博文
一种基于随机权神经网络的类增量学习与记忆融合方法
|
引用本文
李德鹏, 曾志刚. 一种基于随机权神经网络的类增量学习与记忆融合方法. 自动化学报, 2023, 49(12): 2467−2480 doi: 10.16383/j.aas.c220312
Li De-Peng, Zeng Zhi-Gang. A class incremental learning and memory fusion method using random weight neural networks. Acta Automatica Sinica, 2023, 49(12): 2467−2480 doi: 10.16383/j.aas.c220312
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c220312
关键词
连续学习,灾难性遗忘,随机权神经网络,再可塑性启发
摘要
连续学习(Continual learning, CL)多个任务的能力对于通用人工智能的发展至关重要. 现有人工神经网络(Artificial neural networks, ANNs)在单一任务上具有出色表现, 但在开放环境中依次面对不同任务时非常容易发生灾难性遗忘现象, 即联结主义模型在学习新任务时会迅速地忘记旧任务. 为了解决这个问题, 将随机权神经网络(Random weight neural networks, RWNNs)与生物大脑的相关工作机制联系起来, 提出一种新的再可塑性启发的随机化网络(Metaplasticity-inspired randomized network, MRNet)用于类增量学习(Class incremental learning, Class-IL)场景, 使得单一模型在不访问旧任务数据的情况下能够从未知的任务序列中学习与记忆融合. 首先, 以前馈方式构造具有解析解的通用连续学习框架, 用于有效兼容新任务中出现的新类别; 然后, 基于突触可塑性设计具备记忆功能的权值重要性矩阵, 自适应地调整网络参数以避免发生遗忘; 最后, 所提方法的有效性和高效性通过5个评价指标、5个基准任务序列和10个比较方法在类增量学习场景中得到验证.
文章导读
人和其他高级动物可以在其一生中学习并记住许多技能, 这种连续学习不同任务的能力被称为连续学习(Continual learning, CL). 相比之下, 人工神经网络(Artificial neural networks, ANNs)在接受新任务训练时, 通常会迅速忘记如何执行之前的任务, 这种现象称为灾难性遗忘[1]. 从网络拓扑的角度来说, 遗忘的发生是由于连接主义网络的本质: 其信息均被存储在模型参数中, 直接在新任务上训练网络会修改连接权值并偏离旧任务, 从而不可避免地发生遗忘[2]. 从数据分布的角度来说, 大多数ANNs只是为了学习某一特定任务而建立, 其中训练与测试数据为独立同分布(Independently identical distribution, IID). 该条件假设了一种静态场景, 即数据分布不随时间的推移而发生变化. 然而, 现实世界中流式数据(Streaming data)的不确定性使得预训练模型无法应对非IID任务. 与此同时, 遗忘的发生并不是因为网络容量有限(同样的网络在交错或联合训练时仍可以学习许多任务)[3], 而是源于现实世界中流式数据往往以任务序列的形式先后出现, 其中每个任务的数据可能会在一段时间后消失, 甚至由于内存限制或隐私问题而无法存储或重新访问[4]. 因此, 研究有效且高效的CL方法以克服ANNs中的灾难性遗忘具有重要意义, 对于通用人工智能的发展也至关重要.
近年来, CL受到了越来越多的关注[5–8]. 根据学习过程中如何处理与利用特定于任务的信息, CL方法可以大致分为以下三类:
1) 扩展方法(Expansion method)[9–11]: 这类方法的典型特征为不断增加单独的模型参数以适应新类别, 即: 模型通过冻结以前的任务参数或者为每个任务分配一个副本, 从而逐步为新任务添加额外的网络分支. 例如, 文献[12]通过在新任务的训练过程中扩展网络节点, 提出一种可自适应更新的动态网络以增加对新类别的特征表征能力. 其虽然可以有效防止遗忘旧任务, 但往往会导致网络规模随着任务数量的增加而增加. 此外, 扩展方法通常受限于“多头” (Multi-heads)设置, 其中每个任务都具备一个专有的输出层, 而且测试阶段一般需要提供任务的身份(Task identities, Task-ID)才能正确匹配已经学过的、特定于该任务的头(Head)[7].
2) 重放方法(Replay method)[13–15]: 这类工作通过保存部分原始样本或使用生成模型生成伪样本, 以在学习新任务时进行联合训练. 作为一种经典的重放方法, 梯度情景记忆(Gradient episode memory, GEM)[16]在学习新任务时利用有限的历史数据依次限制每个任务的损失函数不增加. 在此基础上, 平均梯度情景记忆(Averaged GEM, A-GEM)[17]和逐层优化梯度分解(Layerwise optimization by gradient decomposition, LOGD)[18]分别通过考虑所有旧任务的平均损失来放松约束、在不同情景中指定共享和特定于任务的信息以缓解遗忘. 文献[19]进一步构建基于少数示范性样本的目标检测网络用于低温电子显微镜粒子拾取. 重放方法通常依赖旧任务数据的数量和质量. 一方面, 由于内存限制或隐私问题可能根本无法存储或重新访问; 另一方面, 不断训练生成模型也会导致复杂性逐渐增加, 而且需要额外注意避免模式崩溃.
3) 基于正则化的方法(Regularization-based method)[20–22]: 通过施加惩罚限制重要参数, 使其在后续任务的训练过程中不发生较大变化. 文献[23]首次提出了一种弹性权值巩固(Elastic weight consolidation, EWC)方法, 该方法利用量化的权值重要性有选择地保护对于旧任务重要的权值来学习新任务. 在此基础上, 文献[24]以在线方式基于损失函数计算权值重要性, 并提出了突触智能(Synaptic intelligence, SI)算法. 文献[4]提出的记忆感知突触(Memory aware synapses, MAS)可以进一步用于无标签情况. 文献[25]通过寻找不干扰先前任务权值更新的正交投影, 提出了正交权值修改(Orthogonal weights modification, OWM), 在新任务上训练时, 其权值只允许沿着输入空间的正交方向进行变化. 文献[26]基于知识自蒸馏(Knowledge self-distillation)技术设计了一种域增量学习基准并创新性地用于持续人群计数. 它们仅向目标函数引入正则化项而不需要扩大网络规模或存储旧任务数据.
然而, 现有的CL方法为了减轻灾难性遗忘难以同时满足最小化计算、存储和时间需求, 往往对这些条件中的两个或全部做出妥协[15]. 大多数CL模型都是在深度神经网络(Deep neural networks, DNNs)上实现的, 并严重依赖反向传播(Back propagation, BP)算法. 因此, 这些方法不仅训练耗时, 而且在任务序列的训练过程中对超参数的设置极为敏感. 更为重要的是, 它们潜在地需要多次遍历访问(对应较大的epoch)任务数据以获得更好的性能, 往往不利于保留旧任务的信息, 甚至由于隐私限制可能是不可行的[16]. 对比之下, 生物脑显然已经实现了高效且灵活的连续学习方式. 以上基于DNNs的CL模型与高级动物在学习能力上的显著差距促使我们进一步借鉴生物脑的认知机制.
近年来, 具有跨学科特性的类脑智能引起了众多研究人员的关注[27–29]. 本质上说, 类脑智能算法是从神经元、突触和神经环路的基本和涌现特性中获取灵感, 从而对其结构、机制或功能进行数学建模, 以找到类脑生物特征. 这与人工智能密切相关, 因为更好地了解生物大脑将进一步构建更加智能的模型. 为此, 本文将随机权神经网络与生物大脑的相关工作机制联系起来, 提出了一种新的再可塑性启发的随机化网络(Metaplasticity-inspired randomized network, MRNet)用于类增量学习(Class incremental learning, Class-IL)场景. 具体地, 本文的主要贡献如下: 1) 以前馈方式开发了一种多层随机权网络结构, 并设计了具备记忆功能的再可塑性矩阵, 用于指导输出权值的更新; 2) 为了有效兼容非IID任务以及伴随出现的新类别, 进一步构造了具有解析解的通用CL框架, 从而实现学习与记忆融合; 3) 通过设计不同难度和未知顺序的任务序列, MRNet相比于现有的CL方法可以有效且高效地应用于Class-IL, 表明本文方法进一步拓展了传统机器学习算法在图像分类任务上的分析能力.
与现有工作相比, 所提方法的优势见表1所示. 具体地: 1) MRNet利用任务之间共享的随机权值和解析解实现了以前馈方式构建, 只需要访问一次当前任务的数据(相当于epoch始终为1), 具有易于实现、参数高效、收敛速度快等优点, 是一种更加通用的CL方法; 2) MRNet只需要巩固最后一层的解析解而无需逐层优化模型参数, 无需存储旧数据或构建数据生成器, 也无需增加网络尺寸; 3) 由于不需要调整学习率等超参数, 其模型更新只需要较少的人为干预且具有较强的任务顺序鲁棒性.

图 1 三种连续学习场景
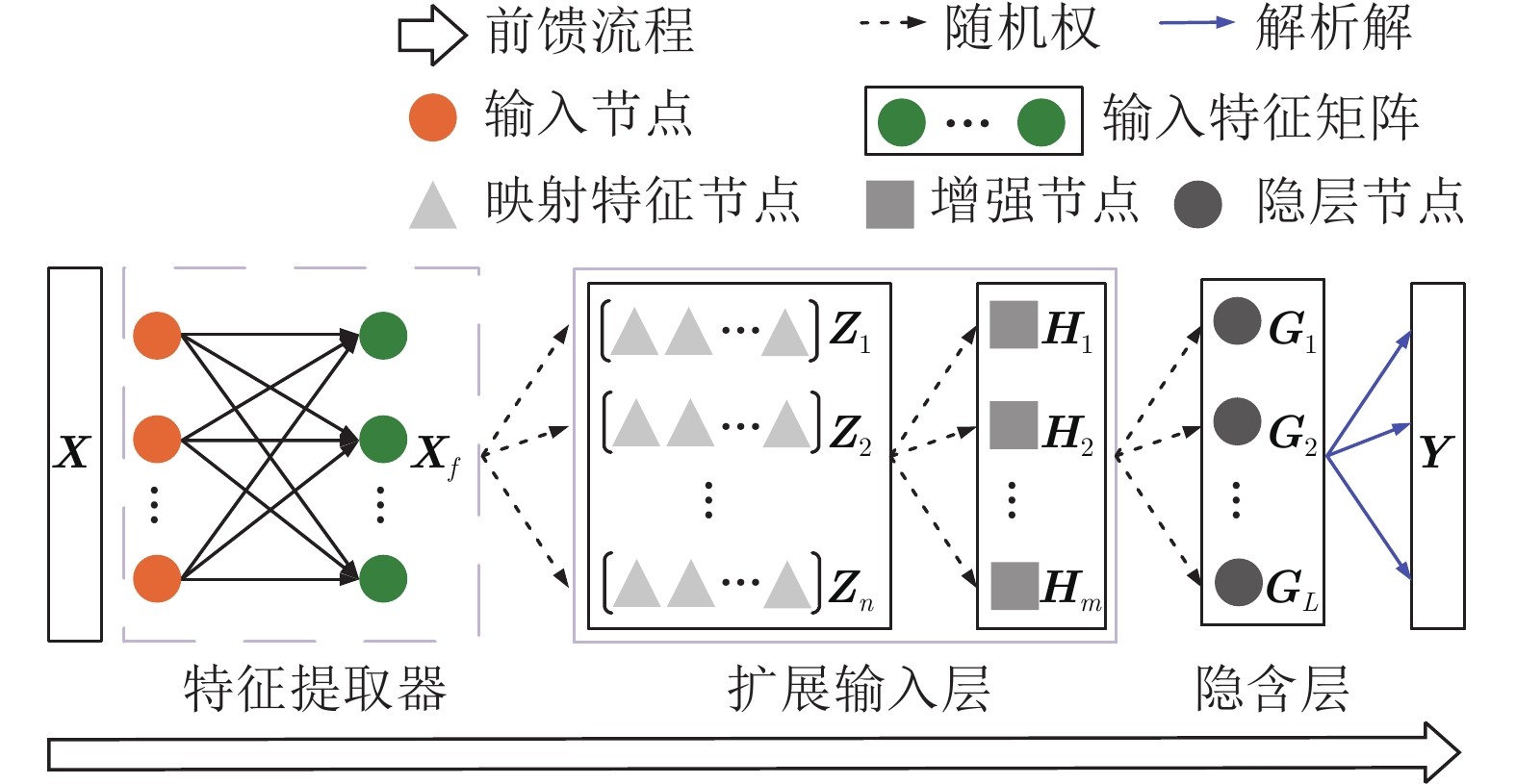
图 2 用于连续学习的MRNet结构

图 3 FashionMNIST-10/5任务序列
本文基于随机权神经网络建立了统一的连续学习框架, 用于有效兼容未来非独立同分布任务以及伴随出现的新类别, 并给出了无需梯度下降算法的解析解, 包括受启发于突触再可塑性构造了具备记忆功能的权值重要性矩阵用于自适应地调整网络参数, 从而维持对历史任务的记忆. 与现有经典和最先进的连续学习方法相比, 所提MRNet具有参数高效、收敛速度快、人为干预度少等优点. 与此同时, 它打破了现有连续学习方法需要多次遍历访问(对应较大的epoch)当前任务的数据以在新任务上获得更好性能的约束, 是一种更加具有通用性的学习与记忆融合模型与算法. 然而, MRNet结构包括一个全局特征提取器和特征到端的简单分类器, 这表明本文所提方法需要借助预训练模型. 因此, 我们将在MRNet基础上进一步建立端到端的连续学习器.
作者简介
李德鹏
华中科技大学人工智能与自动化学院博士研究生. 主要研究方向为增量学习, 对抗机器学习, 脑启发神经网络, 计算机视觉. E-mail: dpli@hust.edu.cn
曾志刚
华中科技大学人工智能与自动化学院教授. 主要研究方向为神经网络理论与应用, 动力系统稳定性分析, 联想记忆. 本文通信作者. E-mail: zgzeng@hust.edu.cn
https://wap.sciencenet.cn/blog-3291369-1416753.html
上一篇:智能网联电动汽车节能优化控制研究进展与展望
下一篇:基于滚动时域强化学习的智能车辆侧向控制算法