博文
爬虫(一)
||
关于爬虫的定义和概念表述不赘述,相关参考内容较多,读者可自行查询 。主要介绍如何爬虫,爬虫目前采用的方式是代码和软件,代码爬虫方便快捷,自主性强,个人建议使用python爬取,有经验的小伙伴欢迎多交流 。

![]()
(一)软件爬虫
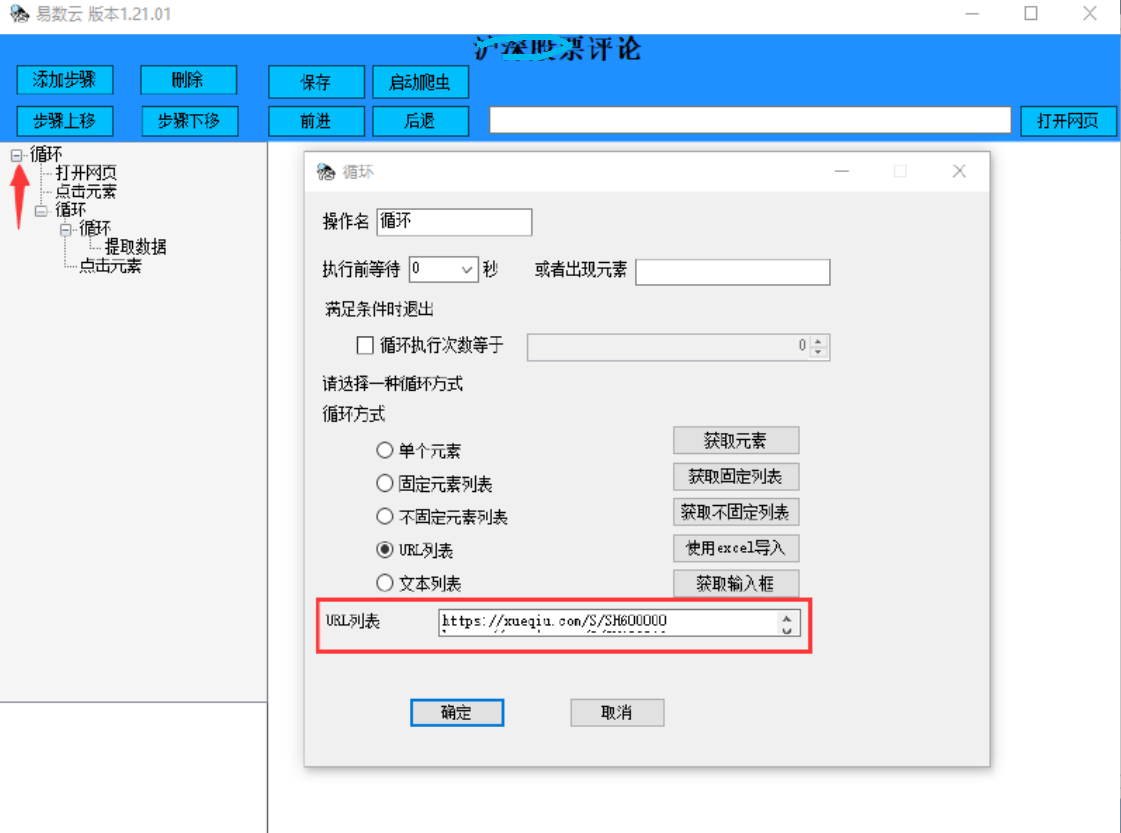
常用软件:八爪鱼、火车头、易数云。以下是案例与配图:
“本文选取上证50指数为股票市场的研究对象,同时需要在雪球网中爬取投资者的评论观点作为文本信息语料库。在网页中文本信息的爬取,主要采用网络爬虫进行爬取。网络爬虫是通过模拟浏览器发送网络请求,再通过接受请求相应来完成数据的提取。目前,在市场上有不同的爬虫软件供大家选择,使用率较高的如八爪鱼、火车头等。雪球网设置有双向的反爬取程序,本文通过多种爬虫软件进行使用,最终选择了易数云作为本文数据爬去的软件,在易数云软件上,可以自行定义爬虫规则。”
点滴分享,福泽你我!Add oil!
参考:
(1)《有限注意与A股市场股价回归预测--基于SVM与Logistic的比较研究》硕士文献
(2)如何入门爬虫(知乎):https://zhuanlan.zhihu.com/p/21479334/
(4)Python 爬虫介绍:https://www.runoob.com/w3cnote/python-spider-intro.html
(5)网络爬虫(爬虫策略)维基百科:https://zh.wikipedia.org/wiki/%E7%B6%B2%E8%B7%AF%E7%88%AC%E8%9F%B2
https://wap.sciencenet.cn/blog-3428464-1231018.html
上一篇:机器学习背后的数学(上)
下一篇:Logistic Regression(逻辑斯蒂回归)
扫一扫,分享此博文
全部作者的其他最新博文
- • [转载]太阳同步轨道
- • 膳食指南