博文
生活是科学(36):图灵奖是否给了欺诈?
||
In addition to plagiarism in the last episode, here is yet another worse problem with the latest Turing Award 2018: Fraud. I raise this example publicly here so that we can conduct a fruitful academic discussion. By conducting the discussion, we are exercising our basic rights for freedom of speech as well as academic freedom.
除了上一集的剽窃之外,最近的2018年图灵奖还存在另一个更严重的问题:欺诈。我在这里公开提出这个事件,以便我们进行富有成果的学术讨论。通过进行讨论,我们正在行使着言论自由和学术自由的基本权利。
Under William-Webster online dictionary, the definition of fraud is “intentional perversion of truth in order to induce another to part with something of value or to surrender a legal right”.
在William-Webster在线词典中,欺诈的定义是“故意歪曲真相,以诱使他人放弃某些有价值的东西或放弃合法权利”。
U.S. Federal Criminal Code, Title 18, Code § 1341. Frauds and swindles reads, “Whoever, having devised or intending to devise any scheme or artifice to defraud, or for obtaining money or property by means of false or fraudulent pretenses, representations, or promises …”
美国联邦刑法典,第18条,第§1341欺诈和诈骗款写道:“无论是谁设计或打算设计任何欺诈手段,或通过虚假或欺诈性的借口,陈述或承诺的手段以获取金钱或财产……”
Did Turing Awards 2018 go to fraud? Has the work of Turing Prize 2018 violated the Code of Ethics and Professional Conduct (CEPC) of the granting organization ACM? ACM CEPC code stipulates: “1.3: Making deliberately false or misleading claims, fabricating or falsifying data, …, and other dishonest conduct are violations of the Code.”
2018年图灵奖是否给了欺诈?2018年图灵奖的工作是否违反了授予组织ACM的《道德与职业行为准则》(CEPC)?ACM CEPC准则规定:“ 1.3:故意做出虚假或误导性主张,捏造或伪造数据……以及其他不诚实行为,均违反了此准则。”
I invite the reader to judge by himself, and provide his comments on my Facebook page, whether the ACM Turing Award 2018 went to fraud. This episode has three claims, Falsification of Data, making misleading claims, and fraud, respectively. As plagiarism in the last episode is Claim 1, let us number these three Claims by 2, 3 and 4, respectively.
我邀请读者自己判断,并在我的Facebook页面上发表评论,ACM 2018年Turi图灵奖是否涉及欺诈。这一集有三个主张,分别是:数据造假,误导性声明和欺诈。由于上一集中的抄袭对应了主张1,我们将这三个主张分别编号为主张2、3和4。
As the problems involve not only Turing Award 2018, but also the prize money provider Alphabet/Google, let me name the respondents explicitly below:
由于问题不仅涉及2018年的图灵奖,还涉及奖金提供者Alphabet/谷歌公司,因此让我在下面明确指定被告:
Respondents:Geoffrey Hinton, Yann LeCun, Yoshua Bengio, and Alphabet/Google.
被告: Geoffrey Hinton, Yann LeCun,Yoshua Bengio和Alphabet/谷歌公司。
Claim 2: Falsification of Data
主张2:数据造假
Violations of CEPC 1.3: “… Making deliberately false or misleading claims, fabricating or falsifying data, …”
违反CEPC 1.3:“ ...... 故意做出虚假或误导性主张,捏造或伪造数据...... ”
Claim 2 on Alphabet/Google mounts to unfair methods of competition that are unlawful per 15 U.S. Code § 45 (a) (1): “Unfair methods of competition … affecting commerce, and unfair or deceptive acts or practices … affecting commerce, are hereby declared unlawful.”
主张2根据15美国法典§45(a)(1),Alphabet / 谷歌采用不公平竞争手法是属非法的:“不公平竞争手法......影响商业,以及不公平或欺骗性行为或做法......影响商业,特此宣布为非法。”
In the Turing Award announcement of ACM, under “Select Technical Accomplishments,”
ACM的图灵奖公告中,在“优选技术成就”题目下的,
- all three “accomplishments” of Hinton (backpropagation, Boltzmann Machines, Improvements to CNN),
- Hinton的所有三个“成就”(反向传播,玻尔兹曼机,对CNN的改进),
- all the three “accomplishments” of Bengio (probabilistic models of sequences using neural networks, high-dimensional word embeddings and attention, generative adversarial networks) and
- Bengio的所有三个“成就”(使用神经网络的序列概率模型,高维词嵌入和注意,生成对抗网络)以及
- all the three “accomplishments” of LeCun (CNN, improving backpropagation, broadening the vision of neural networks) have violated CEPC 1.3.
- LeCun的所有三个“成就”(CNN,改进了反向传播,拓宽神经网络的视野)都违反了CEPC 1.3
Why? The Respondents used training data sets as testing data sets, explained below. This behavior amounts to deliberately false claims, misleading claims, fabricating reported data, and falsifying performance data. See above CEPC 1.3 statements.
为什么?如下所述,被告将训练数据集用作测试数据集。这种行为意味着故意做虚假声明,误导性声明,假造报告数据以及伪造性能数据。参见上文CEPC 1.3声明。
What does the Claimant mean by “using training sets as testing sets”?
原告“用训练集作为测试集”是什么意思?
The only major technical difference between Cresceptron in [P1] to [P3]
Cresceptron [P1]到[P3]
[P1] J. Weng, N. Ahuja and T. S. Huang, “Cresceptron: a self-organizing neural network which grows adaptively,” in Proc.Int'l Joint Conference on Neural Networks, Baltimore, Maryland, vol. 1, pp. 576-581, June 1992.
[P2] J. Weng, N. Ahuja and T. S. Huang, “Learning recognition and segmentation of 3-D objects from 2-D images,” in Proc. 4th International Conf. Computer Vision (ICCV), Berlin, Germany, pp. 121-128, May 1993.
[P3] J. Weng, N. Ahuja and T. S. Huang, “Learning recognition and segmentation using the Cresceptron,” International Journal of Computer Vision (IJCV), vol. 25, no. 2, pp. 105-139, Nov. 1997.
and the Respondents’ work [P4] to [P6]
与被告[P4] 到[P6]
[P4] A. Krizhevsky, I. Sutskever and G. Hinton, ImageNet Classification with Deep Convolutional Neural Networks, Advances in Neural Information Processing 25, pp. 1106-1114, 2012, MIT Press, Cambridge, MA.
[P5] Y. LeCun and L. Bengio and G. Hinton, Deep Learning, Nature, vol. 521, pp. 436-444, 2015.
[P6] Y. LeCun, L. Bottou, and Y. Bengio, and P. Haffner, Gradient-Based Learning Applied to Document Recognition, Proc. of the IEEE, vol. 86, no. 11, Nov. 1998.
和被告的其它工作之间的唯一主要技术差异是:
and others from the Respondents was the following: Cresceptron uses unsupervised Hebbian learning (with position blurring) which (similar to multi-level nearest neighbor from samples) does not have the well-known local minima problem. But the Respondents used error backpropagation based on “gradient descent” which only reaches a local minimum. The local minimum is not in a low-dimensional space, but in an extremely high-dimensional space. The fraudulent “solution” that was reported by the Respondents is in fact found by implicitly using the test set as a training set, called post-selectionbelow:
Cresceptron使用无监督的Hebbian学习(具有位置模糊),该学习(类似于样本中的多级最近邻居)没有众所周知的局部最小值问题,但是被告使用基于“梯度下降”的误差反向传播,到达局部最小值点。这局部最小值点不是在低维空间中,而是在极高维空间中。实际上,通过隐避地将测试集用作训练集(以下称为“后选择”)来找出被告所报告的以下欺诈性“答案”:
The Respondents tried many networks each was initialized with a random set of weights, corresponding to a random starting position in a hilly terrain, and each reached a local-minimum. Among many local-minimum networks, the Respondents picked (post-selection) a luckiest network whose error happened to be the smallest using the test set. Namely, the training stage consists of two substages, (1) finding local minima for many networks and (2) select the network with smallest error using the training set among the many networks. Namely, the test set was explicitly used in the second substage of the training stage. This corresponds to using the test set as a training set, although used in a way different from the training set. However, such a luckiest network does not do well for new and unobserved data. If a validation set is used (e.g., in ImageNet Contest), the validation set is used for finding local minima. The same fraud still exists because the post-selection still uses the test set.
被告尝试了许多网络,每个网络都使用一组随机的权重进行初始化,每个网路对应于丘陵地形中的一个随机起始位置,并且每个网络都达到了局部最小值点。从许多局部最小网络中,被告选择(后选择)那个最幸运的网络,其误差碰巧是用测试集检测为最小的。即,训练阶段包括了两个子阶段,(1)为许多网络找到局部最小值点,(2)使用训练集从许多网络中选出误差最小的网络。即,在训练阶段的第二子阶段中确切使用了测试集。这对应了将测试集用作训练集,尽管与训练集的使用方法不同。但是,这个最幸运的网络对于新的和未观察到的数据而言效果不佳。如果使用了验证集(例如在ImageNet竞赛中),验证集只是用来找局部最小值点。 由于后选择还是用测试集,因此仍然存在着相同的欺诈行为。
See Life is Science (10) and (15) on Claimant’s Facebook 2017 for further discussion on other types of data falsification in the construction of ImageNet data sets themselves.
有关在ImageNet数据集建立过程中其他类型的数据造假的进一步讨论,请参见y原告在脸书2017上的生活是科学第10集和第15集。
How did Li Fei-Fei and others hand picked images? There have been no published information about the manual selection of the ImageNet data set because of the lack of transparency. However, we can know her behaviors from the paper, Li Fei-Fei, Rob Fergus, and Pie Perona, Learning generative visual models from few training examples: an incremental Bayesian approach tested on 101 object categories. IEEE Computer Vision and Pattern Recognition (CVPR), Workshop on Generative-Model Based Vision. 2004. I quote from section III.A, line 8 of that paper:“Two graduate students not associated with the experiment then sorted through each category, mostly getting rid of irrelevant images (e.g. a zebra-patterned shirt for the zebra category).”
李飞飞和其他人如何手工挑选图像?由于缺乏透明度,尚未发布有关手动选择ImageNet数据集的信息。但是我们可以从Li Fei-Fei,Rob Fergus和Pietro Perona的论文(Learning generative visual models from few training examples: an incremental Bayesian approach tested on 101 object categories. IEEE Computer Vision and Pattern Recognition (CVPR), Workshop on Generative-Model Based Vision. 2004) 得知她的行为。我引用这篇文章的第III.A节第8行:“与此实验无关的两名研究生对每个类别进行了筛选,主要是丢弃了不相关的图像(例如,斑马图案衬衫因为已有了斑马类)。”
Below, to facilitate citation, my evidence items are coded by claim number first, followed by the index of each evidence.
下面,为了方便引用,我的证据项首先按主张编号,然后按每个证据编号。
Evidence 2.1: Local minima in gradient descent. Error backprogation follows a well-known mathematical technique, called gradient descent; it is a solution-search method which finds a local height minimum on a high-dimensional hilly terrain. The dimensionality of the terrain world for a neural network is the number of network weights, which is much larger than the number 3 is our 3D world. The height of the terrain corresponds to the estimated cost of the current searched point as a candidate solution. Gradient descent means wherever the search point is now, the search steps down in the direction where the slope is steepest. The height of the terrain is estimated from the training data set (validation set). Intuitively, this way finds only a locally minimum solution in the estimated cost because a local valley typically does not contain the global minimum of the estimated cost on the entire hilly terrain. Even if you use many networks, each of which starts from a random starting point, the lowest-local-minimum network among all these networks is not necessarily the true minimum of the test set becausethe height is an estimated height from only the training data set (training set and validation set).
证据2.1:梯度下降中的局部最小值点。误差反向传播遵循一种众所周知的数学技术,称为梯度下降。它是一种搜索解的方法,以求在高维丘陵地形上找到高度的局部最小值点。神经网络的地形世界的维数是网络权重的数量,比3D世界的数量大得多。丘陵地形的高度对应于当前搜索点作为候选解的估计成本。梯度下降法意味着无论现在的搜索点在哪里,搜索都将沿着坡度最陡的方向继续找。高度是根据训练数据集(验证集)估算的。直观上,这种方法只能找到估计成本中的局部最小值解,因为局部山谷通常不包含整个丘陵地形上估计成本的全局最小值。即使你使用许多网络,每个网络都从一个随机的起点开始,所有这些网络中最低的局部最小网络也不一定是测试集的真正最小值网络,因为其高度仅是根据训练数据(训练集和验证集)得出的估计高度。
Evidence 2.2: The terrain of the test data set is at least considerably different from that of the training data set. This is especially true for AI problems, because a learning system must generalize from a training data set and be tested on an unknown testing sets. Using the testing sets to select a solution from many (network) solutions is a pure cheating. The Claimant does not mean that the gradient decent method itself is a cheating, but the use of a testing sets during post-selection as a way to find a solution (network) is a cheating.
证据2.2:训练集(训练数据和验证数据)的丘陵地形和测试集的丘陵地形不同。测试数据集的地形与训练数据集的地形至少大不相同。对于AI问题尤其如此,因为学习系统必须从训练数据集中进行概括,并在未知的测试集中进行测试。使用测试集从许多网络中选择一个网络是一种纯粹的欺骗。并原告不意味着梯度下降方法本身就是欺诈,但是在后选择过程中使用测试集选个解(网络)的方法就是欺诈。
Evidence 2.3: The curse of dimensionality. Furthermore, there is an even severe issue in AI problems, known as "the curse of dimensionality". Here is a classical example for an AI professor who teaches the number of local minima in a high dimensional space:
Suppose each dimension as only 10 local minima.
Then a 2-parameter space has 102local minima.
A 3-parameter space has 103local minima.
...
A 14-parameter space has 1014local minima.
Stop! 1014 is already roughly the number of neurons in the human brain!
However, the number of parameters in the vision networks of Respondents is not 14, but instead several millions at least. That is the main reason why the Respondents must try a huge number of randomly initialized local-minima-networks to find a lucky network.
证据2.3:维数的诅咒。此外,在AI问题中存在一个更严重的问题,即“维数的诅咒”。这是一位AI教授的经典示例,他教高维空间中的局部极小值点:
假设每个维度只有10个局部最小值点。
然后,一个2维空间具有102个局部最小值点。
一个3维空间具有103个局部最小值点。
...
一个14维空间具有1014个局部最小值。
停止!1014已经是人脑中神经元的数目了!
但是,被告的视觉网络中的参数数不是14,而是至少数百万。这就是为什么被告必须尝试大量随机初始化的局部最小网络来找到一个幸运网络的主要原因。
Evidence 2.4: The slide with the title “backpropagation algorithm” in Hinton’s June 23, 2019 Award talk, did not reveal a huge number of random networks must be used for the “backpropagation algorithm”. During his next slide titled “How to learn many layers of features” at the same talk, Hinton made a false or misleading claim: “statistical gradient descent, even though it has no real rights to work, actually works very well.” He purposefully did not mention the post-selection using test data.
证据2.4:在2019年6月23日的颁奖演讲上,Hinton的标题为“反向传播算法”的幻灯片没有暴露“反向传播算法”必须用大量随机网络。在相同演讲的下一张题为“如何学习多层功能”的幻灯片中Hinton提出了一个虚假或误导性的主张:“统计梯度下降,即使它没有做好的真正权利,实际上做得非常好。”他故意没有提及使用测试集做后选择。
The primary reason the “backpropagation algorithm” showed a small superficial error was because a huge number of random networks must be tried and all were discarded except the one which was reported. When selecting the best network, the testing data set was used as a training data set; this methodology is simply misleading and ethically wrong.
“反向传播算法”给出表面较小的误差的主要原因是因为必须尝试大量随机网络,并且除了报告的网络之外,所有其他尝试了的网络都被抛弃。选择最佳网络时,将测试数据集用作训练数据集;这种方法简直是误导,在伦理上是错误的。
Evidence 2.5: Using the test set of MNIST data as training set, Dr. LeCun used a huge number of networks to find a smallest error through as many as 22 variations of CNN networks, from 10000*1.7%=170 errors down to 1000*0.53%=53 errors. LeCun reported 23 errors by Juergen Schmidhuber in CVPR 2012 which suffer from the same data falsification problem using LSTM.
证据2.5:LeCun博士使用MNIST数据的测试集作为训练集,使用大量网络通过多达22种CNN网络变体找最小的错误点(从10000 * 1.7%= 170错误降至1000 *0.53%= 53个错误。)LeCun报告了Juergen Schmidhuber在CVPR 2012中报告的23个错误,这些使用LSTM的工作有着相同的数据造假问题。
However, Chris Adami and his postdoc David Knoester at the BEACON Center of MSU has reached only 7 errors on the same test set, over 3 times of reduction from the LeCun-reported lowest 23! See http://yann.lecun.com/exdb/mnist/index.html
然而,Chris Adami和他的MSU BEACON中心的博士后David Knoester在同一测试集上仅发生了7个错误,比LeCun报告的最低23个错误小3倍!参见http://yann.lecun.com/exdb/mnist/index.html
The more degrees of freedom one has in the parameters of his networks, the smaller the superficial error he can find, of course, using the test set as a training set as long as one can screen many random networks! Anyone who fully understands what was truly going on will not be surprised if somebody else comes up with a network which reaches a zero error by using the MNIST test set as a training set.
一个网络的参数中拥有的自由度越多,你发现的表面误差就越小,当然,只要可以将测试集用作训练集用于筛选许多随机网络!如果有人通过使用测试集作为训练在MNIST集上报告有个网络达到零错误,任何完全了解真相的人都不会感到惊讶。
Can such a lucky-network-out-of-many be applied well to new data? Of course not. Therefore, Dr. LeCun’s methodology is technically wrong.
这样的幸运网络能很好地应用到新数据吗?当然不能。因此,LeCun博士的方法在技术上是错误的。
Evidence 2.6: The Claimant and his students have demonstrated this well-known but rarely reported CNN phenomenon. See, for example,
证据2.6:原告和他的学生已经证明了这一众所周知但很少报道的CNN现象。例如,参见:
[P7] Z. Zheng and J. Weng, “Mobile Device Based Outdoor Navigation With On-line Learning Neural Network: a Comparison with Convolutional Neural Network,” in Proc. 7th Workshop on Computer Vision in Vehicle Technology (CVVT 2016) at CVPR 2016, Las Vegas, pp. 11-18, June 26, 2016.
A large number of random CNNs networks were necessary to find a lucky CNN trained with error backpropagation, but this “finding” stage uses the test set. Namely, the testing set was used as a training set for CNN.
要经过误差反向传播训练找到幸运的CNN,必须使用大量随机CNN网络,但是此“查找”阶段使用了测试集。即,将测试集用作CNN的训练集。
In contrast, much-advanced after Cresceptron, a very different kind of neural networks called Developmental Networks (DN), needs onlyone network to reach the statistically optimal network (in the sense of maximum likelihood) in onlyone epoch through onlythe training set! This property was mathematically proved by Weng 2015 [P8] and included also in Weng’s book [P9] (Theorems 6.1-6.3).
相比之下, Cresceptron之后进步了很多的一种称为发育网(DN)的神经网络只需一个网络经过训练集一次就可以达到统计上最优的网络(最大似然估计)!该性质已在Weng 2015 [P8]中得到数学证明,并且也包含在Weng的书[P9]中(定理6.1-6.3)。
[P8] J. Weng, “Brain as an Emergent Finite Automaton: A Theory and Three Theorems.” International Journal of Intelligence Science, vol. 5, no. 2, pp. 112-131, January 2015.
[P9] J. Weng, Natural and Artificial Intelligence: Introduction to Computational Brain-Mind, BMI Press, Second Edition, ISBN: 978-0-9858757-1-8, pp. 465, 2019.
In other words, whatever random weights a DN uses, all random weights are performance-equivalent in the resulting DN network! Intuitively, inside DN, at each time, the random initial weighs only affect which neuron to be the winner in competition, but every winner neuron does the same thing.
换句话说,无论DN使用什么随机权重,在生成的DN网络中,所有随机权重在性能上都是相同的!直观地讲,在DN的内部,随机初始权重仅影响哪个神经元成为竞争的赢家,但是每个赢家神经元都做同样的事情。
Experimentally, see [P10], Fig. 7(1) and (b). A lack of clear logic inside all neural networks trained with gradient descent (i.e., black box) is the most basic reason for such a stark contrast between a CNN and a DN, shown in Fig. 7 of [P10].
实验上,请参见[P10],图7(1)和(b)。在CNN和DN之间形成[P10]的图7显示的如此鲜明对比的最基本原因是,所有经过梯度下降训练的神经网络内部缺乏清晰的逻辑。
[P10] Z. Zheng and J. Weng, “Mobile Device Based Outdoor Navigation With On-line Learning Neural Network: a Comparison with Convolutional Neural Network,” in Proc. 7th Workshop on Computer Vision in Vehicle Technology (CVVT 2016) at CVPR 2016, Las Vega, pp. 11-18, June 26, 2016.
Evidence 2.7: Use of a validation set does not change the nature of the falsification problems because the validation set is often very similar to the test set. Apparently most papers of machine learning do not use a validation data set. Because the ground truth is available to the authors (e.g., like during ImageNet Contest), they can report only the lucky network which has the minimum error on the ground truth even if they use a validation set!
证据2.7:使用验证集不会改变数据造假的性质,因为验证集通常与测试集非常相似。显然,大多数机器学习论文都不使用验证数据集。因为作者可以使用正确解(例如,在ImageNet竞赛中),所以即使他们使用验证集,他们也只需要报告在正确解上具有最小错误的幸运网络!
Similarly, human tampering into the network internal structure and parameters (such as LSTM) is like a human chess player with computer assistance.
同样地,人工篡改网络内部的结构和参数(例如LSTM)就像在计算机辅助下的国际象棋参赛人。
A well-known step in pattern recognition called cross validation should be used, although it only alleviates the bias between a training set and a validation set. The cross-validation only switches the role between the training set and the testing set but does not eliminate the falsification of both data sets themselves such as in the ImageNet Contest. Unfortunately, the performance reporting method of the ImageNet Contest does not even use the well known cross-validation. Therefore, not only both data sets of ImageNet were falsified (recall the above example of “zebra” and “stripe shirts”), the manual partition between the training set and the test set is also biased (i.e., absence of cross validation).
应该使用模式识别中一个众所周知的步骤,称为交叉验证,尽管它只能减轻训练集和验证集之间的偏心。交叉验证仅在训练集和测试集之间切换角色,而不能消除两个数据集本身的造假,例如在ImageNet竞赛中。不幸的是,ImageNet竞赛的性能报告方法甚至连众所周知的交叉验证都没有用。因此,不仅两个ImageNet数据集都被伪造(回忆“斑马”和“条纹衬衫”的以上例子),而且训练集和测试集之间的手动划分也存在偏心(即没有交叉验证)。
In contrast, with DN, each network “life” must be trained, tested, and reported, throughout its “lifetime”. Yet, each network “life” is optimal for its “life experience”.
相反,使用DN,每个网络“生命”必须在其整个“生命期”进行训练、测试和报告。而且,每个网络“生命””都是其“生活经验”的最佳选择。
Evidence 2.8: July 10, 2012 ImageNet Test images (ground truth) were released. The training set contains validation data sets. The deadline for submission was September 30, 2012. Namely, the ground truth was available to all the contestants for an extended period, 70 days, leaving the teams sufficient time if some teams decided to assign team members to hand-label test sets. The Claimant does not yet have direct evidence of how many ImageNet teams actually hand-labeled the test sets, but it is not sufficiently responsible for the ImageNet organizers to manage the tests this way.
证据2.8:2012年7月10发布了ImageNet测试图像(正确解)。训练集包含了验证数据集。提交截止日期为2012年9月30日。也就是说,为团队留出足够的时间使所有参赛团队都可以在70天的较长时间内获得正确解,如果他们决定将分配团队成员对测试集做手工标记。原告还没有直接证据表明有多少ImageNet参赛团队为测试集做了手工标记,但是ImageNet组织者以这种方式管理测试是不够负责任的。
Evidence 2.9: All published papers from Google/Alphabet, which use networks trained with gradient descent, appear to have the same problem of using test sets as training sets. Readers have noticed each of Google/Alphabet papers have many authors. For example,
V. Mnih et al. in Naturevol. 518 Feb. 26, 2015 had as many as 20 authors;
A. Graves, et al. in Nature, vol. 538 Oct. 27, 2016 had also 20 authors;
M. Moravcik et al. in Sciencevol. 356, May 5, 2017 had 10 authors;
S. McKinney et al. in Naturevol. 577, Jan. 2, 2020 had 31 authors.
Of course, such a large number of humans were necessary for each task to hand-tune various configurations of architectures generating a huge number of random and hand-turned networks. Such a huge scale of hand-tuning and a huge number of random networks for each hand-tuned configuration are indeed necessary for a small luck during the post-selection stage, as I explained above.
证据2.9:Google/Alphabe的所有使用梯度下降训练网络的已经发表了的论文,似乎都存在使用测试集作为训练集的问题。读者们注意到了,每篇Google/Alphabet论文都有很多作者。例如,
1. V. Mnih等。在Nature第518卷,2015年2月26日,共有20位作者;
2. A. Graves等。在Nature第538卷, 2016年10月27日,也有20位作者;
3. M. Moravcik等。在Science第356卷,2017年5月5日有10位作者;
4. S. McKinney等。在在Nature第577卷,2020年1月2日,共有31位作者。
当然,为了每个任务,如此大量的人工对于手工调试各种架构组成是必需的。为了我以上解释过的后选择阶段的小运气,确实需要如此大量的手工调试和为每个手工调试架构都产生的大量的随机网络。
A. Graves, et al. 2016, above, partially admitted such a huge-scale search and picking based on test data (see, e.g., the last paragraph of left column, page 473 and Figure 5).
But such a lucky network cannot be applied well to open data.
上面的A. Graves等2016年文章部分地承任了基于测试数据的如此大规模的搜索和选择(例如,参见第473页左栏的最后一段和图5)。但是,这样的幸运网络无法很好地应用于开放数据。
S. McKinney et al. 2020 above wrote: “We report results on test sets that were not used to train or tune the AI system” (3rdparagraph, left column, page 90), but this statement does not rule out a post-selection using test sets. A post-selection is different from the term “tune”.
以上S.McKinney等2020年文章写道:“我们报告测试集的结果。测试集未用于训练或调试AI系统”(第90页,左栏,第3段),但此声明并不排除基于测试集的后选择。后选择与术语“调试”是不相同的。
All these Google networks are basically human intelligence by spending labor of many humans who are assisted by machines, over-working on a static and closed data set, and through unethical research misconduct.
所有这些Google网络基本上都是人类的智慧,他们花费许多人的劳动,这些人在机器的协助下工作,过度地处理静态和封闭的数据集以及通过研究不端行为。
Apparently, Google’s top-level management probably has not been sufficiently well informed by its machine learning employees, till somebody reported to Larry Page and Brin Sergey early October 2019. This situation is sad because its huge investment in machine learning since 2013, much of the investment is from American public. Only when the test source was open, could the Google’s top-level management be partially exposed to a fraction of the problem (such as the reasons why Anthony Levandowski quit from the Google’s self-driving car project that he headed and the related later disputes). Google’s top-level management should undergo a thorough internal investigation to protect public investment into Google/Alphabet before the U.S. Federal government investigations commence.
显然,谷歌的高层管理人员好像没有充分地从搞机器学习的员工们了解到真相,直到2019年10月初有人向Larry Page和Brin Sergey 揭露。这种情况都是令人遗憾的,因为谷歌自2013年以来其在机器学习方面做了巨额投资, 其投资的大部分来自美国公众。 只有当测试源开放时,谷歌的高层管理人员才能部分地看到一些问题(例如为什么Anthony Levandowski退出了他领导的谷歌自动驾驶汽车项目的以及以后的争议)。 谷歌的高层管理人员应该在美国联邦局展开调查之前进行彻底的内部调查,以保护公众对谷歌/Alphbet的投资。
Evidence 2.10: Possible human intervention behind Google competition scenes, not fully machine competitions. According to the Claimant’s knowledge about the limitations of CNN trained with gradient descent, apart from the post-selection problem, all computer game results from Google seem to have an additional major problem. When their Google networks played with an expert human player, the Google’s human developers needed to interact with their Google networks (e.g., AlphaGo) behind the scene. This is like one human player playing with a team of Google human players. The one human player does not have any computer assistance but the Google player team does have extensive computer assistance. This is unfair and considered cheating by any fair game rules. Garry Kasparov complained the same when he played with IBM Deep Blue.
证据2.10:谷歌竞赛幕后可能有人为干预,而不是完全的机器竞赛。根据原告对使用梯度下降训练的CNN的局限性的知识,除了后选择问题,谷歌提供的所有计算机游戏结果似乎还存在另一个主要问题。当他们的谷歌网络与人类专家一起玩时,谷歌的开发人员需要在幕后与谷歌网络(例如AlphaGo)进行互动。这就如同一名人类玩家对阵一组谷歌人类玩家。这名人类玩家没有任何计算机的协助,但谷歌人类玩家确有雄厚的计算机协助。这是不公平的,并且根据任何公平的游戏规则都被视为作弊。加里·卡斯帕罗夫(Garry Kasparov)在对阵IBM Deep Blue时也提出过同样的抱怨。
The Complainant does not yet submit direct evidence about what actually happened behind the scenes of the Google computer game competitions, but he presented an educated guess based on his insights on limitations of CNNs.
原告还没有呈现直接证据证明谷歌计算机游戏竞赛的幕后实际发生了什么,但是基于对CNN局限性的洞察,他提出了有根据的推测。
Evidence 2.11: June 23, 2019, in Yann LeCun’s 2018 ACM A. M. Turing Lecture, from his slide titled “The Salvation?” up to the final slide, LeCun continuously used a piecemeal approach which falsifies or misleads. By piecemeal, the Complaint means that his network has multiple pieces. During these slides, LeCun continued to hide the hand-selection process which uses test data sets as training data sets for each of his pieces. His slide titled “Theory often Follows Invention” makes excuses for the “lack of theory” or the “black box” nature of his networks. This slide has demonstrated that, apparently, the three Respondents as neural network researchers were not aware of, or ignored, the new trend-setting capability of “Auto-Programming for General Purposes” (APFGP) of DN from the Claimant and his students. APFGP has put traditional computer science that is based on Universal Turing Machines under the new light of Emergent Universal Turing Machines that model human brains.
证据2.11:2019年6月23日,在Yann LeCun的2018年ACM A. M. Turing演讲中,从他的幻灯片“The Salvation救赎?”一直到最后一张幻灯片,LeCun连续采用零碎的方法来伪造或误导。这里零碎的意思是,被告的网络有多个部分。在这些幻灯片中,LeCun继续隐瞒手工后选择过程,该过程使用测试数据集作为他每个部分的训练数据集。他在标题为“理论经常跟随发明”幻灯片里,为其网络的“缺乏理论”或“黑匣子”性质找借口。这张幻灯片表明,显然,作为神经网络研究人员的三名被告没有读到到或忽略了原告和他的学生们提供的DN的“通用自主编程”(APFGP)的引领新趋势的新功能。APFGP将基于通用图灵机的传统计算机科学置于模拟人脑的涌现通用图灵机的新视野之下。
The Claimant requests that ACM facilitates such badly needed and long-overdue academic communications in computer science so that its due-paying ACM members receive long over-due service.
原告要求ACM促进计算机科学中这种急需和长期逾期了的学术通信,为付款ACM会员们提供已经长期逾期了的正当服务。
Evidence 2.12: The Respondents failure to admit and discuss the post-selection practice even after the respondents got aware from their research ethics committees that their post-selection practice was raised and questioned. For example, in a recent April 17, 2020 publication, T. P. Lillicrap, A. Santoro, L. Marris, C. J. Akerman and G. Hinton, Backpropagation and the brain, Nature Reviews Neuroscience, https://doi.org/10.1038/s41583-020-0277-3 the authors continued to hide the post-selection practice in their methods. Furthermore, Hinton seemed to lack a minimal carefulness knowing that such a review article was probably not rigorously reviewed. For example, in Fig. 4, the so called “(3) backprogating action potentials” transits along the upward arrow from the “(1) Feedforwardcompartment” to the “(2) Feedback compartment”. If Hinton was so grossly careless technically on such a visually extremely obvious error (probably drafted by somebody else) in his publication, how can he be reasonably careful about the extensive practice of post-selection (possibly conducted by his coworkers) that was not discussed at all in any of his publications that I can find?
证据2.12:被告从其研究伦理委员会了解到他们的后选择被揭露并受到质疑之后,被告仍然不承认并讨论其后选择行为。例如,作者在2020年4月17日的最新发表文章,Lillicrap, Santoro, Marris, Akerman和Hinton,“反传播与大脑”,《自然神经科学评论》(Nature Reviews Neuroscience),https://doi.org/10.1038/s41583 -020-0277-3 中继续掩盖他们的方法中的后选择。此外,Hinton似乎缺乏最低的仔细,因为他知道这样的评论文章可能不会有严格的审稿。例如,在图4中,所谓的“(3)后向传播动作电位”沿着向上的箭头从“(1)前馈区”传到“(2)反馈区”。如果Hinton在发表文章中对这样一个视觉上极其明显的错误(可能是其他人起草的)在技术上如此非常粗心,那么他如何会合理地和仔细地对待(可能由他的同事执行的)的一直在做的后选择?在我能找到的他的所有文章中都没有谈到过后选择。
Claim 3: Making Misleading Claims Violations of CEPC 1.3: “Making deliberately false or misleading claims.”
主张3:提出误导性声明。违反CEPC 1.3:“故意制造虚假或误导性声明。”
Evidence 3.1: Misleading Boltzmann Machines: … In the Turing Award announcement:
证据3.1:误导性的玻尔兹曼机:…在图灵奖公告中:
[P11] ACM, “Fathers of the Deep Learning Revolution Receive ACM A. M. Turing Award”, Bengio, Hinton, and LeCun Ushered in Major Breakthroughs in Artificial Intelligence, See ACM official web, https://amturing.acm.org, 2019,
under “Select Technical Accomplishments”, the second work of Hinton, Boltzmann Machines, violated CEPC 1.3.
在“优选技术成就”下,Hinton的第二项工作是玻尔兹曼机,违反了CEPC 1.3。
The publication [P4] above which probably corresponds to the lowest error rate in ImageNet Contest 2012 has dropped Boltzmann machines. The mention of Boltzmann machines in the Turing Award nomination package apparently misled the ACM Turing Award Committee.
上面的出版物[P4](可能相对了ImageNet 2012竞赛的最低误差率)已经放弃了B玻尔兹曼机器。图灵奖提名包中提到的玻尔兹曼机显然误导了ACM图灵奖评奖委员会。
The Claimant failed to find any member in the ACM Turing Award Committee who was an expert in neural networks:
原告未能从ACM图灵奖评奖委员会中任何一位神经网络专家:
Committee Chair:
委员会主席:
Michael J Carey, University of California, Irvine, carey@acm.org
Committee Members:
委员会成员:
Rodney A Brooks, brooksra@acm.org
Shafi Goldwasser, shafi@theory.csail.mit.edu
David Heckerman, heckerma@acm.org
Jon Kleinberg, jkleinberg@acm.org
David Patterson, dapatterson@acm.org
Joseph Sifakis, jsifakis@acm.org
Olga Sorkine-Hornung, osorkine@acm.org
Alfred Z Spector, aspector1@acm.org
Jeannette M. Wing, Columbia University, wing@acm.org
Evidence 3.2: The obviously high computational complexity of Boltzmann machines (using monolithic vectors without partial receptive fields) is probably the main reason for Hinton to drop Boltzmann machines in their ImageNet Contest 2012. This is because the Hinton team must try many random networks using GPUs. Boltzmann machines were obviously too slow, let alone their performance problems.
证据3.2:玻尔兹曼机器的明显较高的计算复杂性(使用没有局部接受野的整块矢量)可能是Hinton在2012年ImageNet竞赛中放弃使用玻尔兹曼机的主要原因。这是因为Hinton团队必须使用GPU尝试许多随机网络。玻尔兹曼机显然太慢,更不用说它们的性能问题了。
Therefore, an ImageNet kind of competition is primarily a competition for resources (e.g., the number of people, the amount of computing resources, and the total number of hours devoted to the team-scale parameter hand-twisting and most-lucky network picking), not really a competition ofnew technology.
因此,ImageNet竞赛主要是针对资源的竞赛(例如,人员数量,计算资源大小以及用于团队规模的手工参数调试和最幸运网络的挑选的总小时数),而不是真正的新技术的竞争。
In contrast, the AIML Contest, which the Claimant organized since 2016, is the only contest, as far as the Claimant knows, that requires competitors the use the same amount of computational resources (the number of neurons). It further requires that each single network “life” must succeed through its “lifetime”. It uses DN as a general-purpose learning engine. The DN has preliminarily, but holistically, solved a series of “holy grail” problems not only in AI and but also Natural Intelligence,
including the local minima problem (every random network is performance equivalent),
the auto-programming for general purposes (APFGP) problem (that each human brain is capable of).
相比之下,自2016年以来一直举办的AIML竞赛,据原告所知,是唯一的要求参赛者使用相同数量的计算资源(神经元数量)的竞赛。它进一步要求每个网络“生命”必须通过其“生命期”获得成功。。它使用DN作为通用学习引擎。DN已初步(但整体上)解决了一系列的“圣杯”问题。这些“圣杯”问题不仅涉及人工智能,还涉及自然智能,
1. 包括局部极小问题(每个随机网络的性能都相同),
2. 通用自主编程(APFGP)问题(每个人的大脑都有的能力)。
See [P10] above and [P12, P13] below for detail.
有关详细信息,请参见上面的[P10]和下面的[P12,P13]。
[P12] J. Weng, Z. Zheng, X. Wu, J. Castro-Garcia, S. Zhu, Q. Guo, and X. Wu, “Emergent Turing Machines and Operating Systems for Brain-Like Auto-Programming for General Purposes,” in Proc. AAAI 2018 Fall Symposium: Gathering for Artificial Intelligence and Natural Systems, Arlington, Virginia, pp. 1-7, October 18 - 20, 2018.
[P13] J. Weng, A Model for Auto-Programming for General Purposes, Cornell University Library, arXiv:1810.05764, 22 pages, June 13, 2017, also Technical Report MSU-CSE-2015-13, 2015.
Evidence 3.3: Yoshua Bengio misled the community by citing a book chapter as PAMI in his CV but does not list this fraudulently cited chapter in his CV. In Bengio’s CV file YB-CV_19Reb2019.pdf (App. 4) published on www.iro.umontreal.ca/~bengioyand still available through a google search using “Yoshua Bengio CV” (probably also in his reports submitted to elsewhere), under the “Service to Profession and the Sciences” section, to the right of 1989-1998, the publication “PAMI 1991” could not be found from Google Scholar. As PAMI is a common acronym for the IEEE Transactions on Pattern Analysis and Machine Intelligence, but the IEEE Explore site did not have this Bengio’s publication either. Instead, I found:
证据3.3:Yoshua Bengio在其学术简历中把一本书中的一章写为PAMI期刊文章,误导了社区,但并未在其学术简历中列出该一本书的一章。发布在www.iro.umontreal.ca/~bengioy上的Bengio的学术简历文件YB-CV_19Reb2019.pdf(附录4)中,并仍然可以通过使用“Yoshua Bengio CV”在Google搜索查得(可能也在他提交给其他部门的报告中),在1989-1998年右侧的“专业和科学服务”部分下,无法从Google Scholar中找到出版物“PAMI 1991”。由于PAMI是IEEE Transactions on Pattern Analysis and Machine Intelligence的常见缩写,但从IEEE Explore网站也没有找到Bengio’s发表文章。相反,我找到了:
[P14] Yoshua Bengio and Renato DeMori, Connectionist Models and their Application to Automatic Speech Recognition, Machine Intelligence and Pattern Recognition, Volume 11, 1991, Pages 175-194,
which is a chapter in an edited book. In his list of three categories of publications, the year 1991 did not include this book chapter. With both the fraudulent cite and the missing, this behavior to mislead seems deliberate.
这是一本编辑书中的一章。在他的三类出版物清单中,1991年确实包括这本书的章。欺诈性引用加缺失,这种误导行为似乎是故意的。
Claim 4: Y. LeCun and Alphabet/Google seemed to have committed wire fraud, violation of Title 18 of the US Criminal Code, 18 U.S.C §1343: “having devised or intending to devise any scheme or artifice to defraud, or for obtaining money … by means of false or fraudulent pretenses, representations, or promises, … to be transmitted by means of wire… for the purpose of executing such scheme”. G. Hinton and Y. Bengio appear to have committed fraud, violation of Canadian Criminal Code Fraud 380 (1) “Every one who, by deceit, falsehood or other fraudulent means, whether or not it is a false pretence within the meaning of this Act, defrauds the public or any person, whether ascertained or not, of any property, money or valuable security or any service, …”
主张4:Y. LeCun和Alphabet/Google似乎犯下了电传欺诈,违反了《美国刑法典》第18编,§1343款:“已设计或打算设计任何欺诈的方案或计谋,或为了获取金钱……通过虚假或欺诈性的借口,陈述或诺言,……以电传方式 …… 以执行该方案为目的”。G. Hinton和Y. Bengio 好像犯了欺诈罪,违反了加拿大《刑法》第380条(1)的规定,“每个人以欺骗手段,虚假或其他蒙骗手段,无论是否构成本法令所指的虚假伪装, 欺诈公众或任何人,无论是否确定,为了任何财产,金钱或有价证券或任何服务,……”
The Respondents presented false pretenses and representations to be transmitted by means of wire for the purpose of executing such scheme and further obtained (Turing Award) money.
被告提供了虚假的借口和陈述,以通过电传的方式进行,目的是执行这种方案并进一步获得了(图灵奖)金钱。
Evidence:The Respondents used test sets as training sets in the evidence presented here and references herein, as if all repeatedly typed here, as fraudulent pretensesandrepresentationsfor the purpose of executing such schemes and receiving money from U.S. and Canadian governments, publicly traded companies such as Alphabet/Google and Facebook, Turing Award, and other awards. They have received such moneys.
证据:被告将测试集用作训练集,按此处提供的证据和此处引用的证据,好像在这里重复输入的所有内容一样,都是欺诈性的借口和陈述,目的是执行此类计划并从美国和加拿大政府,公开交易的公司(如Alphabet/Google和Facebook),图灵奖和其他奖项得到钱。他们已经收到了这些钱。
The following are questions from an authority for this matter and my answers.
以下是有关此问题的一个权威机构提出的问题和我的回答。
Q2.1:Do you have any evidence that the accused used test data sets for training data (or training data sets as testing data sets) and did not disclose that fact in the associated publications? Please provide specific examples if so.
问题2.1:您是否有证据表明被告使用了测试数据集作为训练数据(或将培训数据集作为测试数据集),并且没有在相关出版物中披露该事实?如果是,请提供具体示例。
回答2.1: For the same reasons that I stated above, I do not yet have direct evidence but this is well known mechanisms for error back-propagation. Furthermore, this is the only possible way to reach the artificially high reported-performance, as long as error back-propagation is used. See “backpropagation” line 6 of Section 4.2 of [P4], “using the backpropagation algorithm” in the abstract of [P5], and “trained with backpropagation” in the abstract of [P6].
A2.1:出于与我上面所述相同的原因,我还没有直接的证据,但是众所周知的误差反向传播的机制。此外,只要使用误差反向传播,这是达到人为地高的报告性能的唯一可能方法。请参阅[P4]的第4.2节第6行的“反向传播”,[P5]的摘要中的“使用反向传播算法”,以及[P6]的摘要中的“经过反向传播训练”。
This is mainly because the error backpropagation algorithm starts with random weights. See “backpropagation” page of Wikipedia: “Initially, before training, the weights will be set randomly.”
这主要是因为误差反向传播算法从随机权重开始。请参阅Wikipedia的“反向传播”页面:“最初,训练前,权重将被随机设置。”
Q2.2:Do you have any evidence that selecting a local-minimum network based on its observed training error is considered improper within the consensus view of the community at the time of publication? If so, do you have any evidence that the accused failed to disclose this post-selection practice in their prior published work where such concealment would have been consequential to the acceptance of the work?
问题2.2:您是否有任何证据表明,在发表时,根据领域的共识观点,根据观察到的训练误差选择局部最小点网络是不适当的?如果是这样,您是否有任何证据表明被告没有在他们先前发表的文章中披露这种后选择方法,而这种隐瞒结论性地影响到了文章的被接受?
A2.2: Yes, I do. Two aspects that the respondents violated:
回答2.2:是的,我有。被告违反的两个方面:
(A) Cross-validation. Cross-validation is to reduce the bias in dividing the available data into training set and testing set. Let us consider the simplest two-fold cross-validation (generally n-fold): All the available data are divided into two folds of equal size, A and B. In the first process of training-and-testing, A is the training set and B is the testing set. In the second process of training-and-testing, B is the training set and A is the testing set. Then the error through this two-fold cross-validation is the average error of these two processes. Clearly, cross-validation makes it difficult to choose A and B in such a biased way so that training on A makes testing on B easy. See “Cross-Validation (statistics)” in Wikipedia. However, none of [P4]-[P6] used cross-validation. In fact, ImageNet Contests apparently divide all available data sets into a particular sets A and B so that training on A is easier for testing on B (i.e., the training set, validation set, and testing set are all carefully manipulated by hands). For example, zebras and stripe shirts in the training set are validated by the hand-selected validation set (without stripe shirts) so that the error in the testing set (also without stripe shirts) is artificially low. This was not acceptable by the community at the time of publication.
(A)交叉验证。交叉验证是为了减少将可用数据分为训练集和测试集时的偏心。让我们考虑最简单的两重交叉验证(通常为n重):将所有可用数据分为大小相等的两份A和B。在训练和测试的第一个过程中,A是训练集合,B是测试集合。在训练和测试的第二个过程中,B是训练集,A是测试集。那么,通过这种双重交叉验证的误差就是这两个过程的平均误差。显然,交叉验证使得很难以偏心的方式选择A和B,使得在A上进行训练会使在B上进行测试变得容易。参见Wikipedia中的“交叉验证(统计)”。但是,[P4]-[P6]均未使用交叉验证。实际上,ImageNet竞赛显然将所有可用数据集划分为特定的A集和B集,以便
在A上进行训练更容易在B上进行测试(即,训练集,验证集和测试集都需要仔细地手工操作)。例如,训练集中的斑马和条纹衬衫,通过手工选择的验证集(不含条纹衬衫)进行验证,因此在测试集(也没有条纹衬衫)中的误差人为地被降低了。在发表时,这是领域所不能接受的。
(B) Furthermore, during each process of training-and-testing during cross-validation, the testing set cannot be used for post-selection. Otherwise, cross-validation becomes degenerate: without true testing set in each of the training-and-testing processes. If this post-selection practice in [P4] to [P6] from the respondents was explicitly stated in the manuscripts, [P4]-[P6] would have been rejected. I searched [P4]-[P6] and could not found any place where such post-selection was disclosed.
(B)此外,在交叉验证期间进行训练和测试的每个过程中,测试集都不能用于后选择。 否则,交叉验证就会退化:在每个培训和测试过程中都没有了真正意义上的测试。 如果文章中明确指出了被告在[P4]至[P6]中进行的这种后选择,则[P4]-[P6]将被拒绝。 我搜索了[P4]-[P6],却找不到任何披露此类后选择的地方。
Such falsified performance from the respondents and their tacit agreement to Fei-Fei Li’s claim: “machines' progress has basically reached, and sometimes surpassed human level” during GIF’17 (See figure 1 from YouTube below), have misled the AI research community, many innocent AI students, public companies like Google and Facebook, government funders like NSF, and public.
被告的这种造假性能以及他们对李飞飞主张的默契:“机器的进步基本上已经达到了,有时甚至超过了人类的水平”(参见以下YouTube的图1),误导了AI研究界、许多无辜的AI学生、像谷歌和脸书这样的上市公司、像NSF这样的政府资助部门以及公众。
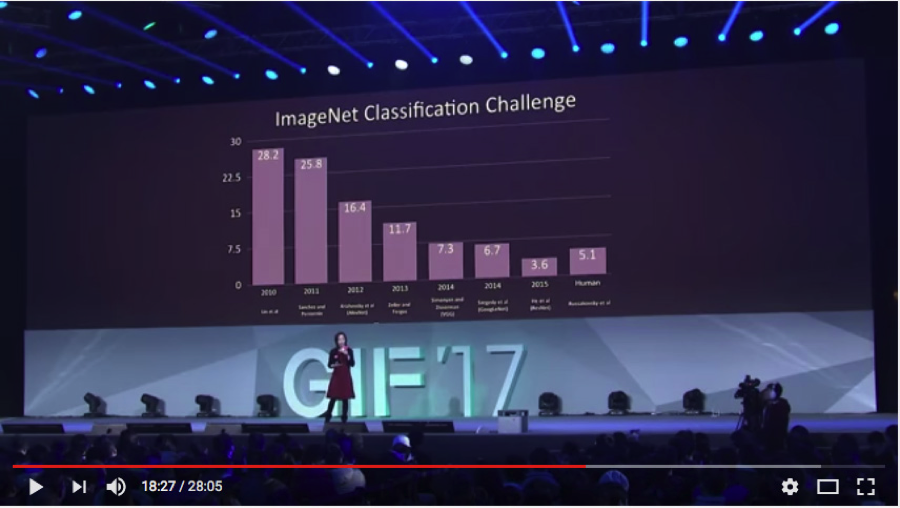
Figure 1: Fei-Fei Li was saying “machines’ progress has basically reached, and sometimes surpassed human level” (GIF'17).
图1:李飞飞正在说“机器的进步已经基本达到,有时甚至超过了人类的水平”(GIF'17)。
Q2.3:Do you have any evidence that hand-labeling was performed by anyone you accuse of doing so and who also failed to disclose it?
问题2.3:您是否有证据表明被告中有人做过手工贴标,但没有公开呢?
A2.3: Yes, LeCun’s MNIST data set is such. LeCun’s MNIST data set and all the MNIST data sets used by the three respondents have been hand-labeled, for both training set and test sets. For example, LeCun’s team should have used the hand-labeled test set of his MNIST data set. Otherwise, there is no way for him to report the history of gradually reduced (test) errors on the same MNIST data set on his own web page. However, LeCun failed to disclose that his group and other groups listed on this web site used his hand-labeled test set as training set, nor did all the publications his web site cited.
回答2.3:是的,LeCun的MNIST数据集就是如此。LeCun的MNIST数据集和三个被告使用的所有MNIST数据集均已手工贴标,分别用于训练集和测试集。例如,LeCun的团队应该使用了他的MNIST数据集中带有手工贴标的测试集。否则,他无法在自己的网页上报告MNIST数据集上逐渐减少了的(测试)误差历史记录。但是,LeCun没有透露他的组和此网站上列出的其他组使用他手工贴标的测试集作为训练集。他的网站引用的文章也没有透露。
For ImageNet data set used by [P3], the ImageNet Contest organizers probably did not supply the labels of training set to the teams. However, basic community accepted practices were not performed by the ImageNet organizers. For example, in DARPA tests, a DARPA manager would go to each team bringing the large data sets with him. The test must be completed within the same day. Hopefully, each team does not have enough time and man-power to hand label all data in the test set within a day. However, this is not the case with the ImageNet Contests. The organizers of ImageNet gave as many as 70 days in 2012, and there has been no evidence that the ImageNet organizers did any sufficient measures to prevent each team to hand-label test sets. This lack of measures to uphold research ethics is not acceptable by the community.
对于[P3]使用的ImageNet数据集,ImageNet竞赛组织者可能未向竞赛团队提供训练集的标签。但是,ImageNet组织者并未执行领域公认的基本做法。例如,在DARPA测试中,DARPA经理会去每个团队,带上大数据集。测试必须在同一天内完成。希望每个团队没有足够的时间和人力在一天之内手工贴标测试集中的所有数据。但是,ImageNet竞赛不是这种情况。ImageNet的组织者在2012年提供了多达70天的时间,而且没有证据表明ImageNet的组织者采取了足够的措施来防止每个团队手工贴标测试集。这种维护研究伦理的缺乏是领域所不能接受的。
Q2.4:Do you have evidence that hand-labeling the test sets was expressly forbidden for ImageNet teams?
问题2.4:您是否有证据表明ImageNet团队明确被禁止手工贴标测试集?
A2.4: I did not find any instructions in the ImageNet web site that explicitly forbid hand-leveling the test sets. However, it is a commons sense that hand-leveling the test sets is unethical.
回答2.4:我在ImageNet网站上找不到任何明确禁止手工贴标测试集的指令。但是,众所周知,手工贴标测试集是不道德的。
Q2.5: To what publication by Dr. LeCun are you referring in "Evidence 2.2"?
问题2.5:在“证据2.2”中,您指的是哪篇LeCun博士的文章?
A2.5: I would like to correct:The LeCun reported lowest error 23 was from D. Cireşan, U. Meier and J. Schmidhuber in CVPR 2012 which suffer from the same data falsification problem using LSTM. LeCun’s lowest error reported by himself was 53 from K. Jarrett, K. Kavukcuoglu, M. Ranzato and Y. LeCun: “What is the Best Multi-Stage Architecture for Object Recognition?”, in Proc. International Conference on Computer Vision (ICCV'09), IEEE Press, 2009. However, such performance data were all falsified by using post-selection and also disregarding the community well accepted cross-validation.
回答2.5:我想纠正:LeCun报告的最低错误23来自CVPR 2012中的D. Cireşan,U. Meier和J. Schmidhuber,他们有使用LSTM的同样数据造假问题。LeCun自己报告的最低误差是53个错误,来自K. Jarrett,K. Kavukcuoglu,M. Ranzato和Y. LeCun:“什么是用于物体识别的最佳多级架构?” 国际计算机视觉会议(ICCV'09),IEEE出版社,2009年。但是,通过后选择并忽略了领域公认的交叉验证,这些性能数据都是伪造的。
An authority wrote: “We examined selected publications by the accused and did not see examples where they used test sets as training sets. … We are left to conclude that there is no evidence to support this charge of research misconduct.”
一个权威写道:“我们检查了被告的一些选定文章,没有看到他们使用测试集作为训练集的例子。……我们只能得出结论,没有证据支持这项研究不当行为的指控。”
The authority went on: “Dr. Weng admits that he does not have ‘direct evidence’ that the
accused improperly used test sets as training sets, instead asserting without supporting evidence that this is well known for error back-propagation.” “Dr. Weng also makes some sweeping statements about Google’s administrative management of its research; these statements are unsupported by anything Dr. Weng presents. We further note that his statement is phrased in such a way that it might be read as containing a threat.” “Evidence is required, especially when evaluating such serious charges.” “Finally, it seems that Dr. Weng believes research fraud occurred because his work has not been given more exposure. This is clearly not grounds to assert fraud, especially in this manner.” “He asks that Federal charges, in the US and Canada, be applied by ACM to the accused. ACM is not a law enforcement agency and does not conduct investigations into, or prosecutions of, alleged violations of laws in any country or municipality.”
此权威继续写道:“翁博士承认他没有“直接证据”证明被告不当使用测试集作为训练集,而是没有支持证据就断言这是众所周知的误差反向传播[的问题]。”“翁博士还就谷歌对它研究的行政管理发表了笼统的声明;翁博士的任何陈述均不支持这些声明。我们进一步注意到,他的措词可能被理解为包含威胁。”“需要证据,尤其是在评估此类严重指控时。”“最后,似乎翁博士相信研究欺诈的发生是因为他的工作尚未得到更多的曝光。显然,这不是断言欺诈的理由,尤其是以这种方式。”“他要求ACM在美国和加拿大对被告提出联邦指控。ACM不是执法机构,也不对任何国家或城市的涉嫌违法行为进行调查或起诉。”
Stay tuned.
敬请继续关注。
https://wap.sciencenet.cn/blog-395089-1229835.html
上一篇:生活是科学(35):图灵奖是否给了剽窃?
下一篇:[转载]公开信:美国MSU大学工学院院长是怎么迫害和清洗中国学生和学者的?