博文
基于自适应噪声的最大熵进化强化学习方法
|
引用本文
王君逸, 王志, 李华雄, 陈春林. 基于自适应噪声的最大熵进化强化学习方法. 自动化学报, 2023, 49(1): 54−66 doi: 10.16383/j.aas.c220103
Wang Jun-Yi, Wang Zhi, Li Hua-Xiong, Chen Chun-Lin. Adaptive noise-based evolutionary reinforcement learning with maximum entropy. Acta Automatica Sinica, 2023, 49(1): 54−66 doi: 10.16383/j.aas.c220103
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c220103
关键词
深度强化学习,进化策略,进化强化学习,最大熵,自适应噪声
摘要
近年来, 进化策略由于其无梯度优化和高并行化效率等优点, 在深度强化学习领域得到了广泛的应用. 然而, 传统基于进化策略的深度强化学习方法存在着学习速度慢、容易收敛到局部最优和鲁棒性较弱等问题. 为此, 提出了一种基于自适应噪声的最大熵进化强化学习方法. 首先, 引入了一种进化策略的改进办法, 在“优胜”的基础上加强了“劣汰”, 从而提高进化强化学习的收敛速度; 其次, 在目标函数中引入了策略最大熵正则项, 来保证策略的随机性进而鼓励智能体对新策略的探索; 最后, 提出了自适应噪声控制的方式, 根据当前进化情形智能化调整进化策略的搜索范围, 进而减少对先验知识的依赖并提升算法的鲁棒性. 实验结果表明, 该方法较之传统方法在学习速度、最优性收敛和鲁棒性上有比较明显的提升.
文章导读
近年来, 深度强化学习作为一种能够有效解决机器学习问题的方法[1], 在自动驾驶[2-3], 轨迹追踪[4-5]与目标定位[6]问题, 复杂多对象任务[7], 组合优化问题[8], 自动控制[9-10]等领域都得到了广泛应用. 而作为这一方法的核心, 深度神经网络的更新方法一直以来都备受学界的关注[11-12]. 其中, 许多研究中提出的方法在更新网络参数时都采用了基于梯度的策略迭代方法[13], 这些研究结果表明基于梯度的策略迭代方法能够有效解决非线性系统[14], 多智能体强化学习[15]等问题. 基于梯度的策略迭代方法即通过计算目标函数的梯度对深度神经网络进行反向传播, 例如蒙特卡洛策略梯度[1], 近端策略优化(Proximal policy optimization, PPO)[16]以及它们的改进方法[17-18]. 其他一些相关研究成果则大多着眼于将PPO的思想应用于诸如参数分布优化的更多领域[19]. 但这些方法都仍然是以基于梯度的策略迭代方法为核心的. 然而, 随着机器学习问题日趋复杂, 深度强化学习所需要处理的目标函数的维度也随之不断增大, 导致基于梯度的策略迭代方法的训练速度和收敛性受到较大影响[20].
为了找到一种更容易探索到全局最优、提高收敛速度的方法, 一些研究者开始尝试使用无梯度优化方法. 2017年, OpenAI发表的论文[20]中采用进化计算中的进化策略(Evolution strategies, ES)对深度神经网络参数进行更新, 并借助多线程并行运算来提高效率, 为强化学习问题提供了一种新型的解决方案—进化强化学习方法. 不同于传统强化学习通过对动作进行扰动来优化参数, 进化方法则是直接对网络参数进行扰动, 在每次循环中根据计算得到的适应性函数的大小对参数添加噪声, 因此进化方法不需要通过梯度下降的反向传播. 此外, 进化策略由于高度的并行性并且只需要在不同进程中传递随机种子, 相对于策略梯度而言训练速度较快. 但相较于传统深度强化学习方法而言具有比较大的随机性, 因此被称为“黑盒优化”[20]. 在2018年Uber发表的论文[21]中, 研究者提出了利用进化方法中的另外一个方法—遗传算法来实现对网络参数的优化. 后续的研究中一般更多采用相对更为容易实现的ES来作为新算法的框架基础和用于对比的基准算法.
研究者们通过理论论证分析了在深度强化学习中使用进化策略的若干优势. Lehman等[22]解释了为何进化策略能够探索到与梯度优化的搜索范围不同的区域, 从而可以使进化强化学习求解到与梯度优化方法不同的最优点. Zhang等[23]通过一系列基于混合国家标准和技术研究所(Mixed National Institute of Standards and Technology, MNIST)数据库的实验来揭示进化策略和随机梯度下降之间的联系与区别, 并证明了进化强化学习的高准确度. 在理论工作完成之后, 众多学者们不断尝试将进化策略应用于多种强化学习前沿问题. Khadka等[24]提出了用于改进深度确定性策略梯度[1]的进化强化学习方法. Shi等[25]将进化策略应用于最大熵强化学习, 提出了最大熵策略搜索方法. Song等[26]用进化策略改进了元学习方法, 提出了基于进化策略的模型无关的元学习. Majumdar等[27]提出的多智能体进化强化学习和Long等[28]提出的进化种群学习模式都是利用进化策略对多智能体强化学习方法的改进. Wang等[29]提出的实例加权增量进化策略是一种将进化策略应用于动态空间中的学习问题的方法.
然而, 大多数上面所提及的方法把重点放在将自然进化策略(Natural ES, NES)[30]最基本的形式用在不同的强化学习算法上, 只有较少的研究涉及对进化强化学习本身的方法改进上[31-32]. 尽管使用NES能够使方法的结构相对得到简化, 但是同时也将进化策略本身具有的一些问题带到了深度强化学习方法中. 目前进化策略的问题主要包括:
1)进化策略的梯度下降方向与最优下降方向存在偏差, 导致了进化强化学习收敛速度较慢[33-34];
2)进化策略的探索性较弱, 容易陷入局部最优[25, 33];
3)进化策略对超参数变化比较敏感, 方法需要依赖超参数设计上的先验知识, 鲁棒性需要提升[32-33].
为了提高进化强化学习算法在这3个方面的性能, 本文提出了一种基于自适应噪声的最大熵进化强化学习方法(Adaptive noise-based evolutionary reinforcement learning with maximum entropy, AERL-ME), 这一方法的贡献如下:
1)通过改进进化策略的更新公式, 在传统算法只注重“优胜”的基础上增加了自然选择中的“劣汰”, 削弱了由于随机探索带来的下降方向偏移问题的影响, 提高了方法的收敛速度;
2)通过在目标函数中引入策略最大熵来鼓励智能体对于新策略的探索, 使智能体在探索新策略和利用已知策略的达到平衡, 提升了方法跳出局部最优的能力;
3)提出了一种基于Kullback-Leibler (KL)散度的自适应噪声控制机制, 这一机制能够根据当前进化的情形智能地调节算法的一个关键参数—噪声标准差的值来调整进化策略的探索范围, 改善了传统进化策略方法由于依赖超参数设计上的先验知识而导致的鲁棒性较弱的缺陷.
本文的组织结构如下: 第1节介绍进化强化学习相关背景知识; 第2节介绍本文提出的改进方法AERL-ME; 第3节介绍实验中用到的模拟环境和实验设计思路, 给出了对比实验, 消融实验和灵敏度分析实验的结果和分析; 第4节总结全文, 说明本文方法仍存在的不足和可以改进的方向.

图 1 基于自适应噪声的最大熵进化强化学习方法的结构
图 2 实验环境
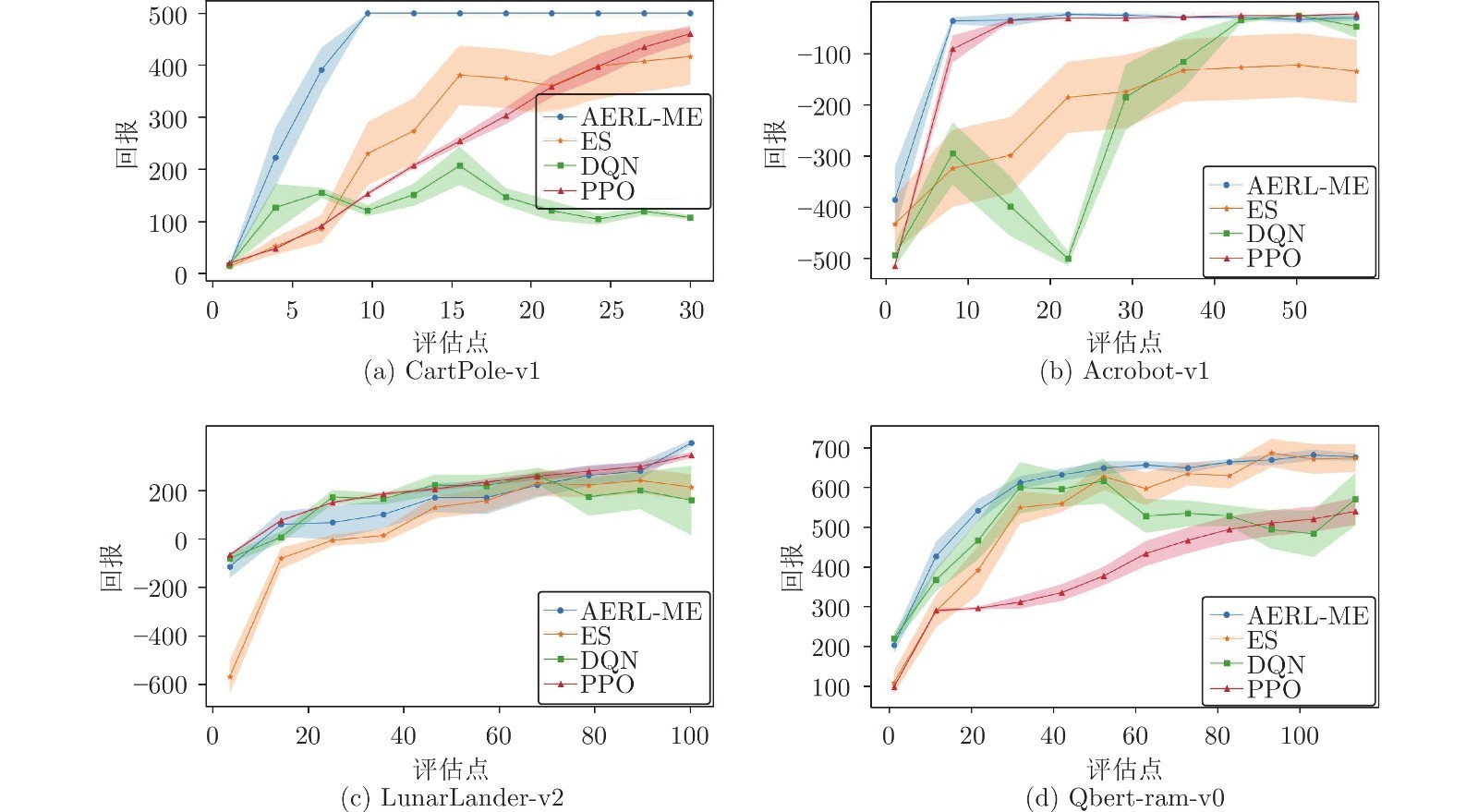
图 3 对比实验结果
本文提出了一种对基于自适应噪声的最大熵进化强化学习方法AERL-ME. 首先, 该方法引入了一种进化策略的改进方法CES削弱了进化方向错误的子代实例对网络更新造成的影响; 其次, 通过在方法的目标函数中添加熵正则化项, 有效地平衡了方法的探索与利用的能力, 使方法能够跳出局部最优; 最后, 该方法提出了一种对噪声标准差的自适应控制机制, 能够在网络更新后根据KL散度智能地调整方法的探索范围. 实验结果表明, 这一方法在继承了进化强化学习的高效率, 低运算成本和高并行化等优点的同时, 又一定程度上解决了传统方法收敛速度慢, 探索性不足和依赖先验知识而导致的鲁棒性较弱的缺点.
未来可以改进的方向是: 1)本文方法只能在离散状态—动作空间的模型下进行学习. 如果需要将之拓展连续空间, 就必须要修改方法中的一些公式, 比如信息熵就需要改成积分的形式. 2)本文方法在面对具有稀疏奖励模型时, 比如在Gym中的爬山小车环境中, 会由于在初始网络周围搜索不到更优的策略而导致在多步迭代之后仍然无法实现网络的更新. 3)可以探索能够进一步降低方法对于超参数初始设置敏感性的自适应控制机制.
作者简介
王君逸
南京大学控制科学与智能工程系硕士研究生. 2021年获南京大学学士学位. 主要研究方向为强化学习, 机器学习与人工智能. E-mail: mf21150062@smail.nju.edu.cn
王志
南京大学控制科学与智能工程系讲师. 2015年获南京大学学士学位. 2019年获中国香港城市大学博士学位. 主要研究方向为强化学习, 机器学习与人工智能. 本文通信作者. E-mail: zhiwang@nju.edu.cn
李华雄
南京大学控制科学与智能工程系副教授. 2009年获南京大学博士学位. 主要研究方向为机器学习与数据挖掘, 模式识别与智能系统. E-mail: huaxiongli@nju.edu.cn
陈春林
南京大学控制科学与智能工程系教授. 分别于2001年和2006年获中国科学技术大学学士学位和博士学位. 主要研究方向为强化学习及智能无人系统. E-mail: clchen@nju.edu.cn
https://wap.sciencenet.cn/blog-3291369-1372073.html
上一篇:基于一步张量学习的多视图子空间聚类
下一篇:基于多维度特征融合的云工作流任务执行时间预测方法