博文
蹲守科学网的这五年——写在第100篇博客
 精选
精选
|||
我在科学网写博客有点像喻海良博主的感觉:休息与放松。但是,为了准备这篇博客,我整整花了5天时间去整理和分析。我在科学网的博客撰写属于中低产田,没有上千上万的博文数量,也很少写关于自己专业学术的东西,更很少码公式,多是自己的胡思乱想。学习R语言已经两年了,这次玩点深奥的,我借助R语言的爬虫算法(这5天都在码代码),将我这前99篇博文做了一个统计分析,也发现了一些有趣的规律,感觉还挺满意:
(1)我是科学网大大的良民
这是我在科学网上发表的前99篇博文的关键词,是从近26万字的博文中统计出来的出现频率最高的前1000个词汇,文字的尺寸越大,表明该词汇出现的频率越高。用一句话把这些词汇串起来的意思就是“中国的科研,论文与学生问题需要研究”,就是这么尿性,活脱一老实本分的科学网假正经,科学网欠我一个良民证。

(2)不高产,不温不火,少打嘴仗
我统计了一下我每篇博文的相关参数,平均每篇评论8.68次,每篇阅读4341.53次,每篇热度为7.82。文字总量约为26万字,五年写这么一点,算是比较少的。每篇的评论与推荐数不足10个,不温不火。嘴仗打的也比较少,严格遵循以理服人的原则。
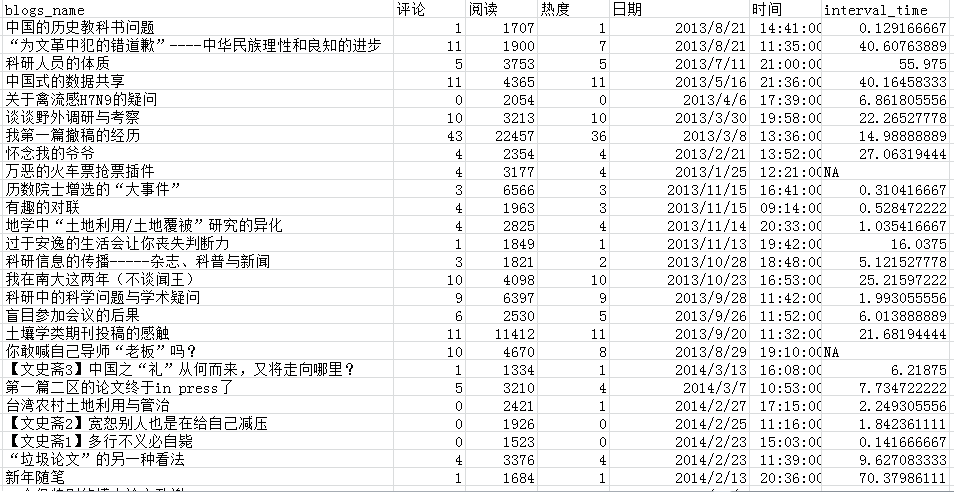
(3)内容广泛,发文时间不定,频率不高
博文内容主要是社会热点评述、历史启示录、诗词还有就是科研与论文。发文平均时间在14.82时,那就是在下午2-3点之间。平均发文间隔为17.4天,大约两周半发文一篇,这也太慢了,考虑提速。
回头我再爬一下谁给我的那些博文点赞的,我觉得我们可以成为好朋友!
@科学网编辑如果想分析一下科学网的博客,我乐意效劳
附代码:
library("xml2")
library("rvest")
library("dplyr")
library("stringr")
blogs_list <- data.frame()
name_list<-data.frame()
hits_list <- data.frame()
time_list <- data.frame()
for (i in 1:10){
web<- read_html(str_c("http://blog.sciencenet.cn/home.php?mod=space&uid=419327&do=blog&view=me&from=space&page=",i))
blogs_name<-web%>%html_nodes(".xs2 a+ a")%>%html_text()
a <- data.frame(blogs_name)
a[which(a$blogs_name==""),] <- NA
name_list<- na.omit(a)
blogs_hits<-web%>%html_nodes("dd.xg1")%>%html_text()
b <- data.frame(blogs_hits)
b[which(b$blogs_hits==""),] <- NA
hits_list <- na.omit(b)
blogs_time<-web%>%html_nodes(".xs2+ dd")%>%html_text()
c <- data.frame(blogs_time)
c[which(c$blogs_time==""),] <- NA
time_list <- na.omit(c)
z<-data.frame(name_list,hits_list,time_list)
blogs_list<-rbind(z,blogs_list)
}
x<- strsplit(as.character(blogs_list$blogs_hits),"\|")
blogs_list$评论 <- gsub("个评论", "",sapply(x,"[",2))
blogs_list$评论[blogs_list$评论=="没有评论"] <- 0
blogs_list$阅读 <- as.numeric(gsub("次阅读", "",sapply(x,"[",1)))#http://www.endmemo.com/program/R/gsub.php
y<- strsplit(as.character(blogs_list$blogs_time)," ")
blogs_list$热度 <- as.numeric(sapply(y,"[",2))
blogs_list$热度[which(is.na(blogs_list$热度))] <- 0
blogs_list$日期 <- as.Date(sapply(y,"[",3))
blogs_list$时间 <- gsub("rn", "",sapply(y,"[",4))
blogs_list$时间 <- gsub(Sys.Date(),"",strptime(blogs_list$时间, format ="%H:%M"))
blogs_list$日期[which(is.na(blogs_list$时间))] <- as.Date(gsub("rn","",as.character(blogs_list$blogs_time[which(is.na(blogs_list$时间))])))
blogs_list$时间[which(is.na(blogs_list$时间))] <-gsub("rn", "",sapply(y,"[",2))[which(is.na(blogs_list$时间))]
blogs_list$时间 <- strptime(blogs_list$时间,"%H:%M")
blogs_list$时间 <-gsub(Sys.Date(),"",blogs_list$时间)
blogs_list$public_time <- strptime(paste(blogs_list$日期,blogs_list$时间),format = "%Y-%m-%d %H:%M")
blogs_list$interval_time1 <- strptime(c(blogs_list$public_time[-1],NA),format = "%Y-%m-%d %H:%M")
blogs_list$interval_time<- difftime(blogs_list$public_time,blogs_list$interval_time1,units = "days")
blogs_list$interval_time[blogs_list$interval_time<0] <- NA
blogs_list$具体时间 <- as.numeric(substr(blogs_list$时间,1,3))
mean(as.numeric(blogs_list$热度))
mean(as.numeric(blogs_list$评论))
mean(as.numeric(blogs_list$具体时间))
mean(as.numeric(blogs_list$interval_time),na.rm = T)
write.csv(blogs_list[,c(1,4:8,10)],file="D:\学习\blogs_list.csv")
lj <- read.table("E:\H\R\博客链接.txt",header = F,sep = "")
dlist <- sapply(lj[13:dim(lj)[1],], function(x) substr(x,39,44))
dlist1<- sapply(lj[1:12,], function(x) substr(x,39,45))
x <- data.frame(dlist1)
y <- data.frame(dlist)
colnames(y)[1] <- "dlist1"
m <- rbind(x,y)
m <- as.numeric(levels(m$dlist1)[m$dlist1])
m
library(rvest)
n <- data.frame()
for(l in m){
p <- read_html(paste0("http://blog.sciencenet.cn/blog-419327-",l,".html"))
blogs_text<-p%>%html_nodes("#blog_article , #blog_article span")%>%html_text()
v <- data.frame(blogs_text)
n <- rbind(n,v)
}
n
t <- as.character()
for(i in 1:dim(n)[1]){
t <- paste(t,n[i,])
}
write.table(t,"E:\H\R\blogs.txt")
library(jiebaR)
library(wordcloud2)
f <- scan('E:\H\R\blogs.txt',sep='',what='')
f <- f[3]
myword <- worker()
new_user_word(myword,
scan("E:\H\R\我的分词.txt",what="",sep=" "))
seg <- segment(f,myword)
engine_s<-worker(stop_word ="E:\H\R\stop_word.txt", encoding = "UTF-8")
seg <- segment(seg,engine_s)
seg <- seg[nchar(seg)>1]
seg <- table(seg)
length(seg)
seg <- sort(seg, decreasing = TRUE)[1:1000]
seg
library(wordcloud2)
library(htmlwidgets)
windowsFonts(myFont=windowsFont("微软雅黑"))
#pdf("D:\学习\my_cloud.pdf", width = 500, height = 500)
#opar <- par(no.readonly = T)
mydata <- data.frame(names(seg),as.numeric(seg))
wordcloud2(mydata, size = 1,shape='star') ##?family="myFont"
a <- wordcloud2(mydata, size = 1,shape='star')
htmlwidgets::saveWidget(a, file ="D:\学习\my_cloud.html",selfcontained = FALSE)
#par(opar)
#dev.off()
https://wap.sciencenet.cn/blog-419327-1069553.html
上一篇:好山好水好寂寞
下一篇:建议国家设立公共卫生与安全频道
全部作者的精选博文
- • 硬扛
- • 寒假
- • 老郑的诗和远方
- • 一瓶黄桃罐头
- • 年终总结(2023)
- • 探访塔吉克斯坦(二)