博文
基于n-gram频率的语种识别改进方法
|
引用本文
郝洺, 徐博, 殷绪成, 王方圆. 基于n-gram频率的语种识别改进方法. 自动化学报, 2018, 44(3): 453-460. doi: 10.16383/j.aas.2018.c160806
HAO Ming, XU Bo, YIN Xu-Cheng, WANG Fang-Yuan. Improve Language Identification Method by Means of n-gram Frequency. ACTA AUTOMATICA SINICA, 2018, 44(3): 453-460. doi: 10.16383/j.aas.2018.c160806
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.2018.c160806
关键词
语种识别,短文本,n-gram频率,鲁棒性
摘要
识别短文本的语言种类是社交媒体中自然语言处理的重要前提,也是一个挑战性热点课题.由于存在集外词和不同语种相同词汇干扰的问题,传统基于n-gram的短文本语种识别方法(如Textcat、LIGA、logLIGA等)识别效果在不同的数据集上相差甚远,鲁棒性较差.本文提出了一种基于n-gram频率语种识别改进方法,根据训练数据不同特性,自动确定语言中特征词和共有词的权重,增强语种识别模型在不同数据集上的鲁棒性.实验结果证明了该方法的有效性.
文章导读
现如今, 随着社交媒体全球化的发展以及其以短文本作为主要载体的特点, 使得识别短文本的语言种类成为社交媒体中自然语言处理任务的一个挑战性热点课题.语种识别主要的解决方案是观察所有语言典型的字母序列发生的频率.早在1994年Cavnar等提出了基于n-gram的词频排序方法[1], 核心思想是比较语言模型文件和目标文本的n-gram词频排序列表.这个方法在400字以上的长文本取得了99.8%的准确率. Frank于2003年, 将这个方法实现成语种识别工具, 并命名为Textcat[2].
其他应用在短文本语种识别上的方法也有很多, Hammarstrom在2007年阐述了一个用词缀表来扩充词典的方法, 并且用一个平行语料库来进行测试[3]. Ceylan等在2009年提出了使用决策树来分类语言种类的方法[4], Vantanen等在2010年针对5~21个字符的文本, 提出了使用n-gram语言模型并结合朴素贝叶斯分类器的方法来实现语言种类的目的[5].
Carter等于2013年针对推特信息提出了基于用户先前消息和嵌入在消息中的连接的内容来实现语种识别的方法, 同时该方法也运用在TwitIE上[6]. Tromp等在2011年提出基于n-gram的图结构语种识别方法[7], 该方法不仅利用词本身的信息, 还有效利用了词与词之间的信息, 使得短文本的语种识别效率大大提升.随后Vogel等在此基础上做了改进[8].
在这期间, 又有很多语种识别工具被研发出来, Lui等在2012年利用n-gram特征结合多项式朴素贝叶斯分类器创造出langid.py[9]; Nakatani在同年发布了IDIG, 一个基于常识、正则化和贝叶斯分类器的语种识别工具[10], 该工具用于推特数据集. 2013年Brown提出基于n-gram字符特征权重的空间向量模型[11].
随着深度学习技术越来越成熟, 许多研究员开始思考如何将深度学习技术运用到语种识别中, 并且做了很多尝试.然而经过实践, 深度学习技术在语音领域有很好的效果[12-18], 与此同时, 面向语音领域的语种识别技术也愈发成熟[19-21].但对于短文本而言, 随着语料库不断地完善, 基于统计的机器学习方法更为简单高效[22-23].
然而, 传统基于n-gram的语种识别对数据集有很强的依赖. Baldwin等指出, 在6种欧洲语料集上取得良好的识别效果并不意味着在含有更多语种的语料集上会取得同样不错的效果[24]. Lui等对各个语种识别模型的评测实验中指出, 同一种模型在不同数据集上的准确率也相差甚远[25].同时他们也指出去除数据集中的噪音, 如推特数据集的特殊字符, 对识别率的提高有明显的帮助.
在本文中, 我们将Textcat、LIGA和logLIGA三个模型在Europarl[26]、LIGA-dataset、Twituser-21、Twituser-7四个数据集中分别做交叉验证, 同时, 我们使用Europarl做训练集, LIGA-dataset、Twituser-21、Twituser-7做测试集, 两组实验结果相差较大.因为在同一个数据集中, 训练集的内容往往涵盖了测试集或者跟测试集相近, 因此一旦训练集与测试集分别为两个不同的数据集, 那么测试集中会含有大量训练集中没有出现过的词, 即集外词.同时, 不同语种但属于同一种语系的语言, 会含有很多拼写相同的词(如英语和荷兰语都有“is”).在短文本中, 这些词汇在文中所占的比例要比长文本高得多, 对语种识别的正确率有一定的影响.
我们可以提高每一个语种特征词的权重, 提高单词在所属语种的辨识度, 这样不仅可以解决大类别语种数量增加而导致相似度计算的干扰, 同时使集外词在句子中所占比例减小, 减少集外词对语种识别的影响.此外我们还可以减少所有语种都含有的共有词的权重, 以降低其在短文本中所占的比重, 从而达到提高识别率的效果.
因此, 本文提出一个根据不同的训练数据, 自适应学习特征词和共有词的权重, 来增强语种识别模型在不同数据集的鲁棒性的方法, 并将其应用在Textcat、LIGA和logLIGA三个模型上, 实验证明了该方法的有效性.

图 1 Textcat方法识别流程
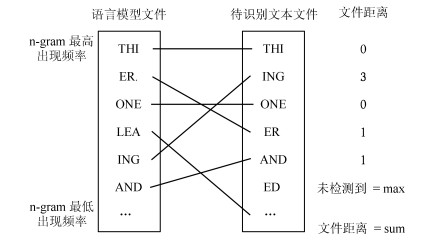
图 2 Textcat模型相似度计算

图 3 LIGA构造图模型样例
数据集的改变会让传统基于n-gram语种识别模型的准确率大打折扣, 增强模型在不同数据集上的鲁棒性能让模型在实际应用中更加有效.本文提出了一种通过动态调整语种特征词和共有词权重的方式, 提升传统模型识别性能的语种识别方法.实验证明了该方法的有效性.
作者简介
徐博
中国科学院自动化所副研究员.主要研究方向为自然语言处理, 深度学习, 短文本智能分析.E-mail:boxu@ia.ac.cn
殷绪成
北京科技大学计算机科学与技术系教授.主要研究方向为模式识别, 机器学习, 文档分析与识别, 信息检索.E-mail:xuchengyin@ustb.edu.cn
王方圆
中国科学院自动化研究所数字内容技术与服务研究中心副研究员.主要研究方向为模式识别, 多媒体信息处理.E-mail:fangyuan.wang@ia.ac.cn
郝洺
北京科技大学计算机与通信工程学院博士研究生.主要研究方向为自然语言处理, 短文本分类, 语种识别.本文通信作者.E-mail:minghao@xs.ustb.edu.cn
https://wap.sciencenet.cn/blog-3291369-1422371.html
上一篇:一种针对单快拍DOA估计的子空间搜索近似消息传递算法
下一篇:基于信号灯状态的燃油最优车速规划与控制