博文
异策略深度强化学习中的经验回放研究综述
|
引用本文
胡子剑, 高晓光, 万开方, 张乐天, 汪强龙, NERETIN Evgeny. 异策略深度强化学习中的经验回放研究综述. 自动化学报, 2023, 49(11): 2237−2256 doi: 10.16383/j.aas.c220648
Hu Zi-Jian, Gao Xiao-Guang, Wan Kai-Fang, Zhang Le-Tian, Wang Qiang-Long, Neretin Evgeny. Research on experience replay of off-policy deep reinforcement learning: A review. Acta Automatica Sinica, 2023, 49(11): 2237−2256 doi: 10.16383/j.aas.c220648
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c220648
关键词
深度强化学习,异策略,经验回放,人工智能
摘要
作为一种不需要事先获得训练数据的机器学习方法, 强化学习(Reinforcement learning, RL)在智能体与环境的不断交互过程中寻找最优策略, 是解决序贯决策问题的一种重要方法. 通过与深度学习(Deep learning, DL)结合, 深度强化学习(Deep reinforcement learning, DRL)同时具备了强大的感知和决策能力, 被广泛应用于多个领域来解决复杂的决策问题. 异策略强化学习通过将交互经验进行存储和回放, 将探索和利用分离开来, 更易寻找到全局最优解. 如何对经验进行合理高效的利用是提升异策略强化学习方法效率的关键. 首先对强化学习的基本理论进行介绍; 随后对同策略和异策略强化学习算法进行简要介绍; 接着介绍经验回放(Experience replay, ER)问题的两种主流解决方案, 包括经验利用和经验增广; 最后对相关的研究工作进行总结和展望.
文章导读
强化学习(Reinforcement learning, RL) 的来源通常被认为是心理学中的行为主义理论, 即有机体能获得最大利益的习惯性行为是在环境给予的奖励或惩罚的不断刺激下, 逐步形成的对刺激的预期. 直到20世纪末, RL才开始得到研究者们的重视并迅速发展, 并被认为是设计智能体的核心技术之一[1-2].
RL通过 “试错” (Trail-and-error)[2]的方式与环境进行交互并获得奖励, 并依据奖励不断调整智能体的行为策略. 这种符合人类的经验性思维与直觉推理的一般决策过程使得其在人工智能领域得到了广泛的应用[3]. 随着应用环境复杂程度的不断提升, “维度灾难”[4]限制了RL的进一步发展. 为了更好地表征复杂任务场景中高维度的状态空间, 谷歌人工智能团队Deepmind创新性地将深度学习(Deep learning, DL) 与RL相结合, 提出了人工智能领域的一个新的研究热点 —— 深度强化学习(Deep reinforcement learning, DRL)[5]. DRL同时具备了DL的特征感知能力和RL的决策能力, 能够学习大规模输入数据的抽象表征, 并以此表征为依据进行自我激励, 优化解决问题的策略[6]. 目前, DRL这种端对端(End-to-end) 的学习方式已经在游戏博弈[5, 7-9]、机器人控制[10-12]、自动驾驶[13-15]、金融贸易[16-18]、医疗保健[19-20]等多个领域取得了显著的进展, 其训练的智能体的表现已经接近甚至超越了人类水平.
不同于监督学习和无监督学习, RL通过智能体与环境的不断交互来对环境进行探索进而获得经验(样本), 并根据所获得的经验对智能体的策略不断更新, 最终找到一个适应环境的最优策略. 由于RL在学习过程中没有固定的数据集, 其需要智能体消耗大量的时间成本来获取交互经验. 在一些复杂的环境尤其是现实环境中(例如自动驾驶) 会承担很多的风险与代价. 除此之外, 损耗、响应时延等问题也会使得智能体能够收集的经验数量是有限的. 如何合理利用有限的经验来训练出策略尽可能好的智能体已然成为国内外研究者的一个关注重点.
经验回放(Experience replay, ER) 是一种存储过去的连续经验并对其进行采样以重复使用进而更新智能体行动策略的技术, 其概念于1992年被Lin等[21]率先提出. 2015年, 随着深度Q网络算法(Deep Q-network, DQN)[5]的提出, 经验回放被证明在DRL的突破性成功中发挥了重要的作用. 这一新的研究热点迅速吸引了大量研究者的关注, 到目前为止, 经验回放已成为提高异策略DRL算法稳定性和收敛速度的一种主要技术. 在现有文献中, 还没有研究尝试将DRL中的经验回放算法进行分类和总结. 本综述以RL的基本理论为出发点, 首先介绍了RL的基本概念. 随后对RL算法依据行为策略与目标策略的一致性进行了分类, 并对其中异策略DRL的典型算法进行了介绍. 然后结合近年来公开文献详细梳理了国内外成熟的异策略DRL中的经验回放方法, 并将其分为两个大类, 即经验利用和经验增广. 最后, 对异策略DRL中的经验回放方法进行了总结与展望.
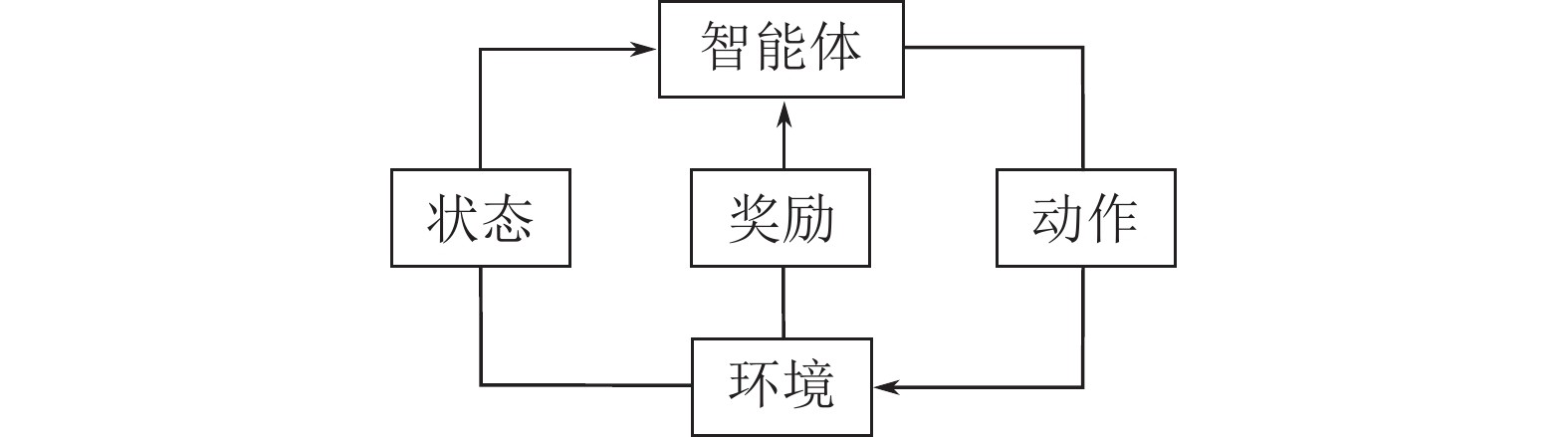
图 1 强化学习过程
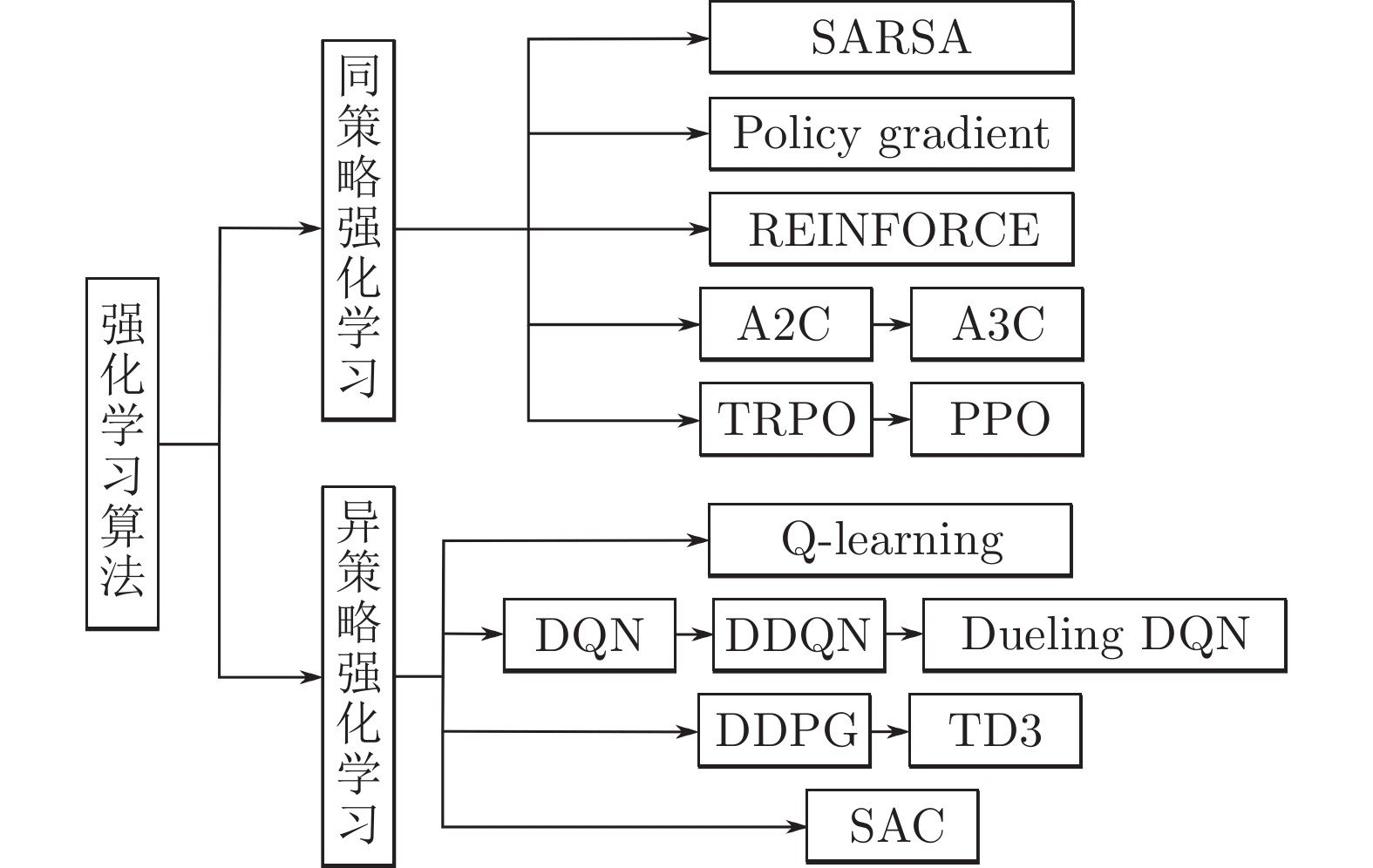
图 2 强化学习算法分类
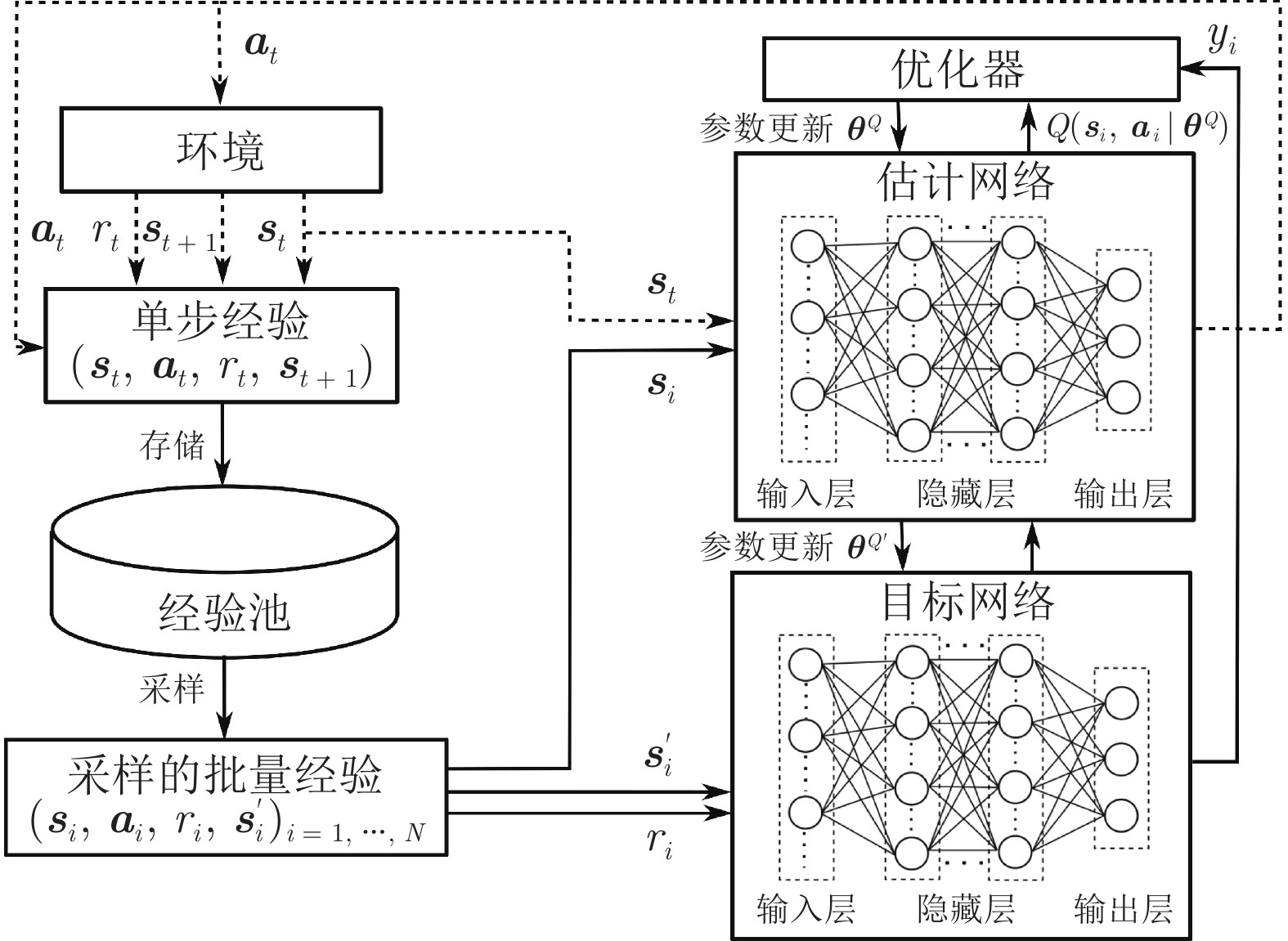
图 3 DQN算法框架
RL通过智能体与环境的交互过程不断获取经验, 来优化智能体自身的行动策略以期获得最大的累积奖励. 作为一种数据驱动的机器学习算法, 经验(数据)决定了RL智能体最终策略的优劣. 在异策略RL中, 经验池的存在造就了经验回放这一研究热点. 通过经验回放, 智能体能够按照需求合理利用多来源的经验, 避免灾难性遗忘的发生, 更快地得到更优的行动策略, 减小训练过程中的成本代价. 因此, 对经验回放机制进行研究有着十分重要的实际意义和发展前景. 本文从RL的基础知识出发, 介绍了常用的异策略RL算法, 并从经验利用和经验增广两个角度对经验回放机制的相关研究进行了详细的介绍和总结, 弥补了国内相关研究领域的空缺.
现有的经验回放方法已经取得了初步的成果, 理论和实践都证明了经验回放对于异策略RL的重要性, 但其仍面临着一些问题和挑战.
1) 算法的适用性: 很多算法过分关注于某类问题而局限了其适用范围. 而且大量的算法使用了神经网络或引入了大量的超参数, 参数敏感性无疑会影响经验回放算法对不同环境的适用效果. 除此之外, 作为RL的一个模块, 经验回放算法同样面临着虚拟到现实的落地困难的窘境.
2) 算法的可解释性: RL作为人工智能领域的一个研究方向, 毫无疑问在经验回放的研究过程中, 会有很多思路和设计来源于对人类或其他物种的行为模拟. 然而, 这些所谓移植性创新往往缺乏可靠的理论支撑, 可解释性较差, 有时难以让人信服.
3) 算法的效率: 无论是在数以百万计的经验池中进行筛选或排序, 还是从无到有地增广数以百万计的经验, 经验回放算法的运算效率始终面临着严峻的考验.
针对上述问题, 本文仍从经验利用和经验增广两个方面分别指出各个方向可能的突破口, 为相关领域的学者提供一些研究思路.
在经验利用方面:
1) 经验优先利用标准: 除了已得到广泛认可的TD error常用来作为经验优先利用的标准外, 经验与当前状态的相似性、经验难度等指标也逐渐被应用于各种RL控制问题中. 调整智能体对经验池中所存储的经验的学习顺序, 在不同的训练阶段使得最适合当前智能体策略更新的经验被学习, 仍然是一种提高RL效率的有效办法[51]. 除了上述的优先标准, 将其他领域例如人类教育学、心理学或者生物学的知识或现象进行建模, 设计出普适于多种任务环境的参数不敏感的优先回放标准仍是经验回放领域今后研究的重点.
2) 经验加权回放的适用性: 经验加权回放是近几年经验回放领域新兴的研究方向, 相关的研究还相对较少. 目前较为成熟的算法还难以简便、准确地应用于所有的实验环境. 因此, 设计更具有普适性且计算更为简洁的经验加权回放方法仍是现阶段需要主要考虑的问题[58]. 除此之外, 由于发展时间较短, 还尚未有研究将此类方法延伸于真实的应用环境, 其在真实环境中是否仍具有较好的效果还有待进一步研究.
3) 经验池的结构设计: 随着任务复杂程度的提升, 经验池的规模也在不断扩大, 经验池的结构设计面临着巨大的压力. 通过改变原有数组形式的存储结构, 采用树、队列、堆栈甚至于图等数据结构来构建经验池, 能在降低计算机内存消耗的同时提升算法的采样效率. 合理设计经验池的更新逻辑也能够充分发挥各种经验优先利用算法的优势[54]. 除此之外, 对计算机的硬件架构进行针对性的设计也是进一步提升经验回放算法效率的有效途径.
4) 经验的表示形式及转换效率: 利用其他领域例如量子力学的理论, 将原始向量形式的经验进行编码, 随后进行存储. 在使用时也可以结合不同的优先利用算法来进行优先采样, 将采样后的经验重新解码以便智能体进行学习. 这种从经验的表示形式入手的方法也是近年来经验回放领域的一个新兴研究方向, 具有一定的研究价值. 但这种先编码后解码的过程需要耗费一定的计算资源, 如何提升经验编码和解码的效率是此类方法需要考虑的重点.
在经验增广方面:
1) 多来源数据的准确性: 在处理较为复杂任务时, 结合不同来源的指导经验进行学习可以大幅减少智能体与环境的交互, 提升算法的收敛速度. 但如何确保其他数据的准确性和有效性是此研究方向不可避免的问题. 专家经验通常是基于专家自身实际操作经验, 智能体的交互经验是在奖励函数的指导下产生的. 专家经验与交互经验所蕴含的策略的统一性, 将在很大程度上影响智能体的表现[49]. 环境模型也是在智能体训练过程中不断优化的, 其收敛速度直接导致了智能体用于训练的模拟经验的准确性[79]. 如何设计更准确的模型结构并提升模型的收敛速度是此方向需要长期关注的问题.
2) 经验重塑算法的效率: 在固定奖励函数的情况下, 对智能体自身的交互经验进行重塑以实现经验的大规模增广是经验回放领域近年来的研究热点. 附加经验的准确性和策略一致性保证了收敛后智能体优秀的性能. 在庞大的经验中选择合适的附加目标以期产生高质量的附加经验仍然是此类方法关注的重点. 但毫无疑问, 大规模的搜索和重塑会对算法的计算效率产生影响[88], 使用多线程进行并行计算或设计其他高效的计算框架或许是经验重塑类方法提升效率的有效途径.
作者简介
胡子剑
西北工业大学电子信息学院博士研究生. 2018 年获得西北工业大学探测制导与控制技术学士学位. 主要研究方向为强化学习理论与应用. E-mail: huzijian@mail.nwpu.edu.cn
高晓光
西北工业大学电子信息学院教授. 1989 年获得西北工业大学系统工程博士学位. 主要研究方向为机器学习理论, 贝叶斯网络理论和多智能体控制应用. E-mail: cxg2012@nwpu.edu.cn
万开方
西北工业大学电子信息学院副研究员. 2016 年获得西北工业大学系统工程博士学位. 主要研究方向为多智能体理论, 近似动态规划和强化学习. 本文通信作者. E-mail: wankaifang@nwpu.edu.cn
张乐天
西安电子科技大学外国语学院硕士研究生. 主要研究方向为科技翻译, 翻译理论和机器翻译. E-mail: 22091213382@stu.xidian.edu.cn
汪强龙
西北工业大学电子信息学院博士研究生. 主要研究方向为深度学习, 强化学习. E-mail: wql1995@mail.nwpu.edu.cn
NERETIN Evgeny
莫斯科航空学院教授. 2011年获得莫斯科航空学院技术科学博士学位. 主要研究方向为航空电子, 智能决策. E-mail: evgeny.neretin@gmail.com
https://wap.sciencenet.cn/blog-3291369-1411108.html
上一篇:《自动化学报》2023年49卷11期目录分享
下一篇:PID控制器参数的优化整定方法