博文
深度学习多隐层架构数理逻辑浅析(十九)(8)
|
CNN(卷积神经网络)像“拿着放大镜看画”,Transformer(自注意力机制)像“站在高处俯瞰全图”,所以transformer注意力比CNN注意力在提取特征方面更具有广谱优势。如果我们再在Transformer多头注意力加入旋转群元变换下的对偶对称不变量,规范设置注意力头的模块Block,升级版Transformer规范头也许将看到规范组件的脉络,让宏观视角的Transformer 从 “全局乱看” 进化到 “模块化、层级化、几何结构化地全局看”。

虽然理论而言,复合旋转变换元的Transformer所有组件均基于现有成熟技术(RoPE、辛矩阵、分块注意力),模块化似乎并无理论障碍,操作上也相对容易实现,不过这不是一个免费的午餐,引入高阶复合旋转变换元会大幅增加计算复杂度带来算力成本压力。
而且,我们怎么知道不同领域分给几个头更恰当?一个Block划给几个隐层深度更科学?什么样的旋转变换怎么耦合匹配训练对象更精准?
显然,对于复杂系统进一步动态量化机制,还需要更基础底层的理论作为指引。
所以,通用ASI终极大杀器,不得不从根本上重构深度学习多隐层架构,而这只有形成伽罗瓦式规范分解的模块化多隐层结构塔才行。那么,深度学习的炼金术般的隐层扩充与伽罗瓦的严谨数理的正规域扩张,二者挂得上边吗?
一、工程线性变换1.1、数据元定义域的扩展深度学习模型多隐层结构,不同层次各有不同的特征属性,每一层次特征属性各有不同的变量,上一层单个数据元是下层多个数据元的共同集体抽象。比如:语句1 = 单词1 + 单词2 + 单词3 + ......
请注意,上面等式左边的定义域是‘语句’,等式右边的定义域是‘单词’。语句1的含义是单词1、单词2、单词3含义等等的共同融合的整体抽象含义。
下面这个图示是单词层向量空间:

下面这个图示是语句层向量空间:
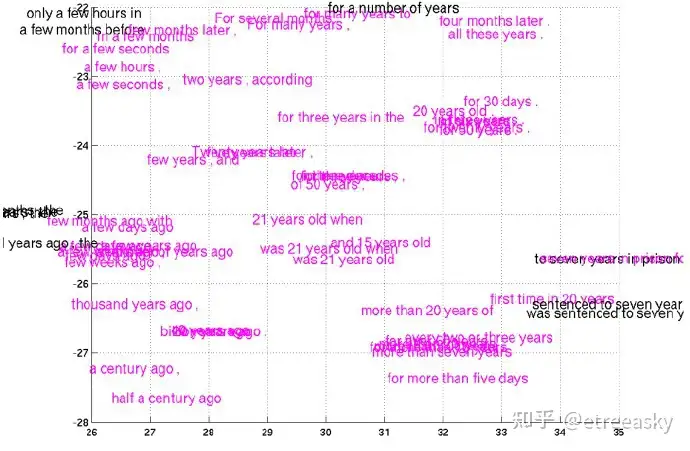
我们可以直观看出,分处于不同层次向量空间的单词层和语句层,单词层次的number与语句层次number的逻辑位置的差异。单词层数据元含义是变化的单词、语句层数据元含义是变化的语句。 当单词特征基系融合为另一层次的逻辑构件(语句)时,单词逻辑层多个数据元集体“抽象”到了语句逻辑层单个数据元,数据元‘含义’(定义域)发生了改变。
对电脑系统而言,要想领会抽象含义,必须对“抽象”这一概念进行准确量化定义。抽象逻辑的数学化,是深度学习模型的重要环节。那么,数学理论中有没有相对应的东东,可以正确表达不同层次逻辑的所谓“抽象”含义呢?数学上,工程线性变换承担了这一角色。
1.2、工程线性变换工程线性变换:f(t)经过线性变换输出为F(s),(工程狭义)是从一个函数空间映到另一个不同函数空间的线性映射,从空间 V 到空间 W ( V→W),自变量与函数空间均发生改变。

线性算子:f(t)经过线性算子输出为g(t),是从一个函数空间映到自身的线性映射,从空间 V 到空间 V ( V→V ),自变量与函数空间保持不变。
二者的区别在于:工程线性变换和线性算子的区别在于其中的变量,工程线性变换的定义域由t变换成了s,线性算子不改变定义域。对于变换,t的函数进去,因s的函数出来,变量发生了变换。 对于算子,t的函数进去,出来的还是t的函数。线性算子是同一线性空间上的线性自同态,不改变参照系空间。线性算子(linear operator) 是工程线性变换(linear transformation)的特例,有:线性映射 ⊇ 工程线性变换 ⊇ 线性算子
线性映射(最广义):满足可加性、齐次性的线性空间映射,是顶层概念。
工程线性变换:f(t)→F(s),不同线性空间之间的线性映射,定义域、值域空间不同,自变量 / 基底 / 域发生改变(如时域→频域,输入空间→隐空间)。工程上常说的线性变换是不同线性空间之间的线性映射,工程线性变换前后的域空间变元发生了改变。
线性算子:f(t)→g(t),同一线性空间内部的线性自同态,空间不变、域不变、自变量不变(如微分、平移、卷积核内线性运算)。
工程线性变换在神经网络中扮演着“坐标系重塑者”和“信息混合器”的角色。隐层中的线性变换 y=Wx+b ,其核心机制是矩阵乘法。权重矩阵 W 的作用, 它不仅仅是一个缩放系数,而是一个空间变换矩阵。它通过旋转、缩放、剪切等操作,将输入数据所在的向量空间特征的加权组合进行扭曲。上一层输出的特征向量 x ,通过与 W相乘,信息传递被重新分配到了一个新的坐标系中。这使得原本在低维或原空间中线性不可分的数据,在新的高维空间中变得线性可分(这就是著名的“核技巧”思想)。深度学习AI主动进行各层次特征的组合、选择、升维/降维,实现多隐层特征的逐层抽象。每一层的线性变换,都是在前一层已经“消化”和“预处理”过的特征基础上,进行更高层次、更任务相关的特征提取和选择。它实现了从“数据表示”到“任务表示”的渐进式转换。低层(靠近输入)线性变换学习的是局部、具体、像素级的特征组合(如边缘、纹理);中层线性变换组合低层特征,形成部件或模式(如眼睛、车轮);高层(靠近输出)线性变换组合中层特征,形成全局、抽象、语义级的概念(如人脸、汽车类别)。权重矩阵 W 对输入特征空间进行线性投影和旋转。每一行权重定义了新空间(下一层)的一个基向量方向,输入向量在该方向上的投影就是新特征的值。每个隐层输入向量的每个分量(可看作原“坐标系”下的坐标)被线性组合,投射到一个全新的“坐标系”(即下一层次的特征基)架构上,这正是参照系的转换。深度学习隐层之间的线性映射是典型的“工程线性变换”。深度学习相邻全连接层 / 线性层之间的线性映射,属于工程狭义线性变换,不属于线性算子。
输入向量 x∈R^din 来自输入特征空间 V;
输出 z=Wx+b(齐次部分 Wx 为纯线性)映射到隐层特征空间 W;
空间维度、特征基底、语义参照系完全改变,跨空间、跨域、变量(特征维度)发生变换,不是同一空间内的自同态,因此是工程线性变换,不是线性算子。
1、深度学习里标准 线性层(全连接层 FC / Linear Layer)的前向计算:
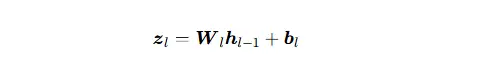
h_(l−1)∈R^Dl−1:第 l−1 层输出特征,属于源线性空间 V_l−1
z_l∈R^Dl:第 l 层线性输出,属于目标线性空间 V_l
W_l∈R^(Dl×Dl−1):线性变换矩阵
b_l∈R^Dl:平移项(仿射偏移,线性结构的扩展),此处算式加上偏置 b_l 后是仿射变换。工程线性变换矩阵 W 是信息传递、空间变换的绝对核心,偏置只是原点平移,不改变线性变换的本质。非线性函数 g (如ReLU, Sigmoid) 是后续的“非线性激活”,它不改变“线性变换”部分的本质,但偏置 b_l使得整个层不再是线性的。没有偏置 b_l,多层网络会退化为单层线性模型。
2、深度学习层间核心线性结构是:
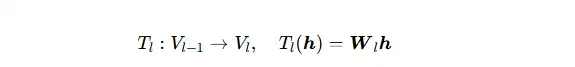
这是标准的工程狭义线性变换:
①满足线性公理:T(αh_1+βh_2)=αTh_1+βTh_2
②跨空间映射:D_(l−1)≠D_l 是常态,即使 D_(l−1)=D_l,基底与语义空间也完全重构
③域发生变换:输入特征分布 → 隐层特征分布,参照系改变
举例:CNN 卷积核内运算是线性算子,卷积层整体通道 / 特征映射是工程线性变换;Transformer 的 Q/K/V 投影矩阵为工程线性变换,符合两大模型的结构设计与数学本质。
三、层间线性变换「信息传递」的完整机制工程线性变换:f(t)→F(s),t 函数进 → s 函数出,空间变、域变、参照系变,
套入深度学习就是:输入特征向量(原空间信号)进 → 隐层特征向量(新空间信号)出,特征空间变、基底变、语义表示域变。
机制 1:线性变换 = 对原空间特征做「加权投影 + 重组」,不改变线性结构
线性变换矩阵 W 的每一行 wi,:,是目标空间的一个新基底方向,也是一个线性投影算子:
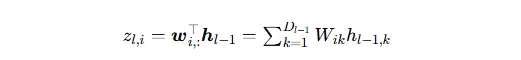
输入是原空间V_(l−1) 的特征组合(如同 f(t))
输出是新空间V_l的投影系数(如同 F(s))
每一个隐层神经元,都是一次从输入域到隐域的线性采样 / 工程线性变换
保留输入特征中线性可解释的全部信息
丢弃冗余线性方向,强化有用线性方向
不创造新的非线性信息,只做线性信息的搬运与重分配
机制 2:跨空间维度变换 —— 升维 / 降维,都是「工程线性变换」
降维(ompression) 将高维特征压缩回低维(如 4×dmodel→dmodel4×dmodel→dmodel )。这迫使网络提取最重要的特征,形成“信息瓶颈”,有助于防止过拟合,保留数据的本质流形结构。降维[D_l<D_(l−1)]如 512→128,高维输入空间 → 低维压缩隐空间,类似 PCA,是典型线性变换(如同时域信号→低维频域系数)。
升维(Expansion)将低维特征映射到高维空间(如 dmodel→4×dmodel)。这增加了模型的表达能力,为非线性激活函数提供更多的“自由度”来拟合复杂函数。升维[D_l>D_(l−1)]如 64→256,低维输入空间 → 高维展开隐空间,把挤在一起的特征拉开,也是跨空间线性变换。
无论升维降维,都是从一个域映射到另一个域,空间改变,因此是工程线性变换,不是同一空间的算子。维度缩放通过改变输出维度 (n_l),网络可以主动控制信息的“宽度”(增加特征/通道数以编码更多信息)或“压缩”(减少维度以实现降维或汇聚)。
机制 3:工程线性变换是「信息通道的权重门控」,决定什么信息传递到下一层
W 的权重值,本质是信息传递的优先级系数:
W_ik 大:第 l−1 层第 k 个特征,对第 l 层第 i 个特征贡献大,这条信息通道被打开
W_ik 接近 0:该特征通道被关闭,信息被过滤
线性变换在这里的角色:对前一层的全部信息做线性筛选、加权、路由,把原域的有效信息,线性映射到新域的新坐标上。
t 的函数进去,s 的函数出来,变量发生变换,定义域由 t 变成 s。前层特征域进去,后层隐特征域出来,特征参照系发生变换,输入空间变成隐空间。
机制 4:多层线性变换串联 = 复合线性变换,仍然是线性变换
工程线性变换的每个输出神经元都是所有输入神经元的加权和。深度学习多隐层结构的各层次特征交互,强制神经网络学习输入特征之间全局性的、密集的相互作用模式。这是全连接层的精髓。
多层线性层堆叠:
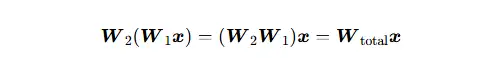
这在数学上仍然是一次线性变换,仍然是:输入空间 V0 → 最终输出空间 VL,跨空间,工程线性变换。这也证明单纯线性变换只能做空间映射,无法拟合复杂结构,必须配合非线性激活函数复合打破一阶线性空间的闭合性。
四、层间线性变换的「深刻作用」—— 为什么深度学习离不开它?作用 1:它是唯一能「跨空间传递线性信息」的标准结构
深度学习的核心是层级化表示学习:像素空间 → 边缘空间 → 纹理空间 → 部件空间 → 语义空间
每一层跃迁,都是从一个特征域,换到另一个完全不同特性元粒度的特征域。
能实现域变换、空间变换、跨线性空间映射的,只有工程线性变换。线性算子只能在同一空间内扭动、平移、微分,无法跳域、无法升维降维、无法切换特征参照系。层间必须是工程线性变换,而不能是线性算子。
作用 2:工程线性变换是「特征解耦与重编码」的线性底座
真实数据(图像、文本、语音)都是多个特征线性混叠的信号,如同被调制的 f(t)
线性变换在这里,是所有高层语义特征的线性解耦基座。线性变换 W_x 做的就是把混叠在原空间的纠缠特征,通过基底变换,解耦到新空间的坐标轴上。类比我们熟悉的信号:
傅里叶变换(线性变换):时域混叠信号 → 频域单频分量
深度学习线性变换:原域混叠特征 → 隐域解耦特征分量
作用 3:工程线性变换提供「可学习的基底」,让网络自适应选择最优表示
傅里叶、小波是固定基底的线性变换;深度学习层间 W 是可学习、可优化、数据驱动的线性变换基底。它的深刻意义在于把 人工设计线性变换 变成AI自主从数据里自动学习最优线性变换。网络通过反向传播更新 W,本质是在学习从输入域到输出域的最优线性映射关系,这是深度学习表示能力的线性根基。
作用 4:工程线性变换是梯度反向传播的「信息高速公路」
误差反向传播时,梯度的回传完全依赖线性变换的链式法则:
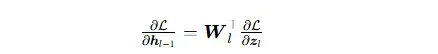
线性变换的可导性、线性结构、矩阵转置映射,让梯度可以从顶层损失空间,一路线性回传到底层输入空间。如果没有层间线性变换,梯度无法跨空间回传,深度网络根本无法训练。
作用 5:工程线性变换 + 非线性激活 = 万能近似的核心组合
线性变换:负责空间变换、跨域映射、信息路由(变空间、变域,你的狭义线性变换)。线性部分的作用提供可训练的、连续的、光滑的空间变换骨架。它本身只能表达直线、平面等简单几何结构。
非线性激活(ReLU/Sigmoid/Swish):负责打破线性闭合,制造非线性边界,拟合复杂函数。非线性激活的作用在每次线性变换后,引入弯曲、折叠、截断等非线性操作(如ReLU的“折纸”效应)。
线性+非线性协作模式: 二者分工完美互补,线性变换把数据挪到 “更容易被分开” 的新空间;非线性激活在新空间里切出复杂决策边界。线性变换负责将数据映射到一个新的空间,非线性激活函数(如ReLU)负责在这个新空间中进行“折叠”或“裁剪”。Linear→Non−linear→Linear→Non−linear...Linear→Non−linear→Linear→Non−linear... 线性变换是“揉面”(改变空间形状),非线性变换是“切一刀”(引入分段线性)。只有不断揉面再切刀,才能拟合出极其复杂的曲面。
虽然我们常说“激活函数引入了非线性”,但如果没有线性变换,激活函数将毫无用处。参数的载体(模型的记忆)依赖线性变换,线性变换层(全连接、卷积)是神经网络中唯一拥有可学习参数(W,b)的地方。 训练神经网络的过程,本质上就是通过反向传播算法,不断调整这些线性变换矩阵 W 的数值,从而找到那个最优的空间扭曲方式,让数据变得易于分类。没有工程线性变换,非线性只能在原空间折腾。
如果只有线性层堆叠,无论多少层单独的线性变换,最终都会退化成一个单层线性模型(y=W3(W2(W1x+b1)+b2)+b3≡y=W′x+b′ )。没有非线性,线性变换只能做投影,无法学习复杂任务。
工程线性变换与非线性激活二者协同效应:非线性激活(线性变换(非线性激活(线性变换(...)))) 这种交替结构,使得网络能够用一系列简单的“工程线性变换+非线性扭曲”操作,逐层复合出一个极度复杂的、高度非线性的最终函数。每一次线性变换都为下一次非线性操作准备了一个新的、经过优化的“中间表示空间”。工程线性变换函数与非线性激活函数交替堆叠,成为构造复杂万能函数逼近器的基本“积木块”。多层网络中的线性变换并非孤立操作,它们与非线性激活函数交织,共同构成了神经网络的“高阶表达能力引擎”。深度学习的强大能力,很大程度上源于众多简单的线性变换单元,在非线性激活的“粘合”下,通过深度堆叠所涌现出的、复杂的表示学习和函数逼近能力。工程线性变换是这场“表示革命”中最基础、最核心的发动机之一。
五、层间线性变换 vs 层内线性算子| 类别 | 工程线性变换(层间) | 线性算子(层内 / 局部) |
|---|---|---|
| 数学形式 | Wx,Vin→Vout | Df、K∗f、平移,V→V |
| 空间是否改变 | 是,跨不同线性空间 | 否,同一空间内部 |
| 域 / 自变量是否改变 | 是,输入域→隐域,参照系切换 | 否,域不变,特征空间不变 |
| 深度学习位置 | 全连接层、投影层、层与层之间 | 卷积核内线性运算、层内归一化线性部分、注意力内线性组合 |
| 核心功能 | 跨空间信息传递、升维降维、特征重编码 | 同空间滤波、平移、微分、局部线性运算 |
| 对应例子 | f(t)→F(s)(拉普拉斯 / 傅里叶) | f(t)→f′(t)(微分)、f(t)→f(t−a)(平移) |
深度学习层与层之间的线性映射 = 工程狭义线性变换,完全符合 “t 进 s 出、变空间、变域” 的定义。
CNN卷积里的卷积核加权求和,是局部感受野内的线性算子;但卷积层整体的 “通道升维、特征映射”,仍然是跨通道空间的线性变换。卷积层中的线性变换(卷积核)作用,强制学习平移不变性的特征检测器。它定义了一个局部的、共享权重的线性滤波器,在输入的空间/通道维度上进行滑动,提取局部模式。这是将“全局密集交互”的先验替换为“局部稀疏交互”和“参数共享”,极大提升了效率并符合图像数据的特性。
Transformer中注意力里的 Q,K,V 投影矩阵,全是工程线性变换(词向量空间→查询 / 键 / 值空间)。自注意力机制中的线性变换(Q, K, V投影)作用,将输入序列的每个token,通过三个不同的线性变换 (W_Q, W_K, W_V) 投影到查询(Query)、键(Key)、值(Value) 三个不同功能的子空间。这是实现动态、内容感知的特征交互和上下文聚合的关键。这里的线性变换不是为了降维或升维,而是为了改变特征的“角色”和“语义”,以便进行有效的注意力计算。
在深度学习中,多隐层之间的线性映射,绝非线性算子。隐层之间的线性映射 (Wx + b) 是从一个向量空间到另一个向量空间的线性变换,它完美符合标准的工程狭义线性变换。它把前一层原特征空间(t 域)的信息,通过可学习的线性映射矩阵,变换到后一层全新的隐特征空间(s 域),完成跨空间、跨域、跨参照系的信息传递与重编码,是深度网络层级表示学习、梯度回传、特征解耦的底层线性骨架;再配合非线性激活,最终获得拟合任意复杂函数的能力。
【更深解读】每一层隐层特征元跃迁,都是从一个特征域,换到另一个完全不同的特征域。层间线性变换特征元跃迁 ,其实就是特征域扩张: F⊆K 都是域,F 是基域、 K/F 是一个隐层域的扩张,得到K 是更大的域。显而易见,这类似于伽罗瓦群域扩张。并且,随着伽罗瓦域的扩张K/F,存在着伽罗瓦群Gal(K/F)的子群与扩张的中间域之间的一一对应关系。具体来说,若H是Gal(K/F)的子群,那么H的不动域是一个中间域;反之,对于任意中间域E,存在Gal(K/F)的子群Gal(K/E)与之对应。
换句话说,深度学习的多隐层特征元扩展,从一开始,天然就黏上了伽罗瓦群特征解域扩张!
逻辑脉络:工程概念界定→深度学习数学形式→信息传递机制→核心作用→模型实例验证→伽罗瓦域类比
当然,当前原始的深度学习多隐层结构域的扩张K/F还不是正规扩张,所以Gal(K/E)也不是Gal(K/F)的正规子群。不过,假若我们有心改造将隐层域扩张变为正规扩张,会有多难么?

https://wap.sciencenet.cn/blog-1666470-1529145.html
上一篇:深度学习多隐层架构数理逻辑浅析(十九)(7)