基于强化学习的数据驱动多智能体系统最优一致性综述
李金娜, 程薇燃
辽宁石油化工大学信息与控制工程学院,辽宁 抚顺113000
【摘 要】 多智能体系统因其在工程、社会科学和自然科学等多学科领域具有潜在、广泛的应用性,在过去的 20 年里引起了研究者的广泛关注。实现多智能体系统的一致性通常需要求解相关矩阵方程离线设计控制协议,这要求系统模型精确已知。然而,实际上多智能体系统具有大规模尺度、非线性耦合性特征,并且环境动态变化,使得系统精确建模非常困难,这给模型依赖的多智能体一致性控制协议设计带来了挑战。强化学习技术因其可以利用沿系统轨迹的测量数据实时学习控制问题的最优解,被广泛用于解决复杂系统最优控制和决策问题。综述了利用强化学习技术,采用数据驱动方式实时在线求解多智能体系统最优一致性控制问题的现有理论和方法,分别从连续和离散、同构和异构、抗干扰的鲁棒性等多个方面介绍了数据驱动的强化学习技术在多智能体系统最优一致性控制问题中的应用。最后讨论了基于数据驱动的多智能体系统最优一致性问题的未来研究方向。 【关键词】 强化学习 ; 多智能体系统 ; 最优一致性 ; 数据驱动
李金娜, 程薇燃. 基于强化学习的数据驱动多智能体系统最优一致性综述[J]. 智能科学与技术学报, 2020, 2(4): 324-340.
LI J N, C W R. An overview of optimal consensus for data driven multi-agent system based on reinforcement learning[J]. CHINESE JOURNAL OF INTELLIGENT SCIENCE AND TECHNOLOGY, 2020, 2(4): 324-340.
多智能体系统由于具有更好的鲁棒性、灵活性和可扩展性,在工程、社会科学和自然科学等多学科领域被广泛地应用。多智能体一致性问题的目标是根据每个智能体及其相邻智能体的局部信息制定控制协议,使所有智能体在一定数量的收益量上达成一致或跟踪一个参考轨迹。近年来,对多智能体的分布式一致性问题的研究因得到各界的广泛关注而迅速发展,在群集、智能电网、卫星群和无人机等各个领域应用广泛。大量文献提出了各种分布式一致性控制协议来保证系统的一致性。随着对一致性问题的深入研究,在获得各个智能体一致性的同时,人们开始研究最小化由智能体之间的局部邻居误差和控制输入组成的预设的性能指标的技术方法,该性能指标代表了多智能体系统的能耗、效率和精度。换言之,每个智能体通过计算局部信息(即自身和邻居的信息)来寻找分布式一致性问题的最优解,这被称作最优一致性控制问题。近年来,大量学者沿着不同的思路和方向对多智能体系统最优一致性问题进行了研究,从连续系统和离散系统、有领导者和无领导者、同构[ 20,21] 和异构等多个方面进行了研究。研究多智能体的分布式最优一致性问题是发挥多智能体系统可以用更灵活更智能的方式处理复杂的问题、解决单智能体不能解决的大规模复杂问题等优势的关键,具有重要的现实意义和理论价值。 目前许多国内外研究者致力于对多智能体系统的分布式控制的研究,对于离散的多智能体系统的分布式一致性问题的研究存在有限时间、参数调节、时延等不同的研究问题,并且对异构多智能体系统的研究更广泛。 随着自适应动态规划方法的不断发展,这种控制方法也被深入应用到了多智能体的最优一致性问题中。 但是随着多智能体系统规模的不断扩大以及数据的不断增多,需要发展更智能的控制技术来解决这些困难。 强化学习(reinforcement learning,RL)是机器学习的一个子领域,其受哺乳动物学习机制的启发,研究如何根据观察到的来自环境的响应系统地修改智能体的行为。强化学习算法指与环境相互作用的智能体利用环境的响应来学习最优控制策略,并从未知环境中找出最优行为的算法。1991年, Werbos P J较早提出了基于强化学习的自适应动态规划(adaptive dynamic programming,ADP)控制,首创采用强化学习技术求解离散系统的最优调节器。这种控制算法采用策略迭代(policy iteration, PI)技术,仅要求对系统动力学有部分了解。2009年, Doya K提出了将强化学习技术应用到求解连续时间系统的控制器中。参考文献 提出了利用积分强化学习(integral reinforcement learning,IRL)的在线学习算法,用于解决系统模型部分未知的线性或非线性系统的最优跟踪控制问题。强化学习算法也被用来求解 H∞控制问题,例如利用强化学习算法解决H∞控制问题的Q-学习方法以及神经动态规划方法。近年来,将强化学习技术应用于多智能体系统的最优一致性控制的研究越来越受到人们的关注。参考文献 引入基于模型的强化学习算法来求解多人微分对策问题。参考文献 考虑了最优协同控制问题,采用基于模型的自适应动态规划方法来学习耦合哈密顿-雅可比-贝尔曼(Hamilton-Jacobi-Bellman,HJB)方程的解。 需要注意的是,参考文献 提出的利用强化学习算法解决多智能体系统最优一致性的方法要求系统模型已知或者部分已知,并使用策略学习方法求解最优一致性协议。随着数字传感器技术的迅速发展和广泛应用,人们可以采集到大量承载系统信息的数据。人们希望利用这些数据开发数据驱动的最优控制协议。数据驱动技术已经被广泛应用于解决单智能体系统的最优控制问题,与策略强化学习(on-policy RL)相比,非策略强化学习(off-policy RL)中引进了行为策略和目标策略,通过行为策略来生成系统的数据,在丰富数据挖掘的同时更新目标策略,以寻找最优策略。非策略强化学习算法克服了策略强化学习算法在应用中产生的两个缺点:一是数据只能由一种特定的方法生成,导致数据挖掘能力非常有限;二是为了充分激励系统,在目标策略中加入探测噪声,使贝尔曼方程的解产生偏差。非策略强化学习是一种更实用、更有效的处理最优控制问题的技术。随着数据处理技术和人工智能技术的深入发展,数据驱动的强化学习技术也越来越多地被应用到多智能体的最优一致性问题中。 基于数据驱动的强化学习技术利用实时测量的数据,在系统动态完全未知的情况下,解决多智能体系统的最优一致性控制协议设计或者决策问题,这对于研究更具复杂性的多智能体系统具有重大的推动作用,是十分重要的方法。 智能体之间的数据交换导致了智能体动力学的耦合性,这给数据驱动的多智能体最优一致性控制问题带来了挑战。 本文综述了基于数据驱动方式解决分布式多智能体系统最优一致性问题的主要成果和进展,将该领域的最新研究成果分为连续、离散、同构、异构、含有扰动等最优一致性问题。 最后讨论了基于强化学习的数据驱动多智能体最优一致性控制的未来的研究方向和挑战性问题。
本节首先介绍研究多智能体系统最优一致性需要用到的图论理论,然后从有领导者和无领导者两个方面介绍多智能体系统最优一致性的定义,最后介绍解决多智能体系统最优一致性所需要的博弈理论。 图论是一致性问题研究分析中非常重要的工具,通常采用图来表示多智能体之间传递信息的关系。考虑由N个多智能体组成的系统,其网络拓扑图为 。其中, ,表示网络拓扑图的顶点集; 表示网络拓扑图的边; 被称为连通矩阵,如果 ,则e ij >0,否则e i =0j 。 表示从顶点v j 到顶点v i 的一条边。定义 为节点v i 的邻居集。 被称为度矩阵,其中 为顶点v i 的加权度。 定义网络拓扑图的拉普拉斯矩阵为。 在解决多智能体的最优一致性问题时,通常将其分为有领导者和无领导者两类进行研究。 考虑由N个智能体组成的多智能体系统,式(1)为智能体的动力学模型:
其中, 和
领导者的动态为:
其中,x 0、 为领导者系统状态量和状态导数,A为领导者系统动态矩阵。 定义 1多智能体系统的一致性问题是设计局部控制协议u i 使所有智能体的状态与领导者达成一致,即对于 。根据多智能体系统最优一致性的概念,为了使式(1)的系统达到最优一致性,可以为每个智能体定义一个局部二次性能指标:
其中,Ri 在多智能体系统中,如果各智能体的地位和作用是平等的,则称这样的系统是无领导者的多智能体系统。 定义2设计局部控制协议u i ;(b)最小化式(3)的性能指标。 2.3 博弈理论
博弈理论是解决分布式问题的有力工具,为研究多人决策和控制问题提供了一个理想的环境。参考文献介绍了多智能体系统的合作控制与博弈理论之间的联系。参考文献将合作控制、强化学习和博弈理论结合起来,提出了一种多智能体团队博弈的在线求解方法。在动态系统中,每个节点的动态性和性能指标只依赖于局部邻居信息,参考文献提出了图形博弈的概念,并给出了“交互式纳什均衡”的新定义。 假设图G是强连通的,根据N个智能体组成的多智能体系统(式(1))和领导者(式(2))定义局部邻居一致性误差变量:
其中, a ij 为连通矩阵,g i 为一致性误差变量。其动态模型为:
其中,d i 为智能体顶点的加权度。定义一个局部二次性能指标:
其中,Qi R i 定义3 N个智能体博弈的全局纳什均衡解是一个N元组 ,并满足:
其中,全部 i 满足 i∈N,对于 为最优值。 博弈N元组的值 被称为N个智能体博弈的纳什均衡结果。 达到一个纳什 均衡,每个参与者的价值函数都能得到优化。 在这种纳什均衡下,没有一个博弈者能够通过改变其输入策略来提高其绩效指标。
在研究多智能体的各种分布式一致性方法时,遇到的共同难题是缺乏整个系统的全局知识,每个智能体只能与其邻居进行交互,以实现某些全局行为。同时,为了寻找最优策略,需要求解耦合的哈密顿-雅可比(Hamilton-Jacobi,HJ)方程。随着数字传感器技术的迅速发展和广泛应用,大量的数据可以通过数据驱动的方式进行采集,这些数据承载了系统信息。研究者希望利用这些数据来开发基于模型数据的最优控制协议。强化学习技术的发展使得研究者可以利用沿系统轨迹的测量数据实时学习优化控制问题的最优解。近几年,很多研究致力于利用强化学习技术,通过基于数据驱动的方式来学习多智能体系统一致性问题的最优的控制策略。本节从同构、异构和具有扰动的多智能体系统3个方面,总结近年来利用基于强化学习的数据驱动技术解决多智能体最优一致性的研究成果和结论。 3.1 基于强化学习的同构多智能体系统最优一致性
基于数据驱动的同构多智能体系统的分布式一致性问题涉及许多关于连续时间的系统。参考文献针对多智能体系统的最优同步问题,提出了一种非策略强化学习算法,并利用产生的数据,采用actor-critic神经网络和最小二乘法来逼近目标控制策略和值函数,得到每个智能体近似最优控制策略。参考文献提出了一种非策略强化学习算法,用可测状态数据代替状态时滞系统动力学知识来学习耦合时变 HJB 方程的两阶段最优一致解。然后,对于每一个智能体,利用单临界神经网络来逼近时变值函数,并帮助计算出最优一致性控制策略。在加权残差法的基础上,参考文献提出了基于加权残差的自适应权值更新律。 对于离散时间的同构多智能体系统,近几十年来,强化学习算法的策略迭代和值迭代技术被广泛应用于求解离散时间的多智能体系统的最优一致性控制。然而,大多数物理系统是非线性的,具有高阶动力学特性,很难对其进行精确建模。作为基于数据的最优控制方法,QD 学习(distributed Q-learning)和Q学习已经被用来学习离散的多智能体系统一致性问题的最优解。对于离散系统,参考文献给出了线性系统的动态图形对策,开发了一种算法来求解博弈问题。参考文献提出了一种实时求解离散线性系统动态图形对策的无模型策略迭代算法,并证明了算法的收敛性。参考文献将这种无模型的策略迭代算法用到了非线性系统优化控制问题中。参考文献研究离散时间多人非零和博弈问题,提出了一种基于数据驱动的基于动作的启发式动态规划方法。下面分别从连续多智能体系统和离散多智能体系统两个方面介绍基于强化学习的数据驱动多智能体最优一致性控制研究成果。 连续多智能体系统以式(1)的多智能体系统的动态特性为系统模型,将控制输入解释为依赖于局部邻居跟踪误差的策略,对应于性能指标(式(3))的值函数为:
其中,u i
其中, 为梯度算子,e ij g i 为智能体的顶点增益, d i 为智能体顶点的加权度,A、B为适当维数的多智能体系统的动态矩阵。最优控制策略为:
其中,p i
其中,R i R j
为了达到全局纳什均衡,需要通过求解N个智能体博弈问题的N个耦合偏微分HJB方程(式(9))来计算每个智能体的最优响应。如果所有的智能体选择自己的最优响应,并且网络拓扑图是强连通的,那么系统是渐近稳定的。因此,所有智能体都是同步的。同时,这N个智能体都处于全局纳什均衡状态。 对每个智能体的动态,引入辅助变量 和 ,有:
其中,ui 为目标策略。 对进行微分,通过式(14)得到:
进一步,有:
步骤1:对于∀i从一个允许的初始控制策略 u i 0 开始计算,令s代表控制策略迭代系数,并且s=0; 步骤2:根据非策略贝尔曼方程(式(16))求解 V i+1 和u i+1 步骤3:当 时,停止。 需要注意的是,算法1中不包含系统模型的参数信息,完全利用系统产生的数据来学习得到最优控制策略,并且不受模型不精确或辨识系统模型简化的影 响。目前值函数和控制策略估计的方法往往采用最小二乘法或者神经网络估计方法。算法1这种非策略强化学习算法具有显著的优点,其可以在不需要智能体系统的动力学知识、无须系统辨识的情况下学习连续多智能体系统的近似最优控制协议,在不影响最优控制协议精度的前提下,消除因为模型辨识不准确所带来的负面影响。不同于现有的基于模型的多智能体系统最优控制,算法1体现了非策略强化学习算法的优势。 考虑一个由通信图G描述的具有N个智能体的离散时间的多智能体系统。每个智能体的动态如下:
其中,和 分别是第i个智能体的系统状态量和控制输入量。
求解离散时间的多智能体系统的最优一致性控制,得到分布式控制协议(式(20))需要以下两个部分的计算。
参考文献在系统未知的情况下利用数据驱动的方式解决最优一致性控制问题。首先通过定义Q函数,得到关于Q函数的贝尔曼方程:
步骤 1:给定一个控制策略 , K 0 是使(A、B)稳定的控制器增益;
步骤4:重复步骤2、步骤3,直到 , ε为任意的极小值,停止迭代; 步骤5:为近似最优控制策略, 是最优反馈增益。 其次,根据算法 2,若利用数据驱动方式求解多智能体一致性,还需要计算可行的耦合增益c,为得到,需要计算式(25):
由Q函数,得到矩阵 。
因此可以利用矩阵H来学习
式(28)可以避免使用系统矩阵 (A、B)。利用求解的反馈增益K和耦合增益c,得到离散时间多智能体系统的分布式控制协议。 算法 2 在研究基于 LQR 的协同控制设计的基础上,成功地引入了一种近似动态规划技术来解决线性多智能体系统(部分或完全)无模型协同控制问题。由于A是不确定的,因此在使用强化学习算法时,可以依靠设计者的经验来获得对智能体的初始稳定控制。并且 HDP 算法可以从任意的初值函数开始,避免了对稳定控制的要求,但仍然存在的困难是输入矩阵B必须已知,因此算法2不能实现完全的无模型控制。 3.2 基于强化学习的异构多智能体系统最优一致性
在广泛的实际应用中,单个系统可能具有不同的动力学特性,事实上它们的状态可能具有不同的维数。因此,许多研究致力于解决异构多智能体系统网络中的一致性,其中智能体的动态性可能不同。对于离散的异构多智能体一致性,参考文献研究了离散时间异构多智能体系统最优一致性控制的Q学习方法。在Bellman-Q函数的基础上,得到了Bellman-Q-Q函数。采用策略迭代法迭代求解最优控制,并采用最小二乘法对实现过程进行激励。参考文献提出了一种自适应最优分布式算法,用于求解存在外部干扰的未知非线性约束输入系统的多智能体离散时间图形对策。该算法基于数值迭代启发式动态规划,在不需要系统动力学知识的情况下求解耦合的哈密顿-雅可比-埃萨克斯(Hamilton-Jacobi-Isaacs,HJI)方程组。参考文献建立了一个折扣性能指标,介绍了用于激励的策略迭代算法。为了实现所提出的在线行为相关启发式动态规划方法,分别利用critic神经网络和actor神经网络实时逼近迭代性能指标函数和控制策略。因为异构多智能体系统可以有不同的状态维数,所以对于异构的多智能体系统问题一般不考虑状态一致性,大多考虑输出一致性,并假设输出具有相同的维数。关于多智能体系统的输出一致性,参考文献研究了网络连接多智能体系统的一致性输出调节问题。每个智能体或子系统都是一个相对度为1的输出反馈形式的非线性系统,但子系统在不同的非线性函数甚至不同的系统阶数下可能具有不同的动力学特性。参考文献提出了一种一致性控制设计方法,利用内模设计策略,保证各子系统的输出收敛到同一期望输出轨迹上。参考文献研究了具有多个未知领导者的一般线性异构多智能体系统的自适应输出包容控制问题。输出控制的目标是保证每个跟随器的输出收敛到由领导者输出的动态凸壳上。参考文献利用状态反馈和动态输出反馈两种分布式控制协议,提出了一种自适应调节律来求解相关的输出调节器方程组。参考文献设计了一个分布式自适应观测器来估计每个智能体的领导者状态,然后将输出同步问题转化为最优控制问题,并提出了一种新的无模型脱离策略强化学习算法,实时在线求解最优输出同步问题。参考文献将多智能体系统最优输出同步问题考虑到非线性系统中,设计了一个分布式观测器来估计每个智能体的领导状态;推导了一个增广的HJB方程,利用HJB的解隐式得到最优解,并通过数据驱动的方式学习每个智能体的最优控制协议。下面分别列举几类利用数据驱动求解异构多智能体系统一致性问题的算法。 对于具有完全未知系统动力学和不确定参数变化的异构多智能体系统的最优鲁棒输出控制问题,参考文献提出了一种基于模型的算法,利用离线策略迭代来解决标称系统模型可用时的鲁棒输出抑制问题。利用p-copy内模原理处理参数变化。为了解决系统模型不可用的问题,从误差动力学和智能体动力学出发,构造了一个新的增广系统,然后为每个智能体引入一个折扣性能函数,从而建立了一个具有有界 L 2 增益的最优输出反馈设计问题。只使用在线计算的状态输出数据,利用贝尔曼方程计算出最优控制策略,并同时找到更新的控制策略。最后,利用这个贝尔曼方程,在不需要任何系统动力学知识的情况下,利用非策略积分强化学习开发了一个无模型算法来实时求解异构多智能体系统的最优鲁棒输出包容问题。 考虑分布在网络拓扑图G上的N+1个节点,其中N个不同的节点可描述为:
首先为每个跟随器设计以下分布式控制器,该控制器由一个局部分布式观测器和采用状态反馈设计的控制协议组成
参考文献得到如下闭环系统:
其中,
根据状态反馈 L 2 增益定理,令 为S的最小 p-copy 内部模型,选择 。利用控制器(式(30))解决鲁棒输出抑制问题,存在矩阵 ,且:
参考文献 提出了一种非策略积分强化学习算法,通过构造新的增广系统,利用固定的控制策略得到完整的状态信息。因为这个增广系统的解依赖于未知的系统动力学信息,所以定义的状态信息无法使用。为了解决这个问题,笔者给出了以下方法来重建一个新的增广系统,其中状态和输出信息都是可用的。 为了实现非策略积分强化学习算法,需要利用固定的控制策略找到的完整状态的信息。在解决鲁棒输出抑制问题时,不考虑增广系统,而是求解增广系统的有界L 2
定义全局变量,构造如下的全局增广系统动力学方程:
得到输出反馈设计的非策略积分强化学习贝尔曼方程:
步骤1:对于每个跟随者i,令为S的最小 p-copy 内部模型。 定义系统的混合控制策略 ,其中 是稳定的, 是一个扩展干扰。 收集系统状态,输出控制输入的反馈信号。 得到 和 ; 步骤2:利用收集到的系统信号求解积分强化学习的贝尔曼方程,并得到和 。 由于积分强化学习的贝尔曼方程在一定的激励持续性条件下,这些解可以用最小二乘法唯一确定; 步骤 3:,令 。 算法3解决了未知系统参数不确定时的鲁棒控制问题,创新点是构造了新的增广系统,这表明,利用从实际系统收集的状态、输出和控制输入信息来稳定增广系统的方法可以解决多智能体鲁棒控制问题。 参考文献研究了具有未知非线性动力学的多智能体主从系统的最优输出同步问题,设计了一个分布式观测器来估计每个智能体的领导状态;为每个智能体定义了一个折扣性能函数,并导出了一个增广HJB方程,求其最小值。HJB解依赖于局部状态和分布观测状态的轨迹。基于HJB解决方案的控制协议保证了所有代理的同步误差局部渐近快速地归零。与标准输出同步方法相比,该方法有两个主要优点:第一,它不仅使稳态同步误差为零,而且使瞬态误差最小;第二,它不需要输出调节器方程的显式解,因为HJB解隐式地提供了最优解。参考文献通过利用强化学习技术来学习每个智能体的最优控制协议,而不需要任何代理或领导者动态的知识;开发了一种非策略强化学习算法,以学习HJB方程的解,从而在线找到每个代理的最优控制协议,而不需要任何关于代理或领导者动态的知识。非策略强化学习算法通过使用两个神经网络,即actor和critic神经网络,近似得到每个智能体的值函数以及更新控制策略。
利用最小二乘法使贝尔曼方程误差最小化。贝尔曼近似误差可以改写成:
其中,
在状态空间中通过从点 t 1 到t N 得到 和 。 采用 最小二乘法得到:
其中,, 所提出的求解HJB的方法不需要了解代理或领导动态。 每个智能体需要通过知道领导者的状态维数和它自己的状态矩阵来执行非策略强化学习算法。 参考文献设计了一个自适应的分布式观测器来估计领导者的状态,并无须任何智能体的动态知识,利用强化学习方式来求解黎卡提方程。其优点是这种方法不需要求解输出调节器方程,不需要通过在每个智能体的控制器中加入领导者动态方程的方式来求解异构系统的输出同步问题。 3.3 具有扰动的多智能体系统最优一致性
在多智能体博弈中,为了寻找最优策略,需要求解耦合的 HJ 方程。在现实世界中,外部干扰是不可避免的,其会影响系统的性能和稳定性。因此,在存在未知外部干扰的情况下,求解多智能体博弈问题也是研究多智能体系统最优一致性的一个关键问题。为了求解具有外部扰动的多智能体对策,需要求解耦合的HJI方程。然而,由于系统状态的不确定性和求解这些非线性方程组的困难性,需要通过基于强化学习的数据驱动技术来近似求解这些方程组。 研究含有扰动的多智能体一致性问题通常采用输出调节、H∞控制、内模原理、增广矩阵等方式。在求解具有未知动力学的离散 HJI方程的研究中,参考文献研究了二阶离散多智能体系统的合作鲁棒输出调节问题,基于数据驱动设计了一种分布式动态状态反馈控制律,并采用内模方法求解鲁棒输出调节问题。对于存在外部干扰的未知非线性约束输入系统的多智能体离散时间图形对策问题,参考文献基于数值迭代启发式动态规划,使用一个actor-critic结构来近似得出值函数、控制策略和最坏情况下的干扰策略,并验证了闭环系统的稳定性和对纳什均衡的收敛性。参考文献提出的非线性多智能体系统的分布式协同H∞最优跟踪控制算法对每个智能体只使用一个神经网络,并保证闭环系统中的神经网络权值逼近误差和协作跟踪误差等所有信号最终一致有界。对于连续系统,参考文献研究了一类多智能体系统的最优一致问题,这类问题的跟随者动力学是未知的,领导者由一个扰动的外系统来模拟产生,文中提出了一种数据驱动方法,该方法对不可测量的先导扰动具有一定的鲁棒性。参考文献提出使用基于数据驱动的多智能体系统在线策略迭代算法来求解耦合的 HJI 方程。参考文献利用鲁棒自适应动态规划方法,通过在线输入和状态数据,设计了无模型的分布式控制器来解决具有参数和动态不确定性的多智能体系统的协同输出调节问题,使得每个跟随器都能实现渐近跟踪和非奇异干扰抑制。 考虑一个具有N个智能体的离散时间含干扰的异构多智能体系统:
其中,、 和 分别为智能体i的状态、输入和外部干扰。 、 和 分别为状态、输入和 外部干扰的未知动态。
对于分布式一致性问题,定义每个智能体的局部跟踪误差,通过系统状态得到了智能体i的局部邻居跟踪误差的动力学表达式:
利用神经网络辨识器辨识多智能体系统的未知动力学。在系统辨识过程中,假设输入层和隐藏层之间的权重矩阵是常数,只需调整隐藏层和输出层之间的权重矩阵。因此,神经网络输出表示为:
为实现HDP算法,参考文献 中设计了一个actor-critic框架。对于每个智能体,构造critic神经网络来执行策略评估,并逼近最优值函数;构造actor逼近器来执行策略改进, 这些改进估计了最优控制和最坏情况下的扰动策略。如下所示:
actor 神经网络对控制输入的逼近误差可以定义为:
目标值函数 由式(57)给 出:
算法4未知动态图形游戏的actor-critic神经网络权重在线调整 步骤1:将actor和辨识器的权重值随机地初始化,将critic权重初始化为0; 步骤2:初始化所有智能体的初始状态, 为任意领导者;
在系统轨迹上,计算局部跟踪误差; 通过式(52)计算控制策略; 通过式(53)计算干扰策略; 通过式(51)计算估计状态; 使用估计状态计算局部跟踪误差; 通过式(54)计算值函数;
其中通过式(57)得到;
更新identifier权重:
步骤4:对于所有i,当时 ,停止迭代。
算法4的优点是将算法以actor-critic结构的形式实现,以逼近 actor 的最优值函数、最优控制和最坏情况下的干扰策略,解决了存在外部干扰的未知非线性约束输入系统的多智能体零和动态图形对策问题。该算法利用数据驱动的方式,不需要精确的系统模型。
3.3.2 连续含扰动多智能体系统
对于连续的多智能体系统,研究具有参数和动态不确定性的多智能体系统的协同输出调节问题。参考文献利用鲁棒自适应动态规划方法,通过在线输入和状态数据,设计了无模型的分布式控制器,利用循环增益定理保证闭环系统的渐近稳定性,从而解决了协同输出调节问题。每个跟随器都能实现渐近跟踪和非奇异干扰抑制。参考文献提出了一种新的数据驱动控制方案,通过鲁棒ADP实现一类部分线性多智能体系统的协同输出调节。不同于现有的多智能体系统无模型控制,参考文献首次尝试将鲁棒ADP、输出调节理论和循环小增益技术相结合。其次,与现有的鲁棒控制策略通常处理有界静态不确定性的方式不同,参考文献提出了一种新的数据驱动分布式控制方法,该方法能够处理表示为主体间耦合的动态不确定性。它严格保证了每个智能体在抑制非奇异干扰的同时能够实现渐近跟踪。 首先,考虑一类异构的多智能体系统:
考虑有外部干扰:
利用线性最优控制理论和输出调节理论,设计了分散最优控制器,之后建立鲁棒分布式控制器:
考虑到耦合多智能体系统与外部系统相关联,利用输出调节理论和循环小增益定理,设计了一种新型的分布式控制器。然后,在不依赖对象动力学知识的情况下,提出了一种基于鲁棒 ADP 的数据驱动控制方法。
其中, ,且:
步骤2:计算矩阵 ,在区间 上设置一个初始策略 ,其中勘探噪声为 ξ i ; 步骤4:求解和 ; 步骤5:令k=k+1,重复步骤4、步骤5,直到。令 k * =k,j=1 ; 步骤6:求解; 步骤7:令j= j+1,重复步骤6、步骤7,直到j=h i +2; 步骤8:求解,得到 ; 步骤9:令i=i+1,重复以上步骤,直到i=N+1。 算法5的优点在于利用鲁棒自适应动态规划方法,通过在线输入和状态数据,设计了无模型的分布式控制器,利用循环小增益定理保证闭环系统的渐近稳定性,从而解决了协同输出调节问题。
4.1 动态拓扑系统
在多智能体系统中,若智能体之间的信息交互是始终保持不变的,则称为固定拓扑。在实际应用中,还存在智能体间的信息交互是时变的情况,这种情况则被称为动态拓扑。具有动态拓扑的多智能体系统是多智能体系统一致性中需要考虑和研究的问题。与固定交互拓扑情况相比,由于每个智能体的邻居集是时变的,具有动态拓扑结构的多智能体系统的最优一致性问题会更加复杂。基于数据驱动的强化学习技术已经在具有固定拓扑的多智能体系统协同一致性问题上取得了众多研究成果以及有了深入的发展,如参考文献[77]研究了有向交换拓扑下离散时间异构多智能体系统的输出同步问题。然而,具有动态拓扑的多智能体系统的协同问题还需要进行深入的研究。因此,将基于数据驱动的强化学习算法扩展到研究动态拓扑结构的多智能体系统中是一个具有潜力和价值的研究方向。 4.2 提高算法的精度和速度
在数据驱动技术中利用actor和critic神经网络进行估计,需要考虑估计精度的问题,如何更好地提高神经网络的估计精度也是一个值得深入探索的研究方向。在多智能体协同问题的研究中,通过强化学习算法求解最优的控制策略的方法大多可以保证结果是严格收敛的,但在保证估计精度准确的同时无法保证收敛速度,在保证收敛速度的同时无法确保估计的准确性。如何同时提高收敛速度和收敛精度仍然是研究所面临的难题,也是未来的一个研究方向。 4.3 探索与开发权衡
强化学习面临的挑战之一是探索与开发(exploration and exploitation)之间的权衡。为了获得奖励,除了利用已知的信息,智能体也需要进行探索,以便在未来做出更好的行动选择。由于强化学习已经扩展到多智能体环境中,静态环境的假设通常不再成立。一个智能体必须适应其他智能体的不断变化。在这种情况下,出现了一种新的探索与开发权衡:一个智能体因为环境的变化而不断地探索,但是这种探索不应过度。在这样一个非平稳的环境中,智能体应该学习选择合适的时机进行探索:智能体学习可以更及时地适应不断变化的环境,同时在环境不变的情况下将探索保持在最小限度。以往的研究中,已提出了许多基于模型的强化学习算法用于克服探索和开发的权衡问题。这些算法都需要通过转移概率来构造模型,导致无法在线学习。因此如何利用强化学习算法在不需要环境模型的情况下解决探索和开发的权衡,是数据驱动技术未来可以发展研究的一个方向。
本文阐述了基于强化学习的数据驱动多智能体系统最优一致性问题的研究现状,分别从同构、异构和含扰动3类多智能体系统总结了通过数据驱动技术解决一致性问题的几种算法,表明了数据驱动技术对多智能体系统分布式最优一致性问题的重要作用,并分析了目前还需要优化的问题,总结了未来基于强化学习的数据驱动技术需要深入研究的方向。 作者简介 About authors
李金娜(1977- ),女,博士,辽宁石油化工大学信息与控制工程学院教授,博士生导师,主要研究方向为数据驱动控制、运行优化控制、强化学习、网络控制等。 程薇燃(1996-),女,辽宁石油化工大学信息与控制工程学院硕士生,主要研究方向为强化学习、多智能体控制、最优控制、数据驱动控制。
转载本文请联系原作者获取授权,同时请注明本文来自王晓科学网博客。 https://wap.sciencenet.cn/blog-951291-1276281.html
上一篇:
[转载]会议预告丨首届国际人工智能会议(CICAI 2021)将在杭州召开 下一篇:
[转载][CFP] 2021 IEEE数字孪生和平行智能国际会议征文开启!

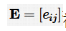 被称为连通矩阵,如果
被称为连通矩阵,如果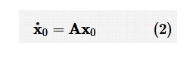
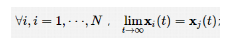 ;(b)最小化式(3)的性能指标。
;(b)最小化式(3)的性能指标。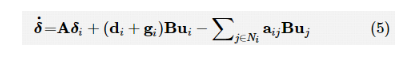
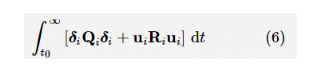
 ,并满足:
,并满足: 为最优值。博弈N元组的值
为最优值。博弈N元组的值 被称为N个智能体博弈的纳什均衡结果。达到一个纳什均衡,每个参与者的价值函数都能得到优化。在这种纳什均衡下,没有一个博弈者能够通过改变其输入策略来提高其绩效指标。
被称为N个智能体博弈的纳什均衡结果。达到一个纳什均衡,每个参与者的价值函数都能得到优化。在这种纳什均衡下,没有一个博弈者能够通过改变其输入策略来提高其绩效指标。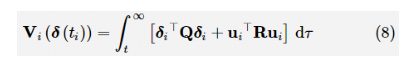

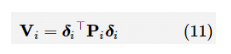
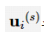 为目标策略。
为目标策略。
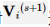 进行微分,通过式(14)得到:
进行微分,通过式(14)得到: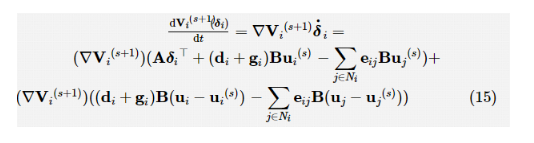


 为S的最小 p-copy 内部模型。定义系统的混合控制策略
为S的最小 p-copy 内部模型。定义系统的混合控制策略 和
和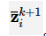 。由于积分强化学习的贝尔曼方程在一定的激励持续性条件下,这些解可以用最小二乘法唯一确定;
。由于积分强化学习的贝尔曼方程在一定的激励持续性条件下,这些解可以用最小二乘法唯一确定;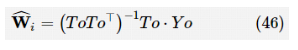
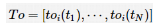 ,
,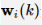 分别为智能体i的状态、输入和外部干扰。
分别为智能体i的状态、输入和外部干扰。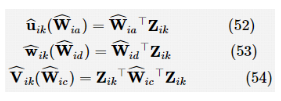
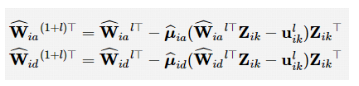

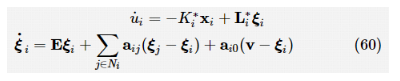
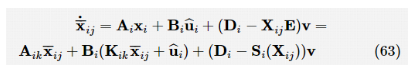
 。令k*=k,j=1;
。令k*=k,j=1;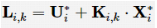 ;
;