博文
负负得正?存在误差的数据能否用于科学研究?
|
研究人员的成果通常会公开发布,并由各种专业的机构整理。这些数据既可以作为其它研究的基础,同时也可作为相关政策制定的参考。如何将研究人员与发文情况相匹配,是其中一项非常重要的工作。
但显然,任何数据库在匹配研究人员与其成果时都很有可能出现误差。例如,将研究人员的简历中的发文数据与Web of Science数据库(简称“WoS”)中的数据匹配,可能出现简历中部分论文并没有被WoS收录的情况,也有可能发现WoS收录了一些并非该研究人员实际发表的论文。
那么,存在误差的发文数据,是否可以用来进行科学研究呢?来自美国的Donna K. Ginther等人最近在Scientometrics期刊上发表的一项研究探讨了这个问题。
1. 研究内容
研究主要回答与样本科研人员匹配的发文数据集是否可以用于科学研究的问题。首先通过不同的来源和方法构建发文数据集,进而衡量数据集是否存在测量误差;如果数据集存在误差,验证是否能通过调整使其满足科学研究的需要。
2. 数据与方法
本研究主要使用了3个数据集:
(1)博士调查(Survey of Doctorate Recipients, SDR)数据。博士学位获得者调查是一项两年一次的纵向调查,由美国国家科学基金会(National Science Foundation)下属的国家科学与工程统计中心(National Center for Science and Engineering Statistics)和美国国立卫生研究院(National Institutes of Health)赞助,主要跟踪美国院校科学、工程或卫生领域博士学位获得者的情况。调查数据包含详细的人口和职业信息以及部分的出版物和专利数据。
(2)金标准(Gold Standard, GS)数据。从1993~2013年的博士调查数据中抽取了750个受访者作为分层随机样本,然后在个人网站、简历和谷歌学术等数据库中手工收集样本人员发文的信息。
(3)科睿唯安(Clarivate)数据。借助博士调查数据和金标准数据提供的信息,从科睿唯安的Web of Science (WoS)数据库中找出与样本人员的姓名、领域和所属单位相匹配的论文。
研究假设金标准数据是最接近真实情况的,和金标准数据相比,科睿唯安数据存在假阳性和假阴性的问题。假阳性是指科睿唯安数据比金标准数据多识别的发文;假阴性是指科睿唯安数据比金标准数据少识别的发文,即某一研究人员有发文,但科睿唯安数据中却显示其没有发文。
为了调整科睿唯安数据存在假阴性的问题,研究创建了两个变量:假阴性-SDR和假阴性-GS。假阴性-SDR表征科睿唯安数据显示某研究人员没有发文但博士调查数据显示其有发文的情况,假阴性-GS表征科睿唯安数据显示某研究人员没有发文但金标准数据显示其有发文的情况。
为了衡量发文情况数据是否存在测量误差,作者按以下步骤进行分析。
(1)构建发文情况和薪酬、资助的计量经济模型,初步判断发文情况是否存在测量误差;
(2)借助赛马模型和工具变量模型,判断金标准数据和科睿唯安数据是否存在测量误差;
(3)如果存在测量误差,尝试通过修改阈值、限制样本等方式调整,并验证调整后数据的效果。
3. 实证分析(1)初步回归结果
作者控制了性别、婚姻状态、种族/民族等方面的固定效应,通过最小二乘法(ordinary least square, OLS)研究发文情况对薪酬和资助的影响,结果如下表所示。结果显示,金标准数据的解释力明显强于科睿唯安数据,且比博士调查数据具有更好的解释力。科睿唯安数据的指标均不具有统计学显著性,博士调查数据仅在第一种学术年龄计数方式(学术年龄的平方)中具有显著性(Panel B一行四列)。作者通过改变博士领域的覆盖范围(广泛范围包括:生物和农业科学、物理科学、社会科学、心理学、工程学和健康,见第二列;狭义范围包括:计算机和数学,见第一、三列)以及学术年龄的计算方法(年龄的平方,见第一、二、四列或以十年为单位,见第三列)证明以上结果具有稳健性。
表1. 发文情况对工资和获得联邦资助的影响

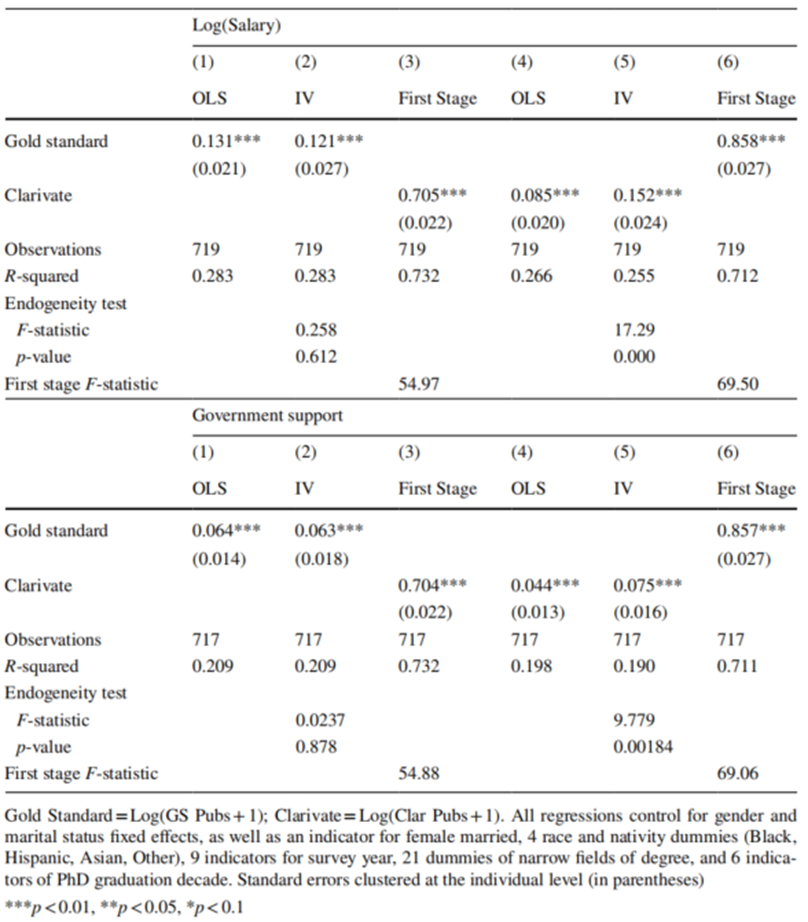
工具变量分析结果如下表所示。OLS估计表明(表中第1、4列),金标准数据中发文每增加1%年薪增长0.131%,而科睿唯安数据中发文每增加1%年薪仅增长0.085%。这一结果表明,科睿唯安数据可能比金标准数据更容易受衰减偏倚。对工具变量分析的结果表明(表中第2、5列),金标准数据的工具变量估计值(0.121%)接近OLS对应值,表明其测量误差较低,这一结果在联邦资助方面也得到了验证。而科睿唯安数据的工具变量系数均高于金标准数据,存在非经典测量误差。且金标准数据的信噪比远高于科睿唯安数据(表中第3、6列)。综合表中数据并进行外生性检验,作者得出金标准数据接近“真实”的发文情况,而科睿唯安数据则存在非经典测量误差。
作者进一步评估了科睿唯安数据的替代测量方法,以确定存在显著非经典测量误差的情况下科睿唯安数据是否可以用于统计分析。第一,调整科睿唯安数据匹配概率阈值。科睿唯安数据的机器学习算法预测论文与作者正确匹配的概率至少为0.5,作者探讨了更高匹配概率阈值对测量误差的影响。结果表明,更高的阈值导致更小的衰减系数,综合而言,匹配概率为0.80可能是最佳选择。第二,调整样本范围。作者采用子样本结果进行最小二乘回归,分别将样本限制为金标准数据与科睿唯安数据的子集、测量值最多相差3、5、10和不受限制。结果表明衰减偏差来自测量误差,当使用科睿唯安数据与金标准数据的子集时,回归效果最好。
表2. 工具变量分析表
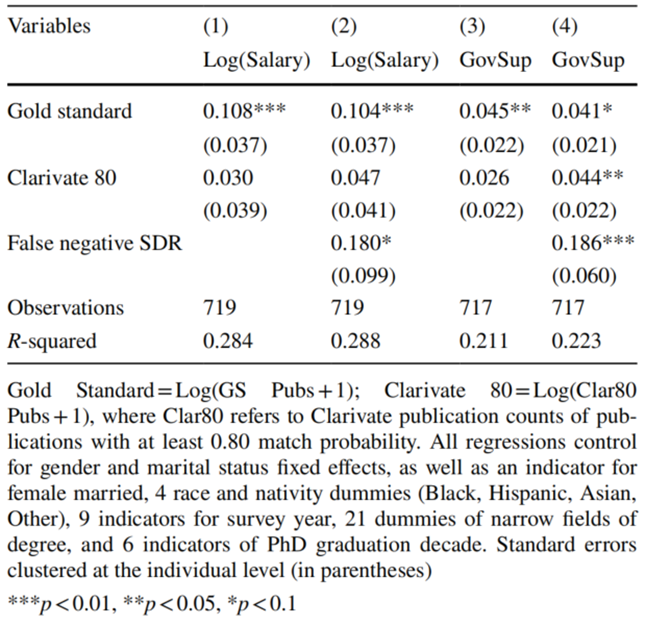
使用0.80匹配概率阈值会使科睿唯安数据有很大改进,当作者将数据限制为金标准的子集时,该结果与金标准数据十分接近(但仍不能与金标准数据完全一致),分析结果如下表所示。
表3. 通过赛马模型对科睿唯安数据的假阴性和假阳性纠偏
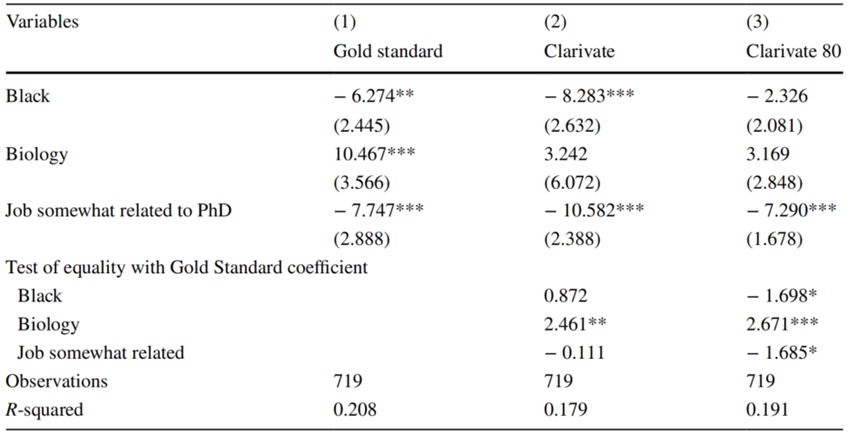
作者分别使用金标准数据、科睿唯安数据和0.80匹配概率阈值的科睿唯安数据进行最小二乘回归,选择黑人、生物领域博士、工作与博士学位关联性作为协变量,这三个协变量在金标准数据的分析中与薪资水平显著相关。结果表明,在金标准数据中,黑人研究者的平均发文比白人研究者少约6.3篇,生物学专业的发文比计算机和数学等专业多约10.5篇。但在科睿唯安数据中(包括0.80匹配概率阈值的数据),以上差异并不显著。结果如下表所示。这一结果说明,即使对科睿唯安数据的假阳性和假阴性进行纠偏,仍将导致缺乏合理的无偏系数。综合来看,在全样本中将发文情况作为因变量仍然面临测量误差带来的问题。
表4. 非经典测量误差的影响
4. 结语
本研究展示了将研究人员与其发文情况匹配所面临的挑战。研究使用金标准数据和科睿唯安数据分别测度发文量对薪酬及资助的影响。利用赛马模型和工具变量估计,研究发现金标准数据相对来说不存在测量误差,而科睿唯安数据存在非经典测量误差。研究尝试通过调整阈值、增加指标等方式控制科睿唯安数据中的假阳性和假阴性来减小测量误差,可以达到同金标准数据相似的效果,但当发文量作为因变量时效果较差。
尽管科睿唯安数据存在非经典测量误差,但本研究展示了如何调整数据以满足科学研究目的。这一思路对科研人员具有重要意义。
原文信息:Ginther, D.K., Zambrana, C., Oslund, P. et al. Do two wrongs make a right? Measuring the effect of publications on science careers. Scientometrics (2023). https://doi.org/10.1007/s11192-023-04849-5
https://wap.sciencenet.cn/blog-1166809-1419890.html
上一篇:成为结构洞:让研究成果更具新颖性和颠覆性
下一篇:消失的它:揭秘OpenAlex数据平台的机构信息缺失现象