博文
爱犯错的智能体(二十,完结篇) -- 平衡:机器vs智能?
 精选
精选
||
一个明智的人,仅仅自己研究自然和真理是不够的,他应该敢于把真理说出来,帮助少数愿意思想并且能够思想的人;因为其余甘心作偏见的奴隶的人,要他们接近真理,原来不比要虾蟆飞上天更容易。
------- 引自拉·梅特里,《人是机器》[1]
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
自然界总是存在各种平衡。对一件事的极致追求,往往需要用另一件的损失来换。比如,有了钱的时候就没时间,有了时间的时候又没有钱,因为“鱼和熊掌不可兼得”。
宇宙万物,在微观层面的平衡表现为量子力学中的不确定性原理,也称为测不准原理,是测量粒子的精确位置与精确速度上的不可兼得,他保护了量子力学。而在宇观,有一个光速不变性原理,30万公里的速度限定了人类探索宇宙的空间范围,他同时也保护了宇宙物理学。那人工智能领域里的平衡、研究方式能是怎样的呢?研究现状又存在哪些瓶颈呢? 我想从五点展开讨论:
1、人工智能的不确定性原理
2、由粗到细的结构发育
3、智能测试
4、智能体实验的伦理
5、人工智能困境
一、不确定原理
在人工智能领域,与物理中有过几个类似的不确定原理。深度学习之前曾一度流行的稀疏学习理论里,科学家们希望通过对数据特征的稀疏化来获得可解释性。但是,其解释性的代价是构造了具有随机性、稠密的变换基函数,如高斯函数。这一思路是稀疏与稠密、时间与空间的不确定性。我们在傅里叶变换、小波变换以及稀疏学习中都能看到这一不确定原理的影子,时间域细节清晰了,频率域就稠密,反之亦然。但这种不确定性原理只提供了寻找可解释变量的方式,能处理的变量规模相对有限,对智能的启示还不明显。

图1 拉特飞·扎德 (来自Wiki)
另一个是模糊理论 [2]的创始人、加州大学伯克利分校的拉特飞·扎德 (Lotfi A. Zadeh, 1921. Feb. 2 - 2017. Sep. 6) 教授(见图1)在1972年提出的、解释复杂系统的不相容原理(Incompatibility Theory) [3]。他认为:
“随着系统复杂性的增加,我们对其特性作出精确而有显著意义的描述能力会随之降低,直至达到一个阈值,一旦超过它,精确和有意义二者就会相互排斥。”
不相容原理表明,随着复杂性的增加,预测和可解释性之间将存在平衡或折衷。然而,纵观人工智能的发展史,复杂性的定义一直在变迁。最早复杂性被认为是模型参数的数量,后又被视为神经网络的网络结构复杂程度。统计学习理论提出后,在分类问题上又转为“能分类任意数据组合的”模型划分能力。值得指出的是,这种划分能力并不与参数个数成线性关系的,有可能一个参数也具有无穷大的划分能力。结果,单从复杂性的角度来度量这种平衡或刻画不确定性,尽管直观,但还存在复杂性不容易确定的问题。
我在《深度学习,你就是116岁的长寿老奶奶》中指出过,可解释性和可预测性之间存在着平衡,因为它是统计和个体之间的平衡。要追求预测性能,总可以找到不具统计解释但却性能优异的个体,而统计往往又会因为平均而牺牲个体的优异性能。这是统计和个体形成的预测与可解释性之间的不确定性,估且将其称为“平猫不确定原理”。
如果令模型的预测P与最优预测P*之间的绝对值差异为∆P =|P-P*|,令模型的可解释性与最优的可解释性I*之间差的绝对值差异为∆I=|I-I*| ,令C是一个足够小的常数,则会存在一个预测和可解释之间的不确定性,即:
![]()
前者可以通过对个体性能的追逐获得足够近的小值,而后者可以通过对平均性能的追逐获得足够近的小值,但两者之间存在折衷,不可兼得。
而现阶段我们对可预测性的追求更多一些,因为他与工业界关注的性能密切相关,能够直接带来GDP的产出,也是引发了第三波人工智能热潮的主要原因。但是,只追求预测性能,会使得其更像是机器、更像是人工智能领域的“飞机”,是“弱人工智能”, 与我们最终期望实现的“强人工智能”还有不小的距离 。
如果我们想要构造具有这种折衷或平衡的智能,有没有可行的路呢?
二、由粗到细的结构发育
除了宇宙可能是从零开始的以外,没有什么其它东西是凭白无故产生的。人的智能从胚胎发育开始,然后有了视觉、听力、触觉等感官和身体器官的发育,并最终有了智能体的形态。再经过漫长的儿童期和教育,智能才得以逐渐完善。在这一过程中,人类的智能经历了由粗到细的结构变化,而平衡似乎就隐藏在其中:
1、人在思维中,存在快思维与慢思维两种方式,常以快思维为主 [4]。而快思维的频繁使用应该与最初的粗糙或粗略学习有密切关系。试想,人在走路的时候,有谁会关注路面的纹理细节呢?即使人的身份识别,早期儿童心理学发现,小孩往往更容易记住父母而非陌生人。但如果母亲用帽子将其轮廓遮挡后,小孩会出现短时的认知障碍。这些都表明,粗略式的学习和记忆是早期智能发育的基础。因为他可以让人类更快速地了解环境和目标。在保证足够预测精度的同时,节省了大量的计算资源和耗能。
2、这种粗放式的认知模式可能被固化到后期的认知中,对快思维起了关键作用。值得指的是,并非只有人类才有这种快思维。非人的动物或智能体都具备,所以在常识智能方面人和其他非人智能体存在着有共性的结构发育方式。
3、 我们也可以推测,这种共性的发育是被嵌套在基因里,通过遗传完成的。所以,似乎人类和非人智能体最初的学习模式、甚至于情感的表达方式都并非全是主动完成的,而是被基因编码所诱导的。从这个角度来看,人和非人智能体似乎就是一台机器。那么,弄明白基因的这种按时表达,也许对于理解智能的发育和建构是关键的,甚至有可能在未来改变智能体的学习模式。但人又不完全是机器,因为人类在漫长的演化中,引入了漫长的儿童期、独特的教育和语言,并通过群体的交互保证了种族的稳定和繁衍。
4、如果以上推测是合理的,那么结构的表达大概是怎样一个次序呢?首先,对于正常发育的人来说,视觉应该是最重要和优先发育的,然后才是其他辅助的感官器官的发育。因为视觉本就是从大脑发育中分离出来的,可以视为大脑的一部分。其次,当具体概念得到由粗到细的认知后,才开始建构更抽象的语言。既使是情感的建立,也是从直觉式的情感开始,然后才有更细腻的、被修饰了的理性情感。在其他认知能力上,发育的模式应是类似的,其建构非常象我们常说的金字塔(见图2)。如果在研究人工智能的过程中,本末倒置的去建构人工智能体,比如重点关注抽象的、如自然语言的结构分析,而不给其提供视觉或其他感官器官的发育研究成果作为支撑,很有可能研究出来的是缺乏真正智能的机器。
5、不仅在具体到抽象中存在金字塔式的由粗到细认知结构,在每个层次如视觉、听觉等也应有类似的层级结构。智能体在使用这些结构时,能自适应地按需选择是用粗糙、还是精细、还是两者折衷的模型来完成推理、预测等认知任务,以获得在快思维和慢思维间的平衡。

图2 埃及金字塔
三、如何判断有智能?
假定若干年后,人造的智能体具备了由粗到细、金字塔式的结构,那如何判定其是否具有智能呢?不妨回看下经典的、一正一反的两个智能测试方案。
在人工智能领域,图灵测试是最经典的智能测试方案,它由艾伦·图灵(Alan Turing)在1950年的论文《计算机器与智能》中提出 [5] 。他设想了一种环境,如图3,在测试者与被测试者隔开的情况下,测试者通过某种设备如键盘向被测试者随意提问。经过多次测试后,如果超过30%的测试者不能确定被测试者是人还是机器,那么这台机器就通过了测试,并被认为具有人类相仿的智能。
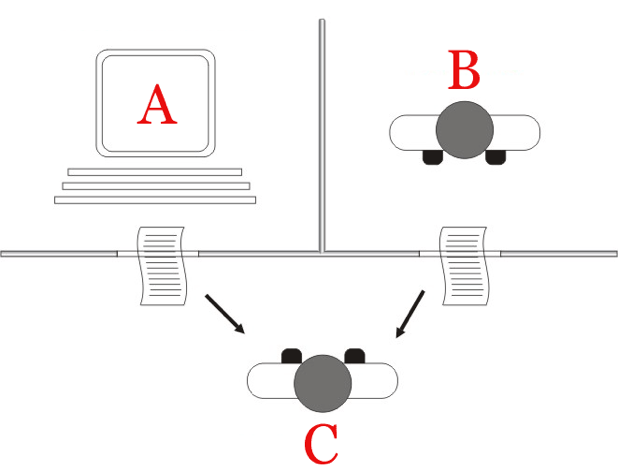
图3 图灵测试(来自Wiki)
自此以后,不计其数的科研人员设计了各种程序,希望能通过图灵测试,以证明其能达到甚至超越人类的智能。然而,情况并没有想象的乐观。事实上,30%的指标,还是图灵当年基于对人工智能前景看好,预测在2000年就能实现的。但现在看来,我们离这一目标还有些不小的距离。
除此以外,图灵测试里设置的提问环节,或多或少都假定了机器和智能体具备了高层或抽象智能,因此自其测试被提出后,人类对问题回答(俗称Q/A)的研究一直常盛不衷。但是,这一测试对并没有涉及常识智能甚至情感的鉴别。而从结构发育的角度来看,如果要建构智能体,这两者的鉴别尤其重要。
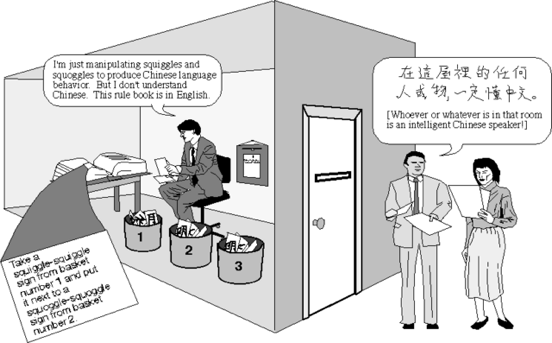
图4 中文房间
另一个有名的测试是中文房间(Chinese room,或称为the Chinese room argument),如图4。它由美国哲学家约翰·希尔勒(John Searle)在1980年提出 [6]。 在中文房间的测试中,希尔勒假定了有个完全不会说中文、只能说英文的人在一间房里。房间除了门和一个小窗口,其余全封闭。不过,他随身带了本具有中文翻译能力或程序的书,房间里还有足够的纸、笔和柜子。测试者将中文纸条通过窗口递进房间,而屋里的人可使用他的书来翻译并以中文回复。尽管完全不懂中文,但却可以让房间外的人以为他是会说流利中文的。
这个测试表明,即使房间里的人对中文一窍不通,但仍然可以通过运行翻译程序来骗过测试者,让测试者对机器产生智能的印象 。与图灵测试不同,中文房间是希望推翻强人工智能对智能的定义,即“只要计算机设计好适当的程序,理论上来说,就可以认为计算机拥有了它的认知状态,并且能像人一样进行理解活动”。
从中文房间的测试不难发现,它主要质疑的是预测行为与智能的等价性。但是,智能不仅仅只是预测。因此,我们应该要在比预测更宽泛的定义和环境下测试智能。
另外,这两个测试都采取了隔离,它迫使测试不得不借助于高层的抽象智能如语言来完成交互。其次,这两个测试似乎都假定了与人的智能的逼近。
回看本科普系列中介绍的犯错机制和常识智能等,可以发现常识智能、犯错都是智能体中必然存在的。尤其是犯错机制,从某种意义来说,他是使得智能体世界具有多样性的原因之一,也是有群体存在的前提之一。所以,智能测试应该不限定于抽象智能,更应该包含常识智能和对犯错情况的一般性测试。
另外,其它非人智能体同样具备了一些基本的智能,包括情感智能、快思维方式和慢思维方式。更何况,如果没有语言和工具的引入,人在自然界的进化中, 本属于极易被淘汰的一种生物。
因此,采用更一般性的智能测试条件:开放环境、不限定人的智能模拟,是评测智能有否的关键。
基于这些考虑,这里提出一个也许可以合理来检验是否具有智能的方案,估且称为“平猫测试”:
将一个机器猫(也可以是其它任意形态)放在透明的盒子里或开放环境里,测试者可以与它交互,可以观察、分析它的行为。在确信它的预测能力足够好的前提下,如果它的犯错程度是可接受的,情绪表达、自我意识会让超过一定比例如30%的测试者感觉与人或非人智能体相差无几时,则可以认为它具有智能。
只要它满足了以上条件,我们就可以认为它是智能体。注意,这里是不要求其具有任何我们已知的智能体形态,但要通过测试,测试者需要确信这只机器猫有智能体该具备的某种平衡。如果只是预测能力方面有异常优异的表现时,而对其它智能相关的指标牺牲过大时,此时不能认为其具有智能,而只能认为是具有机器的预测能力。
要构建能通过这一测试的智能体,我们必须在有智能体形态的智能体上寻找线索。那么,在哪里找呢?
四、如何研究智能--- 智能测试体的选择与伦理
谈强人工智能,一般我们认为是可能制造出真正能推理和解决问题的智能机器,并且,这样的机器能被认为是有知觉,有自我意识的。因为这样的定义,多数人工智能研究者会将其向人的智能看齐,需要研究人或像人的生命体的智能发育。这自然会带来比较严重的伦理问题,因为研究人的智能途径之一是要对人的大脑中进行深层次的探索。可是不管是脑电极形式还是基于核磁共振的方式,都会或多或少损害人脑的神经元细胞。这是大家不愿意涉及强人工智能的原因之一。
当然,退而求其次似乎更合理。于是,科研人员选择了与人类在形态上最为接近的猴子与猩猩来做实验。不管是手势的使用,还是对语言的理解,似乎都有一些相似之处,选择它们似乎是最佳选择。为了人类的未来,它们做些牺牲也无可厚非。所以,在这两类动物上进行的很多实验,经常能看到要么把猴子关在笼子里,要么开颅插好电极固定在架子上,测试其对各项指令的反映程度,试图发现脑区活动与智能的线索。
然而,这也许并非是现阶段研究智能最有效的方式,也可能并非是最好的实验品。因为成本太贵,能做得起猴子猩猩的实验室可以说都是非富即贵的。所以,才会有研究人员宁愿直接在人身上直接做相关测验,因为可能更经济。实际上,真正与人类有良好情感交互的,不是猴子猩猩,而是宠物狗。经过几千年的驯服,狗早已经能够非常好的理解人类的情感,甚至部分语言。从常识智能和基本情感来看,狗已经具备了和人类几乎一样的能力。更何况,狗的数量远多于猴子猩猩,且不存在不可逾越的伦理问题。
事实上,如果不是因为语言和教育,人类在自然界的位置应该是属于弱小的行列。所以,综合这些信息,从这个角度出发,我们并不需要把研究的测试体限定在人和猴子猩猩上,而是有着大量可供选择的测试体,来帮助我们理解目前还不太明了的常识智能和情感。
然而,即使提供了大量的测试体,现阶段着手研究强人工智能也并非是一蹴而就、水到渠成的,因为我们还处在人工智能的困境中。
五、人工智能困境
在这一波人工智能热潮中,有相当多的学科都投入了人工智能的研究中。尽管产业界形成了显著的进展,尤其在安防相关的行业,也有通过图灵测试的所谓报道,但我们似乎并没有看到多少与真正智能相关的影子,困难主要在哪里呢?这里从几个主要方向上谈些自己初浅的观点, 希望能给大家一些思考和线索:
1、机器学习
在本轮人工智能热潮中,最亮眼的主角无疑是深度学习,或更宽泛一些的机器学习。他对于弱人工智能以及在产业界的应用的推动是显而易见的。然而,机器学习是否真能帮助理解真正的智能呢?
我们不妨将机器学习的技术概括成程咬金的三板斧:正则化、加圈、加层,这样也许会比较容易理清头绪。
第一板斧是正则化,其观点是认为我们要研究的问题求解不存在唯一性,往往是一对多的求解。Tikhonov将其称之为 病态问题(ill-posed problem) [7]。要让病态问题良态化,最自然的做法就是引入约束项或正则化项。从病态问题良态化的思想提出至今,这一板斧挥了六十多年,随着对数据的结构持续不断、更新的认识,我们提出了各种正则化的方案,从模型参数的复杂性、到空间的光滑性、到模型结构的复杂性、到特征的稀疏性,诸如此类。但似乎这些努力最终都转化为预测任务,而并没有对智能给出更明晰的解答。可能的原因是:如果给定了一个限定体积的球作为搜索空间,那能寻找的解空间必然只能在此球内去找。不管增加多少的约束项来使问题良态化,该良态化获得的全局最优解也只能是这个球张成的解空间上的局部最优。可是,如果一开始球就给错了呢?如果这个球只是相当于盲人摸象中摸的其中一条腿呢?
第二板斧是加圈,其主要思想是假定有观测到的世界变迁可能有一个或多个小人在暗中控制中,且这些变迁的变量和小人之间存在较复杂的相互关系,由此我们可以构造要么是有明确指向关系的有向图模型、要么是无明确指向的无向图模型,当然也可以混搭。这一板斧的优势在于方便解释,因为关系都是明确的。要丰富对世界各个侧面的理解,最自然的做法就是增加能描述更细粒度关系的圈和圈与圈的边了。但这一方法在变量过于复杂时,又容易出现关系混乱、计算量过大的问题,在现阶段也很难构造出可以自我生长的模型。
第三板斧是深度学习的加层。既可以往深了加,也可以往宽了加,还可以跳着加,只要你想得到就行。加层的历史按性能的改善可以分两阶段,相对浅层的经典神经网络时代和2012年深层的后神经网络时代。尽管有两个时代,从理论方面来看,他的变化却并不大。但从工程技巧来看,逐层变特征学习的策略让其获得了巨大的可寻优空间,再加上大数据的支持,使得其在预测能力相关的任务中,目前处于独孤求败的地位。其它门派只能在小样本环境中找点自留地。但是,(深度)神经网络模型从 MP模型开始,到非线性变换函数的引入、到反向传播算法的提出,到深层结构的发展,这一结构的主要长处还是预测,因为有广义逼用定理的支持。它并没有考虑模型的可塑性、可发育性,也没有触及本文中提及的智能所需要的平衡。
因为预测是机器学习的重中之重,所以,我们在此框架下能够追求的更多是弱人工智能方面的成就,也确实看到了不少相关的成果。但在真正智能的探索方面,机器学习还缺乏相关的理论支持。
2、 脑科学
与机器学习主战场在预测不同,脑科学更关注大脑的发育以及与智能的关系。在近几十年来,脑科学在微观层面,已经进入了细胞、分子水平;在宏观层面,随着各种无创伤脑成像技术的使用,如正电子发射断层扫描术(PET)、功能性磁共振成像技术(fMRI)、多导程脑电图记录术和经颅磁刺激术等的使用,已经可以对不同脑区数以万计的神经细胞的活动与变化进行有效的分析 [8]。
然而,由于目前各种探测技术在空间和时间两方面的成像分辨率都并不理想,我们的分析仍然是雾里看花的方式。尽管这种探测方式远比19世纪初曾盛行的“颅相学”科学多了,但我们对神经细胞集群每个单元的活动仍知之甚少,更不用说,将单元的信息组合起来理解大脑对知识、信息的加工和编码过程 [8]。其次,现在的研究对大脑中的意识也缺乏有效的了解办法。比如,尽管我在前文中提到过梦境的复述方法,但仍没有办法能真正复现大脑在梦境中的场景和故事。另外,如何从简单的神经活动升华为我们平日思考所用的快思维、慢思维,也都还缺少有效的研究方案。不仅如此,如果从机器学习的角度来看,由于脑的活动都是个体的,脑科学中诸多实验的可重复性都偏低,难以形成有统计意义的结论。基于以上原因,如果用唯物主义的讲法来归纳脑科学的情况,那就是:我们已有一些条件来理解脑活动中量变的过程,却还不明了什么时候量变会引起质变。
3、统计学
统计学对人工智能贡献最大的,当属频率派和贝叶斯两大流派,主要不同在于要不要利用先验信息。比如每一次买彩票的情况就可以看成是下一次彩票时可用的先验信息。
自英国学者贝叶斯发表了“论有关机遇问题的求解”一文、并提出了贝叶斯公式后,就有了贝叶斯学派。该学派认为任何一个未知量都可以通过重复实验的方式来获得一个先验的分布,并以之来影响总体分布和推断。而在贝叶斯派形成之前,曾经一统江湖的频率派从来就是立场坚定反对这种特别带主观性质的做法。当两大门派形成后,便为了主观还是客观描述未知量,有了一场吵了近250年,至今还在吵的架 [9]。
另外,为了追求可分析,统计学界偏好采用线性模型求解,以便获得相对干净的答案。但是,现实世界却存在大量的非线性问题。
所以,不管两个学派谁对谁错,要研究真正的智能、寻找可解释性的线索,就需要统计学的这两个学派能提供更多有效的、非线性的理论、方法和工具。
4、数学
对我来说,数学是最美丽的,几千年的努力已经让其成为了人类历史上最完备的学科,没有之一。数学之美在于简洁,往往一两个公式、一个定理就能把连篇累牍的内容讲清楚。然后,这种简洁和完备性的获得也是有代价的,很多时候是通过大量放缩、牺牲小项来得到的。而研究人工智能,在达到一定预测性能后,我们需要了解的,也许就是这些在放缩过程中被牺牲掉的小项。因为我们在处理实际问题时,大多数情况是有噪的,不确定性的。
另外,我们也需要思考一个问题:智能是否需要严谨的数学?也许并不要!如果我们将智能狭义的理解为人类的高级智能的话,那是必需的。但这也只是在需要进行严密思维、慢思维的时候才用到着。大部分的常识智能是不依赖于这类高级智能,即不需要进行太多的数学关联,就能形成。比如大自然中的绝大多数动物,哪种动物会像人一样学过数学?可为什么仍然能很好地适应环境?这说明我们在仿生智能时,从数学上建模可能并不见得是等同于真正智能的感知和预测模式。
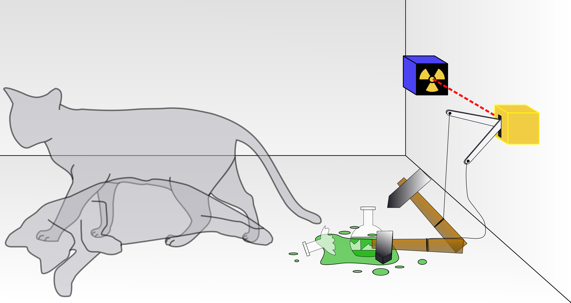
图5 “薛定谔猫”佯谬
5、物理学
谈到物理学与人工智能,必须提下波动力学之父、曾提出过“薛定谔猫”佯谬 (见图5)的奥地利物理学家埃尔温·薛定谔。他于1944年出版的书《生命是什么---活细胞的物理学观》开启了分子生物学的大门,也有说其对人工智能的早期发展起了重要作用。他认为物理学和化学原则有助于解释生命现象,而基因的持久和遗传模式的稳定可以用量子理论来说明。该书也促使英国物理学家克里克从粒子物理的研究转行到生物学,并与美国生物学家沃森一起在1953年提出了DNA双螺旋分子结构模型,解开了遗传信息的复制和编码机理。
而现代物理学中,与人工智能可能最密切相关的是量子计算。从机理上来看,量子比特的量子叠加态特性,可以避开现有计算机发展中摩尔定律的影响,避免现有CPU发热问题,以指数级的效率大幅度提升计算能力。然而,量子计算在理想情况下的主要优势是加速计算。但速度快的同时,他也为每个量子位的状态引入了概率或不确定性。这使得其在研究人工智能时,有可能失去原本机器学习很容易获得的精确性能。比如聚类中最经典的K-均值算法,经典机器学习能轻松达到的性能,利用量子计算的框架来处理,可能效果反而会变得差强人意。另外,智能的本质问题应该不是通过提高计算效率就能解决。
6、遗传学
遗传学解释了基因的复制、交叉、变异,近年来在基因测序方面也取得了长足的进步。从已知的情况看,基因的结构很象是一个超乎寻常的程序员编制的程序,固定的基因序列中包含了可以表达功能的编码区和负责多个其他能力如调控的非编码区。不仅如此,基因似乎有一种按时表达或调控的能力。这种编程技巧目前还无法在人类已有的程序中找到对应的。
不仅如此,目前对于分析非编码 区 DNA 序列还没有一般性的指导方法。在人类基因组中,并非所有的序列均被编码,即便是某种蛋白质的模板,已完成编码的部分也仅占人类基因总序列的 3~5%。非编码区的调控机制人类还远没到能百分之百说得清楚的地步。
说个极端的例子,一个受精卵分裂成两个相同的,两变四,四变八,依此类推,上面的发育成了大脑、上身,下面的发育成了脚,可是这种细胞与细胞间的方向性是如何被调控机制获得的呢?
所以,对非编码区按时调控的深入分析,也许对于理解智能体的结构发育有着重要的作用。 正如 1975年获得诺贝尔生理学或医学奖的美国科学家Dulbecco于1986 年所说:“人类的 DNA 序列是人类的真谛, 这个世界上发生的一切事情,都与这一序列息息相关”[10]。但要完全破译这一序列以及相关的内容,我们还有很长的路要走。
7、认知心理学
心理学中与智能研究相关的主要是认知心理学。从广义来讲,与人认识相关的都是认知心理学的研究范围。狭义理解,主要是信息加工相关的心理学。它将人的认知与计算机类比看待,希望从信息的接受、编码、处理、存储、检索的角度来研究人的感知、记忆、控制和反应等系统。
从20世纪50年代中期开始,到1967年美国心理学家奈瑟出版《认知心理学》一书形成了独立的流派,至今已有近70年的历史。其学科中也衍生了强调整体大于部分的格式塔心理学、 皮亚杰的结构主义等众多分支。因为门派众多,这里仅以此两个分支为例来简要讨论在人工智能研究中的意义和存在的问题。
在视觉方面,格式塔心理学总结了一些规律,如涌现、多视角、聚类、旋转不变性等,强调整体与部分之间的差异,并非简单的累加,甚至整体可能大于部分之和。另外,顿悟学习、学习迁移、创造性思维的研究也是其重要方向之一。其不足在于,忽视了对生理基础的研究,部分实验缺乏足够的证据。另外,格式塔理论发展出来的观点不太容易量化、程序化。结果,尽管大家觉得它有一定的道理,但近几十年在计算机视觉和机器学习研究领域可以见到的相关论文仍然非常少。
皮亚杰倡导的儿童发育心理学和结构主义是另一条探索智能发育的道理,主张认识的同化和顺应,即将本能反应向不同目标的范围扩大的同化,以及根据环境变化而对行为产生改变的顺应 [11]。他对儿童在感觉运算、前运算、和具体运算阶段的观察分析,视角非常独特,也开启了儿童发育心理研究的大门。皮亚杰的结构主义不足在于1)受研究的个体数量和年龄跨度的限制,难以获得更一般性的归纳总结;2)偏好用问题回答的方式来研究,难以对语言未完全掌握的儿童进行有质量的询问。而且,如我之前所述,问题回答本已是高层和抽象智能,远离了智能金字塔的基础。
如果可以多审视下格式塔心理学和皮亚杰的结构主义,也许对于我们重新思考智能体的发育,尤其是理解犯错机制会有着重要的启示作用。另外,也许可以考虑研究宠物的认知心理,尽管它不如人那么聪明,但宠物狗的认知能力并不会比一两岁小孩的弱多少,而且宠物狗的一生长时间是停留在与儿童相仿的认知能力下的。
所以,尽管认知心理学可以利用计算机模拟人的抽象思维能力,但在早期发育和金字塔结构的研究这一块还存在大的空间有待挖掘。
8、社会学
在未来,人工智能体必然是以群体形式来存在和发展壮大的,所以有必要研究群体行为的各种内在因素。与这一问题最密切相关的,是研究社会行为与人类群体的社会学。
自1838年由法国社会学创始人奥古斯特·孔德首次提出“社会学”的概念,19世纪40年代由埃米尔·迪尔凯姆、卡尔·马克思、马克斯·韦伯三大社会学巨头共同创立, 社会学至今已经形成了从微观的社会行动和人际互动、到宏观的社会系统和结构的广泛研究范围。在群体行为的结构功能、符号互动、社会冲突、社会交换、社会心理、社会统计学、社会伦理等方面,社会学都有着深入而丰富的研究成果。
尽管如此,社会学在形式化这些成果方面还存在困难,这使得仿真社会学中的群体行为各要素有一定难度。而如果希望了解未来人工智能体社会的各种变化,程序化这些要素又是必然的。另外,社会学关注的主要是人。而未来的人工智能社会组成肯定不限于只有人类。那么,如果要提前布局和预测,需要将非人类智能群体行为的研究也纳入智能的研究范畴中。
到此,爱犯错的智能体系列就告一段落了。总体来看,研究人工智能、大脑的功能一点也不比研究宇宙简单。从我列举的、并不算完全的方向来看,研究人工智能的相关学科之间的差异比较大。研究机器学习的,可能对脑科学、社会学知之甚少,研究脑科学、社会学又对机器学习的核心理论与算法一知半解。结果, 单靠一臂之力或一个方向的力量,孤立开来各自做研究,可能就只能盲人摸象,看到局部,却依然不明智能路在何方。也许,打破彼此间的鄙视链,交叉合力、优势互补,或许能找到关于智能的答案。
参考文献:
1. 拉·梅特里.人是机器. 商务印书局, 2011.
2. Zadeh, L. A. Fuzzy sets. Information and Control. 8 (3): 338–353,1965 doi:10.1016/S0019-9958(65)90241-X
3. Zadeh. L. A. Outline of a new approach to the analysis of complex systems and decision processes. IEEE Trans. Systems, Man and Cybernetics, SMC3(1): 28–44, 1973.
4.Kahneman, D. Thinking, Fast and Slow. Farrar, Straus and Giroux, 2011
5. Turing, A. M. Computing Machinery and Intelligence:Oxford University Press on behalf of the Mind Association,1950.
6. Searle, J. 1980a. "Minds, Brains, and Programs." Behavioral and Brain Sciences 3, 417-424.
7. Tikhonov, A. N. On the solution of ill-posed problems and the method of regularization, Dokl. Akad. Nauk SSSR, 151:3, 501–504, 1963.
8. 杨雄里. 当前脑科学的发展态势和战略. 2018. https://www.sohu.com/a/221020764_465915
9. Efron, B. Bayes’ theorem in the 21st century. Science, 340(7):1177-1178, 2013.
10. Dulbecco, R. A turning point in cancer research: sequencing the human genome. Science, 231(4742): 1055-1056, 1986.
11. 皮亚杰. 结构主义. 商务印书局,1984.
张军平
2018年12月21日星期五
注:本系列已授权清华大学出版社,将于明年出版。如需引用本科普系列的内容,请采用以下格式引用,谢谢!
张军平. 爱犯错的智能体,清华大学出版社,2019.
延伸阅读:
16. 爱犯错的智能体 --- 听觉篇(二):视听错觉与无限音阶的拓扑
15. 爱犯错的智能体 -- 听觉篇(一):听觉错觉与语音、歌唱的智能分析
14. 爱犯错的智能体 – 视觉篇(十一):主观时间与运动错觉
11. 爱犯错的智能体--视觉篇(八):由粗到细、大范围优先的视觉

张军平,复旦大学计算机科学技术学院,教授、博士生导师,中国自动化学会混合智能专委会副主任。主要研究方向包括人工智能、机器学习、图像处理、生物认证及智能交通。至今发表论文近100篇,其中IEEE Transactions系列18篇,包括IEEE TPAMI, TNNLS, ToC, TITS, TAC等。学术谷歌引用2800余次,ESI高被引一篇,H指数28.
https://wap.sciencenet.cn/blog-3389532-1152736.html
上一篇:爱犯错的智能体(十九) – 群体智能与错觉
下一篇:论文减负 --- 如何鼓励原创性研究