博文
一种加速时间差分算法收敛的方法
|
引用本文
何斌, 刘全, 张琳琳, 时圣苗, 陈红名, 闫岩. 一种加速时间差分算法收敛的方法. 自动化学报, 2021, 47(7): 1679−1688 doi: 10.16383/j.aas.c190140
He Bin, Liu Quan, Zhang Lin-Lin, Shi Sheng-Miao, Chen Hong-Ming, Yan Yan. A method of accelerating the convergence of temporal difference learning. Acta Automatica Sinica, 2021, 47(7): 1679−1688 doi: 10.16383/j.aas.c190140
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c190140
关键词
强化学习,时间差分算法,蒙特卡罗算法,加速收敛
摘要
时间差分算法(Temporal difference methods, TD)是一类模型无关的强化学习算法. 该算法拥有较低的方差和可以在线(On-line)学习的优点, 得到了广泛的应用. 但对于一种给定的TD算法, 往往只能通过调整步长参数或其他超参数来加速收敛, 这也就造成了加速TD算法收敛的方法匮乏. 针对此问题提出了一种利用蒙特卡洛算法(Monte Carlo methods, MC)来加速TD算法收敛的方法(Accelerate TD by MC, ATDMC). 该方法不仅可以适用于绝大部分的TD算法, 而且不需要改变在线学习的方式. 为了证明方法的有效性, 分别在同策略(On-policy)评估、异策略(Off-policy)评估和控制(Control)三个方面进行了实验. 实验结果表明ATDMC方法可以有效地加速各类TD算法.
文章导读
强化学习是机器学习领域中最接近人类和动物学习的方法[1], 在机器人自主决策和学习、复杂动态系统的优化控制和自动驾驶等领域中有着广泛的应用[2-5]. 强化学习算法分为基于模型和无模型两种. 基于模型的算法需要一个精确且完整的环境模型, 而无模型算法没有这个要求. 无模型的强化学习算法中基于值函数的算法较为常用. 该算法需要根据值函数得出最优的策略. 如果值函数无法准确地被评估, 或者评估的效率过低, 那么将得不到最优的策略, 或者耗时过长. 所以, 一个精确和高效的值函数评估方法对于基于值函数的强化学习算法至关重要[6-7].
对于值函数评估问题, 经典的解决方法是TD (Temporal difference methods)算法和MC (Monte Carlo methods)算法. 其中, TD算法可以像动态规划(Dynamic program)方法一样使用自举(Bootstrap)的方式, 即利用已经评估过的状态值来进行新的评估. 这也使得TD算法可以不需要等待情节结束, 就可以进行值函数的更新, 从而实现了在线学习的方式. MC算法必须等到情节结束后才能进行值函数的更新, 因而只能使用离线学习(Off-line)的方式[1]. 但是如果TD算法所利用的评估过的状态值有偏差, 那么评估的结果往往在真实值附近. 另外, TD算法的收敛效率很大程度上取决于初值和步长参数的设定. 优秀的初值和恰当的步长参数可以极大地缩小所需要策略迭代的次数, 但是初值的设定往往需要丰富的经验和相关领域的专业知识. 对于步长参数设定的问题, 有许多自动设置步长参数的算法可以解决[8-9]. 然而, 尽管这些算法有许多理论上的优势, 但是由于其自身的复杂性和进一步增加了TD算法的时间复杂度而得不到广泛的运用, 实际应用中更多地采用固定步长参数的方法[10]. 这也就造成了加速一个特定TD算法收敛速率的方法的匮乏.
论文提出的ATDMC方法是利用MC算法的无偏的性质, 在TD算法完成一次值函数评估后, 进行值函数改进. 即在广义策略迭代中加入减少值函数和真实值函数的之间距离的步骤, 使得在不改变TD算法的在线学习的方式基础上, 加速算法的收敛.
文中第1节描述了强化学习的相关基本概念和所用到的符号的定义. 第2节给出TD算法的收敛速率的分析和ATDMC方法的详细推导过程. 第3节用实验分别展示在同策略评估、异策略评估和控制三个方面的加速效果. 最后一节给出结论和后续的工作方向.
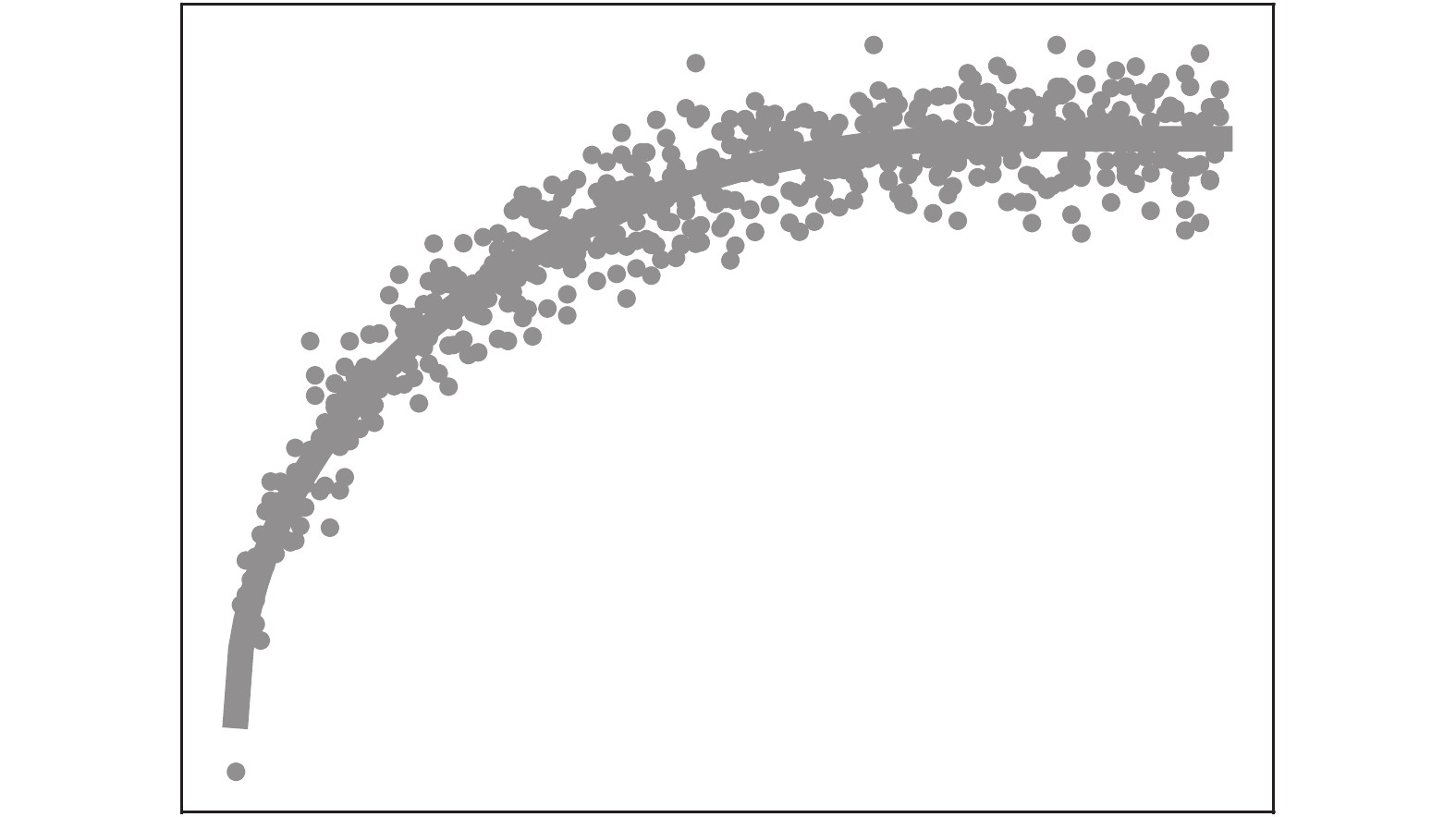
图 1 由UTD构成的不稳定序列

图 2 改进后的GPI

图 3 博扬链
针对加速特定TD算法收敛速率的方法匮乏的问题, 本文提出利用MC算法无偏的性质来加速TD算法收敛的ATDMC方法. 通过分析TD算法的收敛速率得出可以通过减小e1,e2,⋯来加速收敛, 而MC算法的目标可以在学习初期减小这些值, 进一步推导得出了最终的方法. 从推导过程可知, 加速的实现并不需要改变原TD算法, 也即TD算法的在线实现的方式不会被改变. 同时, 只引入了3个额外的变量, 并没有增加算法的空间复杂度. 从实验结果可以看出, 本文提出的方法可以有效地加速各类TD算法, 恰当的步长参数使得算法达到最优的加速效果.
另外, 需要指出的是ATDMC方法只适用于情节式任务. 对于连续任务, 有两种解决方案: 一种是引入可变的折扣因子γ, 在恰当的时间步设置γ等于0 (相当于主动结束任务), 从而转换为一个情节任务, 但并不影响对应MDP的流程; 另外一种是采用平均奖赏设定(Average-reward setting), MC方法的目标需要重新用奖赏和奖赏的平均值的差值来定义. 更多的细节需要进一步研究.
作者简介
何斌
苏州大学计算机科学与技术学院硕士研究生. 主要研究方向为强化学习. E-mail: hebinyc@gmail.com
刘全
苏州大学计算机科学与技术学院教授. 2004年获得吉林大学博士学位. 主要研究方向为强化学习,深度学习,深度强化学习. 本文通信作者. E-mail: quanliu@suda.edu.cn
张琳琳
苏州大学计算机科学与技术学院硕士研究生. 主要研究方向为强化学习. E-mail: 20175227007@stu.suda.edu.cn
时圣苗
苏州大学计算机科学与技术学院硕士研究生. 主要研究方向为深度强化学习. E-mail: 20175227045@stu.suda.edu.cn
陈红名
苏州大学计算机科学与技术学院硕士研究生. 主要研究方向为深度强化学习. E-mail: 20174227007@stu.suda.edu.cn
闫岩
苏州大学计算机科学与技术学院硕士研究生. 主要研究方向为深度强化学习. E-mail: 20165222006@stu.suda.edu.cn
https://wap.sciencenet.cn/blog-3291369-1351932.html
上一篇:高速列车非线性系统的分数阶有限时间控制器设计
下一篇:基于深度学习的极性电子元器件目标检测与方向识别方法