЌШЛКѓИљОнжЇГжЖШуажЕНјаааоМєЃЌзюКѓИљОнжЇГжЖШРДМЦЫуПЩаХЖШЃЌДгЖјШЗЖЈЙиСЊЙцдђЃЌЪЧвЛжжБЛЙуЗКгІгУЕФЙиСЊЙцдђЭкОђЫуЗЈЁЃеыЖдДѓаЭЛЏКЭИДдгЛЏЕФЛњаЕзАБИжЦдьвЕЩњВњЙ§ГЬжавьГЃЪТМўЗЂЩњИХТЪИпЁЂБЈОЏЪ§СПОоДѓЕФЮЪЬтЃЌЗЎКчЬсГіСЫЛљгкЪ§ОнЭкОђAprioriЫуЗЈЕФЙЄвЕЙ§ГЬБЈОЏДІРэЗНЗЈЃЌЫѕаЁСЫжиИДБЈОЏЕФЪ§СПЃЌЬсЩ§СЫЖдБЈОЏЪТМўЕФДІРэаЇТЪЁЃЕЋЪЧИУЫуЗЈШдШЛДцдкашвЊЦЕЗББщРњЪ§ОнПтДгЖјВњЩњДѓСПКђбЁМЏЕФЮЪЬтЁЃеыЖдетвЛЮЪЬтЃЌжмПЕШШЫЬсГіСЫвЛжжНіашЖдЪ§ОнПтЩЈУшвЛДЮМДПЩЪЕЯжИФНјAprioriЫуЗЈЃЌПЩвдгааЇЕиЬсИпВњЩњгааЇЦЕЗБЯюМЏЕФаЇТЪЁЃГ§ДЫжЎЭтЃЌСѕЗМКЭЮтЙуГБЬсГіСЫвЛжжНЋЪ§ОнПтзЊЛЛЮЊОиеѓаЮЪНЃЌЭЈЙ§ЫѕаЁКђбЁЯюМЏЙцФЃЁЂМѕЩйЮогУКђбЁЯюМЏЩњГЩРДЬсИпЫуЗЈаЇТЪЕФЗНЗЈЁЃ
FP-GrowthЫуЗЈЪЧЖдAprioriЫуЗЈзюОЕфЕФИФНјЃЌВЩгУЦЕЗБФЃЪНЪїЃЈFP-treeЃЉДцДЂЦЕЗБЯюМЏЃЌМѕЩйЪ§ОнПтЩЈУшДЮЪ§ЁЃеыЖджЦдьвЕЩшБИЖдПьЫйзМШЗеяЖЯЩшБИЙЪеЯЕФашЧѓЃЌеХБѓЕШШЫЬсГіСЫвЛжжЛљгкаЫШЄЪєадСаЕФИФНјFP-GrowthЫуЗЈЕФЪ§ОнЭкОђЗНЗЈЃЌДгЖјЪЕЯжЖдЙЄвЕЩњВњЩшБИЙЪеЯЕФПьЫйзМШЗеяЖЯЁЃеыЖдТжЬЅжЦдьЙ§ГЬжажЪСПвьГЃЕФЮЪЬтЃЌРюУєВЈЕШШЫЬсГіСЫвЛжжИФНјКѓЕФFP-GrowthВЂааЫуЗЈЃЌИУЫуЗЈФмЙЛИпаЇЕиевЕНгАЯьТжЬЅжЪСПЕФвђЫиЁЃСэЭтЃЌеыЖдFPGrowthЫуЗЈжаДцдкЕФFP-treeеМОнПеМфЙ§ДѓЕФЮЪЬтЃЌЙЫОќЛЊЕШШЫЭЈЙ§ЖдFP-TreeЕФЙцФЃДѓаЁКЭМЦЫуСПвдМАF-ListЗжзщВпТдНјаагХЛЏЃЌЬсГіСЫвЛжжаТЕФЛљгкSparkЕФВЂааFP-GrowthЫуЗЈЁЊЁЊBFPGЫуЗЈЁЃ
Г§ЩЯЪіСНжжЪ§ОнЙиСЊЗжЮіЫуЗЈЭтЃЌгЩгкжЦдьЩњВњЙ§ГЬжаЪ§ОнСПдкВЛЖЯдіМгЃЌдкЯпЕФЖЏЬЌЪ§ОнЙиСЊЗжЮіОпгаИќМгЯжЪЕЕФвтвхЁЃHidber CЬсГіСЫвЛжждкЯпЕФЙиСЊЗжЮіЪ§ОнЭкОђЫуЗЈЁЊЁЊCARMAЫуЗЈЃЌИУЫуЗЈОпгадкЯпЪЕЯжЪ§ОнЙиСЊЗжЮіЁЂОЋЖШИпЁЂдЪаэгУЛЇдкЯпЕїећуажЕЕФгХЕуЁЃДЫКѓЃЌгкРіЕШШЫЗжБ№ЖдЫуЗЈЕФВЮЪ§ЙРМЦЁЂЪ§ОнМЏБщРњДЮЪ§НјааСЫгХЛЏИФНјЃЌЬсИпСЫЫуЗЈЕФЫйЖШМАОЋЖШЁЃШчНёЃЌCARMAЫуЗЈдкдЄВтКЭПижЦСьгђЕУЕНСЫЙуЗКгІгУЁЃ
ФПЧАЙиСЊЗжЮіЗНЗЈДцдкжюЖрВЛзуЃЌШчКЮРћгУЙиСЊЙцдђЫуЗЈЖдЗЧНсЙЙЛЏЪ§ОнНјаагааЇДІРэЁЂШчКЮНЋЙиСЊЙцдђЫуЗЈгыЦфЫћЕФОіВпЗНЗЈНсКЯвдЪЕЯжИќзМШЗЕФЪ§ОнЗжЮіЕШЃЌОљгаД§НјвЛВНЕФбаОПКЭЗЂеЙЁЃ
3.3.2 ЗжРрЗжЮі
ЖдгкжЦдьвЕЩњВњЙ§ГЬЕФЪ§ОнЗжЮіРДЫЕЃЌЪ§ОнЕФЗжРрММЪѕЪЧЪЕЯжЪ§ОнаХЯЂЭкОђМАНсЙћдЄВтЕФЪЎЗжживЊЕФЗНЗЈжЎвЛЁЃ
ЗжРрЪЧжИЭЈЙ§ЫуЗЈНЋЪ§ОнЛЎЗжЕНвбОЖЈвхКУЕФРрБ№жаЁЃГЃгУЕФЗжРрЫуЗЈАќРЈОіВпЪїЫуЗЈЁЂЛљгкЙцдђЕФЗжРрЗЈЁЂШЫЙЄЩёОЭјТчЫуЗЈЁЂЩюЖШбЇЯАЫуЗЈЁЂжЇГжЯђСПЛњЃЈSVMЃЉЫуЗЈЁЂБДвЖЫЙЫуЗЈЕШЁЃ
ОіВпЪїЭЈЙ§ЖдЪ§ОнМЏЕФЗжЮіЙщФЩНјаабЇЯАЃЌгІгУЗЖЮЇЙуЗКЃЌЖдгкkey-valueРраЭЕФЪ§ОнРДЫЕЪЧзюгХбЁдёЁЃФПЧАЃЌНЯЮЊГЃМћЕФОіВпЪїЗжРрЫуЗЈгаC4.5ЁЂSLIQКЭSPRINTЁЃОіВпЪїЫуЗЈдкЩњВњМЦЛЎАВХХЗНУцЕФгІгУБИЪмЙизЂЁЃеыЖдРыЩЂЙЄвЕЕФОВЬЌJob ShopЕїЖШЮЪЬтЃЌЭѕГЩСњЬсГіСЫгУОіВпЪїФЃаЭЬсШЁЕїЖШжЊЪЖЕФЗНЗЈЃЌЖдЩњВњЕїЖШЗНАИНјааСЫгХЛЏЁЃеыЖдЛњаЕзАБИжЦдьвЕЩњВњМЦЛЎжаЙЄЕЅМгЙЄЫГађКЭЭЌвЛЛњЦїВЛЭЌЙЄМўМгЙЄЫГађЕШРњЪЗЪ§ОнЃЌгквеКЦЬсГіСЫвЛжжПЩИљОнЪЕЪБЪ§ОнЮЊЙЄМўАВХХКЯЪЪЕФЛњЦїЕФОіВпЪїФЃаЭЃЌДяЕНСЫжЦдьГЕМфИљОнЩњВњзДЬЌЪЕЪБгХЛЏЕїЖШЕФаЇЙћЁЃСэЭтЃЌдкВњЦЗжЪСПМьВтгыЗжЮіЗНУцЃЌОіВпЪїЫуЗЈвВгаЗЧГЃЙуЗКЕФгІгУЁЃеыЖдЮвЙњРфдўЫсЯДВњЦЗЩњВњММЪѕЩаВЛГЩЪьЁЂВњЦЗБэУцВЛКЯИёТЪНЯИпЕФЮЪЬтЃЌЙљСњВЈЭЈЙ§ЖдРфдўЫсЯДВњЦЗЪ§ОнЪЙгУЖўЗжОіВпЪїЕШЙЄОпНјааЗжЮіЃЌЕУГіСЫгАЯьРфдўЫсЯДВњЦЗБэУцжЪСПШБЯнЕФвђЫивдМАХаЖЈБъзМЃЌЪЙЦѓвЕФмЙЛИќИпаЇЁЂзМШЗЕиЖдВњЦЗШБЯнНјааМьВтЁЃЫЮНЈДЯЬсГіСЫвЛжжЛљгкC4.5ОіВпЪїЫуЗЈЕФЩњВњЙ§ГЬжЪСПЗжЮіФЃаЭЃЌЭЈЙ§евГів§Ц№жЪСПЮЪЬтЕФжївЊвђЫиРДЖдВњЦЗжЪСПШБЯнНјаад№ШЮЗжЮіКЭеяЖЯЃЌНјЖјВЩШЁеыЖдадЕФДыЪЉРДЬсИпВњЦЗКЯИёТЪЁЃ
ЛљгкЙцдђЕФЗжРрЗЈЪЧРћгУгУЛЇЮЊУПИіРржБНгШЗЖЈЕФЗжРрЙцдђРДаЮГЩРрБ№ФЃАхЃЌЙцдђЗжРрЦїЭЈЙ§ЭГМЦбљБОжаТњзуЗжРрЙцдђЕФЙцдђЪ§КЭДЮЪ§РДШЗЖЈбљБОжжРрЕФЗжРрЗНЗЈЃЌГЃгУРДВњЩњИќвзгкНтЪЭЕФУшЪіадФЃаЭЃЌИќЪЪгУгкДІРэРрЗжВМВЛЦНКтЕФЪ§ОнМЏЁЃдкФмКФЗжЮіЯЕЭГжаЃЌаэУїбѓЖдЛљгкЙцдђЕФНкФмДыЪЉЪЕЪЉЗжРрЫуЗЈЕФгІгУНјааСЫЗжЮіЃЌЛљгкЙцдђЕФЗжРрЗЈашвЊгУЛЇздМКбЇЯАЙцдђЃЌгыЦфЫћЗжРрЫуЗЈЯрБШЃЌСщЛюадгызМШЗадНЯВюЁЃ
ШЫЙЄЩёОЭјТчЃЈartificial neural networkЃЌANNЃЉОпгазджїбЇЯАЁЂШнДэадИпЕФЬиЕуЃЌЪЪКЯДІРэФЃК§ЁЂЗЧЯпадЕФЪ§ОнЃЌЦфжаЧАРЁЪНЩёОЭјТчФЃаЭГЃгУгкЗжРрЫуЗЈЁЃЦфжаЃЌЗДЯђДЋВЅЃЈback propagationЃЌBPЃЉЩёОЭјТчЫуЗЈжївЊРћгУЗДЯђДЋВЅЫуЗЈЖдЭјТчЕФШЈжЕКЭЦЋВюНјааЗДИДЕїећбЕСЗЃЌЪЙЪфГіЕФЯђСПОЁПЩФмНгНќЦкЭћЯђСПЁЃЕЋгЩгкЦфЫцЛњЛёШЁЭјТчГѕЪМШЈжиКЭуажЕЕФЬиЕуЃЌBPЩёОЭјТчОпгаЪеСВЪБМфГЄЁЂвзЯнШыОжВПзюгХНтЕФШБЕуЁЃжмИЃРДЁЂеХЯИеўЕШШЫЁЂЙизгЦцЕШШЫЁЂЯФгБтљОљЛљгквХДЋЫуЗЈЖдBPЩёОЭјТчНјааСЫгХЛЏЃЌДгЖјЪЕЯжСЫЖдГнТжЩшБИЙЪеЯЁЂКИНгШлГиееЖШвдМАЕЖОпЪйУќЕШЕФОЋШЗеяЖЯЁЃРюЪРПЦВЩгУСаЮФВЎИёТэПфЖћЬиЃЈLevenberg-MarquardtЃЌLMЃЉЫуЗЈЖдBPЩёОЭјТчНјааИФНјЃЌЖдвКбЙжЇМмЖЅСКЦЃРЭЪйУќНјааСЫОЋШЗЕФдЄВтЁЃТоаЃЧхгІгУжїдЊЗжЮіЗЈЖдBPЩёОЭјТчНјааСЫгХЛЏЃЌзюжеЪЕЯжСЫЖдЛњаЕЩшБИЙЪеЯЕФзМШЗХаЖЯКЭМАЪББЈОЏЁЃ
ЩюЖШбЇЯАзюдчЦ№дДгкЖдШЫЙЄЩёОЭјТчЕФбаОПЃЌзюдчгЩЖрТзЖрДѓбЇЕФHinton G EЕШШЫдк2006ФъЬсГіЃЌжИЛљгкбљБОЪ§ОнЕФАќКЌЖрВуДЮЕФЩюЖШЭјТчНсЙЙЕФЛњЦїбЇЯАЙ§ГЬЁЃЩюЖШбЇЯАБОжЪЩЯЪєгкЛњЦїбЇЯАЕФЗЖГыЃЌЪЧЛњЦїбЇЯАСьгђвЛИіаТЕФбаОПЗНЯђЃЌдкЭМЯёЁЂгявєЁЂЮФБОЗжРрЪЖБ№ЗНУцОпгаЗЧГЃКУЕФгХЪЦЃЌОпгаЧПДѓЕФЖдВЛЭЌРраЭЪ§ОнЕФДІРэФмСІЃЌвђДЫЖджЦдьвЕЩњВњЙ§ГЬжаЕФЪ§ОнЗжЮіЦ№ЕНЗЧГЃДѓЕФзїгУЁЃШчНёБЛЙуЗКЪьжЊЕФЩюЖШбЇЯАЛљБОФЃаЭАќРЈЩюЖШЩёОЭјТчЃЈdeep neural networkЃЌDNNЃЉЁЂбЛЗЩёОЭјТчЃЈrecurrent neural networkЃЌ RNNЃЉЁЂОэЛ§ЩёОЭјТчЃЈconvolutional neural networkЃЌCNNЃЉЁЂЩюЖШжУаХЭјТчЃЈdeep belief networkЃЌDBNЃЉЕШЁЃЩюЖШЩёОЭјТчПЩвдМђЕЅЕиРэНтЮЊКЌгаЖрИівўВиВуЕФЩёОЭјТчЃЌЦфгХЪЦЬхЯждкЖдЮоБъЧЉЪ§ОнЕФздЮвбЇЯАЁЃЖдгкЛњаЕЩшБИжаГЃМћЕФДЋЖЏСуМўГнТжЕФЙЪеЯМрВтЃЌРюМЮСеЕШШЫгІгУЩюЖШЩёОЭјТчРДеяЖЯдчЦкГнТжЕуЪДЙЪеЯЃЌНЋВЩМЏЕФеёЖЏаХКХжБНгзїЮЊDNNЪфШыЃЌПЩвдгааЇНтОіЬиеїЬсШЁЛЗНкдьГЩЕФНЯДѓЮѓВюЃЌгыДЋЭГANNеяЖЯНсЙћЯрБШЃЌЙЪеЯеяЖЯТЪЕУЕНСЫЬсИпЁЃеыЖджЦдьГЕМфжаЙиМќЕЖОпЩшБИЕФЪйУќдЄВтЮЪЬтЃЌСѕЪЄЛдЕШШЫНЋаЁВЈАќЗжЮіЗНЗЈЕУЕНЕФНсЙћзїЮЊЪфШыРДбЕСЗЩюЖШЩёОЭјТчЃЌНЈСЂЕЖОпЪЃгрЪйУќдЄВтФЃаЭЃЌПЩЖдЧаЯїЕЖОпЪЃгрЪйУќНјааОЋШЗЕФдЄВтЁЃОэЛ§ЩёОЭјТчЪЧвЛжжАќКЌОэЛ§МЦЫуЕФЧАРЁЩёОЭјТчЃЌГЄЦквдРДЪЧЭМЯёЪЖБ№СьгђЕФКЫаФЫуЗЈжЎвЛЁЃВмДѓРэЕШШЫВЩгУОэЛ§ЩёОЭјТчздЪЪгІЕиЬсШЁЬиеїЃЌБмУтСЫШЫЮЊЬсШЁЕФОжЯоадЃЌЬсИпСЫЕЖОпФЅЫ№дкЯпМрВтЕФОЋЖШЁЃЮтжОбѓЕШШЫеыЖдВМЦЅЩњВњжаЕФВМЦЅшІДУМьВтЃЌЬсГіСЫвЛжжЛљгкЩюЖШОэЛ§ЩёОЭјТчЕФЕЅЩЋВМЦЅшІДУМьВтЫуЗЈЃЌКмКУЕиНтОіСЫШЫЙЄМьВтаЇТЪЕЭЁЂЮѓМьТЪИпЕФЮЪЬтЁЃХэДѓЧлЕШШЫЬсГіСЫвЛжжЛљгкОэЛ§ЩёОЭјТчЕФвКОЇУцАхШБЯнМьВтЫуЗЈЃЌВЂдкДЋЭГЕЅЯђЬиеїШкКЯЕФЛљДЁЩЯЬсГіСЫЫЋЯђЬиеїШкКЯЕФЭјТчНсЙЙЃЌЬсИпСЫМьВтОЋЖШЁЃРюЙуЕШШЫеыЖдЙЄвЕжаГЃМћЕФЛњДВЕЖОпЯћКФШпгрЮЪЬтЃЌВЩгУвьГЃМьВтОэЛ§ЩёОЭјТчЃЈCNN-ADЃЉЖдЛњДВЕЖОпЕФБРШаНјаазМШЗдЄВтЁЃбЛЗЩёОЭјТчЪЧвЛРргУгкДІРэКЭдЄВтађСаЪ§ОнЕФЩёОЭјТчФЃаЭЃЌгыДЋЭГЛњЦїбЇЯАЗНЗЈЯрБШЃЌЦфЖдгкЪфШы/ЪфГіЪ§ОнУЛгаЙ§ЖрЯожЦЃЌПЩвдгУРДДІРэЮФБОЁЂвєЦЕКЭЪгЦЕЕШађСаЪ§ОнЁЃеыЖдШМУКЕчеОNOxХХЗХдЄВтФЃаЭНЈФЃжаЪфШыБфСПЬиеїМЏШЗЖЈРЇФбЕФЮЪЬтЃЌЭѕЮФЙуКЭедЮФНмЬсГіСЫвЛжжЛљгкЪ§ОнЧ§ЖЏЕФУХПибЛЗЕЅдЊЃЈgated recurrent unitЃЌGRUЃЉбЛЗЩёОЭјТчФЃаЭЃЌНЋGRUзїЮЊRNNЕФЩёОЭјТчЕЅдЊЃЌДгЖјЪЙRNNФмЙЛЗжЮіГЄЪБМфЕФЪБМфађСаЮЪЬтЃЌЖдШМУКЕчеОЙјТЏNOxХХЗХЪЕЯжзМШЗдЄВтЁЃЖдгкЛљгкбЛЗЩёОЭјТчЕФЕчСІБфбЙЦїЙЪеЯеяЖЯФЃаЭДцдкЕФеяЖЯВЛЧхЮњЁЂЪеСВЫйЖШТ§ЕФШБЯнЃЌРюПЁЗхЛљгкђљђ№ЫуЗЈЖдбЛЗЩёОЭјТчЕФВЮЪ§НјааСЫгХЛЏЃЌИФНјКѓЕФБфбЙЦїЙЪеЯеяЖЯФЃаЭЕФЪеСВадМАеяЖЯзМШЗТЪОљЕУЕНСЫНЯДѓЬсЩ§ЁЃЩюЖШжУаХЭјТчЭЈЙ§ФЃФтШЫРрДѓФдЖдЭтВПаХКХЕФДІРэРДЪЕЯжЙІФмЃЌЪЧгЩЖрИіЯожЦВЃЖћзШТќЛњЃЈrestricted Boltzmann machineЃЌRBMЃЉЕўМгзщГЩЕФЭјТчФЃаЭЁЃЭѕЯмБЃЕШШЫдЫгУЩюЖШжУаХЭјТчбЕСЗЭјТчЕФГѕжЕЃЌдйЭЈЙ§ЖдБШжиЙЙЭМЯёгыШБЯнЭМЯёЃЌЪЕЯжПьЫйзМШЗЕФЬЋбєФмЕчГиЦЌБэУцШБЯнМьВтЁЃРюУЮЪЋЕШШЫЬсГіСЫвЛжжЛљгкЩюЖШжУаХЭјТчЕФаТаЭЗчСІЗЂЕчЛњЙЪеЯеяЖЯЗНЗЈЃЌВЂЭЈЙ§гыДЋЭГМьВтЗНЗЈНјааЖдБШЃЌбщжЄСЫИУЫуЗЈЕФТГАєадЁЃСѕКЦЕШШЫЬсГіСЫвЛжжЛљгкЖрВЮЪ§гХЛЏЩюЖШжУаХЭјТчЕФЙіЖЏжсГаЭтШІЫ№ЩЫГЬЖШЪЖБ№ЗНЗЈЃЌПЩгааЇЕиЬсИпЙЪеЯЪЖБ№ЕФзМШЗадКЭЮШЖЈадЁЃФПЧАЩюЖШбЇЯАФЃаЭдкжЦдьЩњВњЪ§ОнЗжЮіжаЕФДѓжТЗЂеЙЗНЯђЪЧгыЦфЫћЫуЗЈЯрНсКЯЃЌЖдЩюЖШбЇЯАЛљБОФЃаЭжаЕФВЮЪ§ЁЂНсЙЙНјаагХЛЏЃЌДгЖјЬсИпЫуЗЈЕФОЋШЗадгыТГАєадЃЌЪЕЯжИќОЋзМЕФМьВтгыдЄВтЁЃ
жЇГжЯђСПЛњЪЧвЛжжЭЈЙ§КЫКЏЪ§УтШЅИпЮЌБфЛЛЃЌжБНгНЋЕЭЮЌВЮЪ§ДњШыКЫКЏЪ§ДгЖјЕУГіИпЮЌЯђСПФкЛ§ЕФЗжРрЗНЗЈЃЌГЃгУгкЙЪеЯеяЖЯЁЃеыЖдЛњаЕжЦдьвЕжаЙіЖЏжсГадьГЩЕФЙЪеЯЪЖБ№ЮЪЬтЃЌТРе№гюЬсГіСЫвЛжжЪЙгУСзЯКШКЫуЗЈгХЛЏЕФжЇГжЯђСПЛњЃЌЖджсГазДЬЌНјааОЋШЗеяЖЯЃЌДгЖјОЋШЗЕиЪЖБ№ЙіЖЏжсГаЕФЙЪеЯРраЭЃЌНЯДЋЭГжЇГжЯђСПЛњЕФЪЖБ№ОЋЖШИќИпЁЃТРЮЌзкЕШШЫЬсГіСЫЛљгкСПзгСЃзгШКгХЛЏЃЈquantum particle swarm optimizationЃЌQPSOЃЉЫуЗЈгХЛЏЕФЯрЙиЯђСПЛњЃЈrelevance vector machineЃЌRVMЃЉЃЌВЂНјааЙЪеЯеяЖЯЃЌЯрНЯгкжЇГжЯђСПЛњЖјбдЃЌЦфИќЪЪгУгкаЁбљБОДІРэКЭдкЯпЙЪеЯеяЖЯЁЃ
БДвЖЫЙЗжРрЫуЗЈЪЧдкБДвЖЫЙЙЋЪНЕФЛљДЁЩЯЃЌРћгУИХТЪЭГМЦНјааЗжРрМЦЫуЕФЗНЗЈЁЃЦфжаЃЌЦгЫиБДвЖЫЙЗжРргІгУзюЙуЗКЁЃжЦдьЩњВњЙ§ГЬжаЩйВЛСЫЕчГиЪйУќгыЕчСІЙЪеЯЕФЮЪЬтЃЌNg S S YЕШШЫеыЖдВЛЭЌЙЄзїЛЗОГЮТЖШМАЗХЕчЕчСїЧщПіЃЌЬсГіСЫгУгкВЛЭЌЙЄзїзДПіЯТЕчГиЙРМЦКЭЪЃгрЪЙгУЪйУќдЄВтЕФЦгЫиБДвЖЫЙФЃаЭЁЃРюУЮцУЕШШЫЛљгкдіСПЪНБДвЖЫЙЫуЗЈЃЌЬсГіСЫвЛжжЪЕЪБаддкЯпЕчТЗЙЪеЯеяЖЯЗНЗЈЃЌПЩвдЭЌЪБЪЕЯждкЯпЕчТЗЙЪеЯеяЖЯЕФИпОЋШЗадгыИпЪЕЪБадЁЃ
ФПЧАЗжРрЗжЮіЗНЗЈдкЙЄвЕЩњВњжавбОгаЙуЗКЕФгІгУЃЌгШЦфЪЧЛљгкЛњЦїбЇЯАЕФЗжРрЗНЗЈЁЃЕЋЪЧЯжНзЖЮЕЅвЛЕФЪ§ОнЗжРрЗНЗЈВЂВЛОпгаНЯИпЕФзМШЗадМАПЩППадЃЌашвЊВЛЭЌЫуЗЈЕФШкКЯВХФмВњЩњНЯЮЊПЩППЕФЪ§ОнЗжРрМАдЄВтНсЙћЁЃШЛЖјВЛЭЌЫуЗЈЕФШкКЯЪЦБиЛсдьГЩЯЕЭГЪБбгЃЌШчКЮЦНКтЯЕЭГЕФПЩППадКЭЪЕЪБадЪЧбаОПЕФЗНЯђжЎвЛЁЃСэЭтгЩгкЙЄвЕЩњВњЕФЬиЪтадКЭИДдгадЃЌеыЖдЭЌвЛРрЗжРрЮЪЬтЃЌВЂУЛгаЭЈгУЕФЗжРрЗНЗЈПЩвдЪЙгУЃЌвЊЕУЕНПЩППЕФЗжРрНсЙћЃЌашвЊгыЪЕМЪГЁОАЁЂЪЕМЪвЕЮёЯрНсКЯЁЃЭЌЪБЃЌШчЙћвЊЕУЕННЯЮЊзМШЗЕФЗжРрНсЙћЃЌЗжРрЫуЗЈФЃаЭЕФбЕСЗЪ§ОнМЏашвЊНсКЯЩњВњСьгђЕФОбщжЊЪЖНјааЯргІЕФЬиеїЙЄГЬДІРэЁЃ
3.3.3 ОлРрЗжЮі
ОлРрОЭЪЧНЋЯрЫЦЕФЪ§ОнЙщЮЊвЛРрЃЌддђЪЧЪЙУПвЛРрЪ§ОнЕФЯрЫЦадзюДѓЁЃГЃгУЕФОлРрЫуЗЈАќРЈЛљгкЛЎЗжЕФОлРрЗНЗЈЁЂЛљгкВуДЮЕФОлРрЗНЗЈЁЂЛљгкУмЖШЕФОлРрЗНЗЈКЭЛљгкФЃаЭЕФОлРрЗНЗЈЫФДѓРрЁЃ
ЦфжаЃЌзюГЃгУЕФЪЧK-meansЫуЗЈЁЃK-meansЫуЗЈЪЧвЛжжЛљгкЛЎЗжЕФОлРрЗНЗЈЃЌЭЈЙ§ЫцЛњбЁдёKИіЪ§ОнЕузїЮЊГѕЪМОлРржааФЃЌИљОнЬиЖЈЕФОрРыЫуЗЈНЋД§ОлРрЕФЪ§ОнМЏЗжГЩKДиЁЃТІаЁЗМЭЈЙ§ЖдДѓСПТСЙЄвЕЩњВњРњЪЗФмКФЪ§ОнНјааДІРэЗжЮіЃЌдЫгУK-meansЫуЗЈЕШЗНЗЈЗжЮіЦфЙцТЩЃЌвдДЫжИЕМЩњВњВПУХИФНјВЮЪ§ЃЌНЕЕЭФмКФЁЃеыЖдФ№ОЦВЛСМЗЂНЭааЮЊдчЦкМЃЯѓЕФЪЖБ№ЃЌUrtubia AЕШШЫЭЈЙ§ЖдВњЦЗжа29жжГЩЗжМьВтЕФЪ§ОнВЩгУK-meansЫуЗЈНјааОлРрЗжЮіЃЌЛёЕУСЫВЛСМЗЂНЭааЮЊФЃаЭЃЌДгЖјЪЕЯжСЫЖдВњЦЗжЪСПЕФШЯЖЈЃЌМѕЩйСЫдчЦкааЮЊдьГЩЕФЫ№ЪЇЁЃЕЋИУЫуЗЈДцдкОлРрНсЙћЪмбЁдёЕФГѕЪМОлРржааФгАЯьНЯДѓЁЂДІРэДѓЪ§ОнЪБМфаЇТЪЕЭЕШШБЕуЁЃаьНЁШёКЭеВгРееНЋИФНјЕФK-meansЫуЗЈКЭЗжВМЪНМЦЫуПђМмSparkНсКЯЃЌЬсГіСЫДѓЪ§ОнЯТЕФПьЫйОлРрЫуЗЈSparkKMЃЌИУЫуЗЈМШУжВЙСЫОЕфK-meansЫуЗЈЕФВЛзуЃЌгжЗЂЛгСЫSparkЗжВМЪНМЦЫуДІРэЫйЖШПьЕФгХЪЦЁЃ
Г§ДЫжЎЭтЃЌГЃгУЕФОлРрЗНЗЈЛЙгаЛљгкУмЖШЕФDBSCANЫуЗЈЁЂЛљгкВуДЮЕФBIRCHЫуЗЈвдМАЛљгкФЃаЭЕФИпЫЙЛьКЯФЃаЭЃЈGMMЃЉЕШЁЃЛљгкУмЖШЕФDBSCANЫуЗЈЭЈЙ§ЖдКЫаФЕуЁЂБпНчЕуКЭдыЩљЕуЕФБъМЧЃЌНЋОпгаУмЖШЕФЧјгђЛЎЗжГЩДиЁЃеыЖдЗчСІЗЂЕчЩшБИжаЙЪеЯТЪзюИпЕФГнТжЯфКЭжїжсЕФЙЪеЯЪЖБ№ЮЪЬтЃЌСжЬЮЕШШЫРћгУDBSCANОлРрЫуЗЈЖддЫааЪ§ОнНјааУмЖШОлРрЃЌЖдГнТжЯфКЭжїжсЕФЙЪеЯНјааНЯзМШЗЕФеяЖЯЁЃеыЖдЕчСІЯЕЭГаХЯЂАВШЋЮЪЬтЃЌаЛОВбўЕШШЫВЩгУЦєЗЂЪНЕФздЪЪгІЫуЗЈЖдDBSCANЫуЗЈЕФВПЗжВЮЪ§НјааЙРМЦЃЌИФНјСЫОлРраЇЙћЃЌДгЖјЬсИпСЫаХЯЂАВШЋдЄОЏЗжЮіЕФзМШЗадЁЃЛљгкВуДЮЕФBIRCHЫуЗЈРћгУЪїНсЙЙНјааОлРрЃЌЪЪгУгкЪ§ОнСПДѓЁЂРрБ№Ъ§ЖрЕФЪ§ОнДІРэЁЃЖдгкФОВФМгЙЄжаФОВФШБЯнЕФЪЖБ№ЮЪЬтЃЌЮтЖЋбѓКЭвЕФўВЩгУBIRCHЫуЗЈЖдЪ§ОнМЏНјаавЛДЮЩЈУшМДПЩЕУЕННЯИпЕФОлРржЪСПЃЌЬсИпСЫЪЖБ№зМШЗТЪЁЃеыЖдЪГЦЗЮРЩњЕФHACCP ЃЈhazard analysis critical control pointЃЉздЖЏЗжРрЃЌвЖЗЩдОЕШШЫЬсГіСЫвЛжжЖруажЕЁЂЖрДњБэЕуЕФBIRCHЫуЗЈЃЌИУЫуЗЈПЩвдЪЪгІHACCPЗжРржаИїжжаЮзДЕФЪ§ОнМЏЁЃЛљгкФЃаЭЕФИпЫЙЛьКЯФЃаЭЪЧвЛжжШкКЯСЫВЮЪ§ФЃаЭКЭЗЧВЮЪ§ФЃаЭЕФгХЪЦЕФОлРрЗНЗЈЃЌГЃБЛгІгУдкгявєЪЖБ№ЁЂЭМЯёЪЖБ№ЕШСьгђЁЃеыЖдЛњаЕНсЙЙжавзЫ№ЛЕЕФЙіЖЏжсГаЃЌСњУњЕШШЫЬсГіСЫвЛжжЛљгкздЛиЙщИпЫЙЛьКЯФЃаЭЃЈAR-GMMЃЉЕФЙіЖЏжсГаЙЪеЯГЬЖШЦРЙРЗНЗЈЁЃЫќвддчЦкЮоЙЪеЯжсГаеёЖЏаХКХЕФARФЃаЭЬиеїЮЊЛљзМЬиеїЃЌв§ШыКѓЦкжсГаеёЖЏаХКХЕФARЬиеїЃЌПЩвдМрВтЙіЖЏжсГаИїжжаЮЪНЕФдчЦкЙЪеЯЁЃеыЖдгІгУЙуЗКЕФТнЫЈСЌНгЃЌЭѕИеЕШШЫРћгУМрВтЧјгђФкТнЫЈСЌНгНсЙЙЕФИїжжЫЩЖЏЙЄПіЕФЪЕЪБЪ§ОнНЈСЂИпЫЙЛьКЯФЃаЭЃЌЛљгкИпЫЙЛьКЯФЃаЭЕФИХТЪУмЖШЗжВМжЎМфЕФЯрЫЦЖШзюДѓзМдђЃЌПЩгааЇХаЖЯМрВтЧјгђТнЫЈЕФЫЩНєзДЬЌЁЃеыЖдгЁЛЈжЏЮяЕФБэУцДУЕуМьВтЃЌРюУєЕШШЫдкДЋЭГИпЫЙЛьКЯБГОАФЃаЭЕФЛљДЁЩЯв§ШыСЫздЪЪгІЗжПщНЈФЃЕФЫМЯыЃЌдкЬсИпгЁЛЈжЏЮяДУЕуМьВтзМШЗТЪЕФЭЌЪБЃЌФмгааЇЕиДІРэМьВтЙ§ГЬжаЕФЙтееВЛОљКЭдыЩљЕШЮЪЬтЁЃ
Ъ§ОнСПЕФбИЫйдіМгЪЙЕУЖдДѓЙцФЃЪ§ОнЕФЗжРрЁЂОлРрГЩЮЊОпгаЬєеНадЕФбаОПЮЪЬтЁЃЖдгкЗжРрЫуЗЈРДЫЕЃЌВЛЭЌЕФЫуЗЈОљгаЦфЖРЬиЕФгХЪЦвдМАЬиЖЈЕФгІгУСьгђЁЃЖдгкОлРрЫуЗЈРДЫЕЃЌДЋЭГОлРрЫуЗЈОЙ§ГщбљЛђНЕЮЌЛсЫ№ЪЇОЋШЗадЃЌЖјВЂааОлРрЫуЗЈОЁЙмОпгаЖдДѓЪ§ОнИпаЇЁЂСМКУЕФРЉеЙадЕШгХЕуЃЌЕЋЫуЗЈЪЕЯжНЯИДдгЁЃМђЕЅИпаЇЁЂРЉеЙадИпЕФУцЯђДѓЪ§ОнЧвВЛЯћКФИќЖрШэгВМўзЪдДЕФЗжРрОлРрЫуЗЈЪЧЮДРДЕФжївЊбаОПКЭгХЛЏЗНЯђЁЃ
4 НсЪјгя
БОЮФЖджЦдьвЕЩњВњЙ§ГЬжаЖрдДвьЙЙЪ§ОнЕФИХФюКЭРраЭЁЂЪ§ОнДІРэЕФЗНЗЈКЭММЪѕНјааСЫНЯЮЊШЋУцЕФзлЪіКЭЪсРэЁЃНЋЩњВњЙ§ГЬжаЕФЖрдДвьЙЙЪ§ОнАДееЪ§ОнРДдДКЭЪ§ОнРраЭНјааСЫЗжРрЃЌЖдЪ§ОнДІРэЕФећЬхСїГЬНјааСЫЖЈвхЃЌВЂЖдЪ§ОнДІРэЙ§ГЬжаЕФОпЬхЗНЗЈЁЂММЪѕМАЦфдкЩњВњЙ§ГЬжаЕФОпЬхгІгУНјааСЫзмНсЗжЮіЁЃ
ЫцзХЙЄвЕЮяСЊЭјЕФПьЫйЗЂеЙЃЌЪ§ОнЕФРДдДИќЖрЃЌЪ§ОнНсЙЙИќМгЖрбљЛЏЃЌЭЌЪБЩњВњЙ§ГЬжааХЯЂЯЕЭГЖдЪ§ОнДІРэЕФЪЕЪБадЁЂзМШЗадвЊЧѓИќИпЃЌетИјЖрдДвьЙЙЪ§ОнЕФДІРэДјРДСЫОоДѓЕФЬєеНЁЃЪзЯШЃЌЩшБИЕФЖрбљадКЭИДдгадЛсИјЪ§ОнВЩМЏЗНЗЈЁЂММЪѕДјРДаТЕФЬєеНЃЌашвЊдіМгИќЮЊЗсИЛЁЂПЩППЁЂИпаЇЕФЪ§ОнВЩМЏЗНЗЈКЭММЪѕЃЛЦфДЮЃЌКЃСПЕФЪ§ОнЖдЪ§ОнДцДЂММЪѕЕФШнСПКЭаЇТЪЁЂОЋЖШЕШЬсГіСЫИќИпЕФвЊЧѓЃЌвВЖдДЋЭГЕФSQLЁЂNoSQLЕШЪ§ОнДцДЂЯЕЭГЕФРЉеЙФмСІЬсГіСЫИќИпЕФвЊЧѓЃЌзлКЯЪ§ОнДцДЂЯЕЭГГЩЮЊЮДРДЗЂеЙЕФЧїЪЦЃЛзюКѓЃЌЪЕМЪЩњВњЖдЪ§ОнЧхЯДЁЂНЕЮЌМАЪ§ОнЗжЮіЗНЗЈКЭММЪѕЕФаЇТЪКЭОЋШЗЖШЕФвЊЧѓНјвЛВНЬсИпЁЃСэЭтЃЌжЛгаадФмИќИпЕФЪ§ОнДІРэЗжЮіЦНЬЈМАИќИпаЇЕФЪ§ОнЭкОђЫуЗЈВХФмТњзуДѓЙцФЃЖрдДвьЙЙЪ§ОнЕФЪЕЪБДІРэгыЗжЮівЊЧѓЁЃСэЭтЃЌЫцзХБпдЕМЦЫудкЙЄвЕЩњВњЙ§ГЬжаЕФПьЫйгІгУЃЌУцЯђБпдЕПижЦЦїЁЂБпдЕЭјЙиКЭБпдЕдЦЕФЪ§ОнВЩМЏЁЂДцДЂЁЂДІРэКЭЗжЮіЕФЗНЗЈКЭММЪѕЕФбаЗЂНЋГЩЮЊжиЕубаОПЗНЯђЁЃ
зїепМђНщ
ГТЪРГЌЃЈ1987-ЃЉЃЌФаЃЌАФУХПЦММДѓбЇМЦЫуЛњММЪѕМАгІгУзЈвЕВЉЪПЩњЃЌжаЙњПЦбЇдКздЖЏЛЏбаОПЫљИДдгЯЕЭГЙмРэгыПижЦЙњМвжиЕуЪЕбщЪвжњРэбаОПдБЃЌжївЊбаОПЗНЯђЮЊЪ§ОнДІРэЁЂЙЄвЕЮяСЊЭјЁЂБпдЕМЦЫу ЁЃ ДоДКгъЃЈ1998-ЃЉЃЌХЎЃЌОЭжАгкжаЙњПЦбЇдКздЖЏЛЏбаОПЫљИДдгЯЕЭГЙмРэгыПижЦЙњМвжиЕуЪЕбщЪвЃЌжївЊбаОПЗНЯђЮЊЪ§ОнДІРэЁЂБпдЕМЦЫу ЁЃ еХЛЊЃЈ1986-ЃЉЃЌХЎЃЌВЉЪПЃЌББОЉКНЬьжЧдьПЦММЗЂеЙгаЯоЙЋЫОЦНЬЈбаЗЂВПИпМЖЙЄГЬЪІЃЌжївЊбаОПЗНЯђЮЊЯжДњОЋУмВтСПЁЂЙЄвЕЮяСЊЭјКЭБпдЕМЦЫу ЁЃ ТэИъЃЈ1990-ЃЉЃЌФаЃЌВЉЪПЃЌжаЙњЙЄвЕЛЅСЊЭјбаОПдКжЧФмЛЏЫљЙЄГЬЪІЃЌжївЊбаОПЗНЯђЮЊЙЄвЕЛЅСЊЭјЁЂШЫЙЄжЧФмЁЂБпдЕМЦЫуЕШ ЁЃ жьЗяЛЊЃЈ1976-ЃЉЃЌФаЃЌВЉЪПЃЌжаЙњПЦбЇдКздЖЏЛЏбаОПЫљИДдгЯЕЭГЙмРэгыПижЦЙњМвжиЕуЪЕбщЪвИпМЖЙЄГЬЪІЃЌжївЊбаОПЗНЯђЮЊШЫЙЄНЛЭЈЯЕЭГЁЂЦНааНЛЭЈЙмРэЯЕЭГ ЁЃ ЩЬауЧлЃЈ1983-ЃЉЃЌХЎЃЌВЉЪПЃЌжаЙњПЦбЇдКздЖЏЛЏбаОПЫљИДдгЯЕЭГЙмРэгыПижЦЙњМвжиЕуЪЕбщЪвжњРэбаОПдБЃЌжївЊбаОПЗНЯђЮЊжЧФмжЦдьЕФЪ§ОнЧ§ЖЏНЈФЃгыгХЛЏММЪѕ ЁЃ амИеЃЈ1969-ЃЉЃЌФаЃЌВЉЪПЃЌжаЙњПЦбЇдКздЖЏЛЏбаОПЫљИДдгЯЕЭГЙмРэгыПижЦЙњМвжиЕуЪЕбщЪвбаОПдБЃЌжївЊбаОПЗНЯђЮЊИДдгЯЕЭГЦНааПижЦгыЙмРэЁЂжЧФмжЦдьЁЂжЧФмНЛЭЈ E-mailЃКxionggang@casc.ac.cnЁЃ
СЊЯЕЮвУЧ:
Tel:010-81055448
010-81055490
010-81055534
E-mail:bdr@bjxintong.com.cn
http://www.infocomm-journal.com/bdr
http://www.j-bigdataresearch.com.cn/
ДѓЪ§ОнЦкПЏ ЁЖДѓЪ§ОнЃЈBig Data ResearchЃЌBDRЃЉЁЗЫЋдТПЏЪЧгЩжаЛЊШЫУёЙВКЭЙњЙЄвЕКЭаХЯЂЛЏВПжїЙмЃЌШЫУёгЪЕчГіАцЩчжїАьЃЌжаЙњМЦЫуЛњбЇЛсДѓЪ§ОнзЈМвЮЏдБЛсбЇЪѕжИЕМЃЌББОЉаХЭЈДЋУНгаЯод№ШЮЙЋЫОГіАцЕФЦкПЏЃЌвбГЩЙІШыбЁжаЮФПЦММКЫаФЦкПЏЁЂжаЙњМЦЫуЛњбЇЛсЛсПЏЁЂжаЙњМЦЫуЛњбЇЛсЭЦМіжаЮФПЦММЦкПЏЃЌВЂБЛЦРЮЊ2018ФъЙњМвембЇЩчЛсПЦбЇЮФЯзжааФбЇЪѕЦкПЏЪ§ОнПтЁАзлКЯадШЫЮФЩчЛсПЦбЇЁБбЇПЦзюЪмЛЖгЦкПЏЁЃ
https://wap.sciencenet.cn/blog-3472670-1287069.html
ЩЯвЛЦЊЃК[зЊди]ЛљгкЩњГЩЖдПЙЭјТчЕФвНбЇЪ§ОнгђЪЪгІбаОП
ЯТвЛЦЊЃК[зЊди]ЛљгкЗжВузЂвтСІЭјТчЕФЗНУцЧщИаЗжЮі